Návrh globálně dostupných služeb pomocí Azure SQL Database
Platí pro:![]() Azure SQL Database
Azure SQL Database
Při sestavování a nasazování cloudových služeb se službou Azure SQL Database používáte aktivní geografickou replikaci nebo skupiny převzetí služeb při selhání k zajištění odolnosti vůči oblastním výpadkům a katastrofickým selháním. Stejná funkce umožňuje vytvářet globálně distribuované aplikace optimalizované pro místní přístup k datům. Tento článek popisuje běžné vzory aplikací, včetně výhod a kompromisů jednotlivých možností.
Poznámka:
Pokud používáte databáze Premium nebo Pro důležité obchodní informace a elastické fondy, můžete je zajistit odolnost vůči oblastním výpadkům tak, že je převedete na zónově redundantní konfiguraci nasazení. Viz zónově redundantní databáze.
Scénář 1: Použití dvou oblastí Azure pro provozní kontinuitu s minimálními výpadky
V tomto scénáři mají aplikace následující charakteristiky:
- Aplikace je aktivní v jedné oblasti Azure
- Všechny databázové relace vyžadují přístup pro čtení a zápis (RW) k datům.
- Aby se snížily latence a náklady na provoz, musí být webové vrstvy a datové vrstvy kompletovány.
- V zásadě je výpadek pro tyto aplikace vyšší obchodní riziko než ztráta dat.
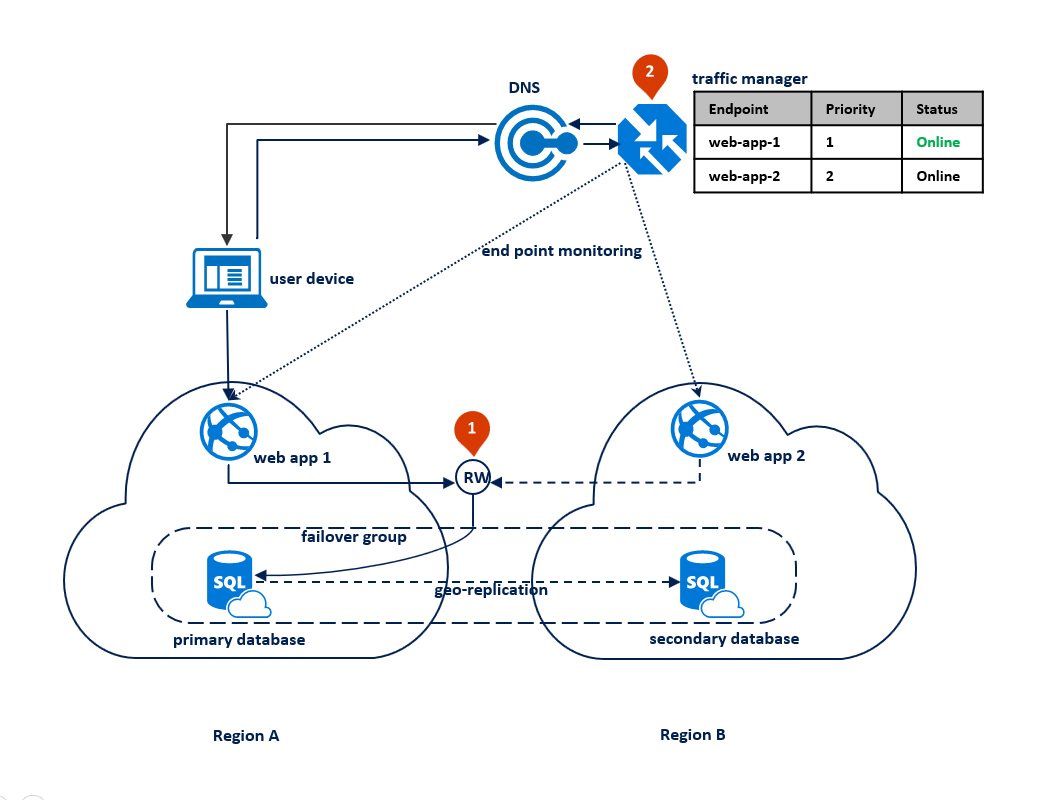
V tomto případě je topologie nasazení aplikace optimalizovaná pro zpracování regionálních havárií, když všechny komponenty aplikace potřebují převzít služby při selhání společně. Následující diagram znázorňuje tuto topologii. V případě geografické redundance se prostředky aplikace nasadí do oblasti A a B. Prostředky v oblasti B se však nevyužívají, dokud se oblast A nezdaří. Skupina převzetí služeb při selhání je nakonfigurovaná mezi dvěma oblastmi pro správu připojení k databázi, replikaci a převzetí služeb při selhání. Webová služba v obou oblastech je nakonfigurovaná pro přístup k databázi prostřednictvím naslouchacího procesu <čtení a zápisu s názvem skupiny.database.windows.net> (1). Azure Traffic Manager je nastavený tak, aby používal metodu směrování podle priority (2).
Poznámka:
Azure Traffic Manager se v tomto článku používá jenom pro ilustrace. Můžete použít jakékoli řešení vyrovnávání zatížení, které podporuje metodu směrování podle priority.
Následující diagram znázorňuje tuto konfiguraci před výpadkem:
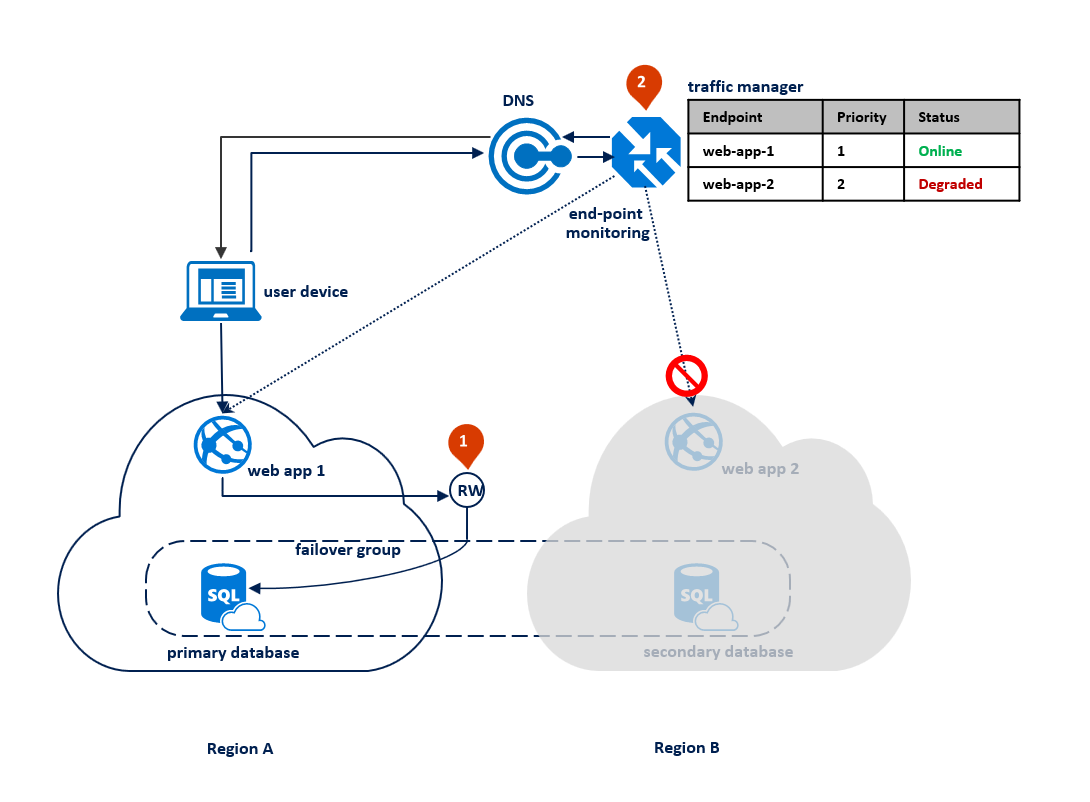
Po výpadku v primární oblasti služba SQL Database zjistí, že primární databáze není přístupná a aktivuje převzetí služeb při selhání sekundární oblasti na základě parametrů zásad automatického převzetí služeb při selhání (1). V závislosti na úrovni smlouvy SLA vaší aplikace můžete nakonfigurovat období odkladu, které řídí dobu mezi detekcí výpadku a samotným převzetím služeb při selhání. Je možné, že Azure Traffic Manager zahájí převzetí služeb při selhání koncového bodu předtím, než skupina převzetí služeb při selhání aktivuje převzetí služeb při selhání databáze. V takovém případě se webová aplikace nemůže okamžitě znovu připojit k databázi. Opětovné připojení se ale po dokončení převzetí služeb při selhání databáze automaticky dokončí. Když se oblast, která selhala, obnoví a znovu online, původní primární server se automaticky znovu připojí jako nová sekundární. Následující diagram znázorňuje konfiguraci po převzetí služeb při selhání.
