Mapování schématu a datového typu v aktivitě kopírování
PLATÍ PRO: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Tento článek popisuje, jak aktivita kopírování služby Azure Data Factory provádí mapování schématu a mapování datového typu ze zdrojových dat na data jímky.
Schema mapping
Výchozí mapování
Ve výchozím nastavení aktivita kopírování mapuje zdrojová data na jímku podle názvů sloupců a rozlišují se malá a velká písmena. Pokud jímka neexistuje, například zápis do souborů, názvy zdrojových polí se zachovají jako názvy jímky. Pokud jímka již existuje, musí obsahovat všechny sloupce, které se kopírují ze zdroje. Takové výchozí mapování podporuje flexibilní schémata a posun schématu od zdroje k jímce od spuštění ke spuštění – všechna data vrácená zdrojovým úložištěm dat je možné zkopírovat do jímky.
Pokud je zdrojem textový soubor bez řádku záhlaví, explicitní mapování se vyžaduje, protože zdroj neobsahuje názvy sloupců.
Explicitní mapování
Můžete také určit explicitní mapování pro přizpůsobení mapování sloupců a polí ze zdroje na jímku podle potřeby. Pomocí explicitního mapování můžete zkopírovat pouze částečná zdrojová data do jímky nebo namapovat zdrojová data do jímky s různými názvy nebo změnit tvar tabulkových nebo hierarchických dat. aktivita Copy:
- Načte data ze zdroje a určí zdrojové schéma.
- Použije definované mapování.
- Zapíše data do jímky.
Přečtěte si další informace:
- Tabulkový zdroj do tabulkové jímky
- Hierarchický zdroj do tabulkové jímky
- Tabulkový/hierarchický zdroj do hierarchické jímky
Mapování můžete nakonfigurovat v uživatelském rozhraní pro vytváření –> aktivita kopírování –> karta mapování nebo programově určit mapování v aktivitě kopírování –>translator vlastnost. Následující vlastnosti jsou podporovány v translator>mappings polích -> objekty ->source a sink, které odkazuje na konkrétní sloupec nebo pole pro mapování dat.
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| name | Název sloupce nebo pole zdroje nebo jímky Platí pro tabulkový zdroj a jímku. | Ano |
| Pořadové | Index sloupce Začněte od 1. Použití a vyžadování při použití textu s oddělovači bez řádku záhlaví |
No |
| path | Výraz cesty JSON pro každé pole pro extrakci nebo mapování Platí pro hierarchický zdroj a jímku, například konektory Azure Cosmos DB, MongoDB nebo REST. U polí pod kořenovým objektem začíná cesta JSON kořenem $; pro pole uvnitř pole zvoleného collectionReference vlastností začíná cesta JSON od elementu pole bez $. |
No |
| type | Dočasný datový typ sloupce zdroje nebo jímky Obecně platí, že tuto vlastnost nemusíte zadávat ani měnit. Přečtěte si další informace o mapování datových typů. | No |
| jazyková verze | Jazyková verze sloupce zdroje nebo jímky Použít, pokud je Datetime typ nebo Datetimeoffset. Výchozí hodnota je en-us.Obecně platí, že tuto vlastnost nemusíte zadávat ani měnit. Přečtěte si další informace o mapování datových typů. |
No |
| format | Formátovací řetězec, který se má použít, pokud je Datetime typ nebo Datetimeoffset. Informace o formátování data a času najdete v textech vlastního formátu data a času. Obecně platí, že tuto vlastnost nemusíte zadávat ani měnit. Přečtěte si další informace o mapování datových typů. |
No |
Kromě těchto vlastností jsou podporovány translator následující mappingsvlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| collectionReference | Použijte při kopírování dat z hierarchického zdroje, jako jsou azure Cosmos DB, MongoDB nebo konektory REST. Pokud chcete iterovat a extrahovat data z objektů uvnitř pole se stejným vzorem a převést na každý řádek na objekt, zadejte cestu JSON tohoto pole, která se má provést křížově. |
No |
Tabulkový zdroj do tabulkové jímky
Pokud například chcete zkopírovat data ze Salesforce do Azure SQL Database a explicitně namapovat tři sloupce:
Při aktivitě kopírování –> karta mapování klikněte na tlačítko Importovat schémata a importujte schémata zdroje i jímky.
Namapujte potřebná pole a vyloučíte nebo odstraňte zbytek.

Stejné mapování lze nakonfigurovat jako následující v datové části aktivity kopírování (viz translator):
{
"name": "CopyActivityTabularToTabular",
"type": "Copy",
"typeProperties": {
"source": { "type": "SalesforceSource" },
"sink": { "type": "SqlSink" },
"translator": {
"type": "TabularTranslator",
"mappings": [
{
"source": { "name": "Id" },
"sink": { "name": "CustomerID" }
},
{
"source": { "name": "Name" },
"sink": { "name": "LastName" }
},
{
"source": { "name": "LastModifiedDate" },
"sink": { "name": "ModifiedDate" }
}
]
}
},
...
}
Pokud chcete kopírovat data z textových souborů s oddělovači bez řádku záhlaví, sloupce jsou místo názvů reprezentovány pořadovým řádkem.
{
"name": "CopyActivityTabularToTabular",
"type": "Copy",
"typeProperties": {
"source": { "type": "DelimitedTextSource" },
"sink": { "type": "SqlSink" },
"translator": {
"type": "TabularTranslator",
"mappings": [
{
"source": { "ordinal": "1" },
"sink": { "name": "CustomerID" }
},
{
"source": { "ordinal": "2" },
"sink": { "name": "LastName" }
},
{
"source": { "ordinal": "3" },
"sink": { "name": "ModifiedDate" }
}
]
}
},
...
}
Hierarchický zdroj do tabulkové jímky
Při kopírování dat z hierarchického zdroje do tabulkové jímky podporuje aktivita kopírování následující možnosti:
- Extrahujte data z objektů a polí.
- Křížové použití více objektů se stejným vzorem z pole, v takovém případě chcete převést jeden objekt JSON na více záznamů v tabulkovém výsledku.
K pokročilejší hierarchické a tabulkové transformaci můžete použít Tok dat.
Pokud máte například zdrojový dokument MongoDB s následujícím obsahem:
{
"id": {
"$oid": "592e07800000000000000000"
},
"number": "01",
"date": "20170122",
"orders": [
{
"prod": "p1",
"price": 23
},
{
"prod": "p2",
"price": 13
},
{
"prod": "p3",
"price": 231
}
],
"city": [ { "name": "Seattle" } ]
}
A chcete ho zkopírovat do textového souboru v následujícím formátu s řádkem záhlaví tak, že zploštějí data uvnitř pole (order_pd a order_price) a kříží spojení s běžnými kořenovými informacemi (číslo, datum a město):<
| Ordernumber | orderDate | order_pd | order_price | city |
|---|---|---|---|---|
| 01 | 20170122 | O1 | 23 | Seattle |
| 01 | 20170122 | P2 | 13 | Seattle |
| 01 | 20170122 | P3 | 231 | Seattle |
Toto mapování můžete definovat v uživatelském rozhraní pro vytváření služby Data Factory:
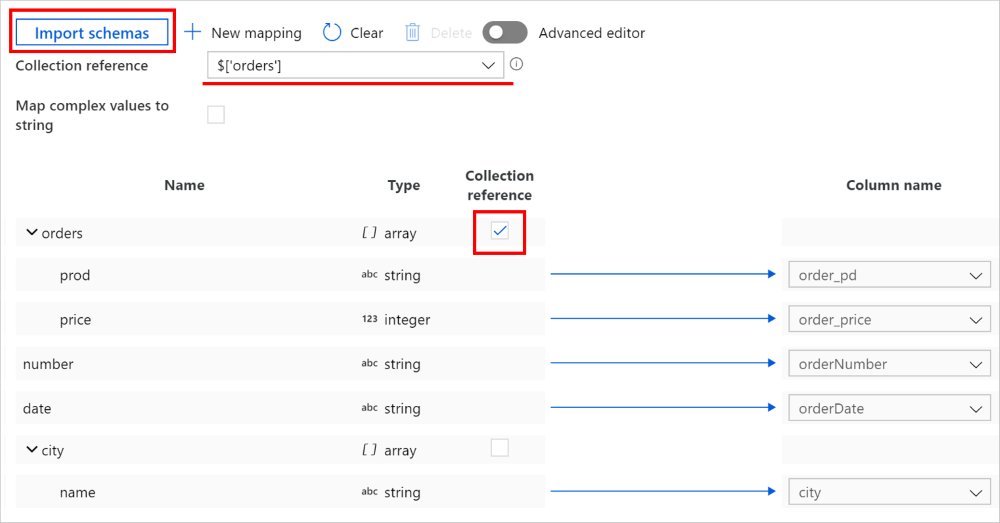
Při aktivitě kopírování –> karta mapování klikněte na tlačítko Importovat schémata a importujte schémata zdroje i jímky. Vzhledem k tomu, že služba při importu schématu vzorkuje několik objektů, můžete ho přidat do správné vrstvy v hierarchii – najet myší na existující název pole a zvolit přidání uzlu, objektu nebo pole.
Vyberte pole, ze kterého chcete iterovat a extrahovat data. Automaticky se vyplní jako odkaz na kolekci. Všimněte si, že pro tuto operaci je podporováno pouze jedno pole.
Namapujte potřebná pole na jímku. Služba automaticky určí odpovídající cesty JSON pro hierarchickou stranu.
Poznámka:
U záznamů, ve kterých je pole označené jako odkaz na kolekci prázdné a je zaškrtnuté políčko, se přeskočí celý záznam.
Můžete také přepnout do rozšířeného editoru, v takovém případě můžete přímo zobrazit a upravit cesty JSON polí. Pokud se rozhodnete přidat nové mapování v tomto zobrazení, zadejte cestu JSON.
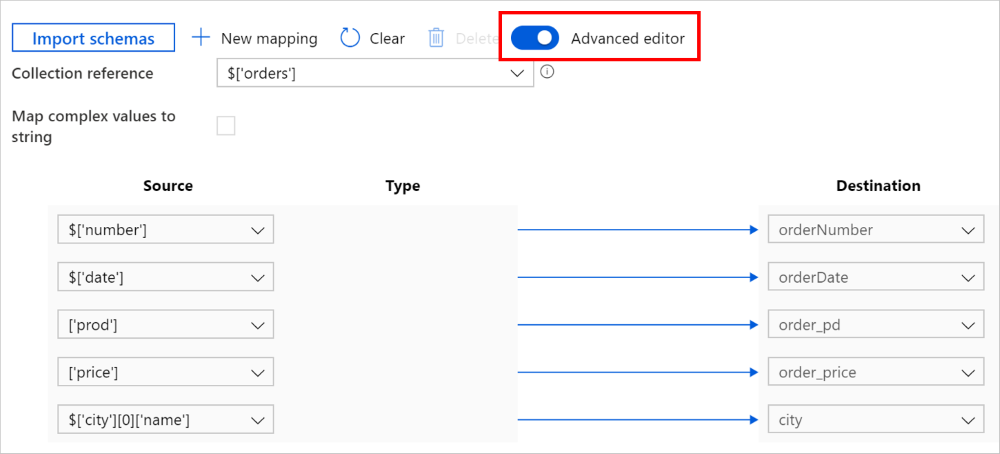
Stejné mapování lze nakonfigurovat jako následující v datové části aktivity kopírování (viz translator):
{
"name": "CopyActivityHierarchicalToTabular",
"type": "Copy",
"typeProperties": {
"source": { "type": "MongoDbV2Source" },
"sink": { "type": "DelimitedTextSink" },
"translator": {
"type": "TabularTranslator",
"mappings": [
{
"source": { "path": "$['number']" },
"sink": { "name": "orderNumber" }
},
{
"source": { "path": "$['date']" },
"sink": { "name": "orderDate" }
},
{
"source": { "path": "['prod']" },
"sink": { "name": "order_pd" }
},
{
"source": { "path": "['price']" },
"sink": { "name": "order_price" }
},
{
"source": { "path": "$['city'][0]['name']" },
"sink": { "name": "city" }
}
],
"collectionReference": "$['orders']"
}
},
...
}
Tabulkový/hierarchický zdroj do hierarchické jímky
Tok uživatelského prostředí je podobný hierarchickému zdroji jako tabulkové jímce.
Při kopírování dat z tabulkového zdroje do hierarchické jímky není zápis do pole uvnitř objektu podporován.
Při kopírování dat z hierarchického zdroje do hierarchické jímky můžete navíc zachovat hierarchii celé vrstvy výběrem objektu nebo pole a mapováním na jímku bez zásahu do vnitřních polí.
K pokročilejší transformaci transformace dat můžete použít Tok dat.
Mapování parametrizace
Pokud chcete vytvořit kanál s šablonou pro dynamické kopírování velkého počtu objektů, určete, jestli můžete využít výchozí mapování , nebo je potřeba definovat explicitní mapování pro příslušné objekty.
Pokud je potřeba explicitní mapování, můžete:
Definujte parametr s typem objektu na úrovni kanálu,
mappingnapříklad .Parametrizace mapování: při aktivitě kopírování –> karta mapování, zvolte přidání dynamického obsahu a vyberte výše uvedený parametr. Datová část aktivity by byla následující:
{ "name": "CopyActivityHierarchicalToTabular", "type": "Copy", "typeProperties": { "source": {...}, "sink": {...}, "translator": { "value": "@pipeline().parameters.mapping", "type": "Expression" }, ... } }Vytvořte hodnotu, která se má předat do parametru mapování. Měl by to být celý objekt
translatordefinice, odkazovat na ukázky v explicitním mapování oddílu. Například pro tabulkový zdroj pro kopírování tabulkové jímky by měla být{"type":"TabularTranslator","mappings":[{"source":{"name":"Id"},"sink":{"name":"CustomerID"}},{"source":{"name":"Name"},"sink":{"name":"LastName"}},{"source":{"name":"LastModifiedDate"},"sink":{"name":"ModifiedDate"}}]}hodnota .
Mapování datového typu
aktivita Copy provádí mapování typů zdrojů na typy jímky s následujícím tokem:
- Převod z nativních zdrojových datových typů na dočasné datové typy používané kanály Azure Data Factory a Synapse
- Automaticky převést dočasný datový typ podle potřeby tak, aby odpovídal odpovídajícím typům jímky, které platí pro výchozí mapování i explicitní mapování.
- Převod z dočasných datových typů na nativní datové typy jímky
aktivita Copy aktuálně podporuje následující dočasné datové typy: Boolean, Byte, Byte, Byte array, Datetime, Datetime, DatetimeOffset, Decimal, Double, GUID, Int16, Int32, Int64, SByte, Single, String, Timespan, UInt16, UInt32 a UInt64.
Mezi dočasnými typy ze zdroje do jímky jsou podporovány následující převody datových typů.
| Zdroj\Jímka | Boolean | Bajtové | Desetinné číslo | Datum a čas (1) | Plovák (2) | Identifikátor GUID | Celé číslo (3) | String | TimeSpan |
|---|---|---|---|---|---|---|---|---|---|
| Boolean | ✓ | ✓ | ✓ | ✓ | ✓ | ||||
| Bajtové | ✓ | ✓ | |||||||
| Datum a čas | ✓ | ✓ | |||||||
| Desetinné číslo | ✓ | ✓ | ✓ | ✓ | ✓ | ||||
| Plovoucí desetiná čárka | ✓ | ✓ | ✓ | ✓ | ✓ | ||||
| Identifikátor GUID | ✓ | ✓ | |||||||
| Integer | ✓ | ✓ | ✓ | ✓ | ✓ | ||||
| String | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| TimeSpan | ✓ | ✓ |
(1) Datum a čas zahrnuje DateTime a DateTimeOffset.
(2) Plovoucí desetiná čárka zahrnuje jednoduché a dvojité.
(3) Celé číslo zahrnuje SByte, Byte, Int16, UInt16, Int32, UInt32, Int64 a UInt64.
Poznámka:
- Tento převod datového typu je v současné době podporován při kopírování mezi tabulkovými daty. Hierarchické zdroje nebo jímky nejsou podporovány, což znamená, že mezi dočasnými typy zdroje a jímky neexistuje žádný převod systémového datového typu.
- Tato funkce funguje s nejnovějším modelem datové sady. Pokud tuto možnost v uživatelském rozhraní nevidíte, zkuste vytvořit novou datovou sadu.
