Modely zpracování dokumentů
Důležité
- Verze Document Intelligence ve verzi Public Preview poskytují dřívější přístup k funkcím, které jsou aktivní ve vývoji.
- Funkce, přístupy a procesy se můžou před obecnou dostupností (GA) změnit na základě zpětné vazby uživatelů.
- Verze Public Preview klientských knihoven Document Intelligence ve výchozím nastavení je rest API verze 2024-02-29-preview.
- Verze Public Preview 2024-02-29-preview je aktuálně dostupná jenom v následujících oblastech Azure:
- USA – východ
- USA – západ 2
- Západní Evropa
Tento obsah se vztahuje na:![]() v4.0 (Preview) | Předchozí verze:
v4.0 (Preview) | Předchozí verze:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)![]() v2.1 (GA)
v2.1 (GA)
Tento obsah se vztahuje na:![]() v3.1 (GA) | Nejnovější verze:
v3.1 (GA) | Nejnovější verze:![]() v4.0 (Preview) | Předchozí verze:
v4.0 (Preview) | Předchozí verze:![]() v3.0
v3.0![]() v2.1
v2.1
Tento obsah se vztahuje na:![]() v3.0 (GA) | Nejnovější verze:
v3.0 (GA) | Nejnovější verze:![]() v4.0 (Preview)
v4.0 (Preview)![]() v3.1 | Předchozí verze:
v3.1 | Předchozí verze:![]() v2.1
v2.1
Tento obsah se vztahuje na:![]() v2.1 | Nejnovější verze:
v2.1 | Nejnovější verze:![]() v4.0 (Preview)
v4.0 (Preview)
Azure AI Document Intelligence podporuje širokou škálu modelů, které umožňují přidat inteligentní zpracování dokumentů do aplikací a toků. Můžete použít předem vytvořený model specifický pro doménu nebo vytrénovat vlastní model přizpůsobený konkrétním obchodním potřebám a případům použití. Funkce Document Intelligence se dá použít s rozhraním REST API nebo pythonem, C#, Javou a javascriptovými klientskými knihovnami.
Přehled modelů
Následující tabulka ukazuje dostupné modely pro jednotlivé aktuální verze Preview a stabilní rozhraní API:
| Typ modelu | Model | • 2024-02-29-preview Odrážka 2023-10-31-preview |
31. 7. 2023 (GA) | 31. 8. 2022 (GA) | v2.1 (GA) |
|---|---|---|---|---|---|
| Modely analýzy dokumentů | Přečíst | ✔️ | ✔️ | ✔️ | Není k dispozici |
| Modely analýzy dokumentů | Rozložení | ✔️ | ✔️ | ✔️ | ✔️ |
| Modely analýzy dokumentů | Obecný dokument | přesunuto do rozložení** | ✔️ | ✔️ | Není k dispozici |
| Předem vytvořené modely | Smlouva | ✔️ | ✔️ | Není k dispozici | Není k dispozici |
| Předem vytvořené modely | Zdravotní pojištění | ✔️ | ✔️ | ✔️ | Není k dispozici |
| Předem vytvořené modely | Průkaz totožnosti | ✔️ | ✔️ | ✔️ | ✔️ |
| Předem vytvořené modely | Faktura | ✔️ | ✔️ | ✔️ | ✔️ |
| Předem vytvořené modely | Příjmu | ✔️ | ✔️ | ✔️ | ✔️ |
| Předem vytvořené modely | US 1040 Tax* | ✔️ | ✔️ | Není k dispozici | Není k dispozici |
| Předem vytvořené modely | US 1098 Tax* | ✔️ | Není k dispozici | – | Není k dispozici |
| Předem vytvořené modely | US 1099 Tax* | ✔️ | Není k dispozici | – | Není k dispozici |
| Předem vytvořené modely | US W2 Tax | ✔️ | ✔️ | ✔️ | Není k dispozici |
| Předem vytvořené modely | US Hypotéka 1003 URLA | ✔️ | Není k dispozici | – | Není k dispozici |
| Předem vytvořené modely | Us Hypotéka 1008 Souhrn | ✔️ | Není k dispozici | – | Není k dispozici |
| Předem vytvořené modely | Zveřejnění uzavírací hypotéky v USA | ✔️ | Není k dispozici | – | Není k dispozici |
| Předem vytvořené modely | Manželství certifikátu | ✔️ | Není k dispozici | – | Není k dispozici |
| Předem vytvořené modely | Platební karta | ✔️ | Není k dispozici | – | Není k dispozici |
| Předem vytvořené modely | Vizitka | deprecated | ✔️ | ✔️ | ✔️ |
| Vlastní klasifikační model | Vlastní klasifikátor | ✔️ | ✔️ | Není k dispozici | Není k dispozici |
| Vlastní model extrakce | Vlastní neurální | ✔️ | ✔️ | ✔️ | Není k dispozici |
| Vlastní model pro odčítání | Vlastní šablona | ✔️ | ✔️ | ✔️ | ✔️ |
| Vlastní model extrakce | Vlastní složené | ✔️ | ✔️ | ✔️ | ✔️ |
| Všechny modely | Možnosti doplňků | ✔️ | ✔️ | Není k dispozici | Není k dispozici |
* - Obsahuje podmodely. Informace o podporovaných variantáchach
| Funkce doplňku | Doplněk nebo zdarma | • 2024-02-29-preview &bullet [2023-10-31-preview](/rest/api/aiservices/operation-groups?view=rest-aiservices-2024-02-29-preview&preserve-view=true |
2023-07-31 (GA) |
2022-08-31 (GA) |
v2.1 (GA) |
|---|---|---|---|---|---|
| Extrakce vlastností písma | Doplněk | ✔️ | ✔️ | Není k dispozici | Není k dispozici |
| Extrakce vzorců | Doplněk | ✔️ | ✔️ | Není k dispozici | Není k dispozici |
| Extrakce s vysokým rozlišením | Doplněk | ✔️ | ✔️ | Není k dispozici | Není k dispozici |
| Extrakce čárových kódů | Bezplatný | ✔️ | ✔️ | Není k dispozici | Není k dispozici |
| Rozpoznávání jazyka | Bezplatný | ✔️ | ✔️ | Není k dispozici | Není k dispozici |
| Páry klíč-hodnota | Bezplatný | ✔️ | Není k dispozici | – | Není k dispozici |
| Pole dotazu | Doplněk* | ✔️ | Není k dispozici | – | Není k dispozici |
Funkce analýzy modelů
