Kopírování dat z Amazon RDS pro SQL Server pomocí Azure Data Factory nebo Azure Synapse Analytics
Tento článek popisuje, jak pomocí aktivity kopírování v kanálech Azure Data Factory a Azure Synapse kopírovat data z Amazon RDS pro databázi SQL Serveru. Další informace najdete v úvodním článku pro Azure Data Factory nebo Azure Synapse Analytics.
Podporované funkce
Tento konektor Amazon RDS pro SQL Server je podporovaný pro následující funkce:
| Podporované funkce | IR |
|---|---|
| aktivita Copy (zdroj/-) | ① ② |
| Aktivita Lookup | ① ② |
| Aktivita GetMetadata | ① ② |
| Aktivita uložená procedura | ① ② |
(1) Prostředí Azure Integration Runtime (2) Místní prostředí Integration Runtime
Seznam úložišť dat podporovaných jako zdroje nebo jímky aktivitou kopírování najdete v tabulce Podporované úložiště dat.
Konkrétně tento konektor Amazon RDS pro SQL Server podporuje:
- SQL Server verze 2005 a novější
- Kopírování dat pomocí ověřování SQL nebo Windows
- Jako zdroj načítá data pomocí dotazu SQL nebo uložené procedury. Můžete se také rozhodnout pro paralelní kopírování ze služby Amazon RDS pro zdroj SQL Serveru. Podrobnosti najdete v části Paralelní kopírování z databáze SQL.
SQL Server Express LocalDB není podporován.
Požadavky
Pokud se vaše úložiště dat nachází uvnitř místní sítě, virtuální sítě Azure nebo amazonového privátního cloudu, musíte nakonfigurovat místní prostředí Integration Runtime pro připojení k němu.
Pokud je vaše úložiště dat spravovanou cloudovou datovou službou, můžete použít Azure Integration Runtime. Pokud je přístup omezený na IP adresy schválené v pravidlech brány firewall, můžete do seznamu povolených přidat IP adresy prostředí Azure Integration Runtime.
K přístupu k místní síti bez nutnosti instalace a konfigurace místního prostředí Integration Runtime můžete také použít funkci Runtime integrace spravované virtuální sítě ve službě Azure Data Factory.
Další informace o mechanismech zabezpečení sítě a možnostech podporovaných službou Data Factory najdete v tématu Strategie přístupu k datům.
Začínáme
K provedení aktivita Copy s kanálem můžete použít jeden z následujících nástrojů nebo sad SDK:
- Nástroj pro kopírování dat
- Azure Portal
- Sada .NET SDK
- Sada Python SDK
- Azure PowerShell
- Rozhraní REST API
- Šablona Azure Resource Manageru
Vytvoření propojené služby Amazon RDS pro SQL Server pomocí uživatelského rozhraní
Pomocí následujících kroků vytvořte propojenou službu Amazon RDS pro SQL Server v uživatelském rozhraní webu Azure Portal.
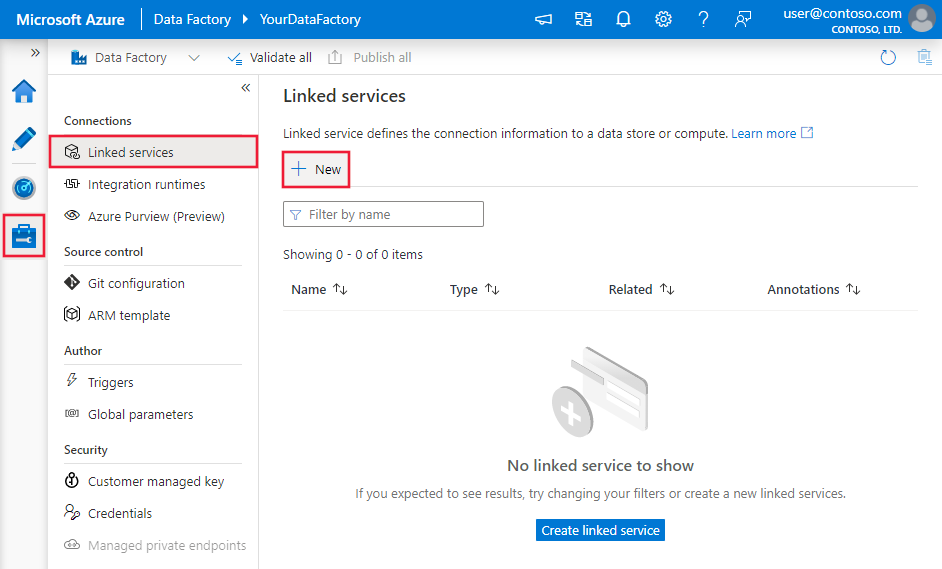
Přejděte na kartu Správa v pracovním prostoru Azure Data Factory nebo Synapse a vyberte Propojené služby a pak klikněte na Nový:
Vyhledejte Amazon RDS pro SQL server a vyberte Amazon RDS pro konektor SQL Serveru.
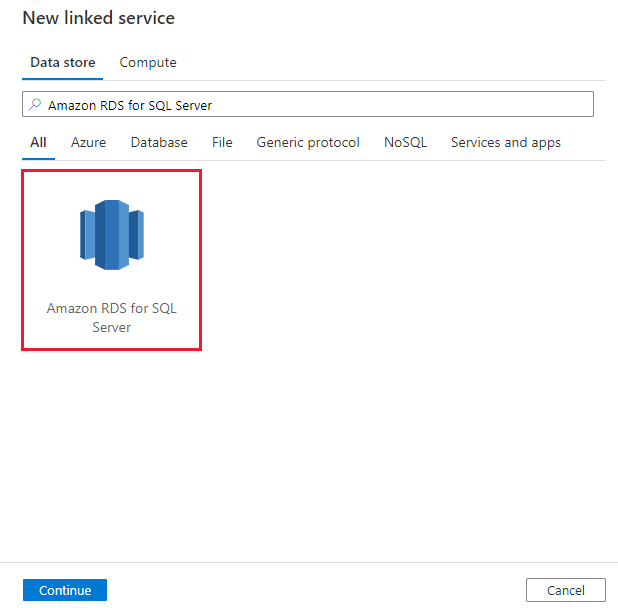
Nakonfigurujte podrobnosti o službě, otestujte připojení a vytvořte novou propojenou službu.
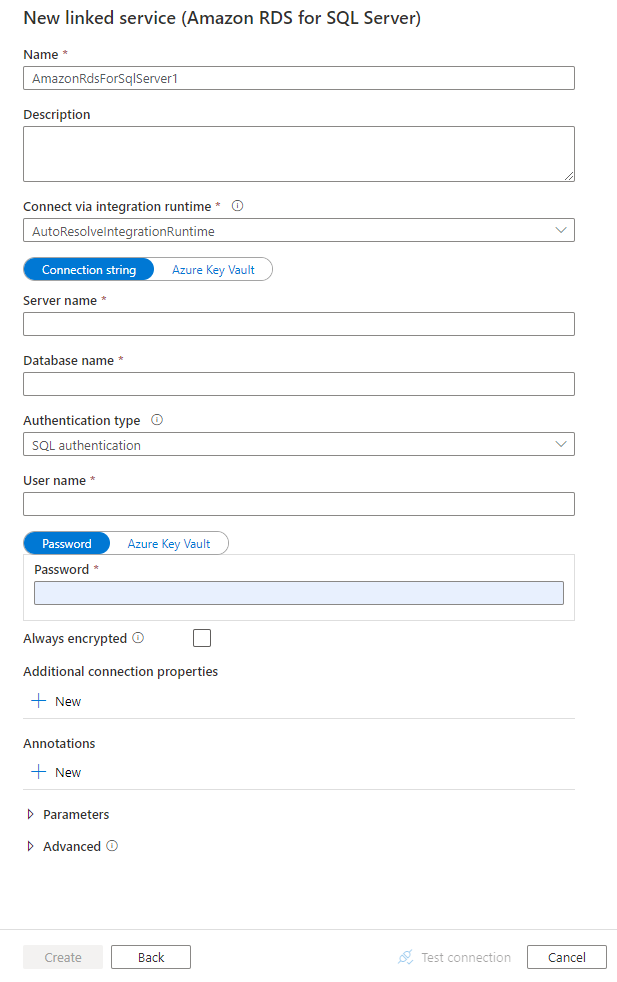
podrobnosti o konfiguraci Připojení oru
Následující části obsahují podrobnosti o vlastnostech, které se používají k definování entit kanálu Data Factory a Synapse specifických pro konektor databáze Amazon RDS pro SQL Server.
Vlastnosti propojené služby
Pro propojenou službu Amazon RDS pro SQL Server jsou podporovány následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu musí být nastavena na AmazonRdsForSqlServer. | Ano |
| připojovací řetězec | Zadejte informace o připojovacím řetězce , které jsou potřeba pro připojení k databázi Amazon RDS pro SQL Server pomocí ověřování SQL nebo ověřování systému Windows. Projděte si následující ukázky. Do služby Azure Key Vault můžete také zadat heslo. Pokud se jedná o ověřování SQL, vytáhněte password konfiguraci z připojovací řetězec. Další informace najdete v příkladu JSON, který následuje za tabulkou a přihlašovacími údaji k úložišti ve službě Azure Key Vault. |
Ano |
| userName | Pokud používáte ověřování systému Windows, zadejte uživatelské jméno. Příkladem je název_domény\uživatelské_jméno. | No |
| Heslo | Zadejte heslo pro uživatelský účet, který jste zadali pro uživatelské jméno. Označte toto pole jako SecureString , abyste ho bezpečně uložili. Nebo můžete odkazovat na tajný klíč uložený ve službě Azure Key Vault. | No |
| alwaysEncrypted Nastavení | Zadejte informace o alwaysencryptedsettings , které jsou potřeba k povolení funkce Always Encrypted k ochraně citlivých dat uložených v Amazon RDS pro SQL Server pomocí spravované identity nebo instančního objektu. Další informace najdete v příkladu JSON podle tabulky a použití oddílu Always Encrypted . Pokud není zadáno, výchozí nastavení always encrypted je zakázané. | No |
| connectVia | Tento modul runtime integrace slouží k připojení k úložišti dat. Další informace najdete v části Požadavky . Pokud není zadaný, použije se výchozí prostředí Azure Integration Runtime. | No |
Poznámka:
Amazon RDS pro SQL Server Always Encrypted se v toku dat nepodporuje.
Tip
Pokud dojde k chybě s kódem chyby UserErrorFailedTo Připojení ToSqlServer a zobrazí se zpráva typu Limit relace pro databázi XXX a bylo dosaženo, přidejte Pooling=false do svého připojovací řetězec a zkuste to znovu.
Příklad 1: Použití ověřování SQL
{
"name": "AmazonSqlLinkedService",
"properties": {
"type": "AmazonRdsForSqlServer",
"typeProperties": {
"connectionString": "Data Source=<servername>\\<instance name if using named instance>;Initial Catalog=<databasename>;Integrated Security=False;User ID=<username>;Password=<password>;"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Příklad 2: Použití ověřování SQL s heslem ve službě Azure Key Vault
{
"name": "AmazonSqlLinkedService",
"properties": {
"type": "AmazonRdsForSqlServer",
"typeProperties": {
"connectionString": "Data Source=<servername>\\<instance name if using named instance>;Initial Catalog=<databasename>;Integrated Security=False;User ID=<username>;",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Příklad 3: Použití ověřování systému Windows
{
"name": "AmazonSqlLinkedService",
"properties": {
"type": "AmazonRdsForSqlServer",
"typeProperties": {
"connectionString": "Data Source=<servername>\\<instance name if using named instance>;Initial Catalog=<databasename>;Integrated Security=True;",
"userName": "<domain\\username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Příklad 4: Použití funkce Always Encrypted
{
"name": "AmazonSqlLinkedService",
"properties": {
"type": "AmazonRdsForSqlServer",
"typeProperties": {
"connectionString": "Data Source=<servername>\\<instance name if using named instance>;Initial Catalog=<databasename>;Integrated Security=False;User ID=<username>;Password=<password>;"
},
"alwaysEncryptedSettings": {
"alwaysEncryptedAkvAuthType": "ServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Vlastnosti datové sady
Úplný seznam oddílů a vlastností dostupných pro definování datových sad najdete v článku o datových sadách . Tato část obsahuje seznam vlastností podporovaných službou Amazon RDS pro datovou sadu SQL Serveru.
Pokud chcete kopírovat data z databáze Amazon RDS pro databázi SQL Serveru, podporují se následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu datové sady musí být nastavena na AmazonRdsForSqlServerTable. | Ano |
| schema | Název schématu | No |
| table | Název tabulky nebo zobrazení | No |
| tableName | Název tabulky nebo zobrazení se schématem Tato vlastnost je podporována pro zpětnou kompatibilitu. Pro nové úlohy použijte schema a table. |
No |
Příklad
{
"name": "AmazonRdsForSQLServerDataset",
"properties":
{
"type": "AmazonRdsForSqlServerTable",
"linkedServiceName": {
"referenceName": "<Amazon RDS for SQL Server linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}
Vlastnosti aktivity kopírování
Úplný seznam oddílů a vlastností dostupných k definování aktivit najdete v článku Pipelines . Tato část obsahuje seznam vlastností podporovaných službou Amazon RDS pro zdroj SQL Serveru.
Amazon RDS pro SQL Server jako zdroj
Tip
Pokud chcete efektivně načítat data z Amazon RDS pro SQL Server pomocí dělení dat, přečtěte si další informace z paralelní kopie z databáze SQL.
Pokud chcete kopírovat data z Amazon RDS pro SQL Server, nastavte typ zdroje v aktivitě kopírování na AmazonRdsForSqlServerSource. Ve zdrojové části aktivity kopírování jsou podporovány následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu zdroje aktivity kopírování musí být nastavena na AmazonRdsForSqlServerSource. | Ano |
| sqlReaderQuery | Ke čtení dat použijte vlastní dotaz SQL. Příklad: select * from MyTable. |
No |
| sqlReaderStoredProcedureName | Tato vlastnost je název uložené procedury, která čte data ze zdrojové tabulky. Poslední příkaz SQL musí být příkaz SELECT v uložené proceduře. | No |
| storedProcedureParameters | Tyto parametry jsou určené pro uloženou proceduru. Povolené hodnoty jsou dvojice názvů nebo hodnot. Názvy a velikost písmen parametrů musí odpovídat názvům a velikostem písmen parametrů uložené procedury. |
No |
| Isolationlevel | Určuje chování uzamčení transakce pro zdroj SQL. Povolené hodnoty jsou: ReadCommitted, ReadUncommitted, RepeatableRead, Serializable, Snapshot. Pokud není zadáno, použije se výchozí úroveň izolace databáze. Další podrobnosti najdete v tomto dokumentu . | No |
| partitionOptions | Určuje možnosti dělení dat používané k načtení dat z Amazon RDS pro SQL Server. Povolené hodnoty jsou: None (výchozí), PhysicalPartitionsOfTable a DynamicRange. Pokud je povolená možnost oddílu (tj. ne None), stupeň paralelismu souběžného načítání dat z Amazon RDS pro SQL Server je řízen parallelCopies nastavením aktivity kopírování. |
No |
| oddíl Nastavení | Zadejte skupinu nastavení pro dělení dat. Použít, pokud možnost oddílu není None. |
No |
V části partitionSettings: |
||
| partitionColumnName | Zadejte název zdrojového sloupce v celočíselném čísle nebo typu date/datetime (int, smallint, bigint, smalldatetimedate, , datetime, datetime2nebo datetimeoffset), který bude použit dělením rozsahu pro paralelní kopírování. Pokud není zadaný, index nebo primární klíč tabulky se automaticky rozpozná a použije jako sloupec oddílu.Použít, pokud je DynamicRangemožnost oddílu . Pokud k načtení zdrojových dat použijete dotaz, připojte se ?AdfDynamicRangePartitionCondition do klauzule WHERE. Příklad najdete v části Paralelní kopírování z databáze SQL. |
No |
| partitionUpperBound | Maximální hodnota sloupce oddílu pro rozdělení rozsahu oddílů. Tato hodnota se používá k rozhodování o kroku oddílu, nikoli k filtrování řádků v tabulce. Všechny řádky v tabulce nebo výsledku dotazu se rozdělí a zkopírují. Pokud není zadáno, aktivita kopírování automaticky rozpozná hodnotu. Použít, pokud je DynamicRangemožnost oddílu . Příklad najdete v části Paralelní kopírování z databáze SQL. |
No |
| partitionLowerBound | Minimální hodnota sloupce oddílu pro rozdělení rozsahu oddílů. Tato hodnota se používá k rozhodování o kroku oddílu, nikoli k filtrování řádků v tabulce. Všechny řádky v tabulce nebo výsledku dotazu se rozdělí a zkopírují. Pokud není zadáno, aktivita kopírování automaticky rozpozná hodnotu. Použít, pokud je DynamicRangemožnost oddílu . Příklad najdete v části Paralelní kopírování z databáze SQL. |
No |
Je třeba počítat s následujícím:
- Pokud je pro AmazonRdsForSqlServerSource zadán sqlReaderQuery, aktivita kopírování spustí tento dotaz na Amazon RDS pro zdroj SQL Serveru, aby získala data. Uloženou proceduru můžete také zadat zadáním sqlReaderStoredProcedureName a storedProcedureParameters , pokud uložená procedura přebírá parametry.
- Při použití uložené procedury ve zdroji k načtení dat si všimněte, že uložená procedura je navržena jako vrácení jiného schématu, pokud je předána jiná hodnota parametru, může dojít k selhání nebo může dojít k neočekávanému výsledku při importu schématu z uživatelského rozhraní nebo při kopírování dat do databáze SQL s automatickým vytvořením tabulky.
Příklad: Použití dotazu SQL
"activities":[
{
"name": "CopyFromAmazonRdsForSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<Amazon RDS for SQL Server input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AmazonRdsForSqlServerSource",
"sqlReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Příklad: Použití uložené procedury
"activities":[
{
"name": "CopyFromAmazonRdsForSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<Amazon RDS for SQL Server input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AmazonRdsForSqlServerSource",
"sqlReaderStoredProcedureName": "CopyTestSrcStoredProcedureWithParameters",
"storedProcedureParameters": {
"stringData": { "value": "str3" },
"identifier": { "value": "$$Text.Format('{0:yyyy}', <datetime parameter>)", "type": "Int"}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Definice uložené procedury
CREATE PROCEDURE CopyTestSrcStoredProcedureWithParameters
(
@stringData varchar(20),
@identifier int
)
AS
SET NOCOUNT ON;
BEGIN
select *
from dbo.UnitTestSrcTable
where dbo.UnitTestSrcTable.stringData != stringData
and dbo.UnitTestSrcTable.identifier != identifier
END
GO
Paralelní kopírování z databáze SQL
Konektor Amazon RDS pro SQL Server v aktivitě kopírování poskytuje integrované dělení dat pro paralelní kopírování dat. Možnosti dělení dat najdete na kartě Zdroj aktivity kopírování.
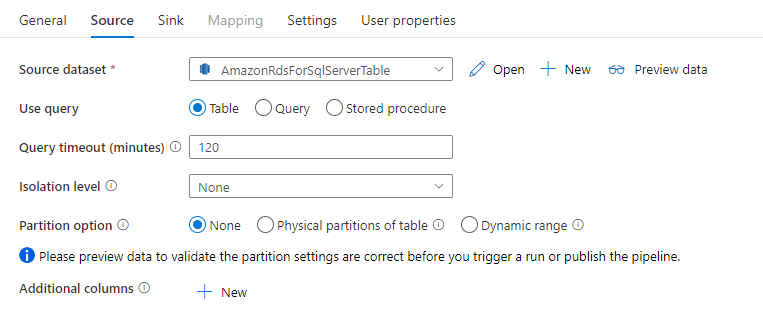
Když povolíte dělené kopírování, aktivita kopírování spouští paralelní dotazy na zdroj Amazon RDS pro zdroj SQL Serveru pro načtení dat podle oddílů. Paralelní stupeň se řídí parallelCopies nastavením aktivity kopírování. Pokud například nastavíte parallelCopies hodnotu čtyři, služba souběžně vygeneruje a spouští čtyři dotazy na základě zadané možnosti a nastavení oddílu a každý dotaz načte část dat z Amazon RDS pro SQL Server.
Doporučujeme povolit paralelní kopírování s dělením dat, zejména pokud načítáte velké množství dat z Amazon RDS pro SQL Server. Následující konfigurace jsou navržené pro různé scénáře. Při kopírování dat do souborového úložiště dat se doporučuje zapisovat do složky jako více souborů (zadat pouze název složky), v takovém případě je výkon lepší než zápis do jednoho souboru.
| Scénář | Navrhovaná nastavení |
|---|---|
| Úplné načtení z velké tabulky s fyzickými oddíly | Možnost oddílu: Fyzické oddíly tabulky. Během provádění služba automaticky rozpozná fyzické oddíly a kopíruje data podle oddílů. Pokud chcete zkontrolovat, jestli tabulka obsahuje fyzický oddíl nebo ne, můžete odkazovat na tento dotaz. |
| Úplné načtení z velké tabulky bez fyzických oddílů, zatímco s celočíselnou nebo datetime sloupcem pro dělení dat. | Možnosti oddílu: Oddíl dynamického rozsahu Sloupec oddílu (volitelné): Zadejte sloupec použitý k dělení dat. Pokud není zadaný, použije se sloupec primárního klíče. Horní mez oddílu a dolní mez oddílu (volitelné): Určete, jestli chcete určit krok oddílu. To není pro filtrování řádků v tabulce, všechny řádky v tabulce budou rozděleny a zkopírovány. Pokud není zadáno, aktivita kopírování automaticky zjistí hodnoty a může trvat dlouhou dobu v závislosti na hodnotách MIN a MAX. Doporučuje se zadat horní mez a dolní mez. Pokud má například sloupec oddílu ID hodnoty od 1 do 100 a dolní mez nastavíte jako 20 a horní mez jako 80, přičemž paralelní kopírování je 4, služba načte data o 4 oddílech – ID v rozsahu <=20, [21, 50], [51, 80] a >=81. |
| Načtěte velké množství dat pomocí vlastního dotazu bez fyzických oddílů, zatímco s celočíselnou nebo datem a datem a časem pro dělení dat. | Možnosti oddílu: Oddíl dynamického rozsahu Dotaz: SELECT * FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition AND <your_additional_where_clause>.Sloupec oddílu: Zadejte sloupec použitý k rozdělení dat. Horní mez oddílu a dolní mez oddílu (volitelné): Určete, jestli chcete určit krok oddílu. To není pro filtrování řádků v tabulce, všechny řádky ve výsledku dotazu budou rozděleny a zkopírovány. Pokud není zadáno, aktivita kopírování automaticky rozpozná hodnotu. Během provádění služba nahradí ?AdfRangePartitionColumnName skutečný název sloupce a rozsahy hodnot pro každý oddíl a odešle do Amazon RDS pro SQL Server. Pokud má například sloupec oddílu ID hodnoty od 1 do 100 a dolní mez nastavíte jako 20 a horní mez 80, přičemž paralelní kopírování je 4, služba načte data podle 4 oddílů v rozsahu <=20, [21, 50], [51, 80] a >=81. Tady jsou další ukázkové dotazy pro různé scénáře: 1. Dotaz na celou tabulku: SELECT * FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition2. Dotaz z tabulky s výběrem sloupce a dalšími filtry klauzule where: SELECT <column_list> FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition AND <your_additional_where_clause>3. Dotaz s poddotazy: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?AdfDynamicRangePartitionCondition AND <your_additional_where_clause>4. Dotaz s oddílem v poddotazu: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition) AS T |
Osvědčené postupy pro načtení dat s možností oddílu:
- Zvolte výrazný sloupec jako sloupec oddílu (například primární klíč nebo jedinečný klíč), abyste se vyhnuli nerovnoměrné distribuci dat.
- Pokud tabulka obsahuje předdefinovaný oddíl, použijte možnost oddílu Fyzické oddíly tabulky, abyste dosáhli lepšího výkonu.
- Pokud ke kopírování dat používáte Prostředí Azure Integration Runtime, můžete nastavit větší počet jednotek Integrace Dat (DIU) (>4) a využít tak více výpočetních prostředků. Zkontrolujte tam příslušné scénáře.
- "Stupeň paralelismu kopírování" řídí čísla oddílů, nastavení příliš velkého čísla někdy snižuje výkon, doporučujeme nastavit toto číslo jako (DIU nebo počet uzlů místního prostředí IR) * (2 až 4).
Příklad: Úplné načtení z velké tabulky s fyzickými oddíly
"source": {
"type": "AmazonRdsForSqlServerSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Příklad: Dotaz s oddílem dynamického rozsahu
"source": {
"type": "AmazonRdsForSqlServerSource",
"query": "SELECT * FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
Ukázkový dotaz pro kontrolu fyzického oddílu
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Pokud tabulka obsahuje fyzický oddíl, zobrazí se "HasPartition" jako "ano", například následující.

Vlastnosti aktivity vyhledávání
Podrobnosti o vlastnostech najdete v aktivitě Vyhledávání.
Vlastnosti aktivity GetMetadata
Podrobnosti o vlastnostech najdete v aktivitě GetMetadata.
Použití funkce Always Encrypted
Při kopírování dat z/do Amazon RDS pro SQL Server s funkcí Always Encrypted postupujte následovně:
Uložte hlavní klíč sloupce (CMK) ve službě Azure Key Vault. Další informace o konfiguraci funkce Always Encrypted pomocí služby Azure Key Vault
Nezapomeňte udělit přístup k trezoru klíčů, kde je uložený hlavní klíč sloupce (CMK ). Požadovaná oprávnění najdete v tomto článku .
Vytvořte propojenou službu pro připojení k databázi SQL a povolte funkci Always Encrypted pomocí spravované identity nebo instančního objektu.
Odstraňování potíží s připojením
Nakonfigurujte službu Amazon RDS pro instanci SQL Serveru tak, aby přijímala vzdálená připojení. Spusťte Amazon RDS pro SQL Server Management Studio, klikněte pravým tlačítkem myši na server a vyberte Vlastnosti. V seznamu vyberte Připojení iony a zaškrtněte políčko Povolit vzdálená připojení k tomuto serveru.
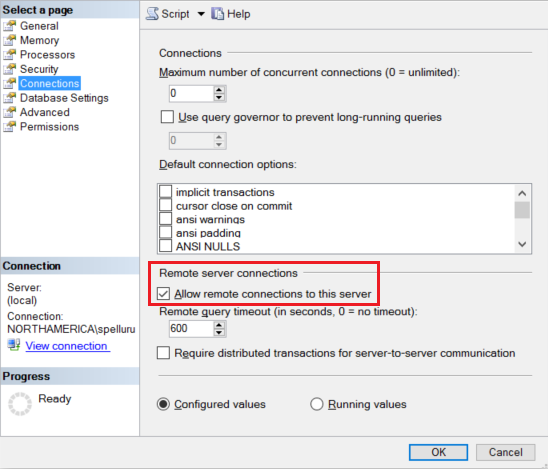
Podrobný postup najdete v tématu Konfigurace možnosti konfigurace serveru vzdáleného přístupu.
Spusťte Amazon RDS pro SQL Server Configuration Manager. Rozbalte Amazon RDS pro konfiguraci sítě SQL Serveru pro požadovanou instanci a vyberte Protokoly pro MSSQLSERVER. Protokoly se zobrazí v pravém podokně. Povolte tcp/IP tak, že kliknete pravým tlačítkem na TCP/IP a vyberete Povolit.
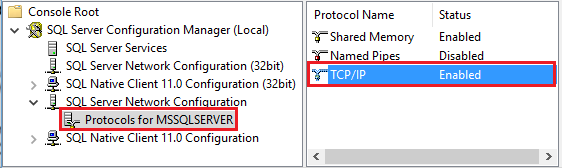
Další informace a alternativní způsoby povolení protokolu TCP/IP naleznete v tématu Povolení nebo zakázání síťového protokolu serveru.
Ve stejném okně poklikejte na tcp/IP a spusťte okno Vlastnosti protokolu TCP/IP.
Přepněte na kartu IP adresy . Posuňte se dolů a zobrazte část IPAll . Zapište port TCP. Výchozí hodnota je 1433.
Vytvořte pravidlo pro bránu Windows Firewall na počítači, které povolí příchozí provoz přes tento port.
Ověřte připojení: Pokud se chcete připojit k Amazon RDS pro SQL Server pomocí plně kvalifikovaného názvu, použijte Amazon RDS pro SQL Server Management Studio z jiného počítače. Příklad:
"<machine>.<domain>.corp.<company>.com,1433".
Související obsah
Seznam úložišť dat podporovaných jako zdroje a jímky aktivitou kopírování najdete v tématu Podporované úložiště dat.