Jak vylepšit model Služby Custom Vision
V této příručce se dozvíte, jak zlepšit kvalitu modelu Custom Vision. Kvalita klasifikátoru nebo detektoru objektů závisí na množství, kvalitě a různých označených datech, která poskytnete, a na tom, jak vyvážená je celková datová sada. Dobrý model má vyváženou trénovací datovou sadu, která představuje, co se do ní odešle. Proces vytvoření takového modelu je iterativní; Je běžné, že trvá několik kol trénování, abyste dosáhli očekávaných výsledků.
Níže je obecný vzor, který vám pomůže vytrénovat přesnější model:
- První kolo školení
- Přidání dalších obrázků a vyvážení dat; Rekvalifikaci
- Přidejte obrázky s různým pozadím, osvětlením, velikostí objektu, úhlem fotoaparátu a stylem; Rekvalifikaci
- Použití nových obrázků k otestování předpovědi
- Úprava existujících trénovacích dat podle výsledků predikce
Zabránit přeurčení
Někdy se model naučí vytvářet předpovědi na základě libovolných charakteristik, které vaše obrázky mají společné. Pokud například vytváříte klasifikátor pro jablka vs. citrusy a použili jste obrázky jablek v rukou a citrusových plodů na bílých talířích, může klasifikátor dávat zbytečné důležitosti pro ruce vs. talíře, nikoli jablka vs. citrusy.
Chcete-li tento problém vyřešit, poskytněte obrázky s různými úhly, pozadími, velikostmi objektů, skupinami a dalšími variantami. V následujících částech jsou tyto koncepty rozšířeny.
Množství dat
Nejdůležitějším faktorem datové sady je počet trénovacích obrázků. Jako výchozí bod doporučujeme použít alespoň 50 obrázků na popisek. S menším počtem obrázků existuje vyšší riziko přeurčení a i když vaše čísla výkonu můžou navrhovat dobrou kvalitu, může váš model bojovat s daty z reálného světa.
Zůstatek dat
Je také důležité zvážit relativní množství trénovacích dat. Například použití 500 obrázků pro jeden popisek a 50 obrázků pro jiný popisek dělá nevyrovnanou trénovací datovou sadu. To způsobí, že model bude přesnější při předpovídání jednoho popisku než jiného. Pravděpodobně uvidíte lepší výsledky, pokud zachováte alespoň poměr 1:2 mezi popiskem s nejmenšími obrázky a popiskem s nejvíce obrázky. Pokud má například popisek s většinou obrázků 500 obrázků, měl by popisek s nejméně obrázky obsahovat alespoň 250 obrázků pro trénování.
Různá data
Nezapomeňte použít obrázky, které představují, co se odešle do klasifikátoru během normálního použití. V opačném případě by se váš model mohl naučit vytvářet předpovědi na základě libovolných charakteristik, které vaše obrázky mají společné. Pokud například vytváříte klasifikátor pro jablka vs. citrusy a použili jste obrázky jablek v rukou a citrusových plodů na bílých talířích, může klasifikátor dávat zbytečné důležitosti pro ruce vs. talíře, nikoli jablka vs. citrusy.

Chcete-li tento problém vyřešit, zahrňte celou řadu imagí, abyste měli jistotu, že váš model dobře zobecní. Níže jsou uvedeny některé způsoby, jak nastavit, aby vaše trénovací sada byla různorodější:
Pozadí: Před různými pozadími můžete poskytnout obrázky objektu. Fotografie v přirozeném kontextu jsou lepší než fotky před neutrálními pozadími, protože poskytují více informací pro klasifikátor.

Osvětlení: Poskytuje obrázky s různým osvětlením (to znamená pořízeno s bleskem, vysokou expozicí atd.), zejména pokud obrázky používané pro predikci mají jiné osvětlení. Je také užitečné používat obrázky s různou sytostí, odstínem a jasem.

Velikost objektu: Zadejte obrázky, ve kterých se objekty liší velikostí a počtem (například fotka housek banánů a detail jednoho banánu). Různá velikost pomáhá klasifikátoru lépe generalizovat.

úhel Kamera: Poskytněte snímky pořízené různými úhly fotoaparátu. Případně platí, že pokud všechny vaše fotky musí být pořízeny s pevnými fotoaparáty (například bezpečnostními kamerami), nezapomeňte každému pravidelně se vyskytujícímu objektu přiřadit jiný popisek, abyste se vyhnuli přeurčení – interpretování nesouvisejících objektů (jako jsou lampy) jako klíčové funkce.

Styl: Poskytuje obrázky různých stylů stejné třídy (například různé odrůdy stejného ovoce). Pokud ale máte objekty s výrazně odlišnými styly (například Mickey Mouse nebo myš v reálném životě), doporučujeme je označit jako samostatné třídy, aby lépe představovaly jejich jedinečné funkce.

Záporné obrázky (pouze klasifikátory)
Pokud používáte klasifikátor obrázků, možná budete muset přidat záporné vzorky , aby byl klasifikátor přesnější. Negativní vzorky jsou obrázky, které neodpovídají žádné z ostatních značek. Když tyto obrázky nahrajete, použijte u nich speciální negativní popisek.
Detektory objektů zpracovávají negativní vzorky automaticky, protože všechny oblasti obrázků mimo nakreslené ohraničující rámečky jsou považovány za záporné.
Poznámka:
Služba Custom Vision podporuje automatické zpracování negativních obrázků. Pokud například vytváříte hroznový vs. klasifikátor banánů a odešlete obrázek obuvi pro predikci, klasifikátor by měl tento obrázek ohodnotit jako blízko 0 % pro hrozny i banány.
Na druhou stranu v případech, kdy jsou záporné obrázky jen variantou obrázků použitých při trénování, je pravděpodobné, že model klasifikuje negativní obrázky jako třídu označenou jako třídu označenou kvůli velkým podobnostem. Pokud máte například oranžový vs. klasifikátor grepu a podáváte na obrázku klementinu, může být klementin označen jako oranžový, protože mnoho rysů klementinu připomíná ty z pomerančů. Pokud jsou vaše negativní obrázky této povahy, doporučujeme vytvořit jednu nebo více dalších značek (například Jiné) a označit negativní obrázky touto značkou během trénování, aby model lépe rozlišoval mezi těmito třídami.
Okluze a zkrácení (pouze detektory objektů)
Pokud chcete, aby detektor objektů detekoval zkrácené objekty (objekty, které jsou částečně vyjmuty z obrázku) nebo odlehlé objekty (objekty, které jsou částečně blokované jinými objekty na obrázku), budete muset zahrnout trénovací obrázky, které tyto případy pokrývají.
Poznámka:
Problém objektů, které jsou odlehlé jinými objekty, není zaměňovat s prahovou hodnotou překrytí, parametr pro hodnocení výkonu modelu. Posuvník Prahová hodnota překrytí na webu Custom Vision se zabývá tím, kolik předpovězeného ohraničujícího rámečku se musí překrývat se skutečným ohraničovacím rámečkem, aby bylo považováno za správné.
Použití předpovědí obrázků k dalšímu trénování
Když model použijete nebo otestujete odesláním obrázků do koncového bodu předpovědi, služba Custom Vision tyto obrázky uloží. Pak je můžete použít ke zlepšení modelu.
Pokud chcete zobrazit obrázky odeslané do modelu, otevřete webovou stránku Služby Custom Vision, přejděte do projektu a vyberte kartu Predikce . Výchozí zobrazení zobrazuje obrázky z aktuální iterace. K zobrazení obrázků odeslaných během předchozích iterací můžete použít rozevírací nabídku Iterace .
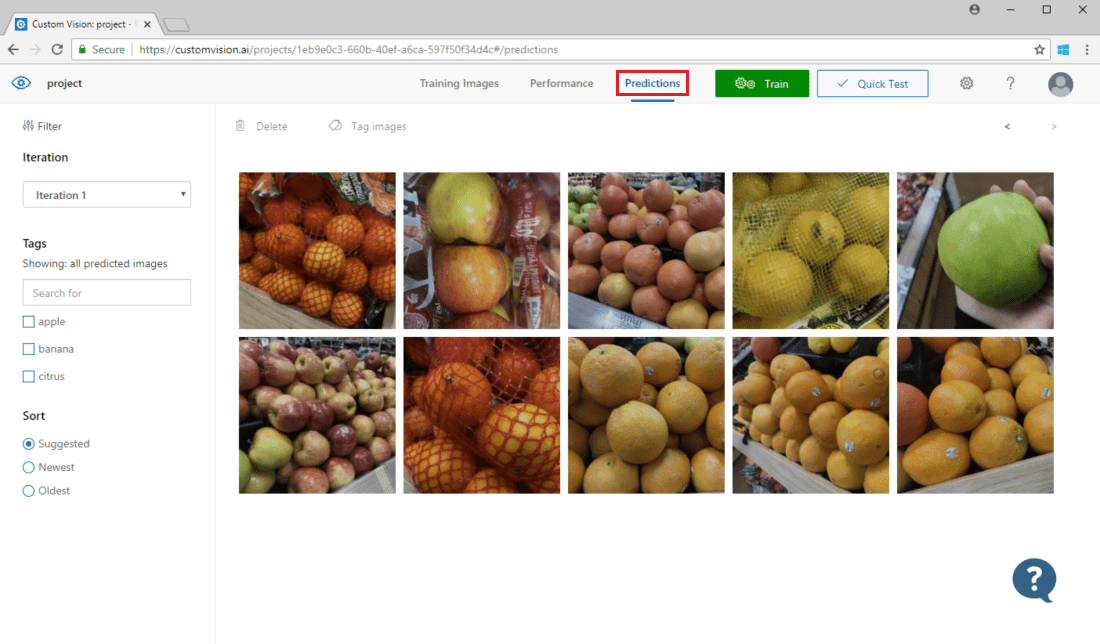
Najeďte myší na obrázek a zobrazte značky, které model predikoval. Obrázky jsou seřazené tak, aby ty, které můžou přinést nejvíce vylepšení modelu, jsou uvedeny nahoře. Pokud chcete použít jinou metodu řazení, vyberte ji v části Seřadit .
Pokud chcete přidat obrázek do existujících trénovacích dat, vyberte obrázek, nastavte správné značky a vyberte Uložit a zavřít. Obrázek se odebere z předpovědí a přidá se do sady trénovacích obrázků. Můžete ho zobrazit tak, že vyberete kartu Trénovací obrázky .
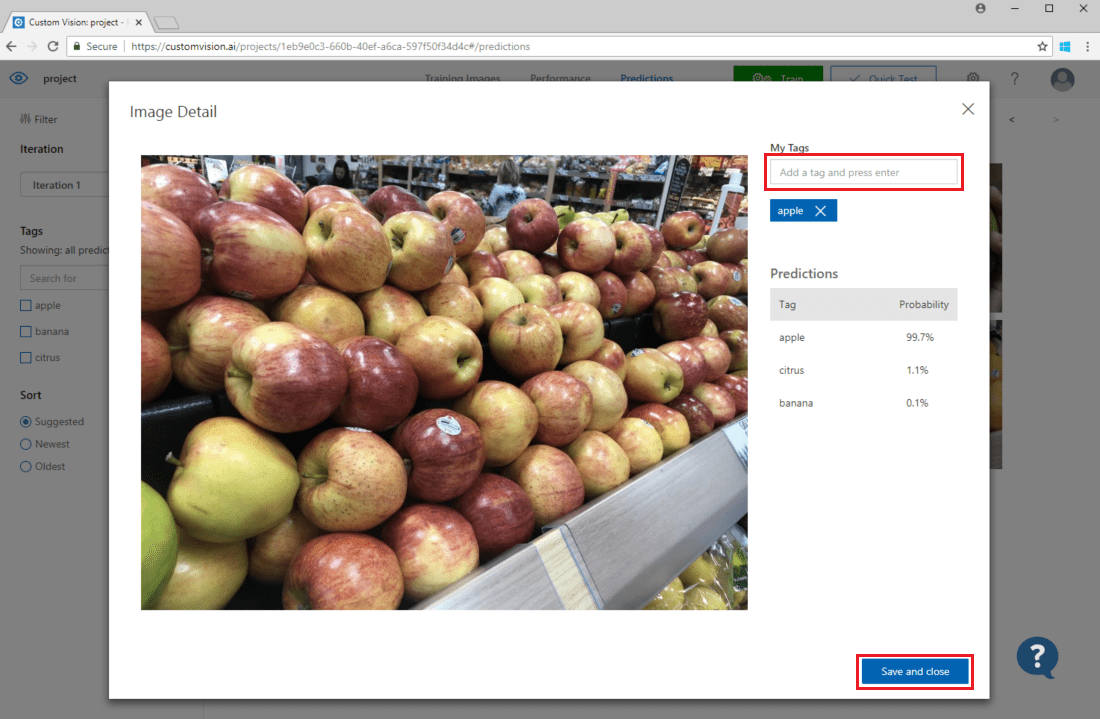
Pak pomocí tlačítka Trénovat model znovu vytrénujte.
Vizuální kontrola předpovědí
Pokud chcete zkontrolovat predikce obrázků, přejděte na kartu Trénovací obrázky, vyberte předchozí trénovací iteraci v rozevírací nabídce Iterace a v části Značky zkontrolujte jednu nebo více značek. V zobrazení by se teď mělo zobrazit červené pole kolem každého obrázku, pro který se modelu nepodařilo správně předpovědět danou značku.
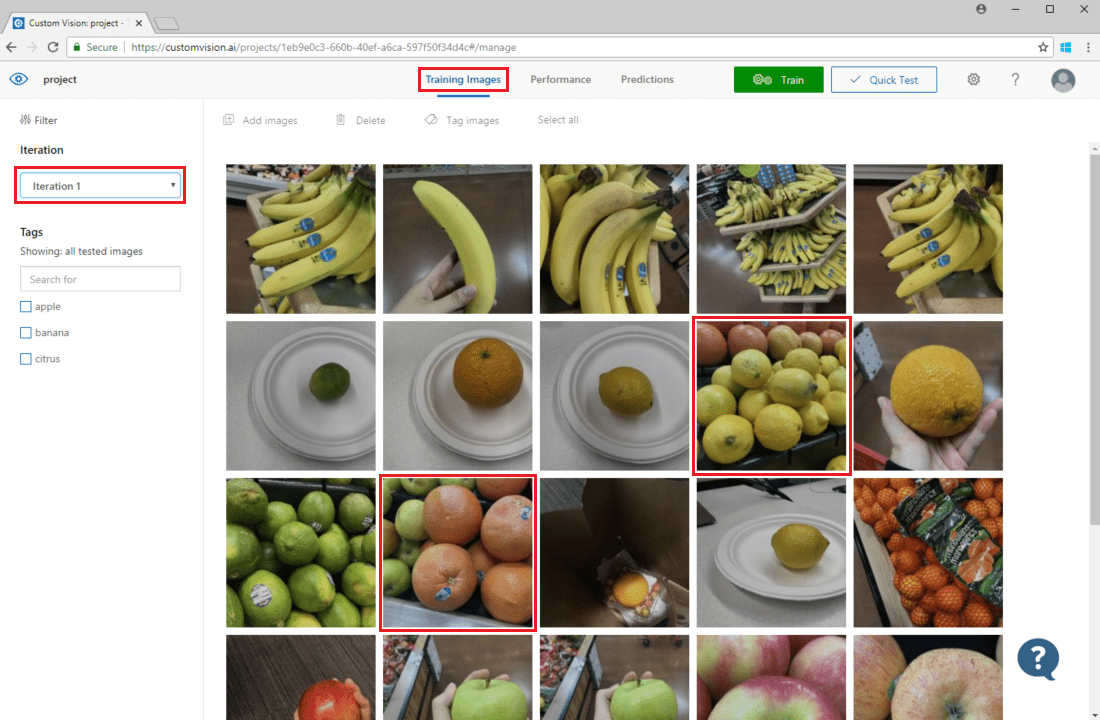
Někdy vizuální kontrola dokáže identifikovat vzory, které pak můžete opravit přidáním dalších trénovacích dat nebo úpravou existujících trénovacích dat. Například klasifikátor pro jablka vs. limetky můžou nesprávně označovat všechna zelená jablka jako limetky. Tento problém pak můžete opravit přidáním a poskytnutím trénovacích dat obsahujících označené obrázky zelených jablek.
Další kroky
V této příručce jste se naučili několik technik, které umožňují přesnější model klasifikace obrázků nebo model detektoru objektů. Dále se dozvíte, jak testovat obrázky programově odesláním do rozhraní API pro predikce.