| ID modelu | Extrakce obsahu | Pole dotazu | Odstavce | Role odstavce | Značky výběru | Tabulky | Páry klíč-hodnota | Jazyky | Čárové kódy | Analýza dokumentů | Vzorce* | Písmo stylu* | Vysoké rozlišení* |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| předem připravená čtení | ✓ | O | O | O | O | O | |||||||
| předem připravené rozložení | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | O | O | O | O | O | ||
| předem připravený dokument | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | O | O | O | O | O | |
| předem připravená vizitka | ✓ | ✓ | ✓ | ||||||||||
| předem připravená smlouva | ✓ | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||
| prebuilt-healthInsuranceCard.us | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-idDocument | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| předem připravená faktura | ✓ | ✓ | ✓ | ✓ | O | O | O | ✓ | O | O | O | ||
| předem připravená potvrzení | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-marriageCertificate.us | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| předem připravená platební karta | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| předem připravená hypotéka.us.1003 | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| předem připravená hypotéka.us.1008 | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-mortgage.us.closingDisclosure | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.w2 | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | ||||
| předem připravená-tax.us.1098 | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | ||||
| prebuilt-tax.us.1098E | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | ||||
| prebuilt-tax.us.1098T | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | ||||
| prebuilt-tax.us.1099(varianty) | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | ||||
| prebuilt-tax.us.1040(varianty) | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| { customModelName } | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O |
%% - Enabled
O - Optional
* - Premium features incur extra costs
Add-On* – Pole dotazu se za ceny liší od ostatních funkcí doplňku. Podrobnosti najdete na stránce s cenami .
| Model | Popis |
|---|---|
| Modely analýzy dokumentů | |
| Čtení OCR | Extrahujte tištěný a rukou psaný text včetně slov, umístění a rozpoznaných jazyků. |
| Analýza rozložení | Extrahujte prvky rozložení textu a dokumentu, jako jsou tabulky, značky výběru, názvy, nadpisy oddílů a další. |
| Předem připravené modely | |
| Zdravotní pojištění | Automatizujte zdravotnické procesy extrahováním pojištění, člena, lékařského předpisu, čísla skupiny a dalších klíčových informací z amerických zdravotních pojištění. |
| Modely daňových dokumentů USA | Zpracujte daňové formuláře USA a extrahujte zaměstnance, zaměstnavatele, mzdu a další informace. |
| Modely dokumentů hypotéky v USA | Zpracujte americké hypotéky a extrahujte informace o půjčkách a nemovitostech dlužníka. |
| Smlouva | Extrahujte podrobnosti smlouvy a strany. |
| Faktura | Automatizujte faktury. |
| Příjmu | Extrahujte údaje o účtech z účtenek. |
| Dokument identity (ID) | Extrahujte pole identity (ID) z licencí řidiče USA a mezinárodních pasů. |
| Vizitka | Naskenujte vizitky a extrahujte do svých aplikací klíčová pole a data. |
| Vlastní modely | |
| Vlastní model (přehled) | Extrahujte data z formulářů a dokumentů specifických pro vaši firmu. Vlastní modely se trénují pro různá data a případy použití. |
| Vlastní modely extrakce | ● Vlastní modely šablon používají pomůcky rozložení k extrakci hodnot z dokumentů a jsou vhodné k extrakci polí z vysoce strukturovaných dokumentů s definovanými vizuálními šablonami. ● Vlastní neurální modely jsou trénovány na různých typech dokumentů k extrakci polí ze strukturovaných, částečně strukturovaných a nestrukturovaných dokumentů. |
| Vlastní klasifikační model | Model vlastní klasifikace může klasifikovat každou stránku ve vstupním souboru, aby identifikoval dokumenty v rámci a může také identifikovat více dokumentů nebo více instancí jednoho dokumentu ve vstupním souboru. |
| Složené modely | Kombinací několika vlastních modelů do jednoho modelu můžete automatizovat zpracování různých typů dokumentů s jedním složeným modelem. |
U všech modelů kromě modelu vizitek teď funkce Document Intelligence podporuje funkce doplňků, které umožňují sofistikovanější analýzu. Tyto volitelné funkce je možné povolit a zakázat v závislosti na scénáři extrakce dokumentů. Pro verzi rozhraní API (GA) a novějších verzí rozhraní API je k dispozici 2023-07-31 sedm možností doplňků:
ocrHighResolutionformulasstyleFontbarcodeslanguageskeyValuePairs(2024-02-29-preview, 2023-10-31-preview)queryFields(2024-02-29-preview, 2023-10-31-preview)Not available with the US.Tax models
Podrobnosti o modelu
Tato část popisuje výstup, který můžete očekávat od každého modelu. Upozorňujeme, že výstup většiny modelů můžete rozšířit o funkce doplňků.
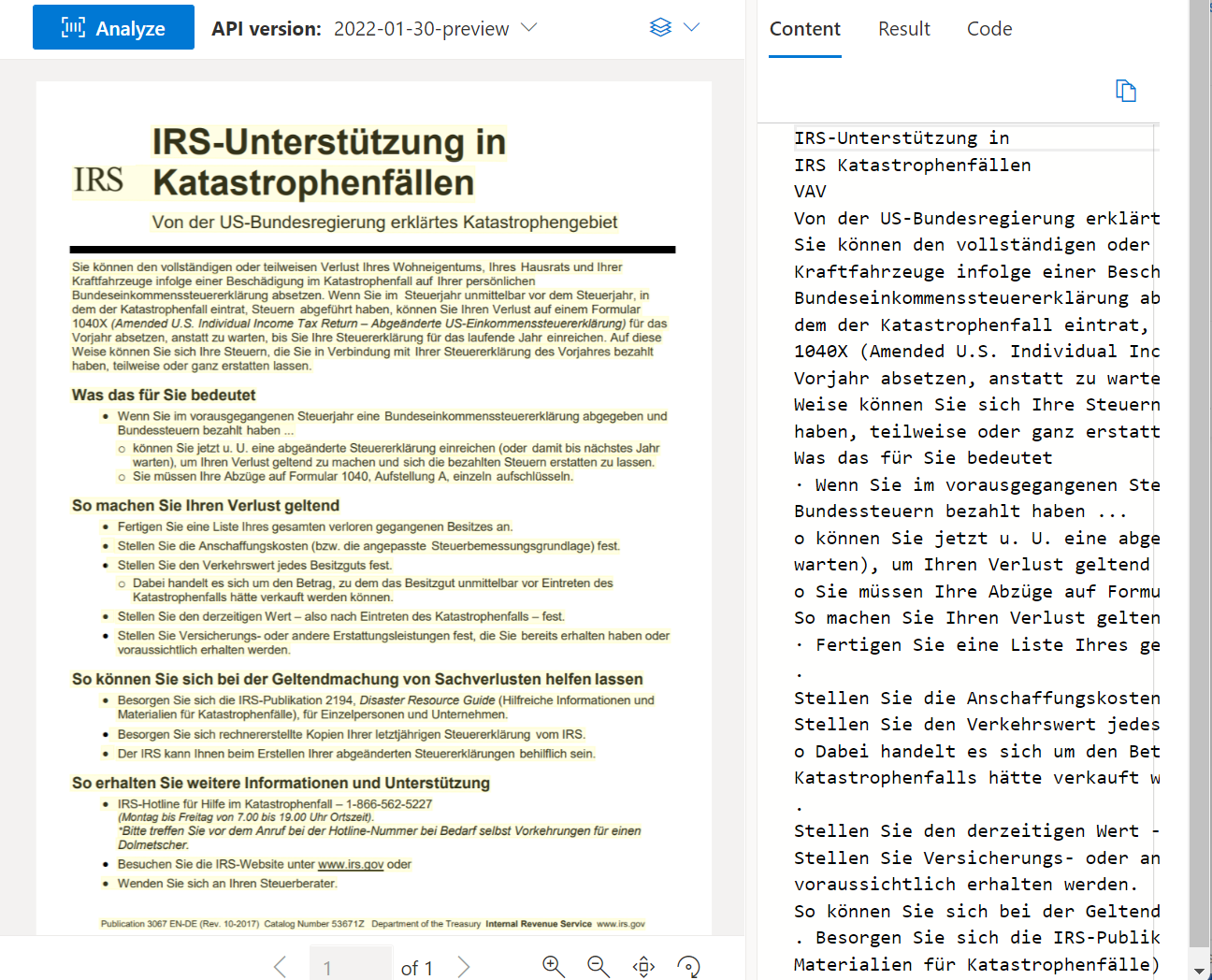
Čtení OCR

Rozhraní API pro čtení analyzuje a extrahuje řádky, slova, jejich umístění, rozpoznané jazyky a ručně psaný styl v případě zjištění.
Ukázkový dokument zpracovaný pomocí nástroje Document Intelligence Studio:
Analýza rozložení
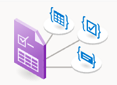
Model analýzy rozložení analyzuje a extrahuje text, tabulky, značky výběru a další prvky struktury, jako jsou názvy, nadpisy oddílů, záhlaví stránek, zápatí stránek a další.
Ukázkový dokument zpracovaný pomocí nástroje Document Intelligence Studio:
Zdravotní pojištění
![]()
Model zdravotní karty kombinuje výkonné funkce optického rozpoznávání znaků (OCR) s modely hlubokého učení k analýze a extrakci klíčových informací z amerických zdravotních pojištění.
Ukázka americké zdravotní pojištění zpracovaná pomocí nástroje Document Intelligence Studio:

Daňové doklady USA

Modely daňových dokumentů USA analyzují a extrahují klíčová pole a řádkové položky z vybrané skupiny daňových dokladů. Rozhraní API podporuje analýzu daňových dokumentů usa v angličtině různých formátů a kvality, včetně obrázků zachycených telefonem, naskenovaných dokumentů a digitálních pdf souborů. V současné době se podporují následující modely:
| Model | Popis | ID modelu |
|---|---|---|
| US Tax W-2 | Extrahování podrobností o kompenzaci k dani. | prebuilt-tax.us.W-2 |
| US Tax 1040 | Extrahujte podrobnosti o hypotékách. | prebuilt-tax.us.1040(varianty) |
| US Tax 1098 | Extrahujte podrobnosti o hypotékách. | prebuilt-tax.us.1098(varianty) |
| US Tax 1099 | Extrahujte příjmy získané z jiných zdrojů než zaměstnavatele. | prebuilt-tax.us.1099(varianty) |
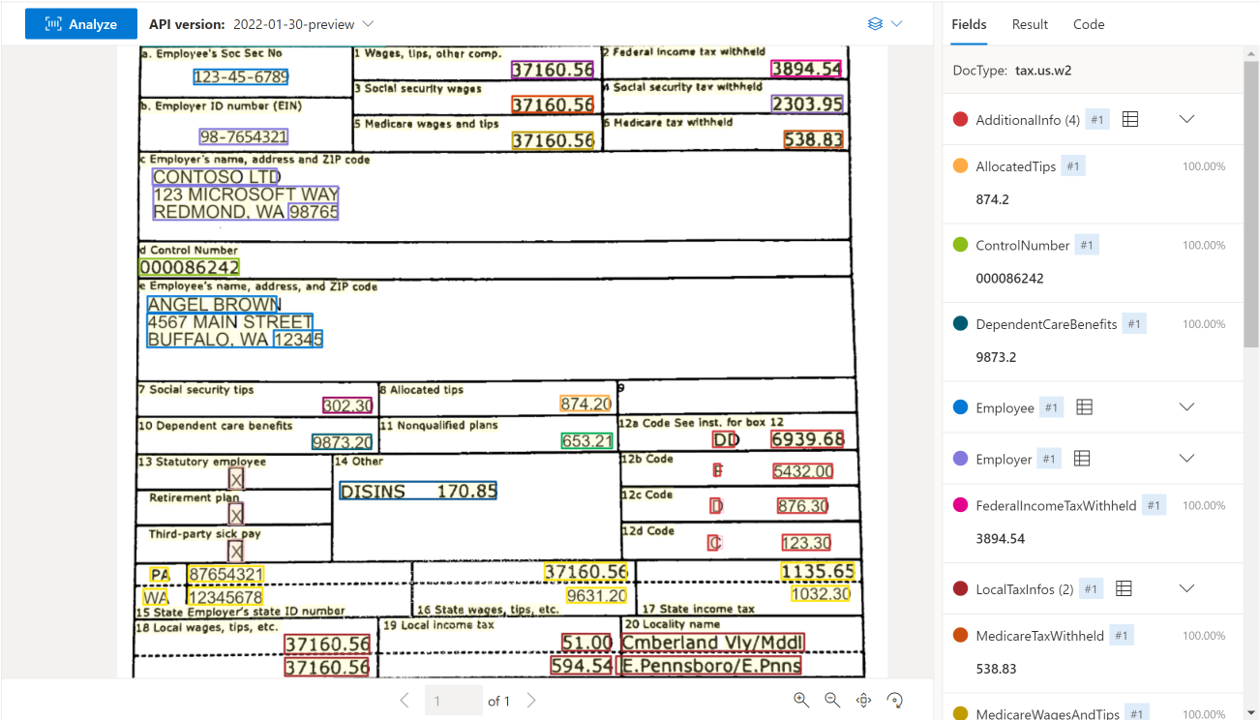
Ukázkový dokument W-2 zpracovaný pomocí nástroje Document Intelligence Studio:
Americké hypotéky dokumenty

Modely dokumentů hypoték v USA analyzují a extrahují klíčová pole, včetně informací o dlužníku, půjčkách a nemovitostech z vybrané skupiny hypoték. Rozhraní API podporuje analýzu amerických hypoték anglického jazyka různých formátů a kvality, včetně obrázků zachycených telefonem, naskenovaných dokumentů a digitálních pdf souborů. V současné době se podporují následující modely:
| Model | Popis | ID modelu |
|---|---|---|
| 1003 Licenční smlouva s koncovým uživatelem (EULA) | Extrahovat půjčku, dlužníka, podrobnosti o nemovitosti. | předem připravená hypotéka.us.1003 |
| Souhrnný dokument 1008 | Extrahujte dlužníka, prodejce, nemovitosti, hypotéku a podrobnosti o započtení. | předem připravená hypotéka.us.1008 |
| Závěrečné zveřejnění | Extrahujte závěrečné, transakční náklady a podrobnosti o půjčkách. | prebuilt-mortgage.us.closingDisclosure |
| Manželství certifikátu | Extrahujte podrobnosti o manželství pro žadatele o společný úvěr. | prebuilt-marriageCertificate |
| US Tax W-2 | Extrahujte podrobnosti o dani z důvodu ověření příjmu. | prebuilt-tax.us.W-2 |
Ukázkový dokument o zavření vyzrazení zpracovaný pomocí nástroje Document Intelligence Studio:

Smlouva
![]()
Model kontraktu analyzuje a extrahuje klíčová pole a řádkové položky ze smluvních smluv, včetně stran, jurisdikcí, ID smlouvy a názvu. Model aktuálně podporuje dokumenty kontraktů v angličtině.
Ukázkový kontrakt zpracovaný pomocí nástroje Document Intelligence Studio:

Faktura

Model faktury automatizuje zpracování faktur a extrahuje jméno zákazníka, fakturační adresu, termín splatnosti a splatnou částku, řádkové položky a další klíčová data. V současné době model podporuje faktury za angličtinu, španělštinu, němčinu, francouzštinu, italštinu, portugalštinu a nizozemštinu.
Ukázková faktura zpracovaná pomocí nástroje Document Intelligence Studio:

Potvrzení
Pomocí modelu účtenek můžete zkontrolovat prodejní účtenky pro obchodní jméno, kalendářní data, řádkové položky, množství a součty z tištěných a ručně psaných účtenek. Verze v3.0 také podporuje jednostránkové zpracování potvrzení o hotelech.
Ukázkový příjem zpracovaný pomocí nástroje Document Intelligence Studio:

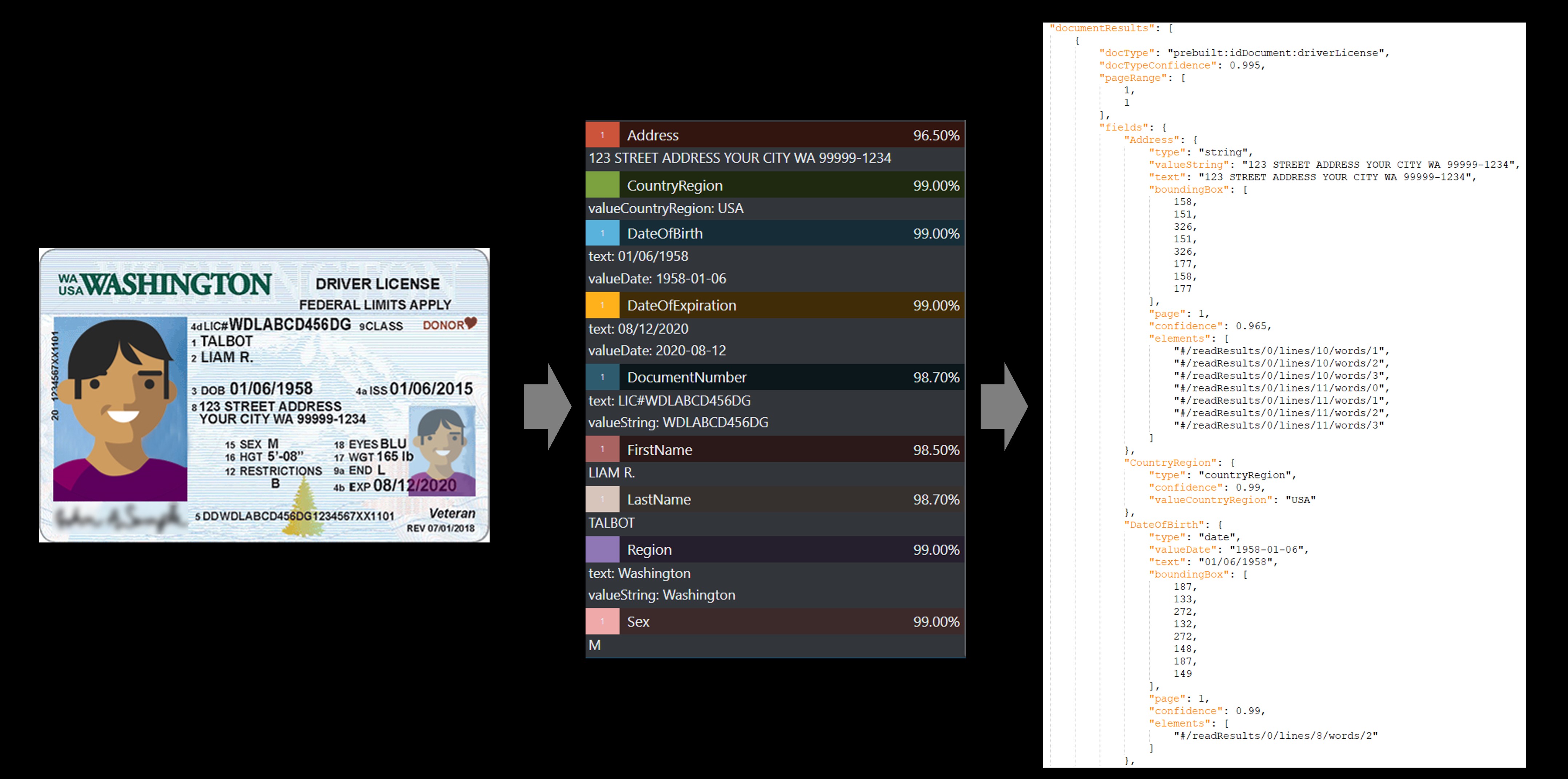
Dokument identity (ID)

Pomocí modelu dokument identity (ID) můžete zpracovat licence řidiče USA (všech 50 států a okresu Columbia) a životopisné stránky z mezinárodních pasů (s výjimkou víza a dalších cestovních dokumentů) k extrakci klíčových polí.
Ukázková licence řidiče v USA zpracovaná pomocí nástroje Document Intelligence Studio:

Manželství certifikátu
![]()
Pomocí modelu certifikátu manželství můžete zpracovávat certifikáty manželství v USA k extrakci klíčových polí, včetně jednotlivců, data a místa.
Ukázkový certifikát manželství v USA zpracovaný pomocí nástroje Document Intelligence Studio:

Platební karta
![]()
Pomocí modelu kreditní karty můžete zpracovávat kreditní a debetní karty k extrakci polí klíče.
Ukázková platební karta zpracovaná pomocí nástroje Document Intelligence Studio:

Vlastní modely

Vlastní modely lze široce klasifikovat do dvou typů. Vlastní klasifikační modely, které podporují klasifikaci typu dokumentu a vlastní modely extrakce, které můžou extrahovat definované schéma z konkrétního typu dokumentu.

Vlastní modely dokumentů analyzují a extrahují data z formulářů a dokumentů specifických pro vaši firmu. Vytrénují se tak, aby rozpoznala pole formulářů v rámci vašeho jedinečného obsahu a extrahovala páry klíč-hodnota a data tabulky. Abyste mohli začít, potřebujete jenom jeden příklad typu formuláře.
Vlastní model verze 3.0 podporuje detekci podpisů ve vlastní šabloně (formuláři) a křížových tabulkách v šablonách i neurálních modelech.
Ukázková vlastní šablona zpracovaná pomocí nástroje Document Intelligence Studio:
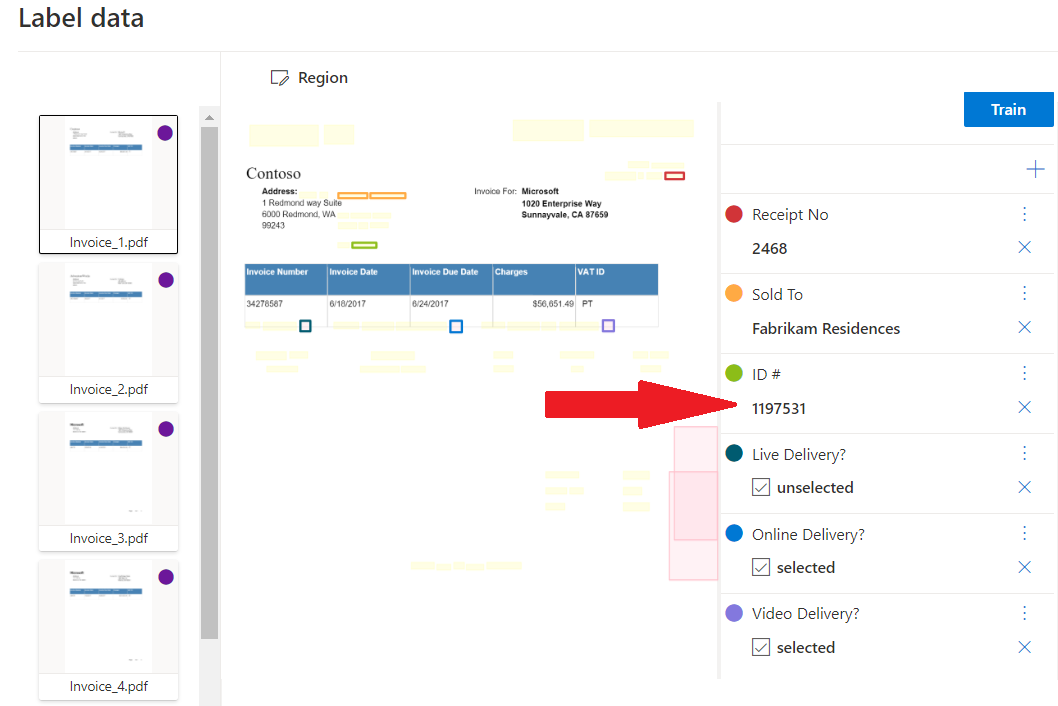
Vlastní extrakce

Vlastní model extrakce může být jeden ze dvou typů, vlastní šablona nebo vlastní neurální. Pokud chcete vytvořit vlastní model extrakce, označte datovou sadu dokumentů hodnotami, které chcete extrahovat, a vytrénujte model na označené datové sadě. Abyste mohli začít, potřebujete jenom pět příkladů stejného formuláře nebo typu dokumentu.
Ukázková vlastní extrakce zpracovaná pomocí nástroje Document Intelligence Studio:

