Systémy AI/ML modelování hrozeb a závislosti
Autoři: Andrew Marshall, Jugal Parikh, Emre Kiciman a Ram Shankar Siva Kumar
Zvláštní poděkování patří Raulovi Rojasovi a pracovní skupině AETHER zabývající se bezpečnostním inženýrstvím.
Listopad 2019
Tento dokument je výstupem pracovní skupiny AETHER zabývající se technickou praxí pro AI a doplňuje stávající postupy SDL pro modelování hrozeb tím, že poskytuje nové pokyny ke stanovování hrozeb a snižování rizik při ohrožení specifické pro oblast AI a strojového učení. Má sloužit jako reference při kontrolách návrhu zabezpečení:
produktů a služeb, které pracují se službami založenými na AI/ML nebo jsou na nich závislé
produktů a služeb vytvářených od základu tak, aby podporovaly AI/ML
Tradiční snižování rizik při ohrožení zabezpečení je důležitější než kdy dřív. K vytvoření základu pro zabezpečení produktů, ze kterých vychází tyto pokyny, jsou zcela zásadní požadavky, které stanovuje Security Development Lifecycle. Selhání při řešení tradičních bezpečnostních hrozeb napomáhá útokům směrovaným konkrétně na AI/ML, kterými se zabývá tento dokument, na úrovni softwaru i ve fyzickém světě a také výrazně zjednodušuje napadení na nižších úrovních softwarového stacku. Úvod do zcela nových bezpečnostních hrozeb v této oblasti najdete v tématu Zajištění budoucnosti AI a strojového učení v Microsoftu.
Sady dovedností techniků zabezpečení a odborníků na data se obvykle nepřekrývají. Tyto pokyny poskytují způsob, jak můžou obě skupiny strukturovaně konverzovat o těchto zcela nových hrozbách a omezeních rizik, aniž by se technici zabezpečení museli stát odborníky na data nebo naopak.
Tento dokument je rozdělený na dvě části:
- Část Nové klíčové aspekty modelování hrozeb se zaměřuje na nové způsoby myšlení a nové otázky, které byste si měli položit při modelování hrozeb pro systémy AI/ML. Tuto část by si měli projít odborníci na data i technici zabezpečení, protože bude fungovat jako jejich příručka při diskuzích o modelování hrozeb a určování priorit při omezování rizik.
- Část Hrozby specifické pro AI/ML a omezení jejich rizik obsahuje podrobnosti o konkrétních útocích a také konkrétní kroky pro zmírnění rizika, které se dnes využívají při ochraně produktů a služeb Microsoftu před těmito hrozbami. Tato část je určená primárně pro odborníky na data, kteří můžou na základě výstupu z procesu modelování hrozeb nebo kontroly zabezpečení potřebovat implementovat konkrétní snižování rizik.
Tyto pokyny jsou uspořádány kolem nežádoucího počítače Učení taxonomie hrozeb, kterou vytvořil Ram Shankar Siva Kumar, David O'Brien, Kendra Albert, Salome Viljoen a Jeffrey Snover s názvem Režimy selhání ve stroji Učení. Pokyny ke správě incidentů týkající se třídění bezpečnostních hrozeb podrobně popsaných v tomto dokumentu najdete v panelu chyb SDL pro hrozby AI/ML. Všechny tyto živé dokumenty se v průběhu času budou vyvíjet s prostředím hrozeb.
Klíčové nové aspekty modelování hrozeb: Změna způsobu zobrazení hranic důvěryhodnosti
Předpokládejte, že může dojít k napadení nebo útoku falešnými záznamy na data, která používáte k trénování, i na poskytovatele dat. Zjistěte, jak detekovat neobvyklé a škodlivé datové položky, jak mezi nimi rozlišovat a jak se z nich zotavit.
Shrnutí
Úložiště trénovacích dat a systémy, které je hostují, jsou součástí vašeho oboru modelování hrozeb. Největší bezpečnostní hrozbou současnosti v oblasti strojového učení je útok falešnými záznamy na data, a to kvůli absenci standardních mechanismů detekce a omezování rizik v této oblasti v kombinaci se závislostí na nedůvěryhodných nebo nekurátorovaných sadách dat jako na zdroji trénovacích dat. K zajištění důvěryhodnosti vašich dat a toho, aby nedocházelo k cyklům trénování s nesmyslným vstupem a výstupem, je zcela zásadní sledovat původ a rodokmen dat.
Otázky, které byste si měli položit při kontrole zabezpečení
Kdyby došlo k útoku falešnými záznamy na vaše data nebo s nimi někdo manipuloval, jak byste to zjistili?
– Pomocí jaké telemetrie můžete detekovat zkreslení kvality vašich trénovacích dat?
Provádíte trénování na základě vstupů od uživatelů?
– Jakým způsobem provádíte ověřování/sanitizaci tohoto vstupního obsahu?
– Je struktura těchto dokumentovaných dat podobná datovým listům pro sady dat?
Pokud k trénování využíváte online úložiště dat, jaké kroky podnikáte, abyste zajistili zabezpečení připojení mezi vaším modelem a daty?
– Můžou nějakým způsobem ohlásit napadení příjemcům svých kanálů?
– Dokáží to vůbec?
Jak citlivá jsou data, která používáte k trénování?
– Katalogizujete je nebo řídíte přidávání, aktualizace a odstraňování datových položek?
Můžou být výstupem vašeho modelu citlivá data?
– Získala se tato data se svolením zdroje?
Jsou výstupem modelu pouze výsledky nezbytné k dosažení jeho cíle?
Vrací váš model hrubá skóre spolehlivosti nebo jakýkoli jiný přímý výstup, který by bylo možné zaznamenat a duplikovat?
Jaký by byl dopad v případě obnovení vašich trénovacích dat po útoku na váš model nebo jeho invertování?
Pokud dojde k náhlému prudkému poklesu úrovně spolehlivosti výstupu vašeho modelu, můžete zjistit, jak a proč k tomu došlo a jaká data to způsobila?
Definovali jste pro svůj model vstup ve správném formátu? Co děláte, abyste zajistili, že vstupy odpovídají tomuto formátu, a co děláte, když neodpovídají?
Pokud jsou vaše výstupy chybné, ale nezpůsobují hlášení chyb, jak se o tom dozvíte?
Víte, jestli jsou vaše trénovací algoritmy na matematické úrovni odolné vůči nežádoucím vstupům?
Jak byste se zotavili z nežádoucí kontaminace vašich trénovacích dat?
– Můžete nežádoucí obsah izolovat nebo dát do karantény a přetrénovat ovlivněné modely?
– Můžete se pro účely přetrénování vrátit zpět ke starší verzi modelu nebo ji obnovit?
Využíváte u nekurátorovaného veřejného obsahu zpětnovazební učení?
Začněte přemýšlet nad rodokmenem vašich dat – kdybyste zjistili problém, dokázali byste ho vysledovat až do okamžiku, kdy v sadě dat vznikl? Pokud ne, je to problém?
Mějte přehled o původu vašich trénovacích dat a identifikujte statistické normy, abyste mohli začít zjišťovat, jak vypadají anomálie.
– Jaké elementy vašich trénovacích dat jsou zranitelné vůči vnějším vlivům?
– Kdo může přispívat do sad dat, které používáte k trénování?
– Jak byste vy zaútočili na zdroje trénovacích dat, abyste poškodili konkurenci?
Související hrozby a omezení rizik v tomto dokumentu
Nežádoucí perturbace (všechny varianty)
Útok falešnými záznamy na data (všechny varianty)
Příklady útoků
Vynucení klasifikace neškodných e-mailů jako spamu nebo zajištění neodhalení škodlivého příkladu
Útočníkem sestavené vstupy, které snižují úroveň spolehlivosti správné klasifikace, a to zejména ve vysoce rizikových scénářích
Náhodná injektáž šumu útočníkem do klasifikovaných zdrojových dat za účelem snížit pravděpodobnost použití správné klasifikace v budoucnu a tím model znehodnotit
Kontaminace trénovacích dat za účelem vynucení chybné klasifikace vybraných datových bodů, což způsobí, že systém provede nebo vynechá určité akce
Identifikace akcí, které můžou provést modely, produkty nebo služby a které můžou zákazníkům způsobit škodu online nebo ve fyzickém světě
Shrnutí
Útoky na systémy AI/ML, které se nezmírní, si můžou najít cestu do fyzického světa. Jakýkoli scénář, který je možné překroutit tak, aby uživatelům způsobil psychickou nebo fyzickou újmu, pro váš produkt nebo službu představuje katastrofické riziko. To se týká i jakýchkoli citlivých dat o vašich zákaznících, která používáte k trénování, a rozhodnutí ohledně návrhu, která můžou způsobit únik těchto privátních datových bodů.
Otázky, které byste si měli položit při kontrole zabezpečení
Provádíte trénování s nežádoucími příklady? Jaký dopad mají na výstup vašeho modelu ve fyzickém světě?
Jak váš produkt nebo služba vnímá trollování? Jak ho můžete rozpoznat a reagovat na něj?
Co by bylo potřeba k tomu, aby váš model vrátil výsledek, který zmate vaši službu tak, aby odepřela přístup legitimním uživatelům?
Jaký dopad by mělo zkopírování nebo krádež vašeho modelu?
Je možné pomocí vašeho modelu odvodit členství jednotlivce v konkrétní skupině nebo jednoduše v trénovacích datech?
Může útočník vynucením provedení určitých akcí u vašeho produktu způsobit poškození dobé pověsti nebo zhoršení vztahů s veřejností?
Jak zpracováváte správně formátovaná, ale zjevně zkreslená data například od trollů?
Je možné jakýmkoli vystaveným způsobem komunikace s vaším modelem nebo jeho dotazování odhalit trénovací data nebo funkce modelu?
Související hrozby a omezení rizik v tomto dokumentu
Odvození členství
Inverze modelu
Krádež modelu
Příklady útoků
Rekonstrukce a extrakce trénovacích dat opakovaným dotazováním modelu za účelem získání výsledků s maximálním skóre spolehlivosti
Duplikace samotného modelu důkladným porovnáváním dotazů s odpověďmi
Dotazování modelu způsobem, který odhalí, že trénovací sada obsahovala určitý prvek privátních dat
Zmanipulování autonomního vozidla k ignorování značek STOP nebo semaforů
Zmanipulování konverzačních robotů k trollování neškodných uživatelů
Identifikace všech zdrojů závislostí AI/ML a front-endových prezentačních vrstev v dodavatelském řetězci dat a modelů
Shrnutí
Řada útoků na AI a strojové učení začíná oprávněným přístupem k rozhraním API zveřejněným za účelem poskytnout přístup k dotazování modelu. Vzhledem k souvisejícím rozsáhlým zdrojům dat a bohatým uživatelským prostředím představuje ