Příklad streamování Apache Sparku (DStream) s Apache Kafka ve službě HDInsight
Zjistěte, jak pomocí Apache Sparku streamovat data do nebo z Apache Kafka ve službě HDInsight pomocí D Toky. Tento příklad používá poznámkový blok Jupyter, který běží v clusteru Spark.
Poznámka:
Pomocí kroků v tomto dokumentu se vytvoří skupina prostředků Azure obsahující cluster Spark ve službě HDInsight i cluster Kafka ve službě HDInsight. Oba tyto clustery se nacházejí ve virtuální síti Azure, což umožňuje přímou komunikaci clusteru Spark s clusterem Kafka.
Jakmile budete hotovi s kroky v tomto dokumentu, nezapomeňte clustery odstranit, abyste se vyhnuli nadbytečným poplatkům.
Důležité
Tento příklad používá D Toky, což je starší technologie streamování Sparku. Příklad, který používá novější funkce streamování Sparku, najdete v dokumentu Strukturované streamování Sparku s apache Kafka .
Vytvoření clusterů
Apache Kafka ve službě HDInsight neposkytuje přístup ke zprostředkovatelům Kafka přes veřejný internet. Cokoli, co komunikuje se systémem Kafka, musí být ve stejné virtuální síti Azure jako uzly v clusteru Kafka. V tomto příkladu se clustery Kafka i Spark nacházejí ve virtuální síti Azure. Následující diagram znázorňuje tok komunikace mezi clustery:
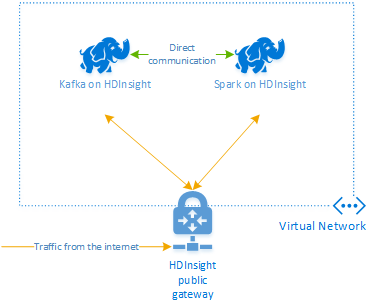
Poznámka:
I když samotná platforma Kafka je omezená na komunikaci ve virtuální síti, k jiným službám v clusteru, jako je SSH a Ambari, je možné přistupovat přes internet. Další informace o veřejných portech dostupných ve službě HDInsight najdete v tématu Porty a identifikátory URI používané službou HDInsight.
I když můžete clustery Azure Virtual Network, Kafka a Spark vytvořit ručně, je jednodušší použít šablonu Azure Resource Manageru. Pomocí následujících kroků nasaďte do svého předplatného Azure virtuální síť Azure, Kafka a Spark.
Pomocí následujícího tlačítka se přihlaste do Azure a otevřete šablonu na webu Azure Portal.

Upozorňující
Aby se zajistila dostupnost Kafka ve službě HDInsight, musí váš cluster obsahovat alespoň čtyři pracovní uzly. Tato šablona vytvoří cluster Kafka, který obsahuje čtyři pracovní uzly.
Tato šablona vytvoří cluster HDInsight 4.0 pro Kafka i Spark.
K naplnění položek v části Vlastní nasazení použijte následující informace:
Vlastnost Hodnota Skupina prostředků Vytvořte skupinu nebo vyberte existující. Umístění Vyberte geograficky blízko vás. Název základního clusteru Tato hodnota se používá jako základní název clusterů Spark a Kafka. Zadáním hdistreamingu například vytvoříte cluster Spark s názvem spark-hdistreaming a cluster Kafka s názvem kafka-hdistreaming. Uživatelské jméno přihlášení clusteru Uživatelské jméno správce pro clustery Spark a Kafka. Heslo přihlášení clusteru Uživatelské heslo správce pro clustery Spark a Kafka. Uživatelské jméno SSH Uživatel SSH, který se má vytvořit pro clustery Spark a Kafka. Heslo SSH Heslo pro uživatele SSH pro clustery Spark a Kafka. 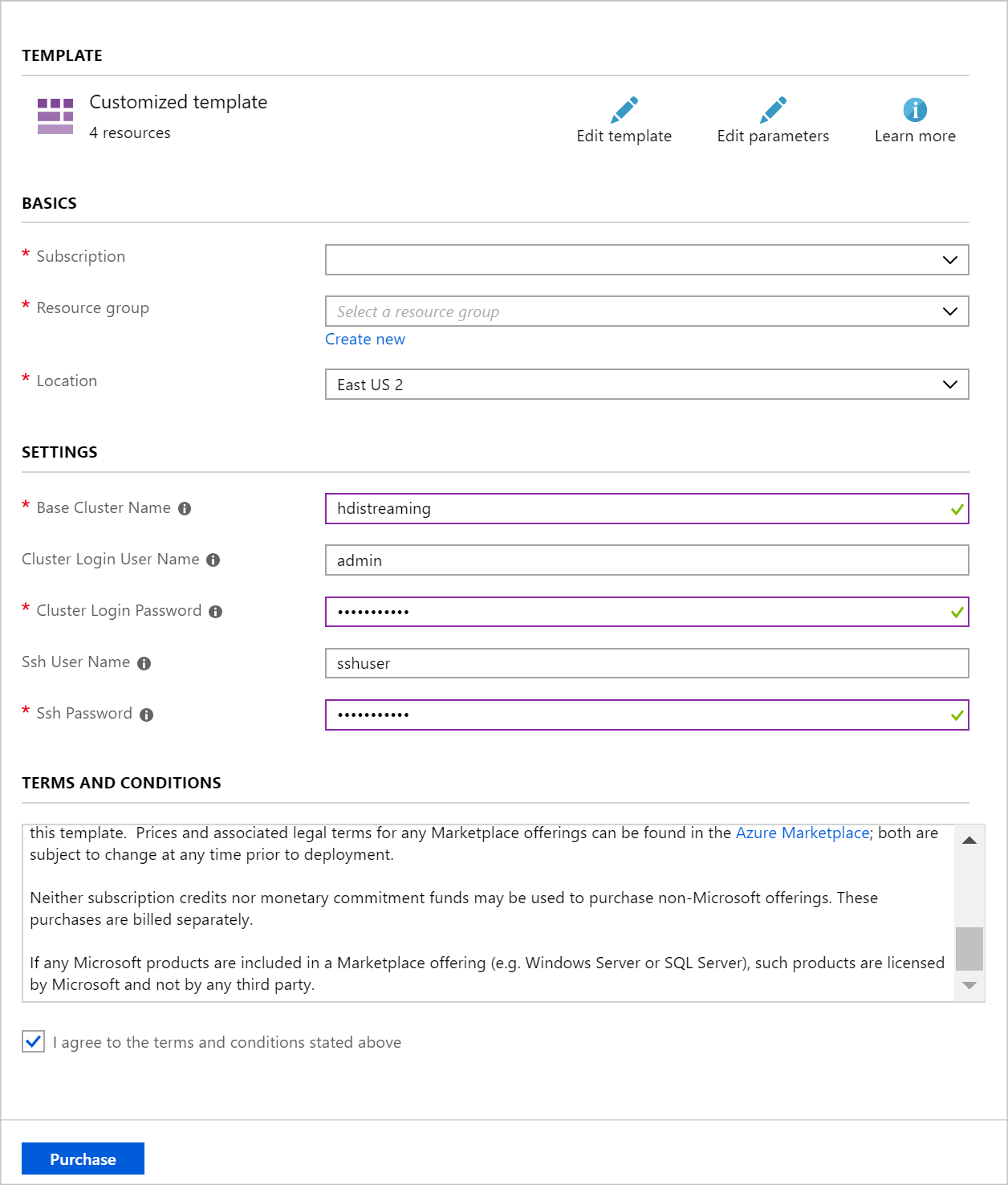
Přečtěte si Podmínky a ujednání a pak vyberte Souhlasím s podmínkami a ujednáními uvedenými nahoře.
Nakonec vyberte Koupit. Vytvoření clusterů trvá přibližně 20 minut.
Po vytvoření prostředků se zobrazí souhrnná stránka.
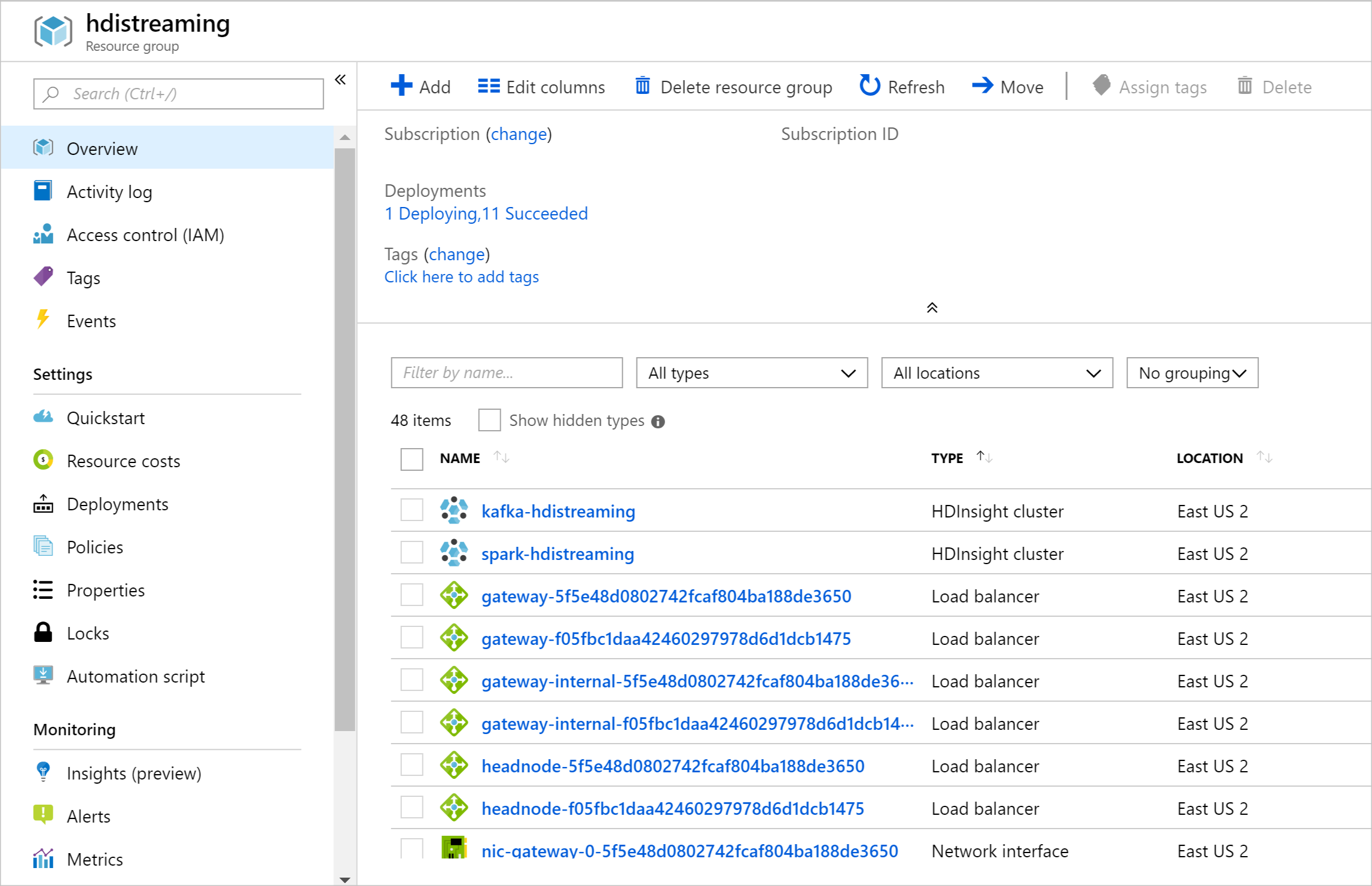
Důležité
Všimněte si, že názvy clusterů HDInsight jsou spark-BASENAME a kafka-BASENAME, kde BASENAME je název, který jste zadali šabloně. Tyto názvy použijete v pozdějších krocích při připojování ke clusterům.
Použití poznámkových bloků
Kód příkladu popisovaného v tomto dokumentu je dostupný na adrese https://github.com/Azure-Samples/hdinsight-spark-scala-kafka.
Odstranění clusteru
Upozorňující
Fakturace clusterů HDInsight se účtuje za minutu bez ohledu na to, jestli je používáte, nebo ne. Až cluster dokončíte, nezapomeňte ho odstranit. Podívejte se, jak odstranit cluster HDInsight.
Vzhledem k tomu, že kroky v tomto dokumentu vytvoří oba clustery ve stejné skupině prostředků Azure, můžete skupinu prostředků odstranit na webu Azure Portal. Odstraněním skupiny se odeberou všechny prostředky vytvořené podle tohoto dokumentu, virtuální sítě Azure a účtu úložiště používaného clustery.
Další kroky
V tomto příkladu jste zjistili, jak pomocí Sparku číst a zapisovat do Kafka. Pomocí následujících odkazů můžete zjistit další způsoby práce se systémem Kafka: