Formát Parquet ve službě Azure Data Factory a Azure Synapse Analytics
PLATÍ PRO: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Pokud chcete parsovat soubory Parquet nebo zapisovat data do formátu Parquet, postupujte podle tohoto článku.
Formát Parquet je podporovaný pro následující konektory:
- Amazon S3
- Úložiště kompatibilní s Amazon S3
- Azure Blob
- Azure Data Lake Storage Gen1
- Azure Data Lake Storage Gen2
- Azure Files
- Systém souborů
- FTP
- Cloudové úložiště Googlu
- HDFS
- HTTP
- Oracle Cloud Storage
- SFTP
Seznam podporovanýchfunkcích Připojení ch
Použití místního prostředí Integration Runtime
Důležité
Pokud chcete kopírovat soubory Parquet v místním prostředí Integration Runtime, například mezi místními a cloudovými úložišti dat, musíte na počítač IR nainstalovat 64bitovou verzi prostředí JRE 8 (Java Runtime Environment) nebo OpenJDK. Další podrobnosti najdete v následujícím odstavci.
Pro kopírování spuštěné v místním prostředí IR se serializací/deserializací souborů Parquet vyhledá služba modul runtime Java tím, že nejprve zkontroluje registr (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome) JRE, pokud nebyl nalezen, druhou kontrolou systémové proměnné JAVA_HOME openJDK.
- Použití JRE: 64bitové prostředí IR vyžaduje 64bitové prostředí JRE. Najdete ho tady.
- Použití OpenJDK: Podporuje se od ir verze 3.13. Zabalte soubor jvm.dll se všemi ostatními požadovanými sestaveními OpenJDK do počítače místního prostředí IR a nastavte proměnnou systémového prostředí JAVA_HOME odpovídajícím způsobem a restartujte místní prostředí IR, aby se projevilo okamžitě.
Tip
Pokud kopírujete data do nebo z formátu Parquet pomocí místního prostředí Integration Runtime a dojde k chybě s oznámením " Při vyvolání javy došlo k chybě, zpráva: java.lang.OutOfMemoryError:Halda Java: Místo haldy Javy", můžete do počítače, který je hostitelem místního prostředí IR, přidat proměnnou _JAVA_OPTIONS prostředí, aby se upravila minimální/maximální velikost haldy pro JVM, aby bylo možné takovou kopii umožnit, a pak kanál znovu spustit.
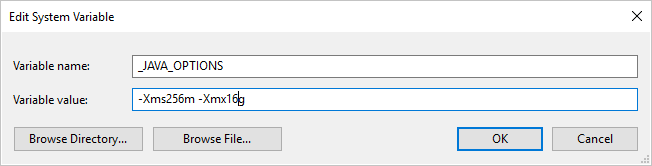
Příklad: nastavte proměnnou _JAVA_OPTIONS s hodnotou -Xms256m -Xmx16g. Xms Příznak určuje počáteční fond přidělení paměti pro virtuální počítač Java Virtual Machine (JVM), zatímco Xmx určuje maximální fond přidělení paměti. To znamená, že prostředí JVM se spustí s Xms množstvím paměti a bude moct používat maximální Xmx velikost paměti. Ve výchozím nastavení služba používá minimální 64 MB a maximální 1G.
Vlastnosti datové sady
Úplný seznam oddílů a vlastností dostupných pro definování datových sad najdete v článku Datové sady . Tato část obsahuje seznam vlastností podporovaných datovou sadou Parquet.
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu datové sady musí být nastavena na Parquet. | Ano |
| location | Nastavení umístění souborů Každý konektor založený na souborech má svůj vlastní typ umístění a podporované vlastnosti v části location. Podrobnosti najdete v článku o konektoru –> část Vlastnosti datové sady. |
Ano |
| compressionCodec | Komprimační kodek, který se má použít při zápisu do souborů Parquet. Při čtení ze souborů Parquet datové továrny automaticky určují kodek komprese na základě metadat souboru. Podporované typy jsou none, gzip, snappy (výchozí) a lzo. Všimněte si, že v současné době aktivita Copy nepodporuje LZO při čtení a zápisu souborů Parquet. |
No |
Poznámka:
Pro soubory Parquet není podporováno prázdné znaky v názvu sloupce.
Níže je příklad datové sady Parquet ve službě Azure Blob Storage:
{
"name": "ParquetDataset",
"properties": {
"type": "Parquet",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"compressionCodec": "snappy"
}
}
}
Vlastnosti aktivity kopírování
Úplný seznam oddílů a vlastností dostupných pro definování aktivit najdete v článku Pipelines . Tato část obsahuje seznam vlastností podporovaných zdrojem a jímkou Parquet.
Parquet jako zdroj
Následující vlastnosti jsou podporovány v části aktivity kopírování *source* .
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu zdroje aktivity kopírování musí být nastavena na ParquetSource. | Ano |
| store Nastavení | Skupina vlastností, jak číst data z úložiště dat. Každý konektor založený na souborech má vlastní podporovaná nastavení čtení v části storeSettings. Podrobnosti najdete v článku o konektoru –> aktivita Copy části vlastností. |
No |
Parquet jako jímka
Následující vlastnosti jsou podporovány v části aktivity kopírování *jímka*.
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu jímky aktivity kopírování musí být nastavena na ParquetSink. | Ano |
| formát Nastavení | Skupina vlastností. Níže najdete tabulku nastavení zápisu parquet. | No |
| store Nastavení | Skupina vlastností pro zápis dat do úložiště dat. Každý konektor založený na souborech má vlastní podporovaná nastavení zápisu v části storeSettings. Podrobnosti najdete v článku o konektoru –> aktivita Copy části vlastností. |
No |
Podporované nastavení zápisu Parquet v části formatSettings:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Typ formátu Nastavení musí být nastaven na ParquetWrite Nastavení. | Ano |
| maxRowsPerFile | Při zápisu dat do složky se můžete rozhodnout zapisovat do více souborů a zadat maximální počet řádků na soubor. | No |
| fileNamePrefix | Platí, pokud maxRowsPerFile je nakonfigurováno.Při zápisu dat do více souborů zadejte předponu názvu souboru, výsledkem je tento vzor: <fileNamePrefix>_00000.<fileExtension>. Pokud není zadána, automaticky se vygeneruje předpona názvu souboru. Tato vlastnost se nevztahuje, pokud zdroj je úložiště dat založené na souborech nebo úložiště dat s povolenou možností oddílu. |
No |
Mapování vlastností toku dat
Při mapování toků dat můžete číst a zapisovat do formátu Parquet v následujících úložištích dat: Azure Blob Storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2 a SFTP a můžete číst parquet formát v AmazonU S3.
Vlastnosti zdroje
Následující tabulka uvádí vlastnosti podporované zdrojem parquet. Tyto vlastnosti můžete upravit na kartě Možnosti zdroje.
| Název | Popis | Povinní účastníci | Povolené hodnoty | Vlastnost skriptu toku dat |
|---|---|---|---|---|
| Formát | Formát musí být parquet |
ano | parquet |
format |
| Cesty se zástupnými kartami | Zpracují se všechny soubory odpovídající cestě se zástupným znakem. Přepíše složku a cestu k souboru nastavenou v datové sadě. | ne | Řetězec[] | Zástupné cardPaths |
| Kořenová cesta oddílu | Pro data souborů rozdělená do oddílů můžete zadat kořenovou cestu oddílu, abyste mohli číst dělené složky jako sloupce. | ne | String | partitionRootPath |
| Seznam souborů | Určuje, jestli váš zdroj ukazuje na textový soubor se seznamem souborů, které se mají zpracovat. | ne | true nebo false |
Filelist |
| Sloupec pro uložení názvu souboru | Vytvoření nového sloupce s názvem zdrojového souboru a cestou | ne | String | rowUrlColumn |
| Po dokončení | Soubory po zpracování odstraňte nebo přesuňte. Cesta k souboru začíná z kořenového adresáře kontejneru. | ne | Odstranit: true nebo false Přesunout: [<from>, <to>] |
purgeFiles moveFiles |
| Filtrovat podle poslední změny | Zvolte filtrování souborů na základě toho, kdy byly naposledy změněny. | ne | Časové razítko | Modifiedafter Modifiedbefore |
| Povolit žádné nalezené soubory | Pokud je pravda, chyba se nevyvolá, pokud se nenašly žádné soubory. | ne | true nebo false |
ignoreNoFilesFound |
Příklad zdroje
Následující obrázek je příkladem konfigurace zdroje parquet v mapování toků dat.
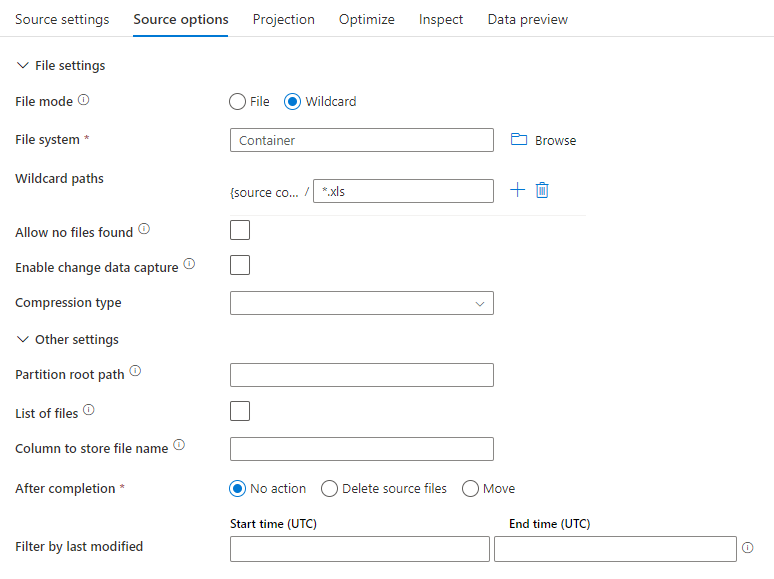
Přidružený skript toku dat je:
source(allowSchemaDrift: true,
validateSchema: false,
rowUrlColumn: 'fileName',
format: 'parquet') ~> ParquetSource
Vlastnosti jímky
Následující tabulka uvádí vlastnosti podporované jímkou parquet. Tyto vlastnosti můžete upravit na kartě Nastavení.
| Název | Popis | Povinní účastníci | Povolené hodnoty | Vlastnost skriptu toku dat |
|---|---|---|---|---|
| Formát | Formát musí být parquet |
ano | parquet |
format |
| Vymazání složky | Pokud je cílová složka před zápisem vymazána. | ne | true nebo false |
truncate |
| Možnost názvu souboru | Formát pojmenování zapsaných dat. Ve výchozím nastavení je ve formátu jeden soubor na oddíl. part-#####-tid-<guid> |
ne | Vzor: Řetězec Na oddíl: String[] Jako data ve sloupci: Řetězec Výstup do jednoho souboru: ['<fileName>'] |
filePattern partitionFileNames rowUrlColumn partitionFileNames |
Příklad jímky
Následující obrázek je příkladem konfigurace jímky parquet v mapování toků dat.
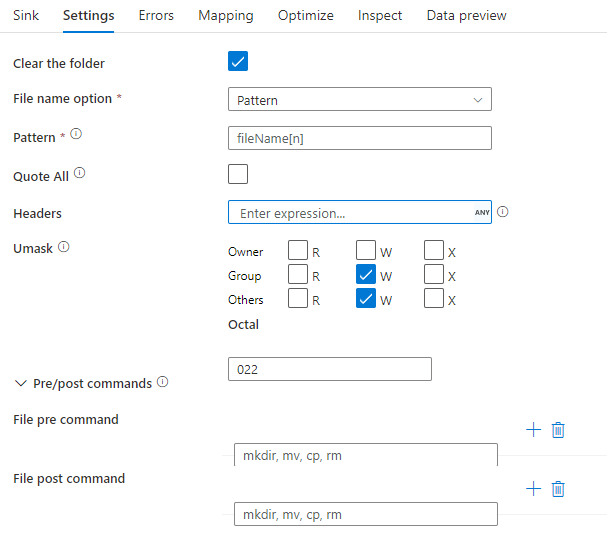
Přidružený skript toku dat je:
ParquetSource sink(
format: 'parquet',
filePattern:'output[n].parquet',
truncate: true,
allowSchemaDrift: true,
validateSchema: false,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> ParquetSink
Podpora datových typů
Složité datové typy Parquet (např. MAP, LIST, STRUCT) se v současné době podporují jenom v Tok dat, ne v aktivitě kopírování. Pokud chcete použít složité typy v tocích dat, neimportujte schéma souboru v datové sadě a ponechejte schéma prázdné v datové sadě. Potom v transformaci zdroje naimportujte projekce.