V aktivitě kopírování se podporují následující vlastnosti pro převod datového typu (v translator části pro programové vytváření):
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| typeConversion | Povolte nové prostředí pro převod datového typu. Výchozí hodnota je false z důvodu zpětné kompatibility. U nových aktivit kopírování vytvořených prostřednictvím uživatelského rozhraní služby Data Factory od konce června 2020 je tento převod datového typu ve výchozím nastavení povolený pro nejlepší možnosti a v příslušných scénářích uvidíte následující nastavení> převodu typů. Pokud chcete vytvořit kanál prostřednictvím kódu programu, musíte explicitně nastavit typeConversion vlastnost na true, aby se povolila.U existujících aktivit kopírování vytvořených před vydáním této funkce se v uživatelském rozhraní pro vytváření nezobrazují možnosti převodu typů kvůli zpětné kompatibilitě. |
No |
| typeConversion Nastavení | Skupina nastavení převodu typů. Použít, pokud typeConversion je nastavena na truehodnotu . V této skupině jsou všechny následující vlastnosti. |
No |
Pod typeConversionSettings |
||
| allowDataTruncation | Umožňuje zkrácení dat při převodu zdrojových dat na jímku s jiným typem během kopírování, například z desetinného čísla na celé číslo z DatetimeOffset na Datetime. Výchozí hodnota je true. |
No |
| treatBooleanAsNumber | Považovat logické hodnoty za čísla, například true jako 1. Výchozí hodnotou je false. |
No |
| Datetimeformat | Formátovat řetězec při převodu mezi kalendářními daty bez posunu časového pásma a řetězců, yyyy-MM-dd HH:mm:ss.fffnapříklad . Podrobné informace najdete v tématu Vlastní řetězce formátu data a času. |
No |
| dateTimeOffsetFormat | Formátovat řetězec při převodu mezi kalendářními daty s posunem časového pásma a řetězci, yyyy-MM-dd HH:mm:ss.fff zzznapříklad . Podrobné informace najdete v tématu Vlastní řetězce formátu data a času. |
No |
| timeSpanFormat | Formátovat řetězec při převodu mezi časovými obdobími a řetězci, dd\.hh\:mmnapříklad . Podrobné informace najdete v části Vlastní řetězce formátu TimeSpan. |
No |
| jazyková verze | Informace o jazykové verzi, které se mají použít při převodu typů, en-us například nebo fr-fr. |
No |
Příklad:
{
"name": "CopyActivity",
"type": "Copy",
"typeProperties": {
"source": {
"type": "ParquetSource"
},
"sink": {
"type": "SqlSink"
},
"translator": {
"type": "TabularTranslator",
"typeConversion": true,
"typeConversionSettings": {
"allowDataTruncation": true,
"treatBooleanAsNumber": true,
"dateTimeFormat": "yyyy-MM-dd HH:mm:ss.fff",
"dateTimeOffsetFormat": "yyyy-MM-dd HH:mm:ss.fff zzz",
"timeSpanFormat": "dd\.hh\:mm",
"culture": "en-gb"
}
}
},
...
}
Starší modely
Poznámka:
Následující modely pro mapování zdrojových sloupců nebo polí na jímku jsou stále podporovány, jak je to kvůli zpětné kompatibilitě. Doporučujeme použít nový model uvedený v mapování schématu. Uživatelské rozhraní pro vytváření obsahu se přepnulo na generování nového modelu.
Alternativní mapování sloupců (starší model)
Můžete zadat aktivitu kopírování –>translator pro>columnMappings mapování mezi tabulkovými daty ve tvaru. V tomto případě se pro vstupní i výstupní datové sady vyžaduje oddíl "struktura". Mapování sloupců podporuje mapování všech sloupců nebo podmnožinu sloupců ve zdrojové datové sadě "struktura" na všechny sloupce v datové sadě jímky "structure". Následují chybové podmínky, které vedou k výjimce:
- Výsledek dotazu zdrojového úložiště dat neobsahuje název sloupce zadaný v části struktura vstupní datové sady.
- Úložiště dat jímky (pokud s předdefinovaným schématem) neobsahuje název sloupce, který je zadaný v části struktura "struktury" výstupní datové sady.
- Buď méně sloupců nebo více sloupců v "struktuře" datové sady jímky, než je uvedeno v mapování.
- Duplicitní mapování
V následujícím příkladu má vstupní datová sada strukturu a odkazuje na tabulku v místní databázi Oracle.
{
"name": "OracleDataset",
"properties": {
"structure":
[
{ "name": "UserId"},
{ "name": "Name"},
{ "name": "Group"}
],
"type": "OracleTable",
"linkedServiceName": {
"referenceName": "OracleLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"tableName": "SourceTable"
}
}
}
V této ukázce má výstupní datová sada strukturu a odkazuje na tabulku v Salesforce.
{
"name": "SalesforceDataset",
"properties": {
"structure":
[
{ "name": "MyUserId"},
{ "name": "MyName" },
{ "name": "MyGroup"}
],
"type": "SalesforceObject",
"linkedServiceName": {
"referenceName": "SalesforceLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"tableName": "SinkTable"
}
}
}
Následující JSON definuje aktivitu kopírování v kanálu. Sloupce ze zdroje mapované na sloupce v jímce pomocí vlastnosti translator ->columnMappings .
{
"name": "CopyActivity",
"type": "Copy",
"inputs": [
{
"referenceName": "OracleDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "SalesforceDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": { "type": "OracleSource" },
"sink": { "type": "SalesforceSink" },
"translator":
{
"type": "TabularTranslator",
"columnMappings":
{
"UserId": "MyUserId",
"Group": "MyGroup",
"Name": "MyName"
}
}
}
}
Pokud k určení mapování sloupců používáte syntaxi "columnMappings": "UserId: MyUserId, Group: MyGroup, Name: MyName" , je stále podporována tak, jak je.
Alternativní mapování schématu (starší verze modelu)
Můžete zadat aktivitu kopírování –>translator mapování>schemaMapping mezi hierarchickými daty a tabulkovými daty ve tvaru tabulky, například kopírování z MongoDB/REST do textového souboru a kopírování z Oracle do Azure Cosmos DB for MongoDB. V části aktivity translator kopírování jsou podporovány následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu převaděče aktivity kopírování musí být nastavena na: TabularTranslator | Ano |
| schemaMapping | Kolekce párů klíč-hodnota, která představuje vztah mapování ze strany zdroje na stranu jímky. - Klíč: představuje zdroj. Pro tabulkový zdroj zadejte název sloupce definovaný ve struktuře datové sady. Pro hierarchický zdroj zadejte výraz cesty JSON pro každé pole, které se má extrahovat a mapovat. - Hodnota: představuje jímku. U tabulkové jímky zadejte název sloupce definovaný ve struktuře datové sady. Pro hierarchickou jímku zadejte výraz cesty JSON pro každé pole, které se má extrahovat a mapovat. V případě hierarchických dat začíná cesta JSON pro pole v kořenovém objektu kořenem $; pro pole uvnitř pole zvolené vlastností collectionReference , cesta JSON začíná od elementu pole. |
Ano |
| collectionReference | Pokud chcete iterovat a extrahovat data z objektů uvnitř pole se stejným vzorem a převést na každý řádek na objekt, zadejte cestu JSON tohoto pole, která se má provést křížově. Tato vlastnost je podporována pouze v případě, že je zdroj hierarchických dat. | No |
Příklad: kopírování z MongoDB do Oracle:
Pokud máte například dokument MongoDB s následujícím obsahem:
{
"id": {
"$oid": "592e07800000000000000000"
},
"number": "01",
"date": "20170122",
"orders": [
{
"prod": "p1",
"price": 23
},
{
"prod": "p2",
"price": 13
},
{
"prod": "p3",
"price": 231
}
],
"city": [ { "name": "Seattle" } ]
}
a chcete ho zkopírovat do tabulky Azure SQL v následujícím formátu tak, že zploštějí data uvnitř pole (order_pd a order_price) a křížově spojíte s běžnými kořenovými informacemi (číslo, datum a město):
| Ordernumber | orderDate | order_pd | order_price | city |
|---|---|---|---|---|
| 01 | 20170122 | O1 | 23 | Seattle |
| 01 | 20170122 | P2 | 13 | Seattle |
| 01 | 20170122 | P3 | 231 | Seattle |
Nakonfigurujte pravidlo mapování schématu jako následující ukázku JSON aktivity kopírování:
{
"name": "CopyFromMongoDBToOracle",
"type": "Copy",
"typeProperties": {
"source": {
"type": "MongoDbV2Source"
},
"sink": {
"type": "OracleSink"
},
"translator": {
"type": "TabularTranslator",
"schemaMapping": {
"$.number": "orderNumber",
"$.date": "orderDate",
"prod": "order_pd",
"price": "order_price",
"$.city[0].name": "city"
},
"collectionReference": "$.orders"
}
}
}
Související obsah
Podívejte se na další články o aktivitě kopírování: