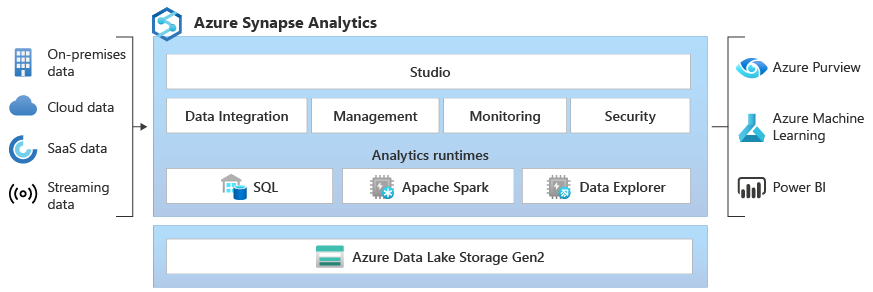
Co je Azure Synapse Data Explorer? (Preview)
Azure Synapse Data Explorer poskytuje zákazníkům interaktivní prostředí pro dotazy, které umožňuje získat přehledy z protokolů a telemetrických dat. Modul runtime Data Explorer analytics je optimalizovaný pro efektivní analýzu protokolů s využitím výkonné technologie indexování, která automaticky indexuje netextová a částečně strukturovaná data, která se běžně nacházejí v telemetrických datech, a doplňuje stávající moduly modulu runtime SQL a Apache Spark.
Další informace najdete v následujícím videu:
Čím je Azure Synapse Data Explorer jedinečný?
Snadný příjem dat – Data Explorer nabízí integrované integrace pro bez kódu nebo s nízkým kódem, příjem dat s vysokou propustností a ukládání dat do mezipaměti ze zdrojů v reálném čase. Data je možné přijímat ze zdrojů, jako jsou Azure Event Hubs, Kafka, Azure Data Lake, open source agenti, jako jsou Fluentd/Fluent Bit, a ze široké škály cloudových a místních zdrojů dat.
Bez komplexního modelování dat – u Data Explorer není potřeba vytvářet komplexní datové modely a není potřeba složité skriptování, které transformuje data před jejich spotřebou.
Bez údržby indexu – není potřeba provádět úlohy údržby, které optimalizují data pro výkon dotazů, ani údržbu indexů. Díky Data Explorer jsou všechna nezpracovaná data okamžitě dostupná, což umožňuje spouštět vysoce výkonné a vysoce souběžné dotazy na streamovaná a trvalá data. Tyto dotazy můžete použít k vytváření řídicích panelů a výstrah téměř v reálném čase a k propojení dat provozní analýzy se zbytkem platformy pro analýzu dat.
Demokratizace analýzy dat – Data Explorer demokratizuje samoobslužnou analýzu velkých objemů dat pomocí intuitivního dotazovací jazyk Kusto (KQL), který poskytuje výraznost a sílu SQL s jednoduchostí Excelu. KQL je vysoce optimalizovaný pro zkoumání nezpracovaných telemetrických dat a dat časových řad díky využití nejlepší technologie indexování textu Data Explorer ve své třídě pro efektivní vyhledávání volného textu a regex a komplexní funkce parsování pro dotazování trasování\textových dat a částečně strukturovaných dat JSON, včetně polí a vnořených struktur. KQL nabízí pokročilou podporu časových řad pro vytváření, manipulaci a analýzu více časových řad s podporou spouštění Pythonu v modulu pro vyhodnocování modelů.
Osvědčená technologie v petabajtovém měřítku – Data Explorer je distribuovaný systém s výpočetními prostředky a úložištěm, který se může nezávisle škálovat a umožňuje analýzu gigabajtů nebo petabajtů dat.
Integrovaná – Azure Synapse Analytics poskytuje interoperabilitu mezi daty mezi Data Explorer, Apache Sparkem a moduly SQL a umožňuje datovým inženýrům, datovým vědcům a datovým analytikům snadno a bezpečně přistupovat ke stejným datům v data lake a spolupracovat na tom.
Kdy použít Azure Synapse Data Explorer?
Data Explorer použijte jako datovou platformu pro vytváření analytických řešení protokolů téměř v reálném čase a Analytických řešení IoT pro:
Konsolidujte a korelujte data protokolů a událostí napříč místními, cloudovými a externími zdroji dat.
Urychlete své operace AI (rozpoznávání vzorů, detekce anomálií, prognózování a další).
Nahraďte řešení prohledávání protokolů založená na infrastruktuře, abyste ušetřili náklady a zvýšili produktivitu.
Vytvářejte analytická řešení IoT pro data IoT.
Vytvářejte analytická řešení SaaS, která budou nabízet služby interním a externím zákazníkům.
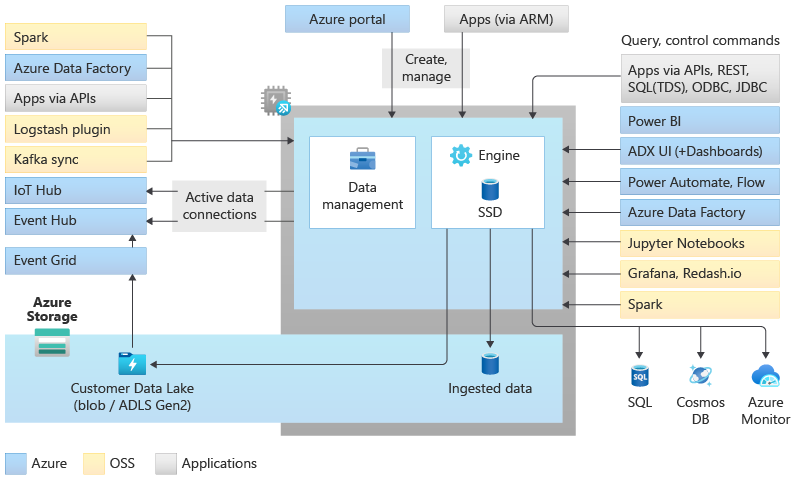
architektura fondu Data Explorer
Data Explorer fondy implementují architekturu škálování na více systémů oddělením výpočetních prostředků a prostředků úložiště. To vám umožní nezávisle škálovat jednotlivé prostředky a například spouštět více výpočetních prostředků jen pro čtení na stejných datech. Data Explorer fondy se skládají ze sady výpočetních prostředků, na kterých běží modul, který je zodpovědný za automatické indexování, komprimaci, ukládání do mezipaměti a obsluhu distribuovaných dotazů. Mají také druhou sadu výpočetních prostředků, na kterých běží služba pro správu dat zodpovědná za úlohy systému na pozadí a spravovaný příjem dat a příjem dat ve frontě. Všechna data se uchovávají v účtech spravovaného úložiště objektů blob pomocí komprimovaného sloupcového formátu.
Data Explorer fondy podporují bohatý ekosystém pro příjem dat pomocí konektorů, sad SDK, rozhraní REST API a dalších spravovaných funkcí. Nabízí různé způsoby, jak využívat data pro ad hoc dotazy, sestavy, řídicí panely, upozornění, rozhraní REST API a sady SDK.
Existuje mnoho jedinečných funkcí, díky kterým je Data Explore nejlepším analytickým modulem pro analýzu protokolů a časových řad v Azure.
Následující části zvýrazňují klíčové rozdíly.
Indexování volných a částečně strukturovaných dat umožňuje téměř v reálném čase provádět vysoce výkonné a vysoce souběžné dotazy.
Data Explorer indexuje částečně strukturovaná data (JSON) a nestrukturovaná data (volný text), takže spuštěné dotazy u tohoto typu dat dobře fungují. Ve výchozím nastavení se každé pole indexuje během příjmu dat s možností použít zásadu kódování nízké úrovně k vyladění nebo zakázání indexu pro konkrétní pole. Oborem indexu je jeden datový horizontální oddíl.
Implementace indexu závisí na typu pole následujícím způsobem:
| Typ pole | Implementace indexování |
|---|---|
| Řetězec | Modul vytvoří index obráceného termínu pro hodnoty řetězcového sloupce. Každá řetězcová hodnota se analyzuje a rozdělí na normalizované termíny a pro každý termín se zaznamená seřazený seznam logických pozic obsahující řad záznamů. Výsledný seřazený seznam termínů a jejich přidružených pozic je uložen jako neměnný B-strom. |
| Číselné Datum a čas TimeSpan |
Modul vytvoří jednoduchý dopředný index založený na rozsahu. Index zaznamenává minimální/maximální hodnoty pro každý blok, skupinu bloků a celý sloupec v rámci datového horizontálního oddílu. |
| dynamicky, | Proces příjmu dat vytvoří výčet všech "atomických" elementů v rámci dynamické hodnoty, jako jsou názvy vlastností, hodnoty a prvky pole, a předá je tvůrci indexů. Dynamická pole mají stejný index obráceného termínu jako pole řetězců. |
Tyto efektivní funkce indexování umožňují zkoumání dat zpřístupnit data téměř v reálném čase pro vysoce výkonné a vysoce souběžné dotazy. Systém automaticky optimalizuje datové horizontální oddíly za účelem dalšího zvýšení výkonu.
Dotazovací jazyk Kusto
KQL má velkou a rostoucí komunitu díky rychlému přijetí služeb Azure Monitor Log Analytics a Application Insights, Microsoft Sentinelu, Azure Data Explorer a dalších nabídek Microsoftu. Jazyk je dobře navržený se snadno čitelnou syntaxí a poskytuje plynulý přechod od jednoduchých jednoduchých dotazů na zpracování dat. To Data Explorer umožňuje poskytovat bohatou podporu IntelliSense a bohatou sadu jazykových konstruktorů a integrovaných funkcí pro agregace, časové řady a analýzy uživatelů, které nejsou k dispozici v SQL pro rychlý průzkum telemetrických dat.