Poznámka:
Během opětovného připojení dojde ke ztrátě všech transakcí potvrzených po převzetí služeb při selhání. Po dokončení převzetí služeb při selhání může aplikace v oblasti B znovu připojit a restartovat zpracování žádostí uživatelů. Webová aplikace i primární databáze jsou teď v oblasti B a zůstávají společně umístěné.
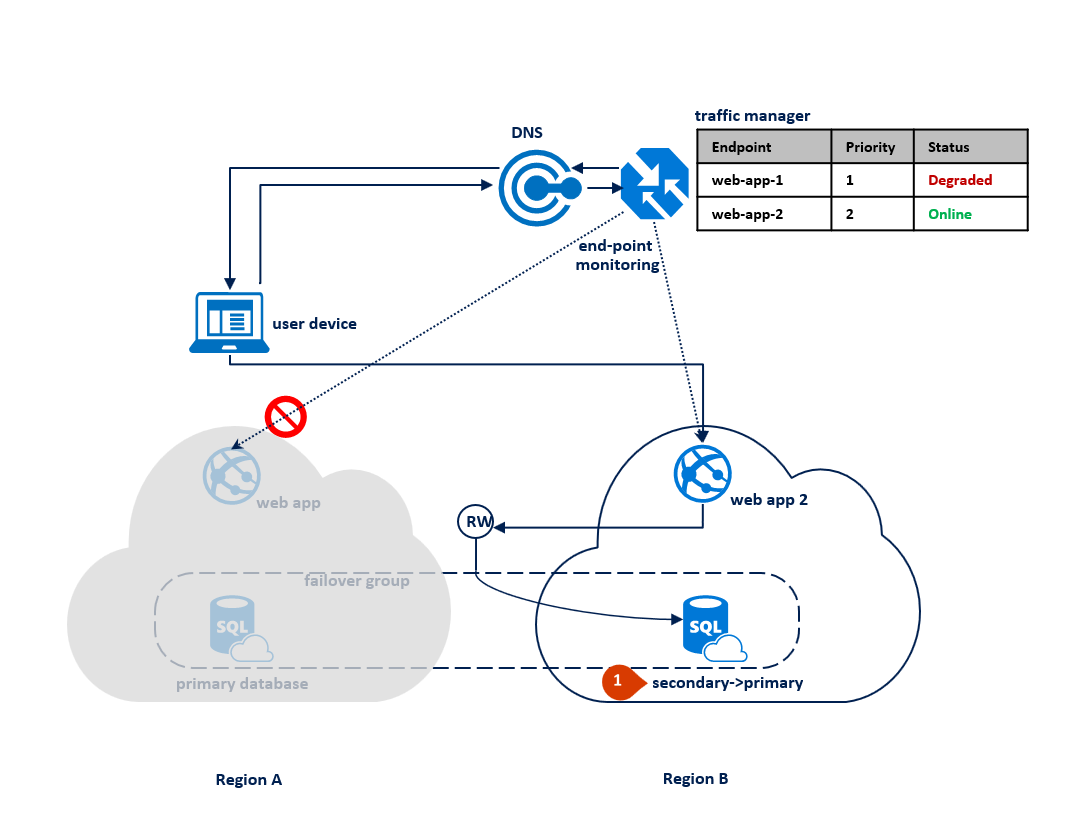
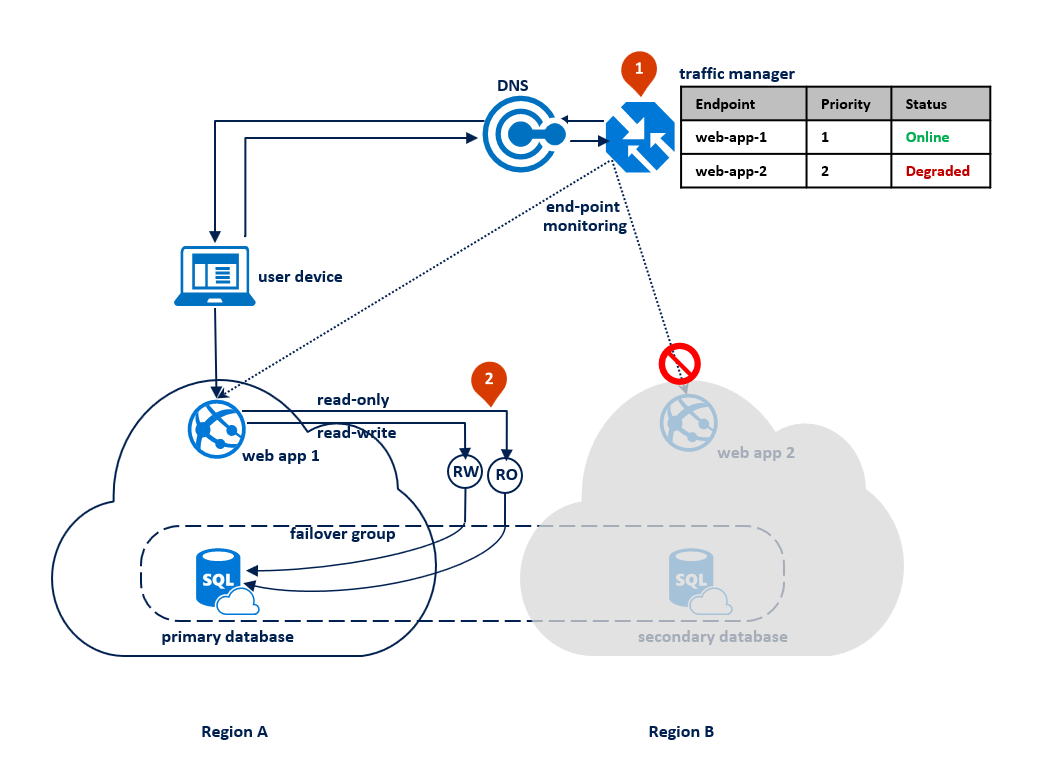
Pokud dojde k výpadku v oblasti B, proces replikace mezi primární a sekundární databází se pozastaví, ale propojení mezi nimi zůstane nedotčené (1). Traffic Manager zjistí, že připojení k oblasti B je poškozené a označí webovou aplikaci koncového bodu 2 jako degradovanou (2). Výkon aplikace není v tomto případě ovlivněn, ale databáze se zpřístupňuje a v případě selhání oblasti A dojde k vyššímu riziku ztráty dat.
Poznámka:
Pro zotavení po havárii doporučujeme konfiguraci s nasazením aplikace omezenou na dvě oblasti. Důvodem je to, že většina geografických oblastí Azure má pouze dvě oblasti. Tato konfigurace nechrání vaši aplikaci před souběžným katastrofickým selháním obou oblastí. V nepravděpodobném případě takového selhání můžete obnovit databáze ve třetí oblasti pomocí operace geografického obnovení. Další informace najdete v doprovodných materiálech k zotavení po havárii služby Azure SQL Database.
Jakmile dojde ke zmírnění výpadku, sekundární databáze se automaticky znovusynchronizuje s primární databází. Během synchronizace může dojít k ovlivnění výkonu primárního serveru. Konkrétní dopad závisí na množství dat, která nový primární server získal od převzetí služeb při selhání.
Poznámka:
Po zmírnění výpadku začne Traffic Manager směrovat připojení k aplikaci v oblasti A jako koncový bod s vyšší prioritou. Pokud máte v úmyslu zachovat primární oblast B nějakou dobu, měli byste odpovídajícím způsobem změnit tabulku priority v profilu Traffic Manageru.
Následující diagram znázorňuje výpadek v sekundární oblasti:
Mezi klíčové výhody tohoto vzoru návrhu patří:
- Stejná webová aplikace se nasadí do obou oblastí bez jakékoli konfigurace specifické pro konkrétní oblast a nevyžaduje další logiku pro správu převzetí služeb při selhání.
- Výkon aplikace není ovlivněn převzetím služeb při selhání, protože webová aplikace a databáze je vždy společně umístěná.
Hlavním kompromisem je, že prostředky aplikace v oblasti B jsou většinu času nedostatečně využité.
Scénář 2: Oblasti Azure pro zajištění provozní kontinuity s maximálním zachováním dat
Tato možnost je nejvhodnější pro aplikace s následujícími charakteristikami:
- Jakákoli ztráta dat je vysoká obchodní riziko. Převzetí služeb při selhání databáze se dá použít pouze jako poslední možnost, pokud je výpadek způsobený katastrofickým selháním.
- Aplikace podporuje režimy operací jen pro čtení a zápis a může pracovat v režimu jen pro čtení po určitou dobu.
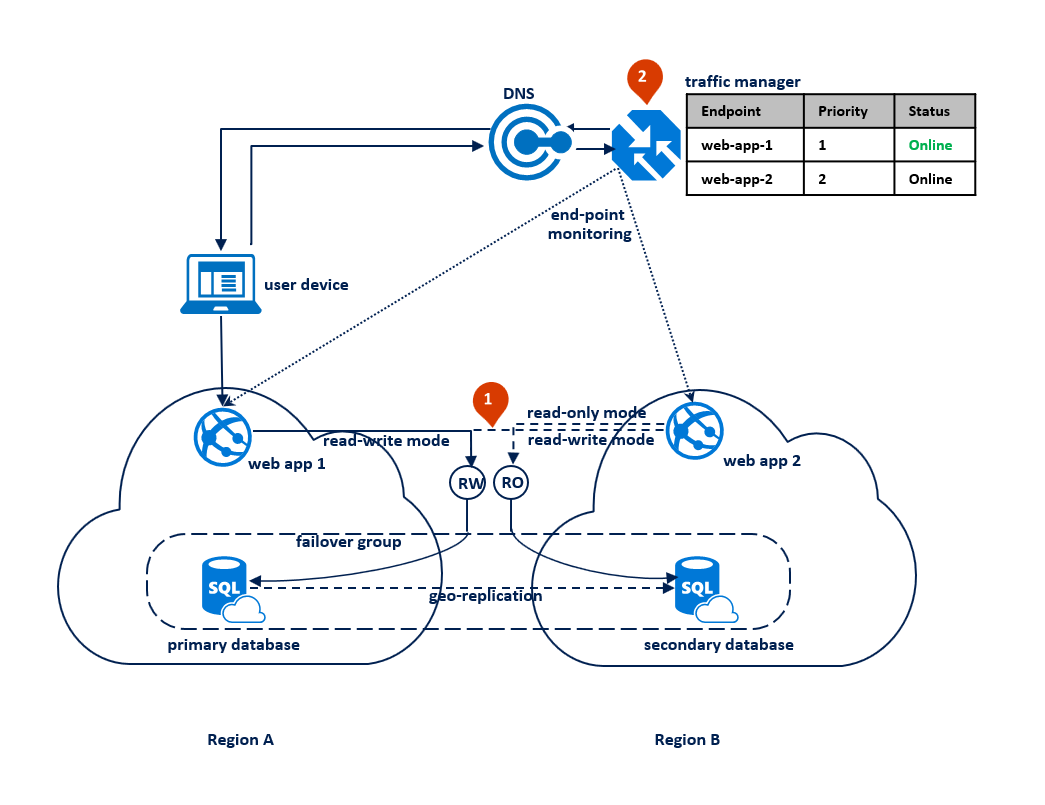
V tomto vzoru aplikace přepne do režimu jen pro čtení, když připojení pro čtení i zápis začnou dostávat chyby časového limitu. Webová aplikace se nasadí do obou oblastí a zahrnuje připojení ke koncovému bodu naslouchacího procesu pro čtení i zápis a k jinému připojení ke koncovému bodu naslouchacího procesu jen pro čtení (1). Profil Traffic Manageru by měl používat prioritní směrování. Monitorování koncových bodů by mělo být povolené pro koncový bod aplikace v každé oblasti (2).
Následující diagram znázorňuje tuto konfiguraci před výpadkem:
Když Traffic Manager zjistí selhání připojení k oblasti A, automaticky přepne uživatelský provoz do instance aplikace v oblasti B. U tohoto modelu je důležité nastavit období odkladu se ztrátou dat na dostatečně vysokou hodnotu, například 24 hodin. Zajišťuje, aby se ztrátě dat zabránilo, pokud dojde k omezení výpadku během této doby. Když je webová aplikace v oblasti B aktivována, operace čtení a zápisu selhávají. V tomto okamžiku by se měl přepnout do režimu jen pro čtení (1). V tomto režimu se požadavky automaticky směrují do sekundární databáze. Pokud je výpadek způsobený katastrofickým selháním, s největší pravděpodobností se nedá během období odkladu zmírnit. Když vyprší platnost skupiny převzetí služeb při selhání, aktivuje převzetí služeb při selhání. Potom bude k dispozici naslouchací proces pro čtení i zápis a připojení k němu přestanou selhát (2). Následující diagram znázorňuje dvě fáze procesu obnovení.
Poznámka:
Pokud dojde k výpadku v primární oblasti během období odkladu, Traffic Manager zjistí obnovení připojení v primární oblasti a přepne uživatelský provoz zpět do instance aplikace v oblasti A. Tato instance aplikace obnoví a funguje v režimu čtení a zápisu pomocí primární databáze v oblasti A, jak je znázorněno v předchozím diagramu.
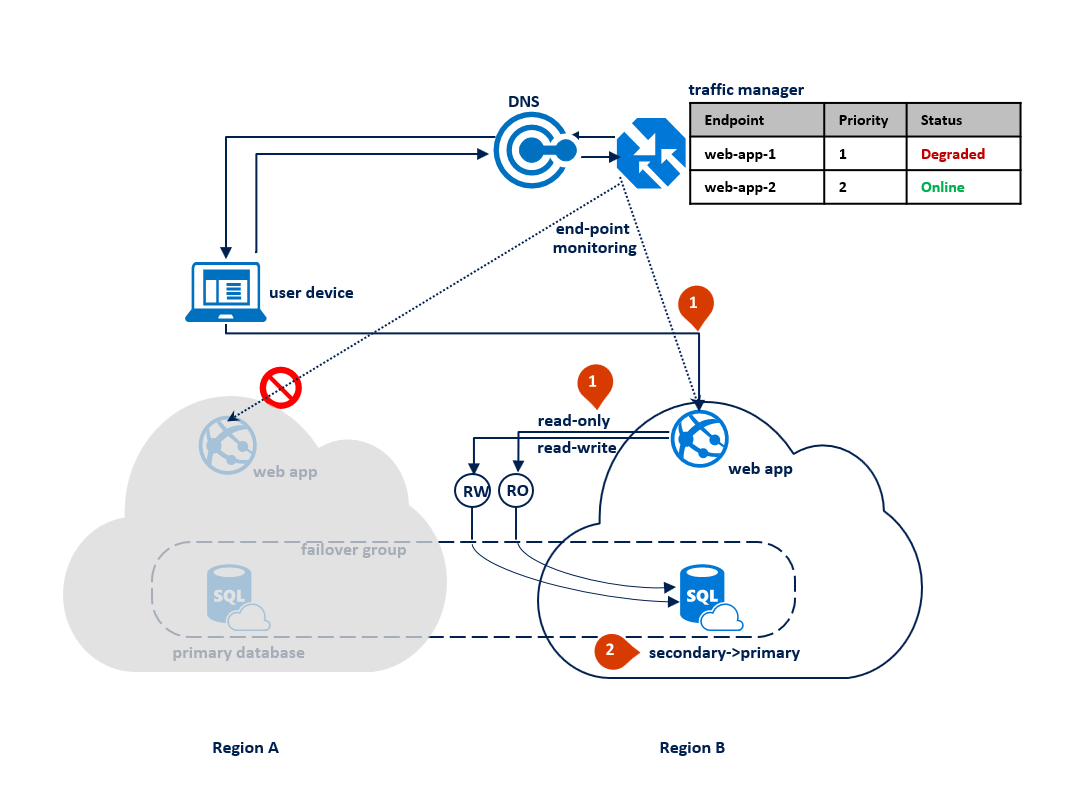
Pokud dojde k výpadku v oblasti B, Traffic Manager zjistí selhání webové aplikace koncového bodu v oblasti B a označí ji jako degradovanou (1). Mezitím skupina převzetí služeb při selhání přepne naslouchací proces jen pro čtení do oblasti A (2). Tento výpadek nemá vliv na prostředí koncového uživatele, ale během výpadku se zobrazí primární databáze. Následující diagram znázorňuje selhání v sekundární oblasti:
Po zmírnění výpadku se sekundární databáze okamžitě synchronizuje s primárním serverem a naslouchací proces jen pro čtení se přepne zpět do sekundární databáze v oblasti B. Během synchronizace primárního serveru může být mírně ovlivněno v závislosti na množství dat, která je potřeba synchronizovat.
Tento vzor návrhu má několik výhod:
- Zabrání ztrátě dat během dočasných výpadků.
- Výpadek závisí jenom na tom, jak rychle Traffic Manager zjistí selhání připojení, které je možné konfigurovat.
Nevýhodou je, že aplikace musí být schopná pracovat v režimu jen pro čtení.
Plánování provozní kontinuity: Volba návrhu aplikace pro zotavení po havárii cloudu
Vaše konkrétní strategie zotavení po havárii cloudu může kombinovat nebo rozšiřovat tyto vzory návrhu tak, aby co nejlépe splňovaly potřeby vaší aplikace. Jak už bylo zmíněno dříve, strategie, kterou zvolíte, vychází ze smlouvy SLA, kterou chcete zákazníkům nabídnout, a topologii nasazení aplikace. Následující tabulka vám pomůže při rozhodování porovnat volby na základě cíle bodu obnovení (RPO) a odhadované doby obnovení (ERT).
| Vzor | RPO | ERT |
|---|---|---|
| Aktivní-pasivní nasazení pro zotavení po havárii se spolusprávou přístupu k databázi | Přístup pro < čtení a zápis 5 sekund | Čas detekce selhání + hodnota TTL DNS |
| Nasazení aktivní-aktivní pro vyrovnávání zatížení aplikace | Přístup pro < čtení a zápis 5 sekund | Čas detekce selhání + hodnota TTL DNS |
| Aktivní-pasivní nasazení pro zachování dat | Přístup jen pro < čtení 5 sekund | Přístup jen pro čtení = 0 |
| Přístup pro čtení i zápis = nula | Přístup pro čtení a zápis = doba detekce selhání + období odkladu se ztrátou dat |
Další kroky
- Přehled a scénáře provozní kontinuity najdete v přehledu provozní kontinuity.
- Informace o aktivní geografické replikaci najdete v tématu Aktivní geografická replikace.
- Další informace o skupinách převzetí služeb při selhání najdete v tématu Skupiny převzetí služeb při selhání.
- Informace o aktivní geografické replikaci s elastickými fondy najdete v tématu Strategie zotavení po havárii elastického fondu.
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro