Rychlý start: Vlastní klasifikace textu
V tomto článku můžete začít vytvářet vlastní projekt klasifikace textu, ve kterém můžete trénovat vlastní modely pro klasifikaci textu. Model je software umělé inteligence, který je natrénovaný k určitému úkolu. V tomto systému modely klasifikují text a trénují se učením z označených dat.
Vlastní klasifikace textu podporuje dva typy projektů:
- Klasifikace s jedním popiskem – každému dokumentu v datové sadě můžete přiřadit jednu třídu. Například filmový skript může být klasifikován pouze jako "Romantika" nebo "Komie".
- Klasifikace více popisků – pro každý dokument v datové sadě můžete přiřadit více tříd. Například filmový skript může být klasifikován jako "Comedy" nebo "Romance" a "Comedy".
V tomto rychlém startu můžete pomocí ukázkových datových sad uvedených vytvořit klasifikaci více popisků, kde můžete klasifikovat filmové skripty do jedné nebo více kategorií nebo můžete použít datovou sadu klasifikace s jedním popiskem, kde můžete klasifikovat abstrakce vědeckých studií do jedné z definovaných domén.
Požadavky
- Předplatné Azure – Vytvořte si ho zdarma.
Vytvoření nového prostředku Azure AI Language a účtu úložiště Azure
Než budete moct použít vlastní klasifikaci textu, budete muset vytvořit prostředek jazyka Azure AI, který vám poskytne přihlašovací údaje, které potřebujete k vytvoření projektu a zahájení trénování modelu. Budete také potřebovat účet úložiště Azure, kde můžete nahrát datovou sadu, která se použije k sestavení modelu.
Důležité
Pokud chcete rychle začít, doporučujeme vytvořit nový prostředek azure AI Language pomocí kroků uvedených v tomto článku. Pomocí kroků v tomto článku můžete vytvořit prostředek jazyka a účet úložiště současně, což je jednodušší než později.
Pokud máte již existující prostředek , který chcete použít, budete ho muset připojit k účtu úložiště.
Vytvoření nového prostředku z webu Azure Portal
Přejděte na web Azure Portal a vytvořte nový prostředek jazyka Azure AI.
V zobrazeném okně vyberte vlastní klasifikaci textu a rozpoznávání vlastních pojmenovaných entit z vlastních funkcí. Vyberte Pokračovat a vytvořte prostředek v dolní části obrazovky.

Vytvořte prostředek jazyka s následujícími podrobnostmi.
Název Požadovaná hodnota Předplatné Vaše předplatné Azure. Skupina prostředků Skupina prostředků, která bude obsahovat váš prostředek. Můžete použít existující nebo vytvořit nový. Oblast Jedna z podporovaných oblastí Například "USA – západ 2". Název Název vašeho prostředku Cenová úroveň Jedna z podporovaných cenových úrovní Službu můžete vyzkoušet pomocí úrovně Free (F0). Pokud se zobrazí zpráva"Váš přihlašovací účet není vlastníkem skupiny prostředků vybraného účtu úložiště", musí mít váš účet přiřazenou roli vlastníka pro skupinu prostředků, abyste mohli vytvořit prostředek jazyka. Požádejte o pomoc vlastníka předplatného Azure.
Vlastníka předplatného Azure můžete určit vyhledáním vaší skupiny prostředků a následujícím odkazem na přidružené předplatné. Potom:
- Výběr karty Řízení přístupu (IAM)
- Výběr přiřazení rolí
- Filtrovat podle role:Vlastník.
V části Vlastní klasifikace textu a rozpoznávání vlastních pojmenovaných entit vyberte existující účet úložiště nebo vyberte Nový účet úložiště. Všimněte si, že tyto hodnoty vám pomůžou začít, a ne nutně hodnoty účtu úložiště, které budete chtít použít v produkčních prostředích. Abyste se vyhnuli latenci při sestavování projektu, připojte se k účtům úložiště ve stejné oblasti jako prostředek jazyka.
Hodnota účtu úložiště Doporučená hodnota Název účtu úložiště Libovolný název Storage account type Standardní LRS Ujistěte se, že je zaškrtnuté příslušné oznámení O umělé inteligenci. Vyberte Zkontrolovat a vytvořit v dolní části stránky.

Nahrání ukázkových dat do kontejneru objektů blob
Po vytvoření účtu úložiště Azure a jeho připojení k prostředku jazyka budete muset nahrát dokumenty z ukázkové datové sady do kořenového adresáře kontejneru. Tyto dokumenty se později použijí k trénování modelu.
Stáhněte si ukázkovou datovou sadu pro projekty klasifikace s více popisky.
Otevřete soubor .zip a extrahujte složku obsahující dokumenty.
Zadaná ukázková datová sada obsahuje asi 200 dokumentů, z nichž každý je souhrnem filmu. Každý dokument patří do jedné nebo více následujících tříd:
- "Záhada"
- "Drama"
- "Thriller"
- "Komie"
- "Akce"
Na webu Azure Portal přejděte k účtu úložiště, který jste vytvořili, a vyberte ho. Můžete to udělat tak, že kliknete na účty úložiště a zadáte název účtu úložiště do pole Filtr pro libovolné pole.
Pokud se vaše skupina prostředků nezobrazí, ujistěte se, že je filtr Rovná se předplatnému nastavené na Vše.
V účtu úložiště vyberte v nabídce vlevo kontejnery umístěné pod úložištěm dat. Na obrazovce, která se zobrazí, vyberte + Kontejner. Pojmenujte kontejner ukázková data a ponechte výchozí úroveň veřejného přístupu.

Po vytvoření kontejneru ho vyberte. Pak vyberte tlačítko Nahrát a
.jsonvyberte soubory.txt, které jste stáhli dříve.


Vytvoření vlastního projektu klasifikace textu
Po nakonfigurování prostředku a kontejneru úložiště vytvořte nový projekt vlastní klasifikace textu. Projekt je pracovní oblast pro vytváření vlastních modelů ML na základě vašich dat. K vašemu projektu má přístup jenom vy a ostatní, kteří mají přístup k používanému prostředku jazyka.
Přihlaste se k sadě Language Studio. Zobrazí se okno, ve které můžete vybrat předplatné a prostředek jazyka. Vyberte prostředek jazyka.
V části Klasifikovat text v sadě Language Studio vyberte Vlastní klasifikaci textu.
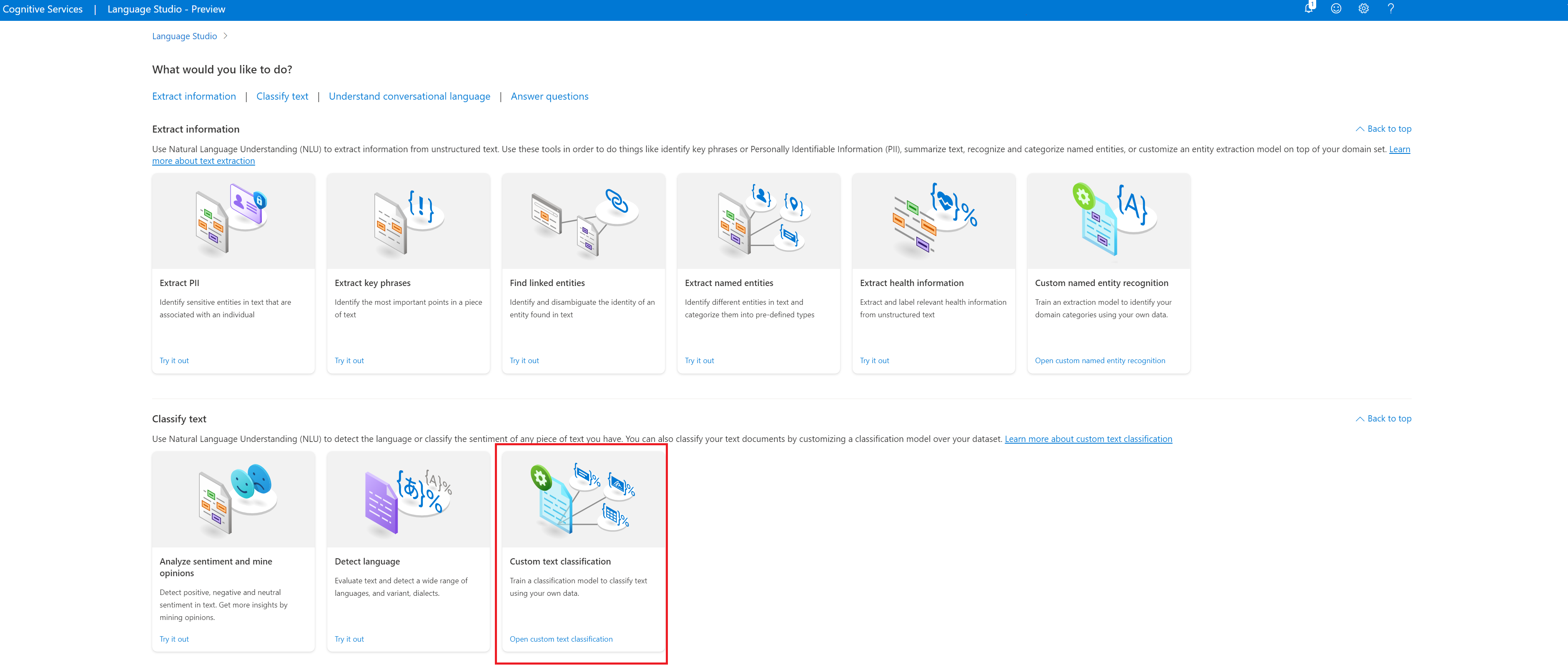
V horní nabídce na stránce projektů vyberte Vytvořit nový projekt . Vytvoření projektu vám umožní označovat data, trénovat, vyhodnocovat, vylepšovat a nasazovat modely.
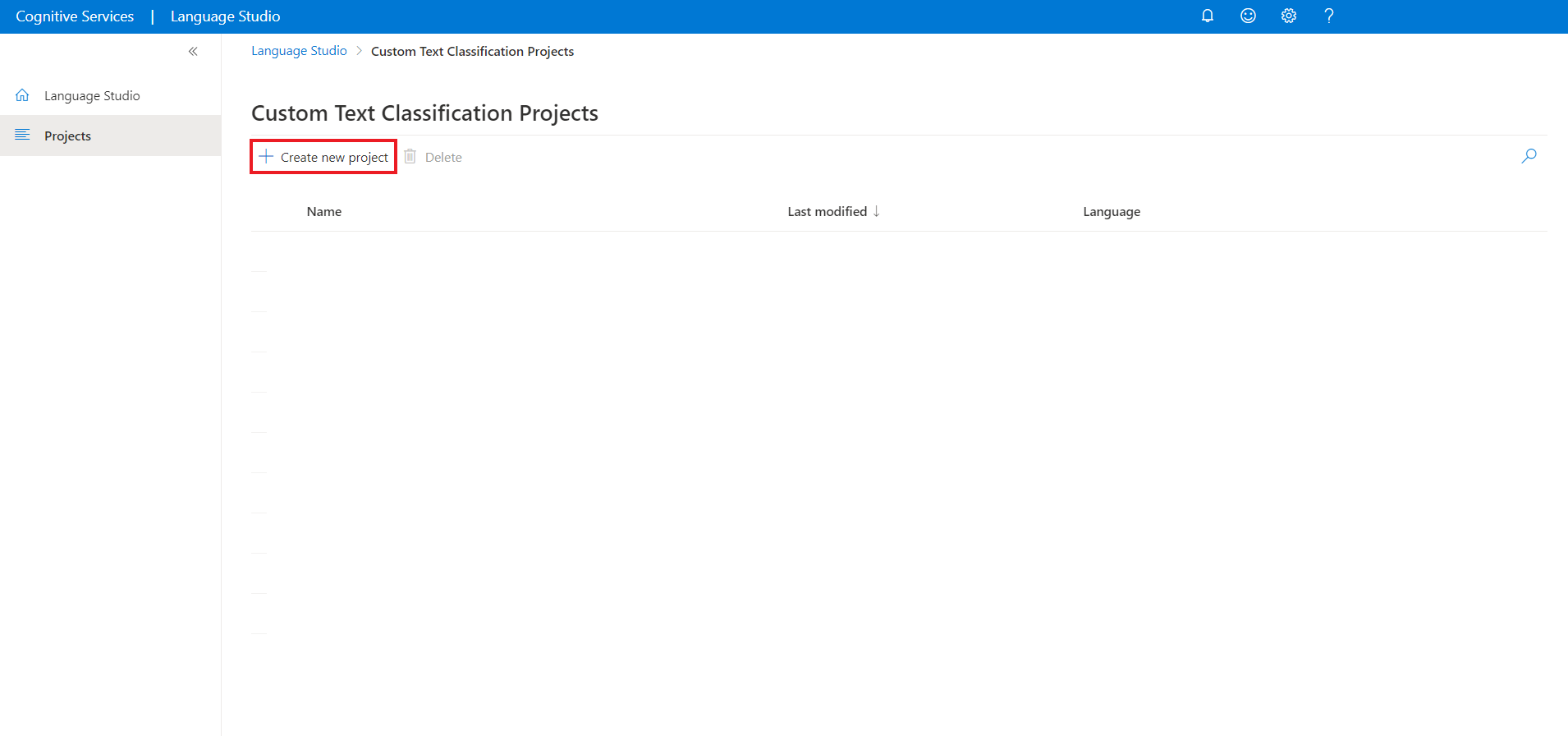
Po kliknutí na možnost Vytvořit nový projekt se zobrazí okno, které vám umožní připojit účet úložiště. Pokud jste už připojili účet úložiště, zobrazí se účet úložiště připojený. Pokud ne, zvolte účet úložiště v rozevíracím seznamu, který se zobrazí, a vyberte Připojení účet úložiště. Tím se nastaví požadované role pro váš účet úložiště. Tento krok pravděpodobně vrátí chybu, pokud nejste v účtu úložiště přiřazeni jako vlastník .
Poznámka:
- Tento krok stačí provést jenom jednou pro každý nový prostředek jazyka, který používáte.
- Tento proces je nevratný, pokud k prostředku jazyka připojíte účet úložiště, nemůžete ho později odpojit.
- Prostředek jazyka můžete připojit pouze k jednomu účtu úložiště.

Vyberte typ projektu. Můžete vytvořit projekt klasifikace více popisků, kde každý dokument může patřit do jedné nebo více tříd nebo projektu klasifikace s jedním popiskem, kde každý dokument může patřit pouze do jedné třídy. Vybraný typ nelze později změnit. Další informace o typech projektů

Zadejte informace o projektu, včetně názvu, popisu a jazyka dokumentů v projektu. Pokud používáte ukázkovou datovou sadu, vyberte angličtinu. Později nebudete moct změnit název projektu. Vyberte Další.
Tip
Vaše datová sada nemusí být úplně ve stejném jazyce. Můžete mít více dokumentů, z nichž každý má různé podporované jazyky. Pokud vaše datová sada obsahuje dokumenty různých jazyků nebo pokud očekáváte text z různých jazyků během běhu, vyberte možnost povolit vícejazyčnou datovou sadu , když zadáte základní informace o projektu. Tuto možnost můžete povolit později na stránce Nastavení projektu.
Vyberte kontejner, do kterého jste datovou sadu nahráli.
Poznámka:
Pokud jste už data označili popiskem, ujistěte se, že se řídí podporovaným formátem , a vyberte Ano, dokumenty jsou už označené a mám formátovaný soubor popisků JSON a v rozevírací nabídce níže vyberte soubor štítků.
Pokud používáte některou z ukázkových datových sad, použijte zahrnutý
webOfScience_labelsFilesoubor nebomovieLabelssoubor JSON. Pak vyberte Další.Zkontrolujte zadaná data a vyberte Vytvořit projekt.




Trénování vašeho modelu
Obvykle po vytvoření projektu začnete popisovat dokumenty , které máte v kontejneru připojeném k projektu. V tomto rychlém startu jste naimportovali ukázkovou datovou sadu s popiskem a inicializovali projekt pomocí ukázkového souboru popisků JSON.
Zahájení trénování modelu v sadě Language Studio:
V nabídce na levé straně vyberte Úlohy trénování .
V horní nabídce vyberte Spustit trénovací úlohu .
Vyberte Vytrénovat nový model a do textového pole zadejte název modelu. Existující model můžete také přepsat tak, že vyberete tuto možnost a zvolíte model, který chcete přepsat z rozevírací nabídky. Přepsání natrénovaného modelu je nevratné, ale nebude mít vliv na nasazené modely, dokud nový model nenasadíte.
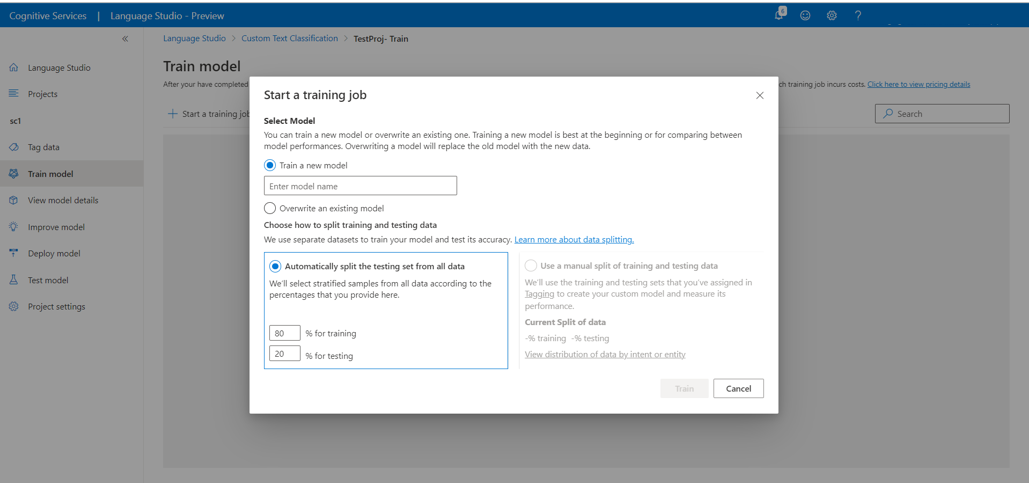
Vyberte metodu rozdělení dat. Můžete zvolit automatické rozdělení testovací sady z trénovacích dat , kde systém rozdělí označená data mezi trénovací a testovací sady podle zadaných procent. Nebo můžete použít ruční rozdělení trénovacích a testovacích dat, tato možnost je povolená jenom v případě, že jste do testovací sady přidali dokumenty během označování dat. Další informace o rozdělení dat najdete v tématu Postup trénování modelu .
Vyberte tlačítko Trénovat.
Pokud v seznamu vyberete ID trénovací úlohy, zobrazí se boční podokno, kde můžete zkontrolovat průběh trénování, stav úlohy a další podrobnosti o této úloze.
Poznámka:
- Pouze úspěšně dokončené trénovací úlohy vygenerují modely.
- Doba trénování modelu může trvat od několika minut do několika hodin na základě velikosti označených dat.
- Najednou můžete mít spuštěnou pouze jednu úlohu trénování. V rámci stejného projektu nemůžete spustit další úlohu trénování, dokud se nedokončí spuštěná úloha.

Nasazení modelu
Obecně platí, že po trénování modelu byste zkontrolovali podrobnosti o jeho vyhodnocení a v případě potřeby provedli vylepšení . V tomto rychlém startu jednoduše nasadíte model a zpřístupníte ho pro vyzkoušení v sadě Language Studio nebo můžete volat rozhraní API pro predikce.
Nasazení modelu v sadě Language Studio:
V nabídce na levé straně vyberte Nasazení modelu .
Vyberte Přidat nasazení a spusťte novou úlohu nasazení.
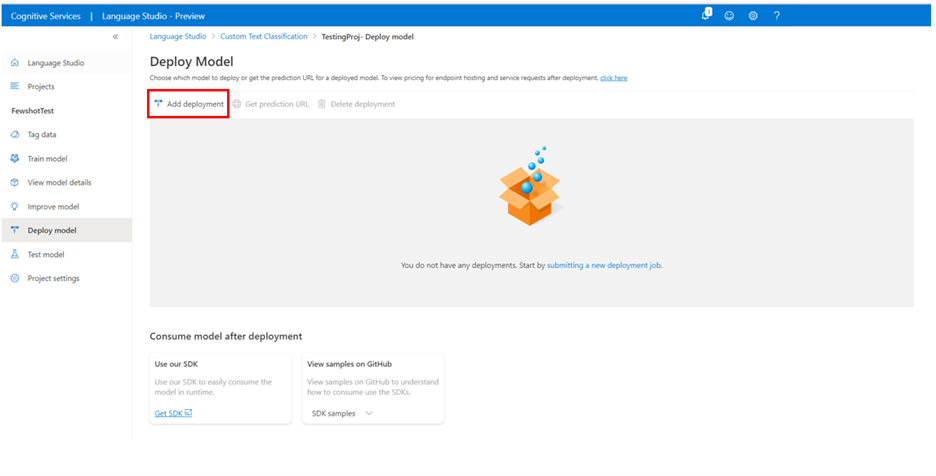
Výběrem možnosti Vytvořit nové nasazení vytvořte nové nasazení a v rozevíracím seznamu níže přiřaďte natrénovaný model. Existující nasazení můžete také přepsat tak, že vyberete tuto možnost a v rozevíracím seznamu níže vyberete natrénovaný model, který k němu chcete přiřadit.
Poznámka:
Přepsání existujícího nasazení nevyžaduje změny volání rozhraní API pro predikce, ale výsledky, které získáte, budou založené na nově přiřazeného modelu.
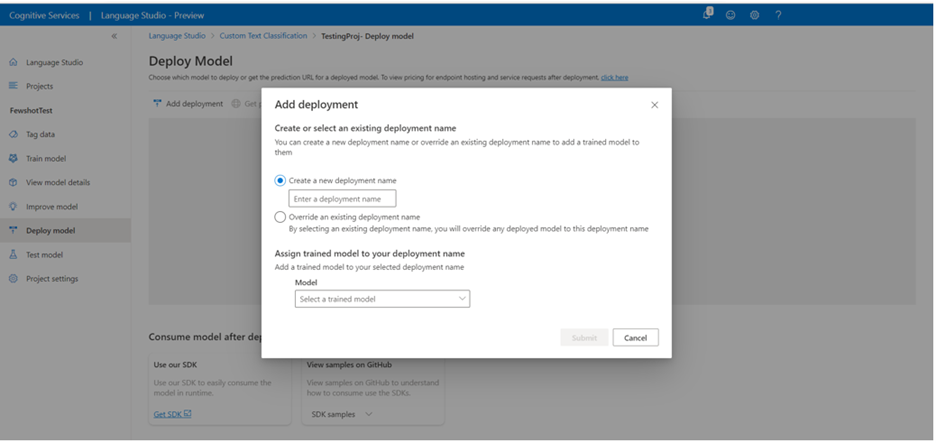
Výběrem možnosti Nasadit spustíte úlohu nasazení.
Po úspěšném nasazení se vedle něj zobrazí datum vypršení platnosti. Vypršení platnosti nasazení je v případě, že nasazený model nebude dostupný pro predikci, což obvykle nastane dvanáct měsíců po vypršení platnosti konfigurace trénování.


Testování modelu
Po nasazení modelu ho můžete začít používat ke klasifikaci textu prostřednictvím rozhraní API pro predikce. V tomto rychlém startu použijete Language Studio k odeslání vlastní úlohy klasifikace textu a vizualizaci výsledků. V ukázkové datové sadě, kterou jste si stáhli dříve, najdete některé testovací dokumenty, které můžete použít v tomto kroku.
Testování nasazených modelů v sadě Language Studio:
V nabídce na levé straně obrazovky vyberte Testovací nasazení .
Vyberte nasazení, které chcete otestovat. Můžete testovat jenom modely, které jsou přiřazené k nasazením.
V případě vícejazyčných projektů vyberte jazyk textu, který testujete, pomocí rozevíracího seznamu jazyka.
V rozevíracím seznamu vyberte nasazení, které chcete dotazovat nebo testovat.
Zadejte text, který chcete odeslat v žádosti, nebo nahrajte
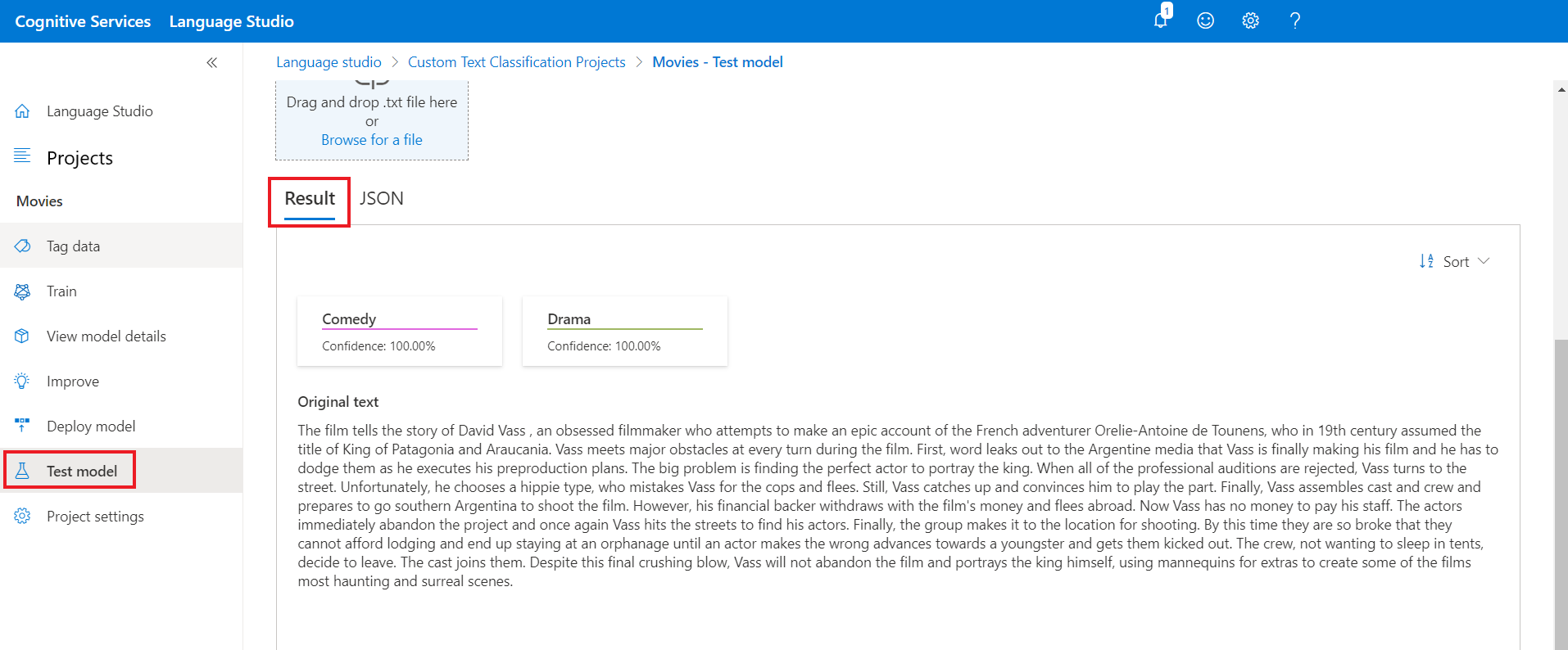
.txtdokument, který chcete použít. Pokud používáte některou z ukázkových datových sad, můžete použít jeden z zahrnutých souborů .txt.V horní nabídce vyberte Spustit test .
Na kartě Výsledek uvidíte predikované třídy textu. Odpověď JSON můžete zobrazit také na kartě JSON . Následující příklad je pro projekt klasifikace s jedním popiskem. Projekt klasifikace více popisků může ve výsledku vrátit více než jednu třídu.

Vyčištění projektů
Pokud už projekt nepotřebujete, můžete projekt odstranit pomocí sady Language Studio. V horní části vyberte Vlastní klasifikaci textu a pak vyberte projekt, který chcete odstranit. V horní nabídce vyberte Odstranit a projekt odstraňte.
Požadavky
- Předplatné Azure – Vytvořte si ho zdarma.
Vytvoření nového prostředku Azure AI Language a účtu úložiště Azure
Než budete moct použít vlastní klasifikaci textu, budete muset vytvořit prostředek jazyka Azure AI, který vám poskytne přihlašovací údaje, které potřebujete k vytvoření projektu a zahájení trénování modelu. Budete také potřebovat účet úložiště Azure, kde můžete nahrát datovou sadu, která se použije při sestavování modelu.
Důležité
Pokud chcete rychle začít, doporučujeme vytvořit nový prostředek azure AI Language pomocí kroků uvedených v tomto článku, který vám umožní vytvořit prostředek jazyka a vytvořit a/nebo připojit účet úložiště současně, což je jednodušší než později.
Pokud máte již existující prostředek , který chcete použít, budete ho muset připojit k účtu úložiště.
Vytvoření nového prostředku z webu Azure Portal
Přejděte na web Azure Portal a vytvořte nový prostředek jazyka Azure AI.
V zobrazeném okně vyberte vlastní klasifikaci textu a rozpoznávání vlastních pojmenovaných entit z vlastních funkcí. Vyberte Pokračovat a vytvořte prostředek v dolní části obrazovky.
Vytvořte prostředek jazyka s následujícími podrobnostmi.
Název Požadovaná hodnota Předplatné Vaše předplatné Azure. Skupina prostředků Skupina prostředků, která bude obsahovat váš prostředek. Můžete použít existující nebo vytvořit nový. Oblast Jedna z podporovaných oblastí Například "USA – západ 2". Název Název vašeho prostředku Cenová úroveň Jedna z podporovaných cenových úrovní Službu můžete vyzkoušet pomocí úrovně Free (F0). Pokud se zobrazí zpráva"Váš přihlašovací účet není vlastníkem skupiny prostředků vybraného účtu úložiště", musí mít váš účet přiřazenou roli vlastníka pro skupinu prostředků, abyste mohli vytvořit prostředek jazyka. Požádejte o pomoc vlastníka předplatného Azure.
Vlastníka předplatného Azure můžete určit vyhledáním vaší skupiny prostředků a následujícím odkazem na přidružené předplatné. Potom:
- Výběr karty Řízení přístupu (IAM)
- Výběr přiřazení rolí
- Filtrovat podle role:Vlastník.
V části Vlastní klasifikace textu a rozpoznávání vlastních pojmenovaných entit vyberte existující účet úložiště nebo vyberte Nový účet úložiště. Všimněte si, že tyto hodnoty vám pomůžou začít, a ne nutně hodnoty účtu úložiště, které budete chtít použít v produkčních prostředích. Abyste se vyhnuli latenci při sestavování projektu, připojte se k účtům úložiště ve stejné oblasti jako prostředek jazyka.
Hodnota účtu úložiště Doporučená hodnota Název účtu úložiště Libovolný název Storage account type Standardní LRS Ujistěte se, že je zaškrtnuté příslušné oznámení O umělé inteligenci. Vyberte Zkontrolovat a vytvořit v dolní části stránky.
Nahrání ukázkových dat do kontejneru objektů blob
Po vytvoření účtu úložiště Azure a jeho připojení k prostředku jazyka budete muset nahrát dokumenty z ukázkové datové sady do kořenového adresáře kontejneru. Tyto dokumenty se později použijí k trénování modelu.
Stáhněte si ukázkovou datovou sadu pro projekty klasifikace s více popisky.
Otevřete soubor .zip a extrahujte složku obsahující dokumenty.
Zadaná ukázková datová sada obsahuje asi 200 dokumentů, z nichž každý je souhrnem filmu. Každý dokument patří do jedné nebo více následujících tříd:
- "Záhada"
- "Drama"
- "Thriller"
- "Komie"
- "Akce"
Na webu Azure Portal přejděte k účtu úložiště, který jste vytvořili, a vyberte ho. Můžete to udělat tak, že kliknete na účty úložiště a zadáte název účtu úložiště do pole Filtr pro libovolné pole.
Pokud se vaše skupina prostředků nezobrazí, ujistěte se, že je filtr Rovná se předplatnému nastavené na Vše.
V účtu úložiště vyberte v nabídce vlevo kontejnery umístěné pod úložištěm dat. Na obrazovce, která se zobrazí, vyberte + Kontejner. Pojmenujte kontejner ukázková data a ponechte výchozí úroveň veřejného přístupu.
Po vytvoření kontejneru ho vyberte. Pak vyberte tlačítko Nahrát a
.jsonvyberte soubory.txt, které jste stáhli dříve.
Získání klíčů prostředků a koncového bodu
Na webu Azure Portal přejděte na stránku přehledu prostředků.
V nabídce na levé straně vyberte Klíče a koncový bod. Pro požadavky rozhraní API použijete koncový bod a klíč.

Vytvoření vlastního projektu klasifikace textu
Po nakonfigurování prostředku a kontejneru úložiště vytvořte nový projekt vlastní klasifikace textu. Projekt je pracovní oblast pro vytváření vlastních modelů ML na základě vašich dat. K vašemu projektu má přístup jenom vy a ostatní, kteří mají přístup k používanému prostředku jazyka.
Aktivace úlohy importu projektu
Odešlete požadavek POST pomocí následující adresy URL, hlaviček a textu JSON pro import souboru štítků. Ujistěte se, že soubor štítků dodržuje akceptované formátování.
Pokud projekt se stejným názvem již existuje, nahradí se data tohoto projektu.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/:import?api-version={API-VERSION}
| Zástupný symbol | Hodnota | Příklad |
|---|---|---|
{ENDPOINT} |
Koncový bod pro ověření požadavku rozhraní API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Název projektu. U této hodnoty se rozlišují malá a velká písmena. | myProject |
{API-VERSION} |
Verze rozhraní API, které voláte. Hodnota, na kterou se zde odkazuje, je určená pro nejnovější vydané verze. Další informace o dalších dostupných verzích rozhraní API | 2022-05-01 |
Hlavičky
K ověření požadavku použijte následující hlavičku.
| Key | Hodnota |
|---|---|
Ocp-Apim-Subscription-Key |
Klíč k vašemu prostředku. Používá se k ověřování požadavků rozhraní API. |
Body
V požadavku použijte následující kód JSON. Nahraďte níže uvedené zástupné hodnoty vlastními hodnotami.
{
"projectFileVersion": "{API-VERSION}",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectName": "{PROJECT-NAME}",
"storageInputContainerName": "{CONTAINER-NAME}",
"projectKind": "customMultiLabelClassification",
"description": "Trying out custom multi label text classification",
"language": "{LANGUAGE-CODE}",
"multilingual": true,
"settings": {}
},
"assets": {
"projectKind": "customMultiLabelClassification",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
],
"documents": [
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
]
},
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"classes": [
{
"category": "Class2"
}
]
}
]
}
}
| Key | Zástupný symbol | Hodnota | Příklad |
|---|---|---|---|
| verze-api | {API-VERSION} |
Verze rozhraní API, které voláte. Zde použitá verze musí být stejná verze rozhraní API v adrese URL. Další informace o dalších dostupných verzích rozhraní API | 2022-05-01 |
| projectName | {PROJECT-NAME} |
Název projektu. U této hodnoty se rozlišují malá a velká písmena. | myProject |
| projectKind | customMultiLabelClassification |
Váš projekt je laskavý. | customMultiLabelClassification |
| jazyk | {LANGUAGE-CODE} |
Řetězec určující kód jazyka pro dokumenty použité v projektu. Pokud je projekt vícejazyčný, zvolte kód jazyka většiny dokumentů. Další informace o podpoře více jazyků najdete v podpoře jazyků. | en-us |
| Vícejazyčné | true |
Logická hodnota, která umožňuje mít v datové sadě dokumenty ve více jazycích a při nasazení modelu můžete dotazovat model v libovolném podporovaném jazyce (nemusí nutně být součástí trénovacích dokumentů). Další informace o podpoře více jazyků najdete v podpoře jazyků. | true |
| storageInputContainerName | {CONTAINER-NAME} |
Název kontejneru úložiště Azure, do kterého jste dokumenty nahráli. | myContainer |
| třídy | [] | Pole obsahující všechny třídy, které máte v projektu. Jedná se o třídy, do které chcete dokumenty klasifikovat. | [] |
| documents | [] | Pole obsahující všechny dokumenty v projektu a třídy označené pro tento dokument. | [] |
| location | {DOCUMENT-NAME} |
Umístění dokumentů v kontejneru úložiště. Vzhledem k tomu, že všechny dokumenty jsou v kořenovém adresáři kontejneru, měl by to být název dokumentu. | doc1.txt |
| datová sada | {DATASET} |
Testovací sada, na kterou se tento dokument před trénováním rozdělí. Další informace o rozdělení dat najdete v tématu Postup trénování modelu . Možné hodnoty pro toto pole jsou Train a Test. |
Train |
Po odeslání požadavku rozhraní API obdržíte 202 odpověď, která značí, že úloha byla odeslána správně. V hlavičce odpovědi extrahujte operation-location hodnotu. Bude formátován takto:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} slouží k identifikaci vašeho požadavku, protože tato operace je asynchronní. Tuto adresu URL použijete k získání stavu úlohy importu.
Možné chybové scénáře pro tento požadavek:
- Vybraný prostředek nemá správná oprávnění pro účet úložiště.
- Zadaná
storageInputContainerNamehodnota neexistuje. - Použije se neplatný kód jazyka nebo pokud typ kódu jazyka není řetězec.
multilingualhodnota je řetězec, nikoli logická hodnota.
Získání stavu úlohy importu
Pomocí následujícího požadavku GET získejte stav importu projektu. Nahraďte níže uvedené zástupné hodnoty vlastními hodnotami.
Adresa URL požadavku
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
| Zástupný symbol | Hodnota | Příklad |
|---|---|---|
{ENDPOINT} |
Koncový bod pro ověření požadavku rozhraní API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Název projektu. U této hodnoty se rozlišují malá a velká písmena. | myProject |
{JOB-ID} |
ID pro vyhledání stavu trénování modelu. Tato hodnota je v location hodnotě záhlaví, kterou jste obdrželi v předchozím kroku. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Verze rozhraní API, které voláte. Hodnota, na kterou se zde odkazuje, je určená pro nejnovější vydané verze. Další informace o dalších dostupných verzích rozhraní API | 2022-05-01 |
Hlavičky
K ověření požadavku použijte následující hlavičku.
| Key | Hodnota |
|---|---|
Ocp-Apim-Subscription-Key |
Klíč k vašemu prostředku. Používá se k ověřování požadavků rozhraní API. |
Trénování vašeho modelu
Obvykle po vytvoření projektu začnete označovat dokumenty , které máte v kontejneru připojeném k projektu. V tomto rychlém startu jste naimportovali ukázkovou označenou datovou sadu a inicializovali projekt pomocí ukázkového souboru značek JSON.
Zahájení trénování modelu
Po importu projektu můžete zahájit trénování modelu.
Odešlete požadavek POST pomocí následující adresy URL, hlaviček a textu JSON a odešlete trénovací úlohu. Nahraďte níže uvedené zástupné hodnoty vlastními hodnotami.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/:train?api-version={API-VERSION}
| Zástupný symbol | Hodnota | Příklad |
|---|---|---|
{ENDPOINT} |
Koncový bod pro ověření požadavku rozhraní API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Název projektu. U této hodnoty se rozlišují malá a velká písmena. | myProject |
{API-VERSION} |
Verze rozhraní API, které voláte. Hodnota, na kterou se zde odkazuje, je určená pro nejnovější vydané verze. Další informace o dalších dostupných verzích rozhraní API | 2022-05-01 |
Hlavičky
K ověření požadavku použijte následující hlavičku.
| Key | Hodnota |
|---|---|
Ocp-Apim-Subscription-Key |
Klíč k vašemu prostředku. Používá se k ověřování požadavků rozhraní API. |
Text požadavku
V textu požadavku použijte následující KÓD JSON. Po dokončení trénování bude model udělen {MODEL-NAME} . Modely budou vytvářet pouze úspěšné trénovací úlohy.
{
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"evaluationOptions": {
"kind": "percentage",
"trainingSplitPercentage": 80,
"testingSplitPercentage": 20
}
}
| Key | Zástupný symbol | Hodnota | Příklad |
|---|---|---|---|
| modelLabel | {MODEL-NAME} |
Název modelu, který se přiřadí k vašemu modelu po úspěšném natrénování. | myModel |
| trainingConfigVersion | {CONFIG-VERSION} |
Toto je verze modelu, která se použije k trénování modelu. | 2022-05-01 |
| evaluationOptions | Možnost rozdělení dat mezi trénovací a testovací sady | {} |
|
| kind | percentage |
Rozdělte metody. Možné hodnoty jsou percentage nebo manual. Další informace najdete v tématu Jak vytrénovat model . |
percentage |
| trainingSplitPercentage | 80 |
Procento označených dat, která se mají zahrnout do trénovací sady Doporučená hodnota je 80. |
80 |
| testingSplitPercentage | 20 |
Procento označených dat, která se mají zahrnout do testovací sady Doporučená hodnota je 20. |
20 |
Poznámka:
testingSplitPercentage A trainingSplitPercentage jsou vyžadovány pouze v případě, že Kind je nastavena percentage hodnota a součet obou procent by měl být roven 100.
Po odeslání požadavku rozhraní API obdržíte 202 odpověď, která značí, že úloha byla odeslána správně. V hlavičce odpovědi extrahujte location hodnotu. Bude formátován takto:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} slouží k identifikaci vašeho požadavku, protože tato operace je asynchronní. Pomocí této adresy URL můžete získat stav trénování.
Získání stavu trénovací úlohy
Trénování může trvat 10 až 30 minut. Pomocí následujícího požadavku můžete pokračovat v dotazování na stav trénovací úlohy, dokud se úspěšně nedokončí.
Stav průběhu trénování modelu získáte pomocí následujícího požadavku GET . Nahraďte níže uvedené zástupné hodnoty vlastními hodnotami.
Adresa URL požadavku
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
| Zástupný symbol | Hodnota | Příklad |
|---|---|---|
{ENDPOINT} |
Koncový bod pro ověření požadavku rozhraní API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Název projektu. U této hodnoty se rozlišují malá a velká písmena. | myProject |
{JOB-ID} |
ID pro vyhledání stavu trénování modelu. Tato hodnota je v location hodnotě záhlaví, kterou jste obdrželi v předchozím kroku. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Verze rozhraní API, které voláte. Hodnota, na kterou se zde odkazuje, je určená pro nejnovější vydané verze. Další informace o dalších dostupných verzích rozhraní API najdete v životním cyklu modelu. | 2022-05-01 |
Hlavičky
K ověření požadavku použijte následující hlavičku.
| Key | Hodnota |
|---|---|
Ocp-Apim-Subscription-Key |
Klíč k vašemu prostředku. Používá se k ověřování požadavků rozhraní API. |
Text odpovědi
Po odeslání požadavku získáte následující odpověď.
{
"result": {
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"estimatedEndDateTime": "2022-04-18T15:47:58.8190649Z",
"trainingStatus": {
"percentComplete": 3,
"startDateTime": "2022-04-18T15:45:06.8190649Z",
"status": "running"
},
"evaluationStatus": {
"percentComplete": 0,
"status": "notStarted"
}
},
"jobId": "{JOB-ID}",
"createdDateTime": "2022-04-18T15:44:44Z",
"lastUpdatedDateTime": "2022-04-18T15:45:48Z",
"expirationDateTime": "2022-04-25T15:44:44Z",
"status": "running"
}
Nasazení modelu
Obecně platí, že po trénování modelu byste si prostudovali podrobnosti o vyhodnocení a v případě potřeby provedli vylepšení . V tomto rychlém startu jednoduše nasadíte model a zpřístupníte ho pro vyzkoušení v sadě Language Studio nebo můžete volat rozhraní API pro predikce.
Odeslání úlohy nasazení
Odešlete požadavek PUT pomocí následující adresy URL, hlaviček a textu JSON a odešlete úlohu nasazení. Nahraďte níže uvedené zástupné hodnoty vlastními hodnotami.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/deployments/{deploymentName}?api-version={API-VERSION}
| Zástupný symbol | Hodnota | Příklad |
|---|---|---|
{ENDPOINT} |
Koncový bod pro ověření požadavku rozhraní API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Název projektu. U této hodnoty se rozlišují malá a velká písmena. | myProject |
{DEPLOYMENT-NAME} |
Název nasazení. U této hodnoty se rozlišují malá a velká písmena. | staging |
{API-VERSION} |
Verze rozhraní API, které voláte. Hodnota, na kterou se zde odkazuje, je určená pro nejnovější vydané verze. Další informace o dalších dostupných verzích rozhraní API | 2022-05-01 |
Hlavičky
K ověření požadavku použijte následující hlavičku.
| Key | Hodnota |
|---|---|
Ocp-Apim-Subscription-Key |
Klíč k vašemu prostředku. Používá se k ověřování požadavků rozhraní API. |
Text požadavku
V textu požadavku použijte následující KÓD JSON. Použijte název modelu, který chcete přiřadit k nasazení.
{
"trainedModelLabel": "{MODEL-NAME}"
}
| Key | Zástupný symbol | Hodnota | Příklad |
|---|---|---|---|
| trainedModelLabel | {MODEL-NAME} |
Název modelu, který se přiřadí k vašemu nasazení. Úspěšně natrénované modely můžete přiřadit pouze. U této hodnoty se rozlišují malá a velká písmena. | myModel |
Po odeslání požadavku rozhraní API obdržíte 202 odpověď, která značí, že úloha byla odeslána správně. V hlavičce odpovědi extrahujte operation-location hodnotu. Bude formátován takto:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} slouží k identifikaci vašeho požadavku, protože tato operace je asynchronní. Tuto adresu URL můžete použít k získání stavu nasazení.
Získání stavu úlohy nasazení
Pomocí následujícího požadavku GET zadejte dotaz na stav úlohy nasazení. Můžete použít adresu URL, kterou jste obdrželi z předchozího kroku, nebo nahradit níže uvedené zástupné hodnoty vlastními hodnotami.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
| Zástupný symbol | Hodnota | Příklad |
|---|---|---|
{ENDPOINT} |
Koncový bod pro ověření požadavku rozhraní API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Název projektu. U této hodnoty se rozlišují malá a velká písmena. | myProject |
{DEPLOYMENT-NAME} |
Název nasazení. U této hodnoty se rozlišují malá a velká písmena. | staging |
{JOB-ID} |
ID pro vyhledání stavu trénování modelu. Toto je hodnota hlavičky location , kterou jste obdrželi v předchozím kroku. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Verze rozhraní API, které voláte. Hodnota, na kterou se zde odkazuje, je určená pro nejnovější vydané verze. Další informace o dalších dostupných verzích rozhraní API | 2022-05-01 |
Hlavičky
K ověření požadavku použijte následující hlavičku.
| Key | Hodnota |
|---|---|
Ocp-Apim-Subscription-Key |
Klíč k vašemu prostředku. Používá se k ověřování požadavků rozhraní API. |
Text odpovědi
Po odeslání požadavku se zobrazí následující odpověď. Pokračujte v dotazování na tento koncový bod, dokud se parametr stavu nezmění na "úspěch". Měli byste získat 200 kód, který indikuje úspěch požadavku.
{
"jobId":"{JOB-ID}",
"createdDateTime":"{CREATED-TIME}",
"lastUpdatedDateTime":"{UPDATED-TIME}",
"expirationDateTime":"{EXPIRATION-TIME}",
"status":"running"
}
Klasifikace textu
Po úspěšném nasazení modelu ho můžete začít používat ke klasifikaci textu prostřednictvím rozhraní API pro predikce. V ukázkové datové sadě, kterou jste si stáhli dříve, najdete některé testovací dokumenty, které můžete použít v tomto kroku.
Odeslání vlastního úkolu klasifikace textu
Pomocí tohoto požadavku POST spusťte úlohu klasifikace textu.
{ENDPOINT}/language/analyze-text/jobs?api-version={API-VERSION}
| Zástupný symbol | Hodnota | Příklad |
|---|---|---|
{ENDPOINT} |
Koncový bod pro ověření požadavku rozhraní API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
Verze rozhraní API, které voláte. Hodnota, na kterou se zde odkazuje, je určená pro nejnovější vydané verze. Další informace o dalších dostupných verzích rozhraní API najdete v tématu Životní cyklus modelu. | 2022-05-01 |
Hlavičky
| Key | Hodnota |
|---|---|
| Ocp-Apim-Subscription-Key | Váš klíč, který poskytuje přístup k tomuto rozhraní API. |
Body
{
"displayName": "Classifying documents",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "{LANGUAGE-CODE}",
"text": "Text1"
},
{
"id": "2",
"language": "{LANGUAGE-CODE}",
"text": "Text2"
}
]
},
"tasks": [
{
"kind": "CustomMultiLabelClassification",
"taskName": "Multi Label Classification",
"parameters": {
"projectName": "{PROJECT-NAME}",
"deploymentName": "{DEPLOYMENT-NAME}"
}
}
]
}
| Key | Zástupný symbol | Hodnota | Příklad |
|---|---|---|---|
displayName |
{JOB-NAME} |
Název vaší práce. | MyJobName |
documents |
[{},{}] | Seznam dokumentů, na kterých se mají spouštět úkoly | [{},{}] |
id |
{DOC-ID} |
Název nebo ID dokumentu | doc1 |
language |
{LANGUAGE-CODE} |
Řetězec určující kód jazyka dokumentu. Pokud tento klíč není zadaný, služba bude předpokládat výchozí jazyk projektu, který byl vybrán během vytváření projektu. Seznam podporovaných jazykových kódů najdete v podpoře jazyků. | en-us |
text |
{DOC-TEXT} |
Úlohu dokumentu, ve které chcete úkoly spouštět. | Lorem ipsum dolor sit amet |
tasks |
Seznam úkolů, které chceme provést | [] |
|
taskName |
CustomMultiLabelClassification | Název úkolu | CustomMultiLabelClassification |
parameters |
Seznam parametrů, které se mají předat úkolu | ||
project-name |
{PROJECT-NAME} |
Název projektu. U této hodnoty se rozlišují malá a velká písmena. | myProject |
deployment-name |
{DEPLOYMENT-NAME} |
Název nasazení. U této hodnoty se rozlišují malá a velká písmena. | prod |
Response
Zobrazí se odpověď 202 označující úspěch. V hlavičce odpovědi extrahujte operation-location.
operation-location je formátovaný takto:
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
Tuto adresu URL můžete použít k dotazování stavu dokončení úkolu a získání výsledků po dokončení úkolu.
Získání výsledků úkolů
Pomocí následujícího požadavku GET zadejte dotaz na stav nebo výsledky úlohy klasifikace textu.
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
| Zástupný symbol | Hodnota | Příklad |
|---|---|---|
{ENDPOINT} |
Koncový bod pro ověření požadavku rozhraní API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
Verze rozhraní API, které voláte. Hodnota, na kterou odkazujeme, je určená pro nejnovější verzi vydané verze modelu. | 2022-05-01 |
Hlavičky
| Key | Hodnota |
|---|---|
| Ocp-Apim-Subscription-Key | Váš klíč, který poskytuje přístup k tomuto rozhraní API. |
Text odpovědi
Odpověď bude dokument JSON s následujícími parametry.
{
"createdDateTime": "2021-05-19T14:32:25.578Z",
"displayName": "MyJobName",
"expirationDateTime": "2021-05-19T14:32:25.578Z",
"jobId": "xxxx-xxxxxx-xxxxx-xxxx",
"lastUpdateDateTime": "2021-05-19T14:32:25.578Z",
"status": "succeeded",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "customMultiClassificationTasks",
"taskName": "Classify documents",
"lastUpdateDateTime": "2020-10-01T15:01:03Z",
"status": "succeeded",
"results": {
"documents": [
{
"id": "{DOC-ID}",
"classes": [
{
"category": "Class_1",
"confidenceScore": 0.0551877357
}
],
"warnings": []
}
],
"errors": [],
"modelVersion": "2020-04-01"
}
}
]
}
}
Vyčištění prostředků
Pokud už projekt nepotřebujete, můžete ho odstranit pomocí následujícího požadavku DELETE . Zástupné hodnoty nahraďte vlastními hodnotami.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}?api-version={API-VERSION}
| Zástupný symbol | Hodnota | Příklad |
|---|---|---|
{ENDPOINT} |
Koncový bod pro ověření požadavku rozhraní API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Název projektu. U této hodnoty se rozlišují malá a velká písmena. | myProject |
{API-VERSION} |
Verze rozhraní API, které voláte. Hodnota, na kterou se zde odkazuje, je určená pro nejnovější vydané verze. Další informace o dalších dostupných verzích rozhraní API | 2022-05-01 |
Hlavičky
K ověření požadavku použijte následující hlavičku.
| Key | Hodnota |
|---|---|
| Ocp-Apim-Subscription-Key | Klíč k vašemu prostředku. Používá se k ověřování požadavků rozhraní API. |
Po odeslání požadavku rozhraní API obdržíte 202 odpověď s informací o úspěchu, což znamená, že projekt byl odstraněn. Výsledky úspěšného volání se záhlavím Operation-Location sloužícím ke kontrole stavu úlohy.
Další kroky
Po vytvoření vlastního modelu klasifikace textu můžete:
Když začnete vytvářet vlastní projekty klasifikace textu, pomocí článků s postupy se dozvíte více o vývoji modelu podrobněji: