Standardní diagnostika nástroje pro vyrovnávání zatížení s metrikami, upozorněními a stavem prostředků
Azure Load Balancer zveřejňuje následující diagnostické funkce:
Multidimenzionální metriky a upozornění: Poskytuje vícerozměrné diagnostické funkce prostřednictvím služby Azure Monitor pro standardní konfigurace nástroje pro vyrovnávání zatížení. Můžete monitorovat, spravovat a řešit potíže se standardními prostředky nástroje pro vyrovnávání zatížení.
Stav prostředku: Stav služby Resource Health vašeho nástroje pro vyrovnávání zatížení je k dispozici na stránce Resource Health v části Monitorování. Tato automatická kontrola vás informuje o aktuální dostupnosti vašeho prostředku nástroje pro vyrovnávání zatížení.
Tento článek obsahuje stručný přehled těchto funkcí a nabízí způsoby jejich použití pro standardní nástroj pro vyrovnávání zatížení.
Multidimenzionální metriky
Azure Load Balancer poskytuje multidimenzionální metriky prostřednictvím metrik Azure na webu Azure Portal a pomáhá získat diagnostické přehledy o prostředcích nástroje pro vyrovnávání zatížení v reálném čase.
Různé konfigurace nástroje pro vyrovnávání zatížení poskytují následující metriky:
| Metrika | Typ prostředku | Popis | Doporučená agregace |
|---|---|---|---|
| Dostupnost cesty k datům | Veřejný a interní nástroj pro vyrovnávání zatížení | Standardní nástroj pro vyrovnávání zatížení nepřetržitě používá datovou cestu z oblasti do front-endu nástroje pro vyrovnávání zatížení do sítě, která podporuje váš virtuální počítač. Pokud instance, které jsou v pořádku, se měření řídí stejnou cestou jako provoz s vyrovnáváním zatížení vaší aplikace. Použitá cesta k datům se ověří. Měření není pro vaši aplikaci neviditelné a neruší jiné operace. | Průměr |
| Stav sondy stavu | Veřejný a interní nástroj pro vyrovnávání zatížení | Standardní nástroj pro vyrovnávání zatížení využívá distribuovanou službu sondy stavu, která monitoruje stav koncového bodu aplikace podle nastavení konfigurace. Tato metrika poskytuje agregované zobrazení nebo filtrované zobrazení jednotlivých koncových bodů instancí ve fondu nástroje pro vyrovnávání zatížení. Uvidíte, jak nástroj pro vyrovnávání zatížení zobrazuje stav vaší aplikace, jak ukazuje konfigurace sondy stavu. | Průměr |
| Počet synů (synchronizace) | Veřejný a interní nástroj pro vyrovnávání zatížení | Standardní nástroj pro vyrovnávání zatížení neukončuje připojení TCP (Transmission Control Protocol) ani nekomunikuje s toky paketů UDP (TCP) tcp nebo user Data-gram. Toky a jejich metody handshake probíhají vždy mezi zdrojem a instancí virtuálního počítače. Při řešení potíží se scénáři souvisejícími s protokolem TCP můžete využít čítače paketů SYN, pomocí kterých můžete zjistit množství pokusů o přihlášení přes protokol TCP. Tato metrika hlásí počet přijatých paketů TCP SYN. | Sum |
| Počet připojení překladu zdrojových síťových adres (SNAT) | Veřejný nástroj pro vyrovnávání zatížení | Standardní nástroj pro vyrovnávání zatížení hlásí počet odchozích toků, které jsou maskované na front-end veřejné IP adresy. Porty SNAT jsou nevyčerpatelným prostředkem. Tato metrika může poskytnout další informace o tom, do jaké míry se vaše aplikace spoléhá na SNAT u odchozích toků. Čítače pro úspěšné a neúspěšné odchozí toky SNAT se hlásí. Čítače je možné použít k řešení potíží a pochopení stavu odchozích toků. | Sum |
| Přidělené porty SNAT | Veřejný nástroj pro vyrovnávání zatížení | Standardní nástroj pro vyrovnávání zatížení hlásí počet portů SNAT přidělených pro každou back-endovou instanci. | Průměrná. |
| Použité porty SNAT | Veřejný nástroj pro vyrovnávání zatížení | Standardní nástroj pro vyrovnávání zatížení hlásí počet portů SNAT, které se využívají pro každou back-endovou instanci. | Průměr |
| Počet bajtů | Veřejný a interní nástroj pro vyrovnávání zatížení | Standardní nástroj pro vyrovnávání zatížení hlásí data zpracovávaná na front-end. Můžete si všimnout, že bajty nejsou rovnoměrně distribuovány napříč back-endovými instancemi. Očekává se to, protože algoritmus Azure Load Balanceru je založený na tocích. | Sum |
| Počet paketů | Veřejný a interní nástroj pro vyrovnávání zatížení | Standardní nástroj pro vyrovnávání zatížení hlásí pakety zpracovávané na front-end. | Sum |
Poznámka:
Metriky související s šířkou pásma, jako je paket SYN, počet bajtů a počet paketů, nezachytí žádný provoz do interního nástroje pro vyrovnávání zatížení prostřednictvím trasy definované uživatelem (např. ze síťového virtuálního zařízení nebo brány firewall).
Maximální a minimální agregace nejsou k dispozici pro metriky počtu synů, počtu paketů, počtu připojení SNAT a počtu bajtů. Agregace počtu se nedoporučuje pro dostupnost cesty k datům a stav sondy stavu. Místo toho použijte průměr pro nejlépe reprezentovaná data o stavu.
Zobrazení metrik nástroje pro vyrovnávání zatížení na webu Azure Portal
Azure Portal zveřejňuje metriky nástroje pro vyrovnávání zatížení prostřednictvím stránky Metriky. Tato stránka je k dispozici na stránce prostředků nástroje pro vyrovnávání zatížení pro konkrétní prostředek i na stránce služby Azure Monitor.
Poznámka:
Azure Load Balancer neodesílá sondy stavu do uvolněných virtuálních počítačů. Když dojde k uvolnění virtuálních počítačů, nástroj pro vyrovnávání zatížení zastaví metriky generování sestav pro danou instanci. Metriky, které nejsou k dispozici, se zobrazí jako přerušovaná čára na portálu nebo zobrazí chybovou zprávu, že metriky nelze načíst.
Zobrazení metrik pro prostředky load balanceru úrovně Standard:
Přejděte na stránku metrik a proveďte jednu z následujících úloh:
Na stránce prostředku nástroje pro vyrovnávání zatížení vyberte v rozevíracím seznamu typ metriky.
Na stránce Azure Monitoru vyberte prostředek nástroje pro vyrovnávání zatížení.
Nastavte odpovídající typ agregace metriky.
Volitelně můžete nakonfigurovat požadované filtrování a seskupení.
Volitelně můžete nakonfigurovat časový rozsah a agregaci. Ve výchozím nastavení se čas zobrazí ve standardu UTC.
Poznámka:
Časová agregace je důležitá při interpretaci určitých metrik, protože se data vzorkují jednou za minutu. Pokud je časová agregace nastavená na pět minut a pro metriky, jako je přidělení SNAT, se v grafu zobrazí pětkrát celkový počet přidělených portů SNAT.
Doporučení: Při analýze typu agregace metrik Sum and Count doporučujeme použít hodnotu časové agregace, která je větší než jedna minuta.
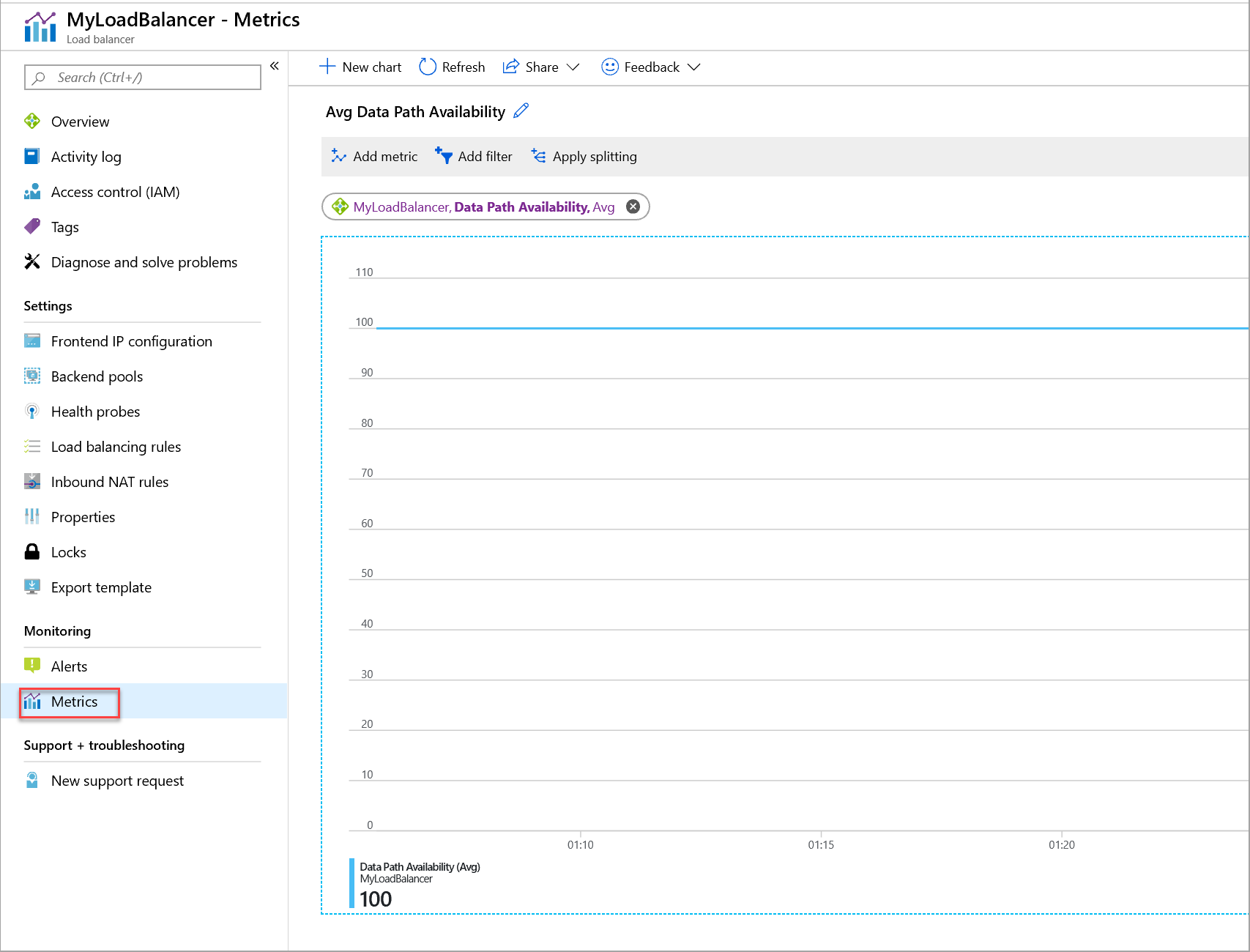
Obrázek: Metrika dostupnosti cesty k datům pro standardní nástroj pro vyrovnávání zatížení
Programové načítání multidimenzionálních metrik prostřednictvím rozhraní API
Pokyny k rozhraní API pro načítání multidimenzionálních definic a hodnot metrik najdete v návodu k rozhraní REST API služby Azure Monitoring. Tyto metriky se dají zapsat do účtu úložiště přidáním nastavení diagnostiky pro kategorii Všechny metriky.
Běžné scénáře diagnostiky a doporučená zobrazení
Je cesta k datům pro front-end nástroje pro vyrovnávání zatížení k dispozici?
Rozbalte
Metrika dostupnosti cesty k datům popisuje stav v rámci oblasti cesty k datům k hostiteli výpočetních prostředků, ve kterém se nacházejí vaše virtuální počítače. Metrika je odrazem stavu infrastruktury Azure. Metriku můžete použít k:
Monitorujte externí dostupnost vaší služby.
Prozkoumejte platformu, ve které je vaše služba nasazená, a zjistěte, jestli je v pořádku. Zjistěte, jestli je hostovaný operační systém nebo instance aplikace v pořádku.
Izolujte, jestli událost souvisí s vaší službou nebo podkladovou rovinou dat. Nezaměňujte tuto metriku se stavem sondy stavu (dostupnost back-endové instance).
Získání dostupnosti cesty k datům pro prostředky load balanceru úrovně Standard:
Ujistěte se, že je vybraný správný prostředek nástroje pro vyrovnávání zatížení.
V rozevíracím seznamu Metriky vyberte Dostupnost cesty k datům.
V rozevíracím seznamu Agregace vyberte Průměr.
Kromě toho přidejte filtr na front-endovou IP adresu nebo front-endový port jako dimenzi s požadovanou IP adresou front-endu nebo front-endovým portem. Pak je seskupte podle vybrané dimenze.
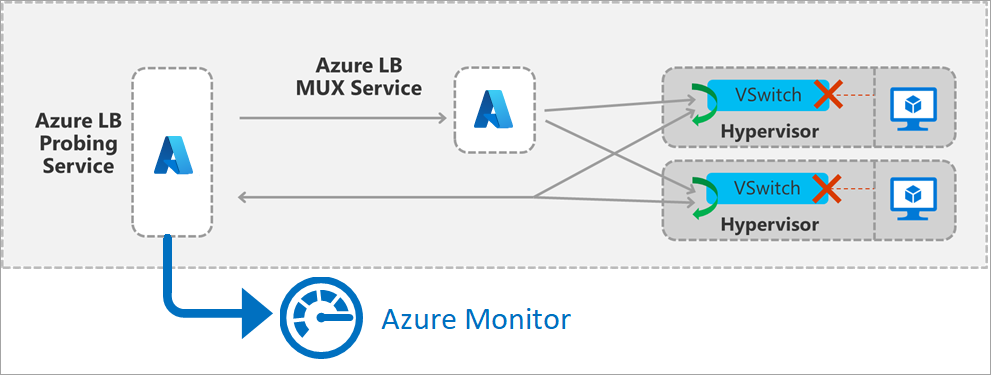
Obrázek: Podrobnosti front-endového sondování nástroje pro vyrovnávání zatížení
Metrika se generuje aktivním měřením v pásmu. Sondovací služba v rámci oblasti pochází z provozu měření. Služba se aktivuje, jakmile vytvoříte nasazení s veřejným front-endem a bude pokračovat, dokud neodeberete front-end.
Paket odpovídající front-endu a pravidlu vašeho nasazení se pravidelně generuje. Prochází oblastí ze zdroje k hostiteli, kde se nachází virtuální počítač v back-endovém fondu. Infrastruktura nástroje pro vyrovnávání zatížení provádí stejné operace vyrovnávání zatížení a překladu jako u všech ostatních přenosů. Tato sonda je v koncovém bodu s vyrovnáváním zatížení v pásmu. Jakmile sonda dorazí na výpočetního hostitele, kde se nachází v pořádku virtuální počítač v back-endovém fondu, výpočetní hostitel vygeneruje odpověď na službu sondy. Váš virtuální počítač tento provoz nevidí.
Dostupnost cesty k datům selže z následujících důvodů:
Vaše nasazení nemá žádné virtuální počítače, které jsou v back-endovém fondu v pořádku.
Došlo k výpadku infrastruktury.
Pro účely diagnostiky můžete metriku použít pro dostupnost cesty k datům společně se stavem sondy stavu.
Pro většinu scénářů použijte jako agregaci Průměr .
Reagují back-endové instance nástroje pro vyrovnávání zatížení na sondy?
Rozbalte
Metrika stavu sondy stavu popisuje stav nasazení aplikace podle konfigurace při konfiguraci sondy stavu vašeho nástroje pro vyrovnávání zatížení. Nástroj pro vyrovnávání zatížení používá stav sondy stavu k určení, kam se mají odesílat nové toky. Sondy stavu pocházejí z adresy infrastruktury Azure a jsou viditelné v hostovaném operačním systému virtuálního počítače.
Pokud chcete získat stav sondy stavu pro prostředky load balanceru úrovně Standard:
Vyberte metriku Stav sondy stavu s typem Průměrná agregace.
Použijte filtr na požadovanou IP adresu front-endu nebo port (nebo obojí).
Sondy stavu selžou z následujících důvodů:
Sondu stavu nakonfigurujete na port, který naslouchá nebo nereaguje nebo nepoužívá nesprávný protokol. Pokud vaše služba používá přímé vrácení serveru nebo plovoucí pravidla IP adres, ověřte, že služba naslouchá na IP adrese konfigurace IP síťové karty a zpětné smyčce nakonfigurované s front-endovou IP adresou.
Vaše skupina zabezpečení sítě, brána firewall hostovaného operačního systému virtuálního počítače nebo filtry aplikační vrstvy nepovolují provoz sondy stavu.
Pro většinu scénářů použijte jako agregaci Průměr .
Návody zkontrolujte statistiky odchozích připojení?
Rozbalte
Metrika připojení SNAT popisuje objem úspěšných a neúspěšných připojení pro odchozí toky.
Neúspěšný svazek připojení větší než nula značí vyčerpání portů SNAT. Pokud chcete zjistit, co může být příčinou těchto selhání, musíte prozkoumat podrobněji. Vyčerpání portů SNAT se projevuje jako selhání vytvoření odchozího toku. Projděte si článek o odchozích připojeních a seznamte se se scénáři a mechanismy v práci a zjistěte, jak zmírnit a navrhnout, abyste se vyhnuli vyčerpání portů SNAT.
Získání statistik připojení SNAT:
Vyberte Připojení nabídky typu metriky a součet jako agregace.
Seskupit podle stavu Připojení pro úspěšné a neúspěšné počty připojení SNAT, které mají být reprezentovány různými řádky.
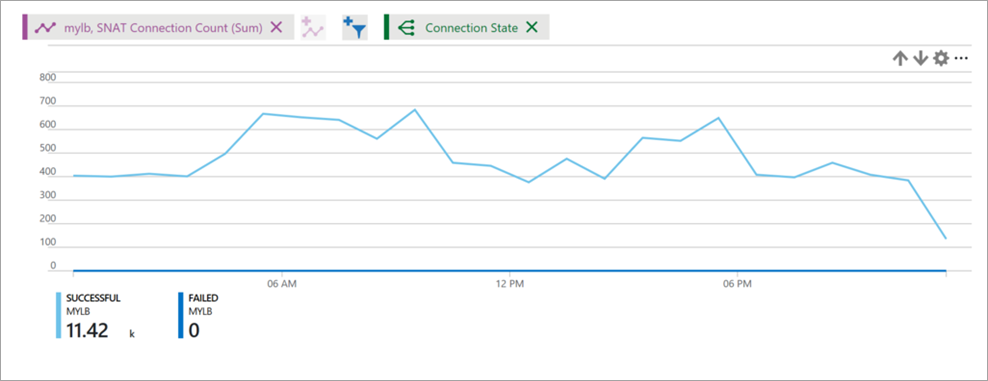
Obrázek: Počet připojení SNAT nástroje pro vyrovnávání zatížení
Návody zkontrolujte využití a přidělení portů SNAT?
Rozbalte
Metrika používaných portů SNAT sleduje, kolik portů SNAT se spotřebovává k údržbě odchozích toků. Tato metrika udává, kolik jedinečných toků se vytváří mezi internetovým zdrojem a back-endovým virtuálním počítačem nebo škálovací sadou virtuálních počítačů, která je za nástrojem pro vyrovnávání zatížení a nemá veřejnou IP adresu. Porovnáním počtu portů SNAT, které používáte s metrikou přidělených portů SNAT, můžete určit, jestli u vaší služby dochází k vyčerpání SNAT nebo k riziku vyčerpání SNAT a k výslednému selhání odchozího toku.
Pokud metriky značí riziko selhání odchozího toku , projděte si článek a proveďte kroky, které tento problém zmírní, aby se zajistil stav služby.
Zobrazení využití a přidělení portů SNAT:
Nastavte časová agregace grafu na 1 minutu, aby se zajistila zobrazení požadovaných dat.
Jako typ metriky a jako agregaci vyberte Použité porty SNAT nebo Přidělené porty SNAT.
Ve výchozím nastavení jsou tyto metriky průměrným počtem portů SNAT přidělených nebo používaných jednotlivými back-endovými virtuálními počítači nebo škálovací sadou virtuálních počítačů. Odpovídají všem veřejným IP adresám front-endu mapovaným na nástroj pro vyrovnávání zatížení agregované přes protokol TCP a UDP.
K zobrazení celkového počtu portů SNAT používaných nebo přidělených pro nástroj pro vyrovnávání zatížení použijte agregační součet metrik.
Vyfiltrujte konkrétní typ protokolu, sadu IP adres back-endu nebo IP adresy front-endu.
Pokud chcete monitorovat stav na back-end nebo instanci front-endu, použijte rozdělení.
- Rozdělení poznámek umožňuje zobrazení pouze jedné metriky najednou.
Pokud například chcete monitorovat využití SNAT pro toky TCP na počítač, agregujte podle průměru rozdělení podle IP adres back-endu a filtrování podle typu protokolu.
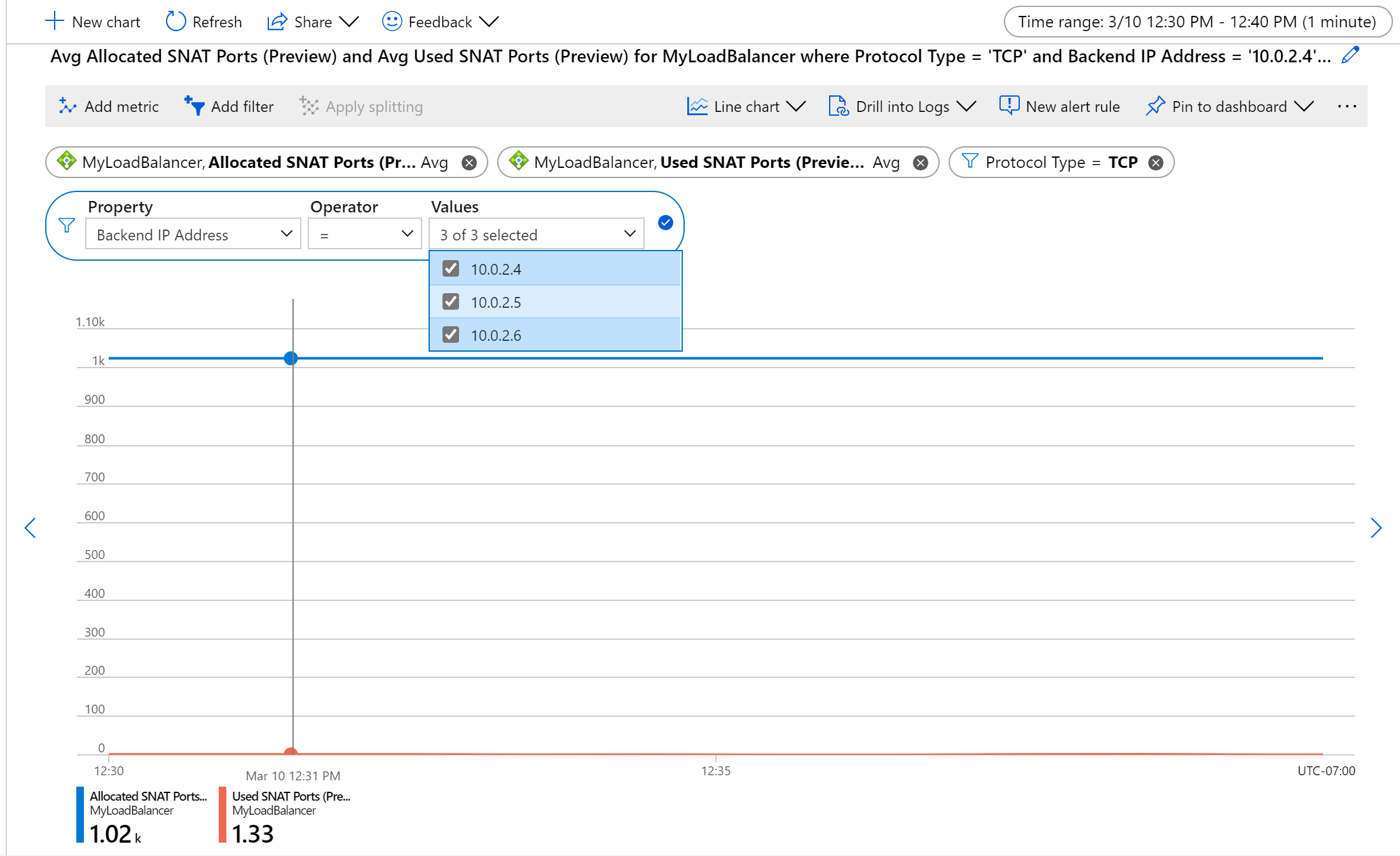
Obrázek: Průměrné přidělení portů TCP SNAT a využití pro sadu back-endových virtuálních počítačů
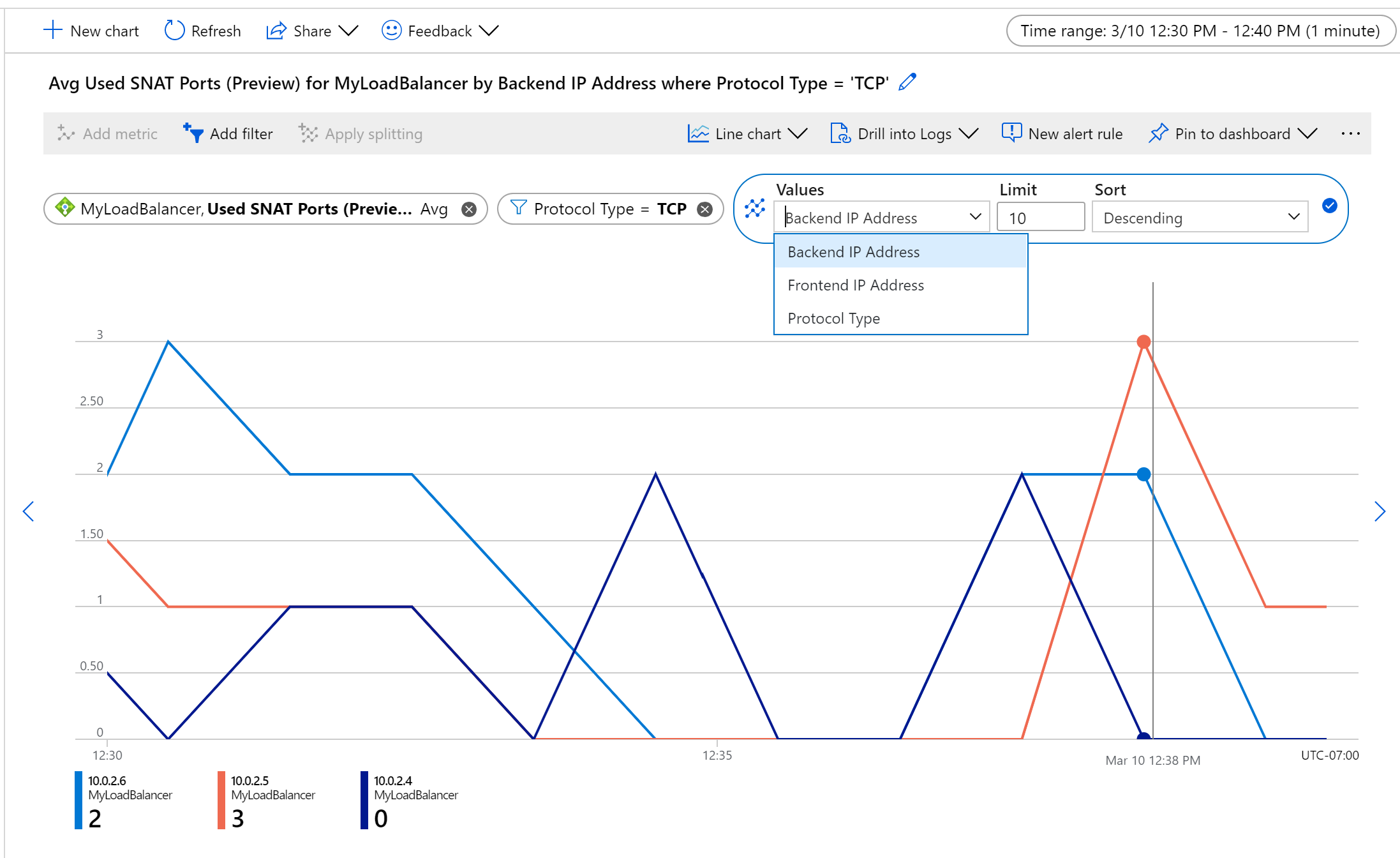
Obrázek: Využití portů TCP SNAT na instanci back-endu
Návody kontrolovat pokusy o příchozí nebo odchozí připojení pro moji službu?
Metrika rozbalení
paketů SYN popisuje svazek paketů TCP SYN, které přišly nebo byly odeslány pro odchozí toky přidružené ke konkrétnímu front-endu. Pomocí této metriky můžete porozumět pokusům o připojení TCP ke službě.Další informace o odchozích připojeních najdete v tématu Překlad zdrojových síťových adres (SNAT) pro odchozí připojení.
Jako agregaci můžete použít součet pro většinu scénářů.
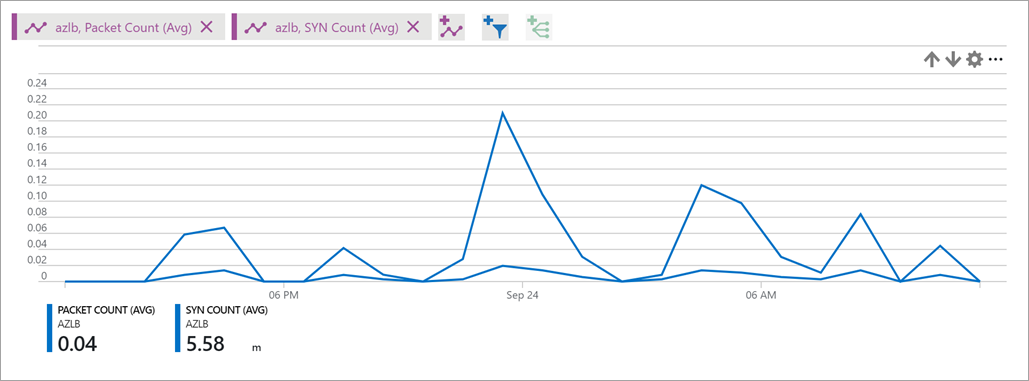
Obrázek: Počet SYN nástroje pro vyrovnávání zatížení
Návody zkontrolovat spotřebu šířky pásma sítě?
Rozbalte
Metrika čítačů bajtů a paketů popisuje objem bajtů a paketů odesílaných nebo přijatých vaší službou na základě front-endu.
Jako agregaci můžete použít součet pro většinu scénářů.
Získání statistik počtu bajtů nebo paketů:
Vyberte typ metriky Počet bajtů nebo Počet paketů s agregací Sum.
Proveďte jednu z následujících akcí:
Použijte filtr na konkrétní IP adresu front-endu, front-endový port, back-endovou IP adresu nebo back-endový port.
Získejte celkové statistiky pro prostředek nástroje pro vyrovnávání zatížení bez jakéhokoli filtrování.
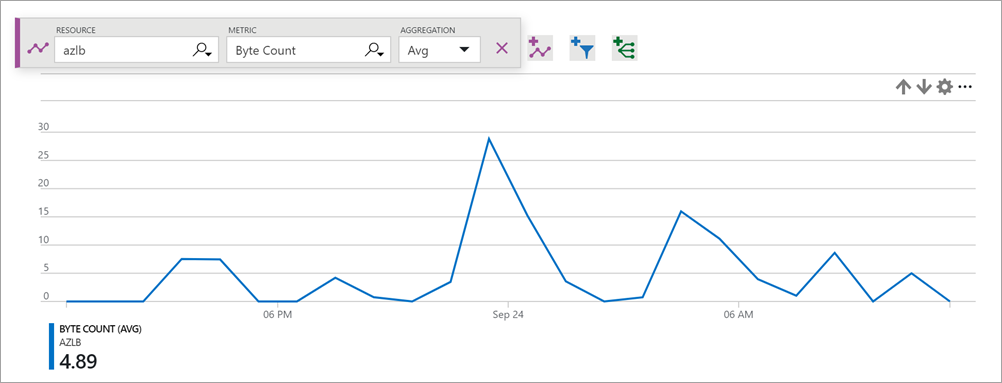
Obrázek: Počet bajtů nástroje pro vyrovnávání zatížení
Návody diagnostikovat nasazení nástroje pro vyrovnávání zatížení?
Rozbalte
Pomocí kombinace metrik dostupnosti cesty k datům a metrik stavu sondy stavu v jednom grafu můžete určit, kde se má problém hledat, a problém vyřešit. Můžete získat jistotu, že Azure funguje správně, a pomocí těchto znalostí zkonstruovat, že konfigurace nebo aplikace jsou hlavní příčinou.
Metriky sondy stavu můžete použít k pochopení toho, jak Azure zobrazuje stav vašeho nasazení podle konfigurace, kterou jste zadali. Při pohledu na sondy stavu je vždy skvělým prvním krokem při monitorování nebo určení příčiny.
Můžete provést krok dále a pomocí metriky dostupnosti cesty k datům získat přehled o tom, jak Azure zobrazuje stav podkladové roviny dat, která odpovídá za vaše konkrétní nasazení. Když zkombinujete obě metriky, můžete izolovat, kde může být chyba, jak je znázorněno v tomto příkladu:
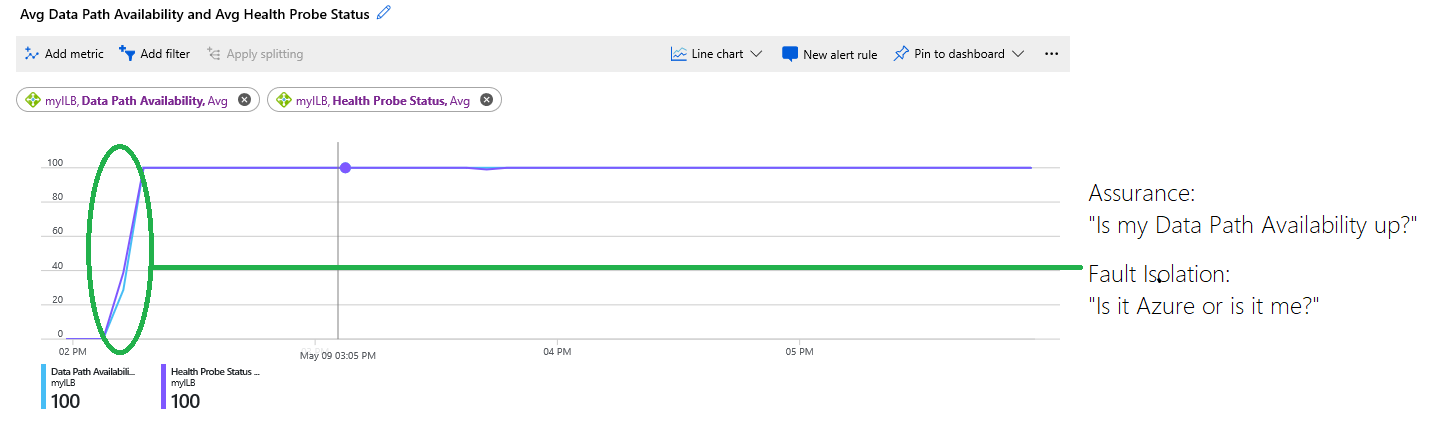
Obrázek: Kombinování dostupnosti cesty k datům a metrik stavu sondy stavu
Graf zobrazuje následující informace:
Infrastruktura hostující vaše virtuální počítače nebyla k dispozici a na začátku grafu byla 0 %. Později byla infrastruktura v pořádku a virtuální počítače byly dosažitelné a do back-endu bylo umístěné více než jeden virtuální počítač. Tyto informace jsou označené modrým trasováním dostupnosti cesty k datům, které byly později o 100 procent vyšší.
Stav sondy stavu označený fialovým trasováním je na začátku grafu o 0 %. Zakroužkovaná oblast zeleně zvýrazňuje, kde se stav sondy stavu stal v pořádku a v jakém okamžiku bylo nasazení zákazníka schopné přijímat nové toky.
Graf umožňuje zákazníkům řešit potíže s nasazením samostatně, aniž by museli hádat nebo se ptát na podporu, jestli dochází k jiným problémům. Služba byla nedostupná, protože sondy stavu selhaly kvůli chybné konfiguraci nebo neúspěšné aplikaci.
Konfigurace upozornění pro vícerozměrné metriky
Azure Load Balancer podporuje snadno konfigurovatelná upozornění pro vícerozměrné metriky. Nakonfigurujte vlastní prahové hodnoty pro konkrétní metriky tak, aby aktivovaly výstrahy s různou úrovní závažnosti, aby nedošlo k žádnému dotykovému monitorování prostředků.
Konfigurace upozornění:
Přechod na stránku upozornění pro nástroj pro vyrovnávání zatížení
Vytvoření nového pravidla upozornění
Nakonfigurujte podmínku upozornění (Poznámka: Abyste se vyhnuli hlučným výstrahám, doporučujeme nakonfigurovat upozornění s typem agregace nastavenou na Průměr, podívat se zpět na pětiminutové okno dat a s prahovou hodnotou 95 %)
(Volitelné) Přidání skupiny akcí pro automatizovanou opravu
Přiřazení závažnosti, názvu a popisu výstrahy, která umožňuje intuitivní reakci
Upozorňování na příchozí dostupnost
Poznámka:
Pokud jsou back-endové fondy vašeho nástroje pro vyrovnávání zatížení prázdné, nástroj pro vyrovnávání zatížení nebude mít žádné platné cesty k testování dat. V důsledku toho metrika dostupnosti cesty k datům nebude dostupná a neaktivují se žádná nakonfigurovaná upozornění Azure na metrikě dostupnosti cesty k datům.
Pokud chcete upozorňovat na příchozí dostupnost, můžete vytvořit dvě samostatná upozornění pomocí metrik dostupnosti cesty k datům a metrik stavu sondy stavu. Zákazníci můžou mít různé scénáře, které vyžadují konkrétní logiku upozorňování, ale pro většinu konfigurací jsou užitečné následující příklady.
Pomocí dostupnosti cesty k datům můžete aktivovat výstrahy vždy, když bude určité pravidlo vyrovnávání zatížení nedostupné. Toto upozornění můžete nakonfigurovat nastavením podmínky upozornění pro dostupnost cesty k datům a rozdělením podle aktuálních hodnot a budoucích hodnot pro front-endový port i front-endovou IP adresu. Nastavení logiky upozornění na menší nebo rovnou 0 způsobí, že se tato výstraha aktivuje vždy, když jakékoli pravidlo vyrovnávání zatížení přestane reagovat. Nastavte členitost agregace a frekvenci vyhodnocování podle požadovaného vyhodnocení.
Pokud je stav sondy stavu, můžete upozornit, když daná back-endová instance nereaguje na sondu stavu po určitou dobu. Nastavte podmínku upozornění tak, aby používala metriku stavu sondy stavu a rozdělila se podle IP adresy back-endu a back-endového portu. Tím zajistíte, že můžete upozorňovat samostatně na schopnost jednotlivých back-endových instancí obsluhovat provoz na konkrétním portu. Použijte typ agregace Průměr a nastavte prahovou hodnotu podle toho, jak často se back-endová instance vyhodnotí a jaká je prahová hodnota považována za v pořádku.
Na úrovni back-endového fondu můžete také upozornit tak, že nedělíte žádné dimenze a použijete typ agregace Průměr . To vám umožní nastavit pravidla upozornění, jako je upozornění, když 50 % členů back-endového fondu není v pořádku.
Upozorňování na odchozí dostupnost
Pro odchozí dostupnost můžete nakonfigurovat dvě samostatná upozornění pomocí počtu připojení SNAT a metrik portů SNAT.
Pokud chcete zjistit selhání odchozího připojení, nakonfigurujte výstrahu pomocí počtu připojení SNAT a filtrování na Připojení stav = Selhání. Použijte agregaci Celkem. Pak ji můžete rozdělit podle back-endové IP adresy nastavené na všechny aktuální a budoucí hodnoty, které budou upozorňovat samostatně pro každou instanci back-endu, u kterých dochází k selhání připojení. Pokud očekáváte, že dojde k selhání odchozího připojení, nastavte prahovou hodnotu na hodnotu větší než nula nebo vyšší číslo.
U používaných portů SNAT můžete upozorňovat na vyšší riziko vyčerpání SNAT a selhání odchozího připojení. Při použití této výstrahy se ujistěte, že rozdělujete podle IP adresy a protokolu back-endu. Použijte agregaci Průměr. Nastavte prahovou hodnotu tak, aby byla větší než procento počtu portů, které jste přidělili pro každou instanci, kterou určíte, je nebezpečná. Můžete například nakonfigurovat výstrahu s nízkou závažností, když back-endová instance používá 75 % přidělených portů. Nakonfigurujte upozornění s vysokou závažností, když používá 90 % nebo 100 % přidělených portů.
Stav služby Resource Health
Stav prostředků nástroje pro vyrovnávání zatížení úrovně Standard je vystaven prostřednictvím existujícího stavu resource health v části Monitorování > Stav služby. Vyhodnocuje se každých dvě minuty měřením dostupnosti cesty k datům, která určuje, jestli jsou dostupné koncové body vyrovnávání zatížení front-endu.
| Stav prostředku | Popis |
|---|---|
| dostupný | Váš prostředek load balanceru úrovně Standard je v pořádku a je dostupný. |
| Snížený výkon | Váš standardní nástroj pro vyrovnávání zatížení má události iniciované platformou nebo uživatelem, které mají vliv na výkon. Metrika dostupnosti cesty k datům hlásila méně než 90 %, ale alespoň 25 % stavu po dobu nejméně dvou minut. S tímto stavem dojde k mírnému až závažnému efektu výkonu. Postupujte podle průvodce řešením potíží s RHC a zjistěte, jestli jsou události iniciované uživatelem, které mají vliv na vaši dostupnost. |
| Neaktivní | Váš prostředek load balanceru úrovně Standard není v pořádku. Metrika dostupnosti cesty k datům hlásila méně stavu 25 % po dobu nejméně dvou minut. S tímto stavem se setkáte s výrazným účinkem na výkon nebo nedostatkem dostupnosti pro příchozí připojení. Příčinou nedostupnosti můžou být události uživatele nebo platformy. Postupujte podle průvodce řešením potíží s RHC a zjistěte, jestli jsou události iniciované uživatelem, které mají vliv na vaši dostupnost. |
| Neznámý | Stav prostředku nástroje pro vyrovnávání zatížení se neaktualizoval nebo nepřijal informace o dostupnosti cesty k datům za posledních 10 minut. Tento stav by měl být přechodný a jakmile se přijmou data, měl by odrážet správný stav. |
Zobrazení stavu prostředků veřejného standardního nástroje pro vyrovnávání zatížení:
Vyberte Sledovat> Stav služby.
Obrázek: Odkaz na stav služby ve službě Azure Monitor
Vyberte Stav prostředku a ujistěte se, že je vybrané ID předplatného a typ prostředku = nástroj pro vyrovnávání zatížení.
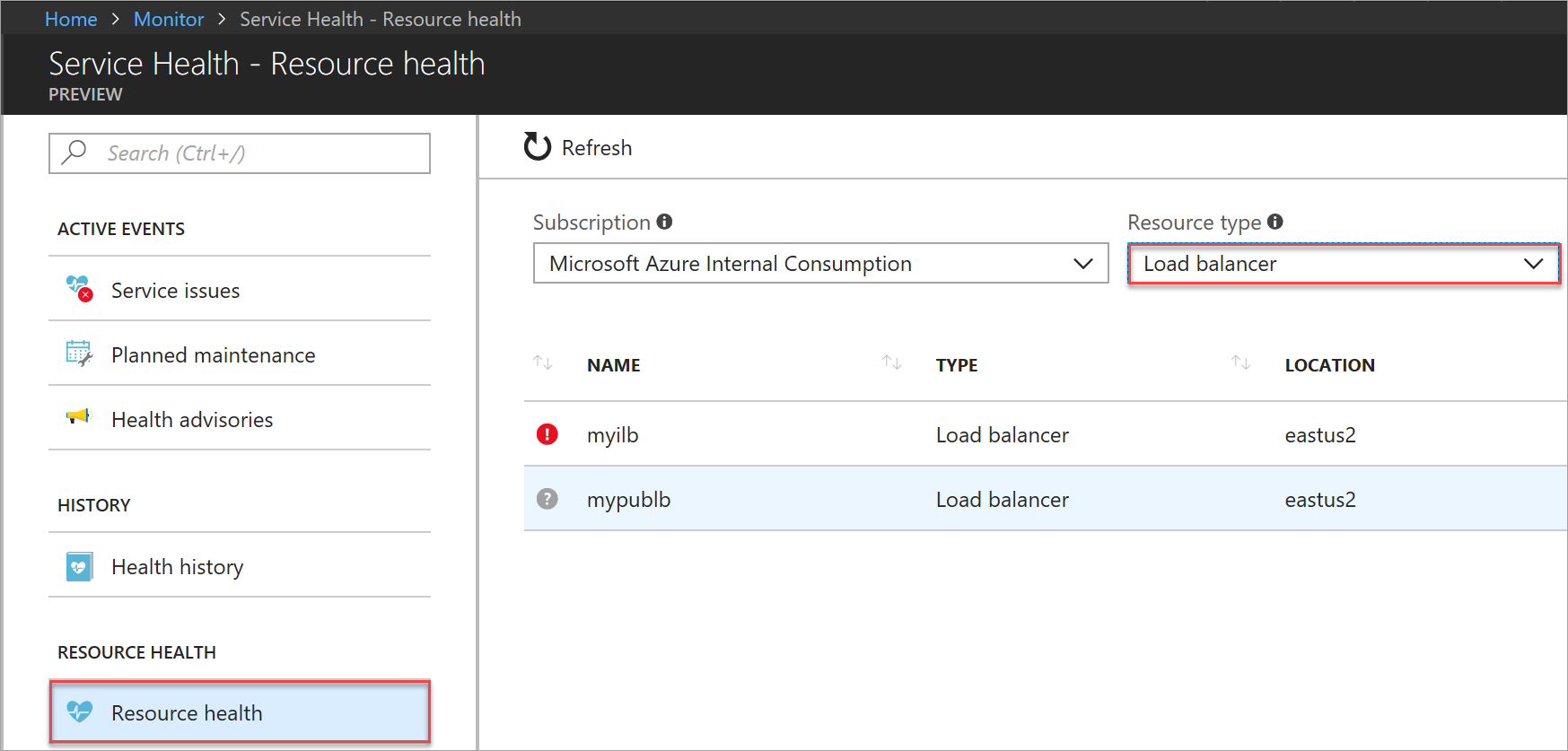
Obrázek: Výběr prostředku pro zobrazení stavu
V seznamu vyberte prostředek nástroje pro vyrovnávání zatížení a zobrazte jeho historický stav.
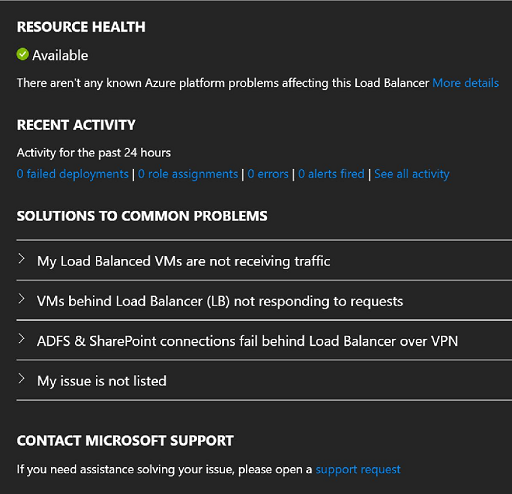
Obrázek: Stav prostředku
Obecný popis stavu prostředku je k dispozici v dokumentaci ke službě Resource Health.
Upozornění funkce Resource Health
Upozornění služby Azure Resource Health vás můžou informovat téměř v reálném čase, když se změní stav prostředku nástroje pro vyrovnávání zatížení. Doporučujeme nastavit upozornění služby Resource Health, která vás upozorní, když je prostředek nástroje pro vyrovnávání zatížení v degradované nebo nedostupné stavu.
Když vytváříte upozornění služby Azure Resource Health pro Load Balancer, Azure odesílá oznámení o stavu prostředků do vašeho předplatného Azure. Výstrahy můžete vytvářet a přizpůsobovat na základě:
- Ovlivněné předplatné
- Ovlivněná skupina prostředků
- Ovlivněný typ prostředku (Nástroj pro vyrovnávání zatížení)
- Konkrétní prostředek (jakýkoli prostředek nástroje pro vyrovnávání zatížení, pro který se rozhodnete nastavit upozornění)
- Stav události ovlivněného prostředku nástroje pro vyrovnávání zatížení
- Aktuální stav ovlivněného prostředku nástroje pro vyrovnávání zatížení
- Předchozí stav ovlivněného prostředku nástroje pro vyrovnávání zatížení
- Typ důvodu ovlivněného prostředku nástroje pro vyrovnávání zatížení
Můžete také nakonfigurovat, komu má být výstraha odeslána:
- Nová skupina akcí (která se dá použít pro budoucí výstrahy)
- Existující skupina akcí
Další informace o tom, jak nastavit tyto výstrahy služby Resource Health, najdete tady:
- Upozornění služby Resource Health pomocí webu Azure Portal
- Upozornění služby Resource Health pomocí šablon Resource Manageru
Další kroky
- Seznamte se se službou Network Analytics.
- Přečtěte si informace o použití Přehledy k zobrazení těchto metrik předkonfigurovaných pro váš nástroj pro vyrovnávání zatížení.
- Přečtěte si další informace o nástroji pro vyrovnávání zatížení úrovně Standard.