Přesun dat do služby Azure Blob Storage
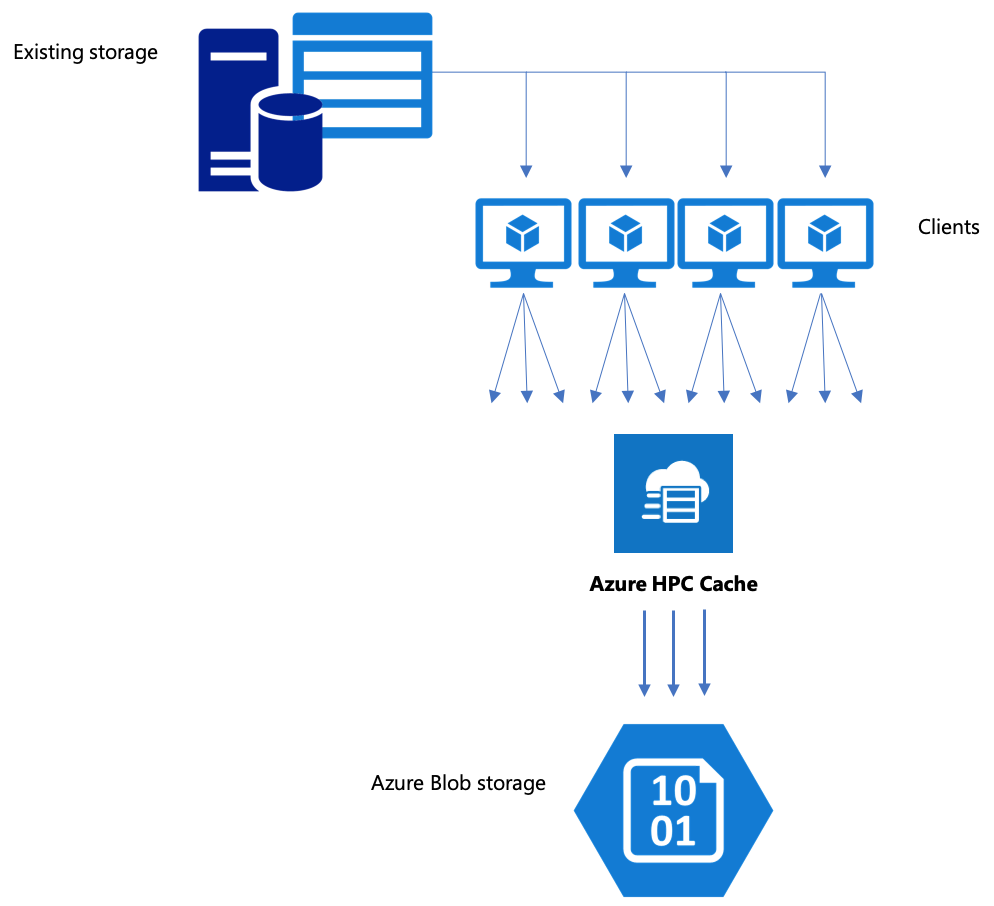
Pokud váš pracovní postup zahrnuje přesun dat do úložiště objektů blob v Azure, ujistěte se, že používáte efektivní strategii. Mezipaměť byste měli vytvořit, přidat kontejner objektů blob jako cíl úložiště a pak zkopírovat data pomocí služby Azure HPC Cache.
Tento článek vysvětluje nejlepší způsoby přesunu dat do úložiště objektů blob pro použití se službou Azure HPC Cache.
Tip
Tento článek se nevztahuje na úložiště objektů blob připojené systémem souborů NFS (cíle úložiště ADLS-NFS). Libovolnou metodu založenou na systému souborů NFS můžete použít k naplnění kontejneru objektů blob ADLS-NFS před nebo po jeho přidání do služby HPC Cache. Přečtěte si předem načtená data pomocí protokolu NFS, abyste se dozvěděli více.
Mějte na paměti tato fakta:
Azure HPC Cache používá specializovaný formát úložiště k uspořádání dat v úložišti objektů blob. To je důvod, proč cíl úložiště objektů blob musí být nový, prázdný kontejner nebo kontejner objektů blob, který byl dříve použit pro data služby Azure HPC Cache.
Kopírování dat prostřednictvím služby Azure HPC Cache do cíle back-endového úložiště je efektivnější, když používáte více klientů a paralelních operací. Jednoduchý příkaz pro kopírování z jednoho klienta bude pomalu přesouvat data.
Strategie popsané v tomto článku slouží k naplnění prázdného kontejneru objektů blob nebo přidání souborů do dříve použitého cíle úložiště.
Kopírování dat prostřednictvím služby Azure HPC Cache
Služba Azure HPC Cache je navržená tak, aby sloužila více klientům současně, takže ke kopírování dat prostřednictvím mezipaměti byste měli používat paralelní zápisy z více klientů.
Příkazy cp , copy které obvykle používáte k přenosu dat z jednoho systému úložiště do jiného, jsou procesy s jedním vláknem, které kopírují pouze jeden soubor najednou. To znamená, že souborový server ingestuje pouze jeden soubor najednou – což je plýtvání prostředky mezipaměti.
Tato část vysvětluje strategie pro vytvoření systému kopírování souborů s více vlákny s více vlákny za účelem přesunu dat do úložiště objektů blob pomocí služby Azure HPC Cache. Vysvětluje koncepty přenosu souborů a rozhodovací body, které je možné použít k efektivnímu kopírování dat pomocí více klientů a jednoduchých příkazů kopírování.
Vysvětluje také některé nástroje, které můžou pomoct. Nástroj msrsync lze použít k částečné automatizaci procesu rozdělení datové sady do kontejnerů a použití příkazů rsync. Skript parallelcp je další nástroj, který čte zdrojový adresář a vydává příkazy kopírování automaticky.
Strategické plánování
Při vytváření strategie paralelního kopírování dat byste měli rozumět kompromisům ve velikosti souboru, počtu souborů a hloubkách adresáře.
- Pokud jsou soubory malé, metrika zájmu je soubory za sekundu.
- Pokud jsou soubory velké (10MiBi nebo vyšší), metrika zájmu je bajty za sekundu.
Každý proces kopírování má rychlost propustnosti a rychlost přenosu souborů, kterou je možné měřit načasováním příkazu kopírování a faktorem velikosti souboru a počtu souborů. Vysvětlení míry je mimo rozsah tohoto dokumentu, ale je nezbytné pochopit, jestli budete řešit malé nebo velké soubory.
Mezi strategie paralelního ingestování dat pomocí služby Azure HPC Cache patří:
Ruční kopírování – V klientovi můžete ručně vytvořit vícevláknovou kopii spuštěním více příkazů kopírování najednou na pozadí s předdefinovanými sadami souborů nebo cest. Přečtěte si informace o ingestování dat azure HPC Cache – metoda ručního kopírování.
Částečně automatizované kopírování pomocí
msrsync-msrsyncobálky, která spouští více paralelníchrsyncprocesů. Podrobnosti najdete v tématu ingestování dat služby Azure HPC Cache – metoda msrsync.Skriptované kopírování pomocí
parallelcp– Naučte se vytvářet a spouštět skript paralelního kopírování v ingestování dat služby Azure HPC Cache – metoda skriptu paralelního kopírování.
Další kroky
Po nastavení úložiště se dozvíte, jak můžou klienti připojit mezipaměť.