Vlastní klasifikátor

Vlastní klasifikační model umožňuje identifikovat typ dokumentu před vyvoláním modelu extrakce. Klasifikační model je k dispozici od 2023-07-31 (GA) rozhraní API. Trénování vlastního klasifikačního modelu vyžaduje alespoň dvě odlišné třídy a minimálně pět vzorků na třídu.
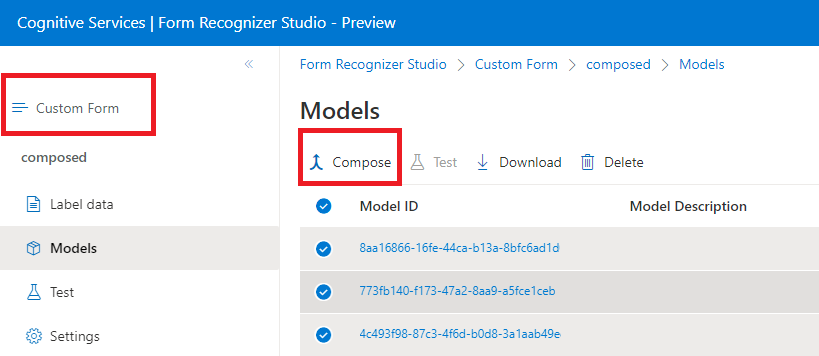
Složené modely
Složený model se vytvoří tak, že vezme kolekci vlastních modelů a přiřadí je k jednomu modelu vytvořenému z vašich typů formulářů. Můžete přiřadit více vlastních modelů složeným modelům volaným s jedním ID modelu. K jednomu složeného modelu můžete přiřadit až 200 trénovaných vlastních modelů.
Okno dialogového okna Složený model v nástroji Document Intelligence Studio:
Požadavky na vstup
Nejlepšíchvýsledkůch
Podporované formáty souborů:
Model PDF Obrázek:
JPEG/JPG, PNG, BMP, TIFF, HEIFsystém Microsoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX) a HTMLČteno ✔ ✔ ✔ Rozložení ✔ ✔ ✔ (2024-02-29-preview, 2023-10-31-preview) Obecný dokument ✔ ✔ Předpřipravený ✔ ✔ Vlastní extrakce ✔ ✔ Vlastní klasifikace ✔ ✔ ✔ (29. 2024. 2024) U SOUBORŮ PDF a TIFF je možné zpracovat až 2000 stránek (s předplatným úrovně Free se zpracovávají pouze první dvě stránky).
Velikost souboru pro analýzu dokumentů je 500 MB pro placenou úroveň (S0) a 4 MB pro bezplatnou úroveň (F0).
Rozměry obrázku musí být mezi 50 x 50 pixelů a 10 000 px x 10 000 pixelů.
Pokud jsou soubory PDF uzamčené heslem, musíte před odesláním toto uzamčení odebrat.
Minimální výška extrahovaného textu je 12 pixelů pro obrázek o velikosti 1024 x 768 pixelů. Tato dimenze odpovídá
8150 bodům na palec (DPI).Pro trénování vlastního modelu je maximální počet stránek pro trénovací data 500 pro vlastní model šablony a 50 000 pro vlastní neurální model.
Pro trénování vlastního modelu extrakce je celková velikost trénovacích dat 50 MB pro model šablony a 1G MB pro neurální model.
Pro trénování modelu vlastní klasifikace je
1GBcelková velikost trénovacích dat s maximálně 10 000 stránkami.
Poznámka:
Nástroj Sample Labeling nepodporuje formát souboru BMP. Jedná se o omezení nástroje, nikoli služby Document Intelligence.
Migrace verzí
Naučte se ve svých aplikacích používat Document Intelligence v3.0 podle našeho průvodce migrací Document Intelligence v3.1.
| Model | Popis |
|---|---|
| Analýza dokumentů | |
| Rozložení | Extrahujte informace o textu a rozložení z dokumentů. |
| Předem připravené | |
| Faktura | Extrahujte klíčové informace z anglické a španělské faktury. |
| Příjmu | Extrahujte klíčové informace z anglických účtenek. |
| Průkaz totožnosti | Extrahujte klíčové informace z licencí na řidiče USA a mezinárodních pasů. |
| Vizitka | Extrahujte klíčové informace z anglických vizitek. |
| Vlastní | |
| Vlastní | Extrahujte data z formulářů a dokumentů specifických pro vaši firmu. Vlastní modely se trénují pro různá data a případy použití. |
| Skládá | Vytvořte kolekci vlastních modelů a přiřaďte je k jednomu modelu vytvořenému z typů formulářů. |
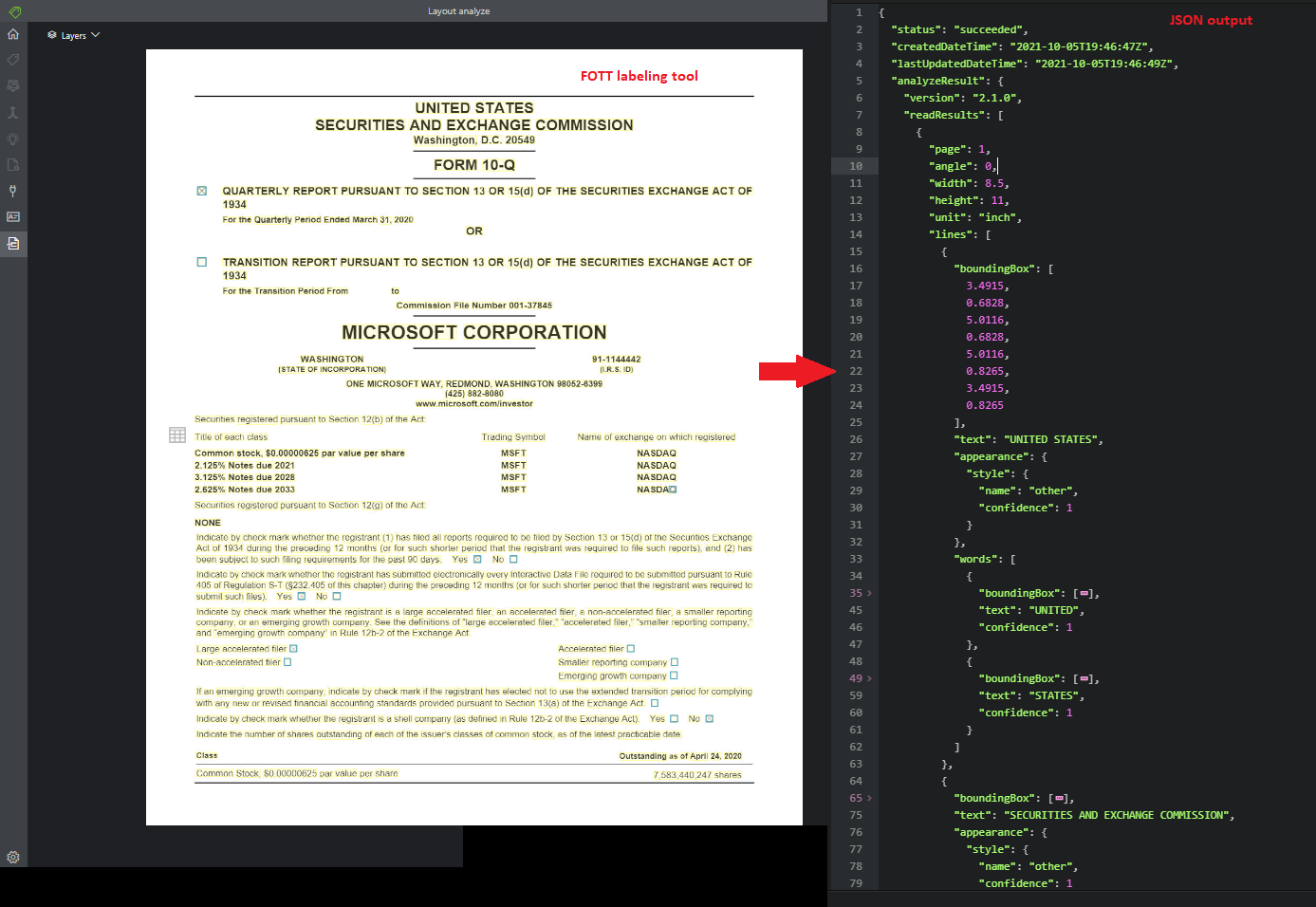
Rozložení
Rozhraní API rozložení analyzuje a extrahuje text, tabulky a záhlaví, značky výběru a informace o struktuře z dokumentů.
Ukázkový dokument zpracovaný pomocí nástroje Ukázkové popisky:
Faktura
Model faktury analyzuje a extrahuje klíčové informace z prodejních faktur. Rozhraní API analyzuje faktury v různých formátech a extrahuje klíčové informace, jako je jméno zákazníka, fakturační adresa, termín splatnosti a splatná částka.
Ukázková faktura zpracovaná pomocí nástroje Ukázkový popisek:

Potvrzení
- Model účtenek analyzuje a extrahuje klíčové informace z tištěných a rukou psaných prodejních účtenek.
Ukázková účtenka zpracována pomocí nástroje Pro popisování vzorku:
Průkaz totožnosti
Model dokumentu ID analyzuje a extrahuje klíčové informace z následujících dokumentů:
Licence řidiče USA (všech 50 států a District of Columbia)
Životopisné stránky z mezinárodních pasů (s výjimkou víza a dalších cestovních dokladů). Rozhraní API analyzuje dokumenty identit a extrahuje.
Ukázková uživatelská licence řidiče zpracovaná pomocí nástroje Ukázkové popisování:
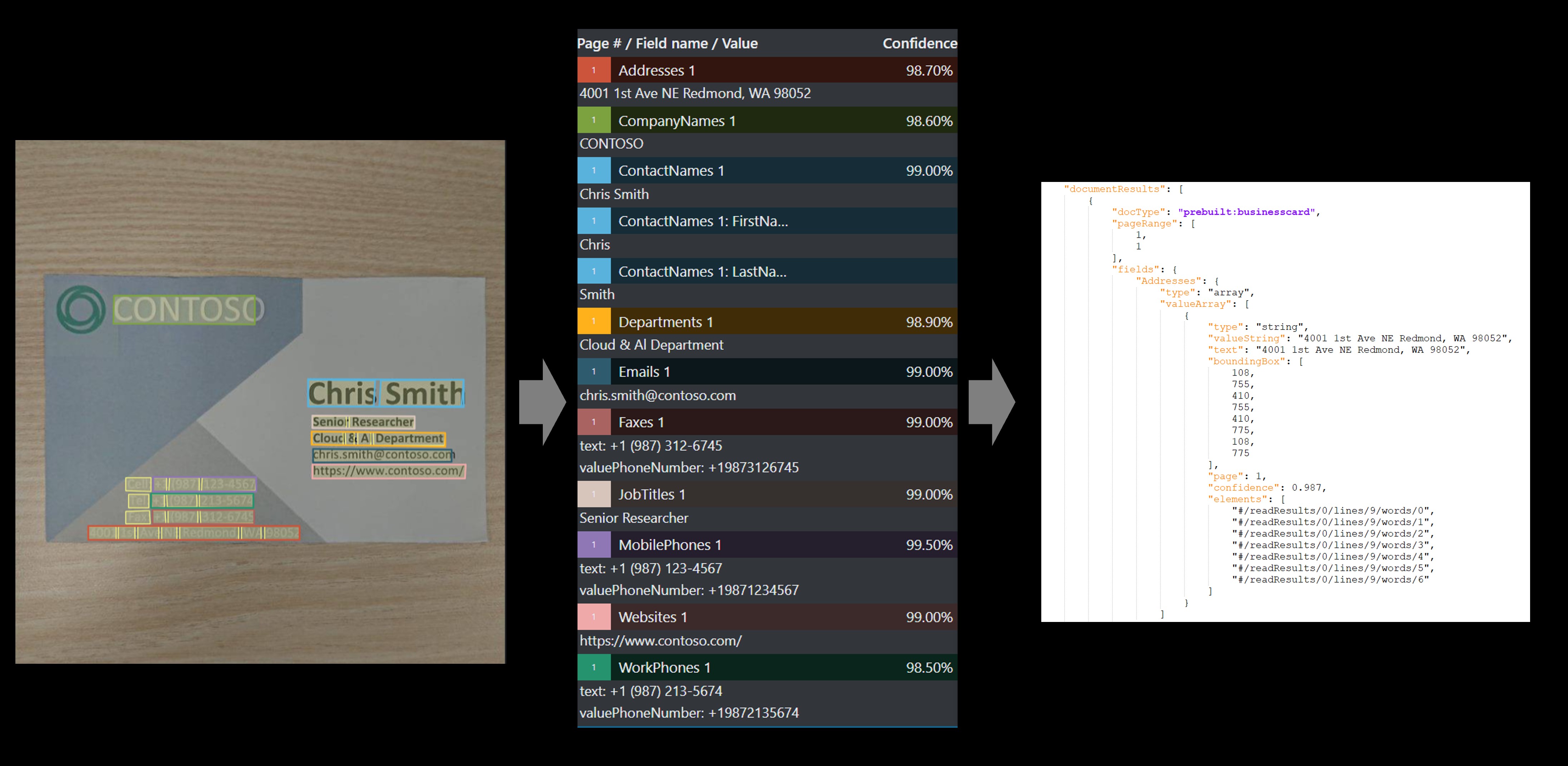
Vizitka
Model vizitek analyzuje a extrahuje klíčové informace z obrázků vizitek.
Ukázková vizitka zpracovaná pomocí nástroje Ukázkový popisek:
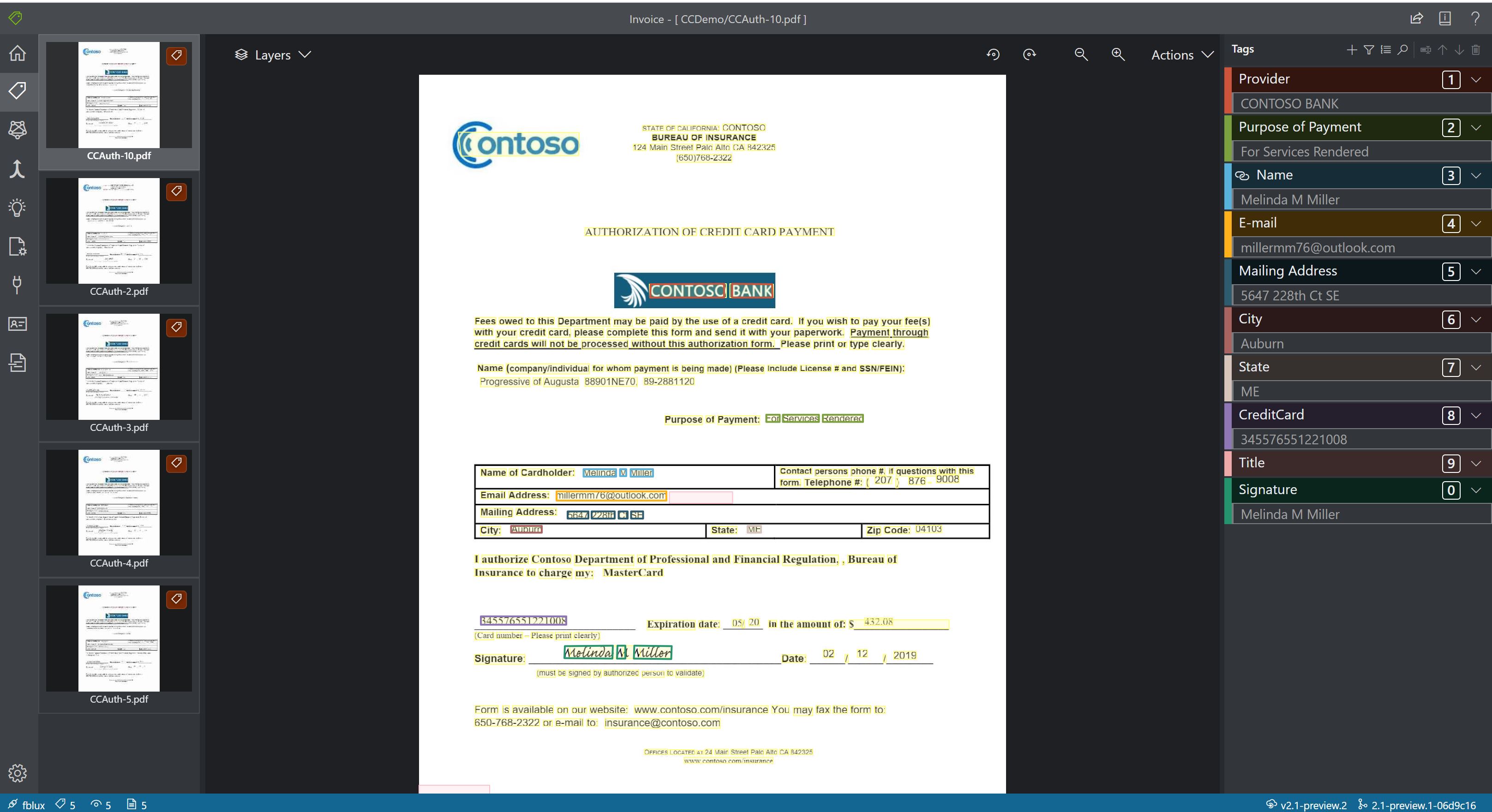
Vlastní
- Vlastní modely analyzují a extrahují data z formulářů a dokumentů specifických pro vaši firmu. Rozhraní API je program strojového učení natrénovaný tak, aby rozpoznal pole formulářů v rámci vašeho jedinečného obsahu a extrahoval páry klíč-hodnota a data tabulek. Abyste mohli začít, potřebujete jenom pět příkladů stejného typu formuláře a vlastní model můžete trénovat pomocí datových sad označených nebo bez popisků.
Ukázkové vlastní zpracování modelu pomocí nástroje Sample Labeling:
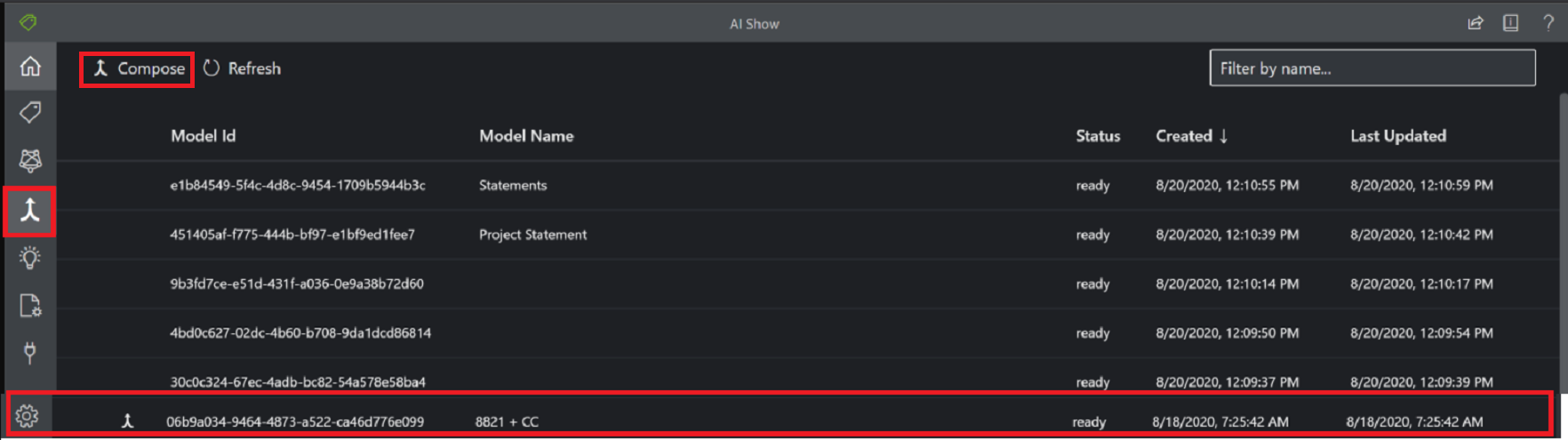
Složený vlastní model
Složený model se vytvoří tak, že vezme kolekci vlastních modelů a přiřadí je k jednomu modelu vytvořenému z vašich typů formulářů. Můžete přiřadit více vlastních modelů složeným modelům volaným s jedním ID modelu. K jednomu složenému modelu je možné přiřadit až 100 natrénovaných vlastních modelů.
Okno dialogového okna Složený model pomocí nástroje Ukázkové popisky:
Extrakce dat modelu
| Model | Extrakce textu | Detekce jazyka | Značky výběru | Tabulky | Odstavce | Role odstavce | Páry klíč-hodnota | Pole |
|---|---|---|---|---|---|---|---|---|
| Rozložení | ✓ | ✓ | ✓ | ✓ | ✓ | |||
| Faktura | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| Příjmu | ✓ | ✓ | ✓ | |||||
| Dokument ID | ✓ | ✓ | ✓ | |||||
| Vizitka | ✓ | ✓ | ✓ | |||||
| Vlastní formulář | ✓ | ✓ | ✓ | ✓ | ✓ |
Požadavky na vstup
Nejlepšíchvýsledkůch
Podporované formáty souborů:
Model PDF Obrázek:
JPEG/JPG, PNG, BMP, TIFF, HEIFsystém Microsoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX) a HTMLČteno ✔ ✔ ✔ Rozložení ✔ ✔ ✔ (2024-02-29-preview, 2023-10-31-preview) Obecný dokument ✔ ✔ Předpřipravený ✔ ✔ Vlastní extrakce ✔ ✔ Vlastní klasifikace ✔ ✔ ✔ (29. 2024. 2024) U SOUBORŮ PDF a TIFF je možné zpracovat až 2000 stránek (s předplatným úrovně Free se zpracovávají pouze první dvě stránky).
Velikost souboru pro analýzu dokumentů je 500 MB pro placenou úroveň (S0) a 4 MB pro bezplatnou úroveň (F0).
Rozměry obrázku musí být mezi 50 x 50 pixelů a 10 000 px x 10 000 pixelů.
Pokud jsou soubory PDF uzamčené heslem, musíte před odesláním toto uzamčení odebrat.
Minimální výška extrahovaného textu je 12 pixelů pro obrázek o velikosti 1024 x 768 pixelů. Tato dimenze odpovídá
8150 bodům na palec (DPI).Pro trénování vlastního modelu je maximální počet stránek pro trénovací data 500 pro vlastní model šablony a 50 000 pro vlastní neurální model.
Pro trénování vlastního modelu extrakce je celková velikost trénovacích dat 50 MB pro model šablony a 1G MB pro neurální model.
Pro trénování modelu vlastní klasifikace je
1GBcelková velikost trénovacích dat s maximálně 10 000 stránkami.
Poznámka:
Nástroj Sample Labeling nepodporuje formát souboru BMP. Jedná se o omezení nástroje, nikoli služby Document Intelligence.
Migrace verzí
Informace o používání funkce Document Intelligence v3.0 ve vašich aplikacích najdete v našem průvodci migrací Document Intelligence v3.1.
Další kroky
Zkuste pomocí nástroje Document Intelligence Studio zpracovat vlastní formuláře a dokumenty.
Dokončete rychlý start s funkcí Document Intelligence a začněte vytvářet aplikaci pro zpracování dokumentů ve zvoleném vývojovém jazyce.
Zkuste zpracovat vlastní formuláře a dokumenty pomocí nástroje Document Intelligence Sample Labeling.
Dokončete rychlý start s funkcí Document Intelligence a začněte vytvářet aplikaci pro zpracování dokumentů ve zvoleném vývojovém jazyce.