Co je Apache Spark™ ve službě HDInsight v AKS? (Preview)
Důležité
Tato funkce je aktuálně dostupná jako ukázková verze. Doplňkové podmínky použití pro Microsoft Azure Preview obsahují další právní podmínky, které se vztahují na funkce Azure, které jsou v beta verzi, ve verzi Preview nebo ještě nejsou vydány v obecné dostupnosti. Informace o této konkrétní verzi Preview najdete v tématu Azure HDInsight o službě AKS ve verzi Preview. Pokud máte dotazy nebo návrhy funkcí, odešlete prosím žádost na AskHDInsight s podrobnostmi a sledujte nás o dalších aktualizacích v komunitě Azure HDInsight.
Apache Spark™ je architektura paralelního zpracování, která podporuje zpracování v paměti za účelem zvýšení výkonu analytických aplikací pro velké objemy dat.
Apache Spark™ poskytuje primitiva pro cluster computing v paměti. Úloha Sparku dokáže data načíst a uložit je do mezipaměti a opakovaně se na ně dotazovat. Výpočetní prostředí v paměti je rychlejší než aplikace založené na discích, jako je Hadoop, které sdílí data prostřednictvím distribuovaného systému souborů Hadoop (HDFS). Apache Spark umožňuje integraci s programovacími jazyky Scala a Python, abyste mohli manipulovat s distribuovanými datovými sadami, jako jsou místní kolekce. Není nutné strukturovat všechno jako mapovací a redukční operace.
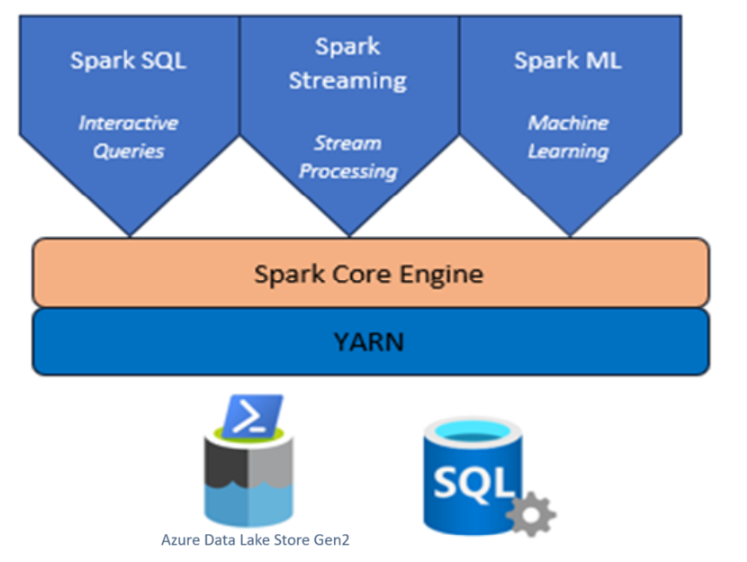
Cluster Apache Spark se službou HDInsight v AKS
Azure HDInsight je spravovaná opensourcová analytická služba určená pro podniky.
Apache Spark™ ve službě Azure HDInsight v AKS je spravovaná služba Spark v Microsoft Azure. Díky Apache Sparku ve službě Azure HDInsight v AKS můžete ukládat a zpracovávat data v rámci Azure. Clustery Spark ve službě HDInsight jsou kompatibilní s Azure Data Lake Storage Gen2 a umožňují použít zpracování Sparku ve stávajících úložištích dat.
Architektura Apache Spark pro HDInsight v AKS umožňuje rychlou analýzu dat a cluster computing pomocí zpracování v paměti. Jupyter Notebook umožňuje pracovat s daty, kombinovat kód s textem markdownu a provádět jednoduché vizualizace.
Apache Spark v AKS ve službě HDInsight se skládá z několika komponent jako podů.
Kontrolery clusteru
Kontrolery clusteru zodpovídají za instalaci a správu příslušných služeb. V clusteru Spark se instalují a spravují různé kontrolery.
Komponenty služby Apache Spark
Služba Zookeeper: Cluster Zookeeper se třemi uzly slouží jako distribuovaný koordinátor nebo úložiště s vysokou dostupností pro jiné služby.
Služba Yarn: Cluster Hadoop Yarn, úlohy Sparku by se v clusteru naplánovaly jako aplikace Yarn.
Klientská rozhraní: Clustery Apache Spark ve službě HDInsight v AKS poskytují různá klientská rozhraní. Livy Server, Jupyter Notebook, Spark History Server, poskytuje služby Sparku hdInsight uživatelům AKS.
Reference
- Názvy open source projektů Apache, Apache Spark, Apache Spark a přidružené jsou ochranné známkyslužby Apache Software Foundation (ASF).