Kurz: Načítání dat a spouštění dotazů v clusteru Apache Spark ve službě Azure HDInsight
V tomto kurzu se dozvíte, jak vytvořit datový rámec ze souboru CSV a jak spouštět interaktivní dotazy Spark SQL na cluster Apache Spark ve službě Azure HDInsight. Ve Sparku je datový rámec distribuovaná kolekce dat uspořádaných do pojmenovaných sloupců. Datový rámec je koncepčním ekvivalentem tabulky v relační databázi nebo datového rámce v R nebo Pythonu.
V tomto kurzu se naučíte:
- Vytvoření datového rámce ze souboru CSV
- Spouštění dotazů nad datovým rámcem
Požadavky
Cluster Apache Spark ve službě HDInsight. Viz Vytvoření clusteru Apache Spark.
Vytvoříte poznámkový blok Jupyter Notebooks.
Jupyter Notebook je interaktivní prostředí poznámkového bloku, které podporuje různé programovací jazyky. Poznámkový blok umožňuje pracovat s daty, kombinovat kód s textem markdownu a provádět jednoduché vizualizace.
Upravte adresu URL
https://SPARKCLUSTER.azurehdinsight.net/jupyternahrazenímSPARKCLUSTERnázvu clusteru Spark. Potom zadejte upravenou adresu URL ve webovém prohlížeči. Po zobrazení výzvy zadejte přihlašovací údaje clusteru.Na webové stránce Jupyter v případě clusterů Spark 2.4 vyberte Nový>PySpark a vytvořte poznámkový blok. V případě verze Spark 3.1 vyberte místo toho nový>PySpark3 a vytvořte poznámkový blok, protože jádro PySpark už není ve Sparku 3.1 k dispozici.
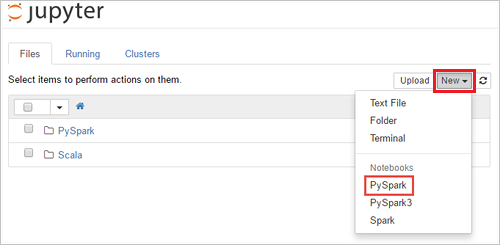
Vytvoří se nový poznámkový blok a otevře se s názvem Bez názvu(
Untitled.ipynb).Poznámka:
Když k vytvoření poznámkového bloku použijete jádro PySpark nebo PySpark3,
sparkrelace se automaticky vytvoří při spuštění první buňky kódu. Není potřeba relaci vytvářet explicitně.
Vytvoření datového rámce ze souboru CSV
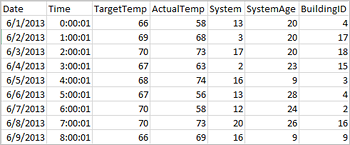
Aplikace mohou vytvářet datové rámce přímo ze souborů nebo složek ve vzdáleném úložišti, jako je Azure Storage nebo Azure Data Lake Storage; z tabulky Hive; nebo z jiných zdrojů dat podporovaných Sparkem, jako jsou Azure Cosmos DB, Azure SQL DB, DW atd. Následující snímek obrazovky ukazuje snímek souboru HVAC.csv použitého v tomto kurzu. Tento soubor CSV je součástí všech clusterů HDInsight Spark. Data zaznamenávají změny teploty několika budov.
Do prázdné buňky poznámkového bloku Jupyter Notebook vložte následující kód a stisknutím kombinace kláves SHIFT+ENTER kód spusťte. Kód naimportuje typy potřebné pro tento scénář:
from pyspark.sql import * from pyspark.sql.types import *Po spuštění interaktivního dotazu v Jupyter se název okna nebo karty webového prohlížeče zobrazí jako (Zaneprázdněn) společně s názvem poznámkového bloku. Zobrazí se také plný kroužek vedle textu PySpark v pravém horním rohu. Po dokončení úlohy se změní na prázdný kruh.
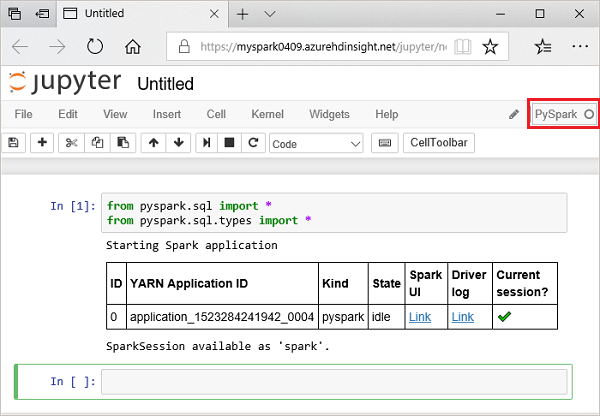
Poznamenejte si vrácené ID relace. Na obrázku výše je ID relace 0. V případě potřeby můžete načíst podrobnosti o relaci tak, že přejdete na místo, kde
https://CLUSTERNAME.azurehdinsight.net/livy/sessions/ID/statementsCLUSTERNAME je název clusteru Spark a ID je číslo ID relace.Spuštěním následujícího kódu vytvořte datový rámec a dočasnou tabulku (hvac).
# Create a dataframe and table from sample data csvFile = spark.read.csv('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv', header=True, inferSchema=True) csvFile.write.saveAsTable("hvac")
Spouštění dotazů nad datovým rámcem
Po vytvoření tabulky můžete nad daty spustit interaktivní dotaz.
V prázdné buňce poznámkového bloku spusťte následující kód:
%%sql SELECT buildingID, (targettemp - actualtemp) AS temp_diff, date FROM hvac WHERE date = \"6/1/13\"Zobrazí se následující tabulkový výstup.
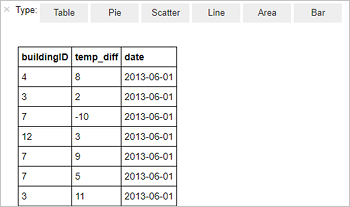
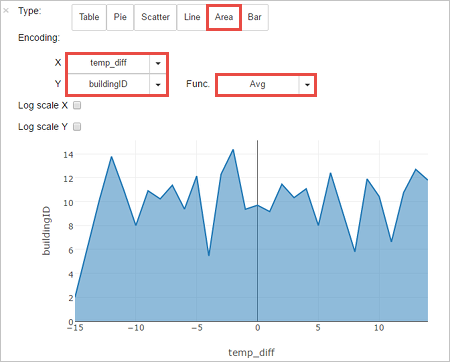
Výsledky můžete také zobrazit v dalších vizualizacích. Pokud chcete výstup zobrazit v podobě plošného grafu, vyberte Oblast a pak nastavte další hodnoty následujícím způsobem.
V řádku nabídek poznámkového bloku přejděte na Příkaz Uložit>soubor a Kontrolní bod.
Pokud právě začínáte s dalším kurzem, nechte poznámkový blok otevřený. Pokud ne, vypněte poznámkový blok a uvolněte prostředky clusteru: na řádku nabídek poznámkového bloku přejděte na Tlačítko Zavřít a Zastavit soubor>.
Vyčištění prostředků
S HDInsight se vaše data a poznámkové bloky Jupyter ukládají ve službě Azure Storage nebo Azure Data Lake Storage, takže můžete cluster bezpečně odstranit, když se nepoužívá. Za cluster HDInsight se vám také účtují poplatky, i když se nepoužívá. Vzhledem k tomu, že poplatky za cluster jsou mnohokrát vyšší než poplatky za úložiště, dává smysl odstranit clustery, když se nepoužívají. Pokud se chystáte hned začít pracovat na dalším kurzu, měli byste cluster zachovat.
Otevřete cluster na webu Azure Portal a vyberte Odstranit.
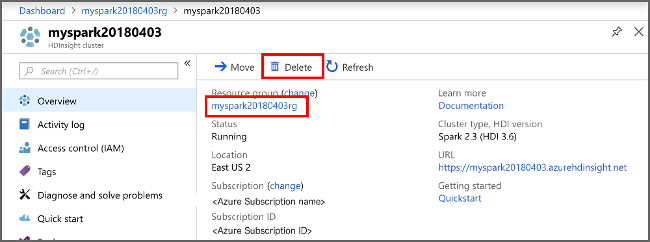
Můžete také výběrem názvu skupiny prostředků otevřít stránku skupiny prostředků a pak vybrat Odstranit skupinu prostředků. Odstraněním skupiny prostředků odstraníte cluster HDInsight Spark i výchozí účet úložiště.
Další kroky
V tomto kurzu jste zjistili, jak vytvořit datový rámec ze souboru CSV a jak spouštět interaktivní dotazy Spark SQL na cluster Apache Spark ve službě Azure HDInsight. V dalším článku se dozvíte, jak se data zaregistrovaná v Apache Sparku dají načíst do analytického nástroje BI, jako je Power BI.