Zápis zpráv událostí do Azure Data Lake Storage Gen2 pomocí rozhraní Apache Flink® DataStream API
Důležité
Tato funkce je aktuálně dostupná jako ukázková verze. Doplňkové podmínky použití pro Microsoft Azure Preview obsahují další právní podmínky, které se vztahují na funkce Azure, které jsou v beta verzi, ve verzi Preview nebo ještě nejsou vydány v obecné dostupnosti. Informace o této konkrétní verzi Preview najdete v tématu Azure HDInsight o službě AKS ve verzi Preview. Pokud máte dotazy nebo návrhy funkcí, odešlete prosím žádost na AskHDInsight s podrobnostmi a sledujte nás o dalších aktualizacích v komunitě Azure HDInsight.
Apache Flink používá systémy souborů k využívání a trvalému ukládání dat, a to jak pro výsledky aplikací, tak pro odolnost proti chybám a obnovení. V tomto článku se dozvíte, jak zapisovat zprávy událostí do Azure Data Lake Storage Gen2 pomocí rozhraní DataStream API.
Požadavky
- Cluster Apache Flink ve službě HDInsight v AKS
- Cluster Apache Kafka ve službě HDInsight
- Musíte zajistit, aby se nastavení sítě postarala, jak je popsáno v tématu Použití Apache Kafka ve službě HDInsight. Ujistěte se, že hdInsight v clusterech AKS a HDInsight jsou ve stejné virtuální síti.
- Použití MSI pro přístup k ADLS Gen2
- IntelliJ pro vývoj na virtuálním počítači Azure ve službě HDInsight ve službě AKS Virtual Network
Konektor Apache Flink FileSystem
Tento konektor systému souborů poskytuje stejné záruky pro batch i streaming a je navržený tak, aby poskytoval přesně jednou sémantiku pro spouštění streamování. Další informace naleznete v tématu Flink DataStream Filesystem.
Apache Kafka Připojení or
Flink poskytuje konektor Apache Kafka pro čtení dat z témat Kafka a zápis dat do témat Kafka s přesně jednou zárukou. Další informace najdete v tématu Apache Kafka Připojení or.
Sestavení projektu pro Apache Flink
pom.xml v IntelliJ IDEA
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<flink.version>1.17.0</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<kafka.version>3.2.0</kafka.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-files -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<appendAssemblyId>false</appendAssemblyId>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
Program pro jímku ADLS Gen2
abfsGen2.java
Poznámka:
Nahrazení Apache Kafka na clusteru HDInsight bootStrapServers vlastními zprostředkovateli pro Kafka 3.2
package contoso.example;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.configuration.MemorySize;
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy;
import java.time.Duration;
public class KafkaSinkToGen2 {
public static void main(String[] args) throws Exception {
// 1. get stream execution env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Configuration flinkConfig = new Configuration();
flinkConfig.setString("classloader.resolve-order", "parent-first");
env.getConfig().setGlobalJobParameters(flinkConfig);
// 2. read kafka message as stream input, update your broker ip's
String brokers = "<update-broker-ip>:9092,<update-broker-ip>:9092,<update-broker-ip>:9092";
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers(brokers)
.setTopics("click_events")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStream<String> stream = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
stream.print();
// 3. sink to gen2, update container name and storage path
String outputPath = "abfs://<container-name>@<storage-path>.dfs.core.windows.net/flink/data/click_events";
final FileSink<String> sink = FileSink
.forRowFormat(new Path(outputPath), new SimpleStringEncoder<String>("UTF-8"))
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(Duration.ofMinutes(2))
.withInactivityInterval(Duration.ofMinutes(3))
.withMaxPartSize(MemorySize.ofMebiBytes(5))
.build())
.build();
stream.sinkTo(sink);
// 4. run stream
env.execute("Kafka Sink To Gen2");
}
}
Zabalte soubor JAR a odešlete ho do Apache Flinku.
Nahrajte soubor JAR do ABFS.

Předejte informace o souboru JAR úlohy při
AppModevytváření clusteru.
Poznámka:
Nezapomeňte přidat classloader.resolve-order jako parent-first a hadoop.classpath.enable jako
trueVýběrem agregace protokolu úloh odešlete protokoly úloh do účtu úložiště.

Vidíte spuštěnou úlohu.





Ověření streamovaných dat v ADLS Gen2
Vidíme click_events streamování do ADLS Gen2.

