Přesun dat do clusteru vFXT – paralelní příjem dat
Po vytvoření nového clusteru vFXT může být vaším prvním úkolem přesun dat na nový svazek úložiště v Azure. Pokud ale obvyklá metoda přesunu dat vydává jednoduchý příkaz pro kopírování z jednoho klienta, pravděpodobně se zobrazí nízký výkon kopírování. Kopírování s jedním vláknem není dobrou volbou pro kopírování dat do back-endového úložiště clusteru Avere vFXT.
Vzhledem k tomu, že Avere vFXT pro cluster Azure je škálovatelná mezipaměť s více klienty, nejrychlejším a nejúčinnějším způsobem kopírování dat do něj je více klientů. Tato technika paralelizuje příjem dat souborů a objektů.
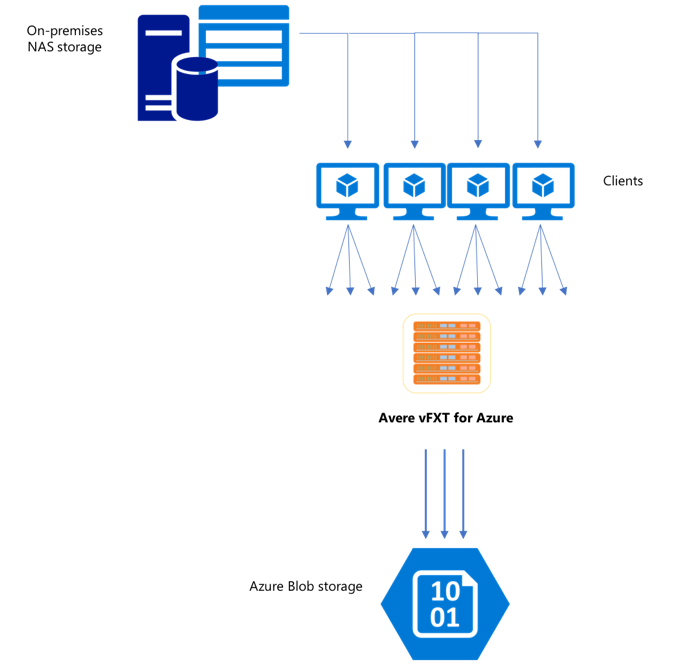
copy Příkazycp, které se běžně používají k přenosu dat z jednoho systému úložiště do jiného, jsou procesy s jedním vláknem, které kopírují jenom jeden soubor najednou. To znamená, že souborový server ingestuje pouze jeden soubor najednou – což je plýtvání prostředky clusteru.
Tento článek vysvětluje strategie pro vytvoření systému kopírování souborů s více vlákny s více vlákny pro přesun dat do clusteru Avere vFXT. Vysvětluje koncepty přenosu souborů a rozhodovací body, které je možné použít k efektivnímu kopírování dat pomocí více klientů a jednoduchých příkazů kopírování.
Vysvětluje také některé nástroje, které můžou pomoct. Nástroj msrsync lze použít k částečné automatizaci procesu rozdělení datové sady do kontejnerů a použití rsync příkazů. Skript parallelcp je další nástroj, který čte zdrojový adresář a vydává příkazy kopírování automaticky. rsync Nástroj lze také použít ve dvou fázích k zajištění rychlejší kopie, která stále poskytuje konzistenci dat.
Kliknutím na odkaz přejdete na oddíl:
- Příklad ručního kopírování – důkladné vysvětlení pomocí příkazů pro kopírování
- Příklad dvoufázové synchronizace rsync
- Příklad částečně automatizovaného (msrsync)
- Příklad paralelního kopírování
Šablona virtuálního počítače ingestoru dat
Šablona Resource Manageru je k dispozici na GitHubu k automatickému vytvoření virtuálního počítače pomocí nástrojů pro paralelní příjem dat uvedených v tomto článku.
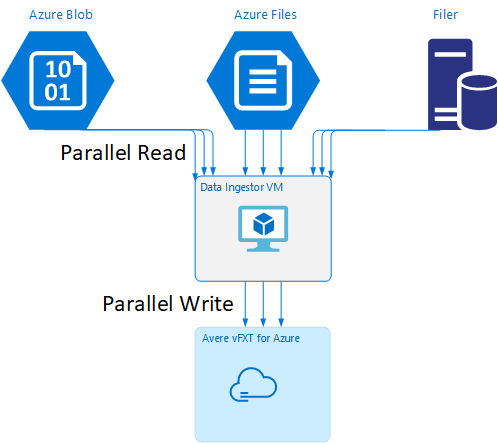
Virtuální počítač ingestor dat je součástí kurzu, ve kterém nově vytvořený virtuální počítač připojí cluster Avere vFXT a stáhne svůj spouštěcí skript z clusteru. Podrobnosti najdete v souboru Bootstrap a data ingestor virtuálního počítače .
Strategické plánování
Při návrhu strategie pro paralelní kopírování dat byste měli porozumět kompromisům ve velikosti souboru, počtu souborů a hloubkách adresáře.
- Pokud jsou soubory malé, metrika zájmu je soubory za sekundu.
- Pokud jsou soubory velké (10MiBi nebo vyšší), metrika zájmu je bajty za sekundu.
Každý proces kopírování má rychlost propustnosti a rychlost přenosu souborů, kterou je možné měřit načasováním příkazu kopírování a faktorem velikosti souboru a počtu souborů. Vysvětlení způsobu měření sazeb je mimo rozsah tohoto dokumentu, ale je důležité pochopit, jestli budete řešit malé nebo velké soubory.
Příklad ručního kopírování
V klientovi můžete ručně vytvořit vícevláknovou kopii spuštěním více příkazů kopírování najednou na pozadí s předdefinovanými sadami souborů nebo cest.
Příkaz Linux/systém UNIX cp obsahuje argument -p pro zachování vlastnictví a metadat mtime. Přidání tohoto argumentu do níže uvedených příkazů je volitelné. (Přidání argumentu zvyšuje počet volání systému souborů odesílaných z klienta do cílového systému souborů pro úpravy metadat.)
Tento jednoduchý příklad paralelně zkopíruje dva soubory:
cp /mnt/source/file1 /mnt/destination1/ & cp /mnt/source/file2 /mnt/destination1/ &
Po vydání tohoto příkazu jobs příkaz zobrazí, že jsou spuštěna dvě vlákna.
Předvídatelná struktura názvu souboru
Pokud jsou názvy souborů předvídatelné, můžete pomocí výrazů vytvořit paralelní vlákna kopírování.
Pokud například adresář obsahuje 1 000 souborů, které jsou očíslovány postupně od 0001 do 1000, můžete pomocí následujících výrazů vytvořit deset paralelních vláken, které každý kopíruje 100 souborů:
cp /mnt/source/file0* /mnt/destination1/ & \
cp /mnt/source/file1* /mnt/destination1/ & \
cp /mnt/source/file2* /mnt/destination1/ & \
cp /mnt/source/file3* /mnt/destination1/ & \
cp /mnt/source/file4* /mnt/destination1/ & \
cp /mnt/source/file5* /mnt/destination1/ & \
cp /mnt/source/file6* /mnt/destination1/ & \
cp /mnt/source/file7* /mnt/destination1/ & \
cp /mnt/source/file8* /mnt/destination1/ & \
cp /mnt/source/file9* /mnt/destination1/
Neznámá struktura názvu souboru
Pokud struktura pojmenování souborů není předvídatelná, můžete soubory seskupit podle názvů adresářů.
Tento příklad shromažďuje celé adresáře, které se posílají příkazům cp spustit jako úlohy na pozadí:
/root
|-/dir1
| |-/dir1a
| |-/dir1b
| |-/dir1c
|-/dir1c1
|-/dir1d
Po shromáždění souborů můžete spustit příkazy paralelního kopírování, které rekurzivně zkopírují podadresáře a veškerý jejich obsah:
cp /mnt/source/* /mnt/destination/
mkdir -p /mnt/destination/dir1 && cp /mnt/source/dir1/* mnt/destination/dir1/ &
cp -R /mnt/source/dir1/dir1a /mnt/destination/dir1/ &
cp -R /mnt/source/dir1/dir1b /mnt/destination/dir1/ &
cp -R /mnt/source/dir1/dir1c /mnt/destination/dir1/ & # this command copies dir1c1 via recursion
cp -R /mnt/source/dir1/dir1d /mnt/destination/dir1/ &
Kdy přidat přípojné body
Jakmile budete mít dostatek paralelních vláken směřujících na jeden přípojný bod systému souborů, bude existovat bod, kdy přidání dalších vláken neposkytuje větší propustnost. (Propustnost se bude měřit v souborech, sekundách nebo bajtech za sekundu v závislosti na typu dat.) Nebo horší může snížení propustnosti způsobit nadměrné podprocesy.
V takovém případě můžete přidat přípojné body na straně klienta do jiných IP adres clusteru vFXT pomocí stejné cesty připojení systému souborů:
10.1.0.100:/nfs on /mnt/sourcetype nfs (rw,vers=3,proto=tcp,addr=10.1.0.100)
10.1.1.101:/nfs on /mnt/destination1type nfs (rw,vers=3,proto=tcp,addr=10.1.1.101)
10.1.1.102:/nfs on /mnt/destination2type nfs (rw,vers=3,proto=tcp,addr=10.1.1.102)
10.1.1.103:/nfs on /mnt/destination3type nfs (rw,vers=3,proto=tcp,addr=10.1.1.103)
Přidáním přípojných bodů na straně klienta můžete zvětšovat další příkazy kopírování do dalších /mnt/destination[1-3] přípojných bodů a dosáhnout dalšího paralelismu.
Pokud jsou například vaše soubory velmi velké, můžete definovat příkazy kopírování pro použití odlišných cílových cest, paralelní odesílání dalších příkazů z klienta provádějícího kopírování.
cp /mnt/source/file0* /mnt/destination1/ & \
cp /mnt/source/file1* /mnt/destination2/ & \
cp /mnt/source/file2* /mnt/destination3/ & \
cp /mnt/source/file3* /mnt/destination1/ & \
cp /mnt/source/file4* /mnt/destination2/ & \
cp /mnt/source/file5* /mnt/destination3/ & \
cp /mnt/source/file6* /mnt/destination1/ & \
cp /mnt/source/file7* /mnt/destination2/ & \
cp /mnt/source/file8* /mnt/destination3/ & \
V předchozím příkladu jsou všechny tři cílové přípojné body cílem procesy kopírování klientského souboru.
Kdy přidat klienty
Pokud jste dosáhli schopností klienta, přidání dalších vláken kopírování nebo dalších přípojných bodů nezvýší žádné další soubory za sekundu ani bajty za sekundu. V takovém případě můžete nasadit dalšího klienta se stejnou sadou přípojných bodů, na kterých budou spuštěny vlastní sady procesů kopírování souborů.
Příklad:
Client1: cp -R /mnt/source/dir1/dir1a /mnt/destination/dir1/ &
Client1: cp -R /mnt/source/dir2/dir2a /mnt/destination/dir2/ &
Client1: cp -R /mnt/source/dir3/dir3a /mnt/destination/dir3/ &
Client2: cp -R /mnt/source/dir1/dir1b /mnt/destination/dir1/ &
Client2: cp -R /mnt/source/dir2/dir2b /mnt/destination/dir2/ &
Client2: cp -R /mnt/source/dir3/dir3b /mnt/destination/dir3/ &
Client3: cp -R /mnt/source/dir1/dir1c /mnt/destination/dir1/ &
Client3: cp -R /mnt/source/dir2/dir2c /mnt/destination/dir2/ &
Client3: cp -R /mnt/source/dir3/dir3c /mnt/destination/dir3/ &
Client4: cp -R /mnt/source/dir1/dir1d /mnt/destination/dir1/ &
Client4: cp -R /mnt/source/dir2/dir2d /mnt/destination/dir2/ &
Client4: cp -R /mnt/source/dir3/dir3d /mnt/destination/dir3/ &
Vytváření manifestů souborů
Po pochopení výše uvedených přístupů (více vláken kopírování na cíl, více cílů na klienta, více klientů na zdrojový systém souborů s podporou sítě), zvažte toto doporučení: Sestavení manifestů souborů a jejich následné použití s příkazy kopírování napříč více klienty.
Tento scénář používá příkaz systém UNIX find k vytvoření manifestů souborů nebo adresářů:
user@build:/mnt/source > find . -mindepth 4 -maxdepth 4 -type d
./atj5b55c53be6-01/support/gsi/2018-07-22T21:12:06EDT
./atj5b55c53be6-01/support/pcap/2018-07-23T01:34:57UTC
./atj5b55c53be6-01/support/trace/rolling
./atj5b55c53be6-03/support/gsi/2018-07-22T21:12:06EDT
./atj5b55c53be6-03/support/pcap/2018-07-23T01:34:57UTC
./atj5b55c53be6-03/support/trace/rolling
./atj5b55c53be6-02/support/gsi/2018-07-22T21:12:06EDT
./atj5b55c53be6-02/support/pcap/2018-07-23T01:34:57UTC
./atj5b55c53be6-02/support/trace/rolling
Přesměrujte tento výsledek na soubor: find . -mindepth 4 -maxdepth 4 -type d > /tmp/foo
Pak můžete iterovat manifest pomocí příkazů BASH ke zjištění počtu souborů a určení velikostí podadresářů:
ben@xlcycl1:/sps/internal/atj5b5ab44b7f > for i in $(cat /tmp/foo); do echo " `find ${i} |wc -l` `du -sh ${i}`"; done
244 3.5M ./atj5b5ab44b7f-02/support/gsi/2018-07-18T00:07:03EDT
9 172K ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-18T05:01:00UTC
124 5.8M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-19T01:01:01UTC
152 15M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-20T01:01:00UTC
131 13M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-20T21:59:41UTC_partial
789 6.2M ./atj5b5ab44b7f-02/support/gsi/2018-07-20T21:59:41UTC
134 12M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-20T22:22:55UTC_vfxt_catchup
7 16K ./atj5b5ab44b7f-02/support/pcap/2018-07-18T17:12:19UTC
8 83K ./atj5b5ab44b7f-02/support/pcap/2018-07-18T17:17:17UTC
575 7.7M ./atj5b5ab44b7f-02/support/cores/armada_main.2000.1531980253.gsi
33 4.4G ./atj5b5ab44b7f-02/support/trace/rolling
281 6.6M ./atj5b5ab44b7f-01/support/gsi/2018-07-18T00:07:03EDT
15 182K ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-18T05:01:00UTC
244 17M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-19T01:01:01UTC
299 31M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-20T01:01:00UTC
256 29M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-20T21:59:41UTC_partial
889 7.7M ./atj5b5ab44b7f-01/support/gsi/2018-07-20T21:59:41UTC
262 29M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-20T22:22:55UTC_vfxt_catchup
11 248K ./atj5b5ab44b7f-01/support/pcap/2018-07-18T17:12:19UTC
11 88K ./atj5b5ab44b7f-01/support/pcap/2018-07-18T17:17:17UTC
645 11M ./atj5b5ab44b7f-01/support/cores/armada_main.2019.1531980253.gsi
33 4.0G ./atj5b5ab44b7f-01/support/trace/rolling
244 2.1M ./atj5b5ab44b7f-03/support/gsi/2018-07-18T00:07:03EDT
9 158K ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-18T05:01:00UTC
124 5.3M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-19T01:01:01UTC
152 15M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-20T01:01:00UTC
131 12M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-20T21:59:41UTC_partial
789 8.4M ./atj5b5ab44b7f-03/support/gsi/2018-07-20T21:59:41UTC
134 14M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-20T22:25:58UTC_vfxt_catchup
7 159K ./atj5b5ab44b7f-03/support/pcap/2018-07-18T17:12:19UTC
7 157K ./atj5b5ab44b7f-03/support/pcap/2018-07-18T17:17:17UTC
576 12M ./atj5b5ab44b7f-03/support/cores/armada_main.2013.1531980253.gsi
33 2.8G ./atj5b5ab44b7f-03/support/trace/rolling
Nakonec musíte pro klienty vytvořit skutečné příkazy pro kopírování souborů.
Pokud máte čtyři klienty, použijte tento příkaz:
for i in 1 2 3 4 ; do sed -n ${i}~4p /tmp/foo > /tmp/client${i}; done
Pokud máte pětklientůch
for i in 1 2 3 4 5; do sed -n ${i}~5p /tmp/foo > /tmp/client${i}; done
A pro šest.... Extrapolovat podle potřeby.
for i in 1 2 3 4 5 6; do sed -n ${i}~6p /tmp/foo > /tmp/client${i}; done
Zobrazí se výsledné soubory N , jeden pro každého klienta N , který má názvy cest k adresářům úrovně čtyři získané jako součást výstupu find příkazu.
Pomocí každého souboru sestavte příkaz pro kopírování:
for i in 1 2 3 4 5 6; do for j in $(cat /tmp/client${i}); do echo "cp -p -R /mnt/source/${j} /mnt/destination/${j}" >> /tmp/client${i}_copy_commands ; done; done
Výše uvedené soubory vám poskytnou N soubory, každý s příkazem pro kopírování na řádek, který lze spustit jako skript BASH v klientovi.
Cílem je souběžně spouštět více vláken těchto skriptů na jednotlivých klientech paralelně na více klientech.
Použití dvoufázového procesu rsync
Standardní rsync nástroj nefunguje dobře pro naplnění cloudového úložiště prostřednictvím Avere vFXT pro systém Azure, protože generuje velký počet operací vytváření a přejmenování souborů, aby se zajistila integrita dat. Pokud ale použijete druhé spuštění, které kontroluje integritu souboru, můžete tuto možnost rsync bezpečně --inplace přeskočit.
Standardní rsync operace kopírování vytvoří dočasný soubor a vyplní ho daty. Pokud se přenos dat úspěšně dokončí, dočasný soubor se přejmenuje na původní název souboru. Tato metoda zaručuje konzistenci i v případě, že se k souborům přistupuje během kopírování. Tato metoda ale generuje více operací zápisu, což zpomaluje přesouvání souborů v mezipaměti.
Možnost --inplace zapíše nový soubor přímo do konečného umístění. Soubory nejsou zaručeny konzistentní během přenosu, ale to není důležité, pokud vytváříte systém úložiště pro pozdější použití.
Druhá rsync operace slouží jako kontrola konzistence u první operace. Vzhledem k tomu, že se soubory už zkopírovaly, druhá fáze je rychlá kontrola, která zajistí, aby soubory v cíli odpovídaly souborům ve zdroji. Pokud se některé soubory neshodují, jsou recopied.
Obě fáze můžete vydávat společně v jednom příkazu:
rsync -azh --inplace <source> <destination> && rsync -azh <source> <destination>
Tato metoda je jednoduchá a časově efektivní metoda pro datové sady až do počtu souborů, které může interní správce adresářů zpracovat. (Obvykle se jedná o 200 milionů souborů pro cluster se 3 uzly, 500 milionů souborů pro cluster se šesti uzly atd.)
Použití nástroje msrsync
Tento msrsync nástroj lze také použít k přesunu dat do back-endového základního fileru clusteru Avere. Tento nástroj je navržený tak, aby optimalizoval využití šířky pásma spuštěním několika paralelních rsync procesů. Je k dispozici na GitHubu na adrese https://github.com/jbd/msrsync.
msrsync rozdělí zdrojový adresář do samostatných kontejnerů a pak spustí jednotlivé rsync procesy v každém kontejneru.
Předběžné testování pomocí čtyřjádrových virtuálních počítačů ukázalo nejlepší efektivitu při použití 64 procesů. msrsync Pomocí možnosti -p nastavte počet procesů na 64.
Argument můžete použít --inplace také s msrsync příkazy. Pokud použijete tuto možnost, zvažte spuštění druhého příkazu (stejně jako u rsync, popsaného výše), abyste zajistili integritu dat.
msrsync může zapisovat pouze do místních svazků a z místních svazků. Zdroj a cíl musí být přístupné jako místní připojení ve virtuální síti clusteru.
Pokud chcete použít msrsync k naplnění cloudového svazku Azure clusterem Avere, postupujte podle těchto pokynů:
Instalace
msrsynca požadavky (rsync a Python 2.6 nebo novější)Určete celkový počet souborů a adresářů, které se mají zkopírovat.
Například použijte nástroj
prime.pyAvere s argumentyprime.py --directory /path/to/some/directory(k dispozici stažením adresy URL https://github.com/Azure/Avere/blob/master/src/clientapps/dataingestor/prime.py).Pokud nepoužíváte
prime.py, můžete vypočítat počet položek pomocí nástroje GNUfindnásledujícím způsobem:find <path> -type f |wc -l # (counts files) find <path> -type d |wc -l # (counts directories) find <path> |wc -l # (counts both)Vydělte počet položek číslem 64 a určete počet položek na proces. Toto číslo použijte s
-fmožností nastavit velikost kbelíků při spuštění příkazu.msrsyncZadejte příkaz pro kopírování souborů:msrsync -P --stats -p 64 -f <ITEMS_DIV_64> --rsync "-ahv" <SOURCE_PATH> <DESTINATION_PATH>Pokud používáte
--inplace, přidejte druhé spuštění bez možnosti, abyste zkontrolovali, že se data správně zkopírují:msrsync -P --stats -p 64 -f <ITEMS_DIV_64> --rsync "-ahv --inplace" <SOURCE_PATH> <DESTINATION_PATH> && msrsync -P --stats -p 64 -f <ITEMS_DIV_64> --rsync "-ahv" <SOURCE_PATH> <DESTINATION_PATH>Tento příkaz je například navržený tak, aby přesunul 11 000 souborů v 64 procesech z /test/source-repository do /mnt/vfxt/repository:
msrsync -P --stats -p 64 -f 170 --rsync "-ahv --inplace" /test/source-repository/ /mnt/vfxt/repository && msrsync -P --stats -p 64 -f 170 --rsync "-ahv --inplace" /test/source-repository/ /mnt/vfxt/repository
Použití skriptu paralelního kopírování
Skript parallelcp může být užitečný také pro přesun dat do back-endového úložiště clusteru vFXT.
Následující skript přidá spustitelný soubor parallelcp. (Tento skript je určený pro Ubuntu; pokud používáte jinou distribuci, musíte nainstalovat parallel samostatně.)
sudo touch /usr/bin/parallelcp && sudo chmod 755 /usr/bin/parallelcp && sudo sh -c "/bin/cat >/usr/bin/parallelcp" <<EOM
#!/bin/bash
display_usage() {
echo -e "\nUsage: \$0 SOURCE_DIR DEST_DIR\n"
}
if [ \$# -le 1 ] ; then
display_usage
exit 1
fi
if [[ ( \$# == "--help") || \$# == "-h" ]] ; then
display_usage
exit 0
fi
SOURCE_DIR="\$1"
DEST_DIR="\$2"
if [ ! -d "\$SOURCE_DIR" ] ; then
echo "Source directory \$SOURCE_DIR does not exist, or is not a directory"
display_usage
exit 2
fi
if [ ! -d "\$DEST_DIR" ] && ! mkdir -p \$DEST_DIR ; then
echo "Destination directory \$DEST_DIR does not exist, or is not a directory"
display_usage
exit 2
fi
if [ ! -w "\$DEST_DIR" ] ; then
echo "Destination directory \$DEST_DIR is not writeable, or is not a directory"
display_usage
exit 3
fi
if ! which parallel > /dev/null ; then
sudo apt-get update && sudo apt install -y parallel
fi
DIRJOBS=225
JOBS=225
find \$SOURCE_DIR -mindepth 1 -type d -print0 | sed -z "s/\$SOURCE_DIR\///" | parallel --will-cite -j\$DIRJOBS -0 "mkdir -p \$DEST_DIR/{}"
find \$SOURCE_DIR -mindepth 1 ! -type d -print0 | sed -z "s/\$SOURCE_DIR\///" | parallel --will-cite -j\$JOBS -0 "cp -P \$SOURCE_DIR/{} \$DEST_DIR/{}"
EOM
Příklad paralelního kopírování
Tento příklad používá skript paralelního kopírování ke kompilaci glibc pomocí zdrojových souborů z clusteru Avere.
Zdrojové soubory jsou uloženy v přípojném bodu clusteru Avere a soubory objektů jsou uloženy na místním pevném disku.
Tento skript používá výše uvedený paralelní skript kopírování. Tato možnost -j se používá s parallelcp a make k získání paralelizace.
sudo apt-get update
sudo apt install -y gcc bison gcc binutils make parallel
cd
wget https://mirrors.kernel.org/gnu/libc/glibc-2.27.tar.bz2
tar jxf glibc-2.27.tar.bz2
ln -s /nfs/node1 avere
time parallelcp glibc-2.27 avere/glibc-2.27
cd
mkdir obj
mkdir usr
cd obj
/home/azureuser/avere/glibc-2.27/configure --prefix=/home/azureuser/usr
time make -j