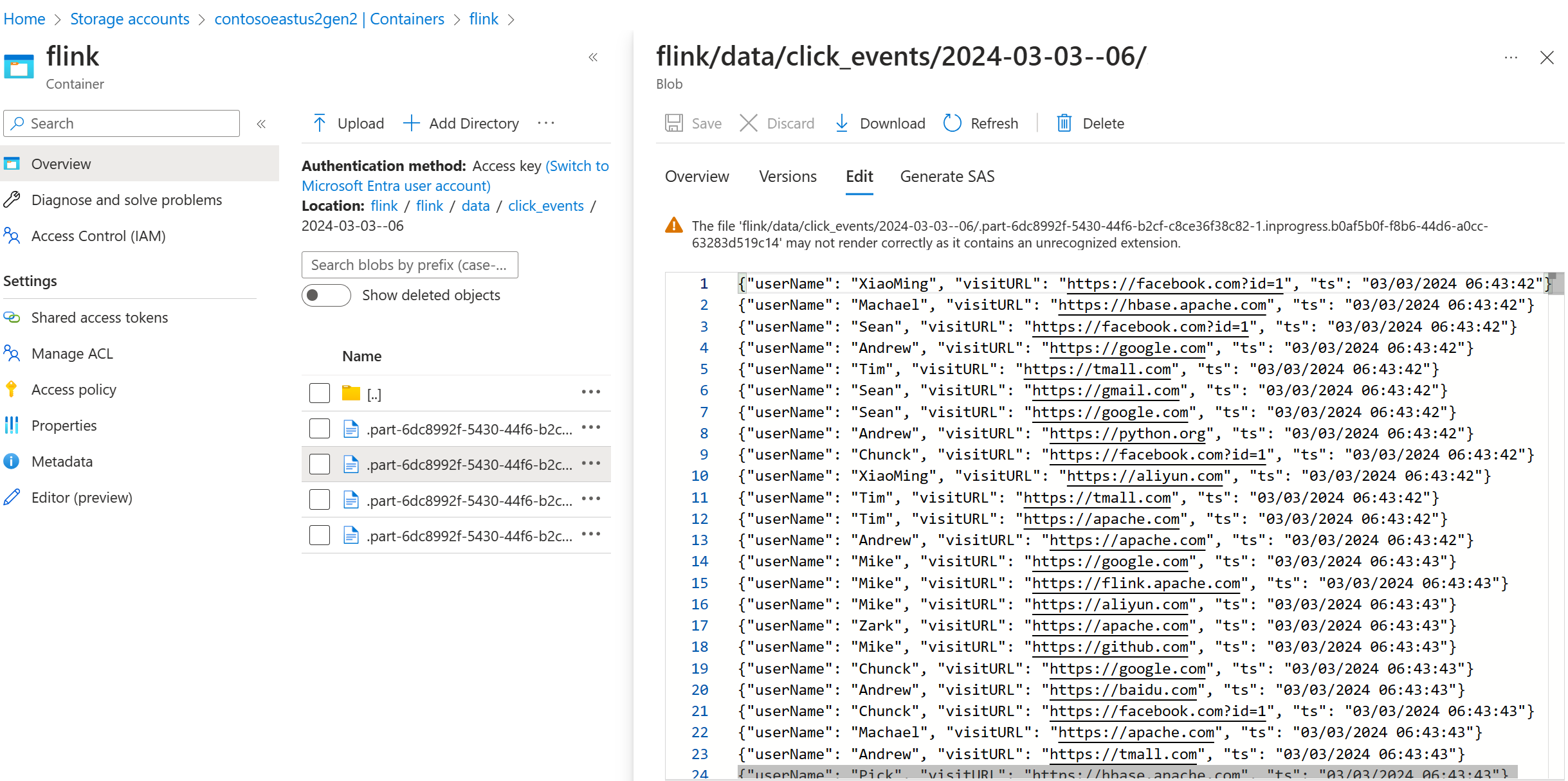
Můžete zadat zásady postupného uvedení probíhajícího souboru v některé z následujících tří podmínek:
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(Duration.ofMinutes(5))
.withInactivityInterval(Duration.ofMinutes(3))
.withMaxPartSize(MemorySize.ofMebiBytes(5))
.build())
Reference
- Apache Kafka Připojení or
- Flink DataStream Filesystem
- Web Apache Flink
- Názvy apache, Apache Kafka, Kafka, Apache Flink, Flink a přidružených opensourcových projektů jsou ochranné známky Apache Software Foundation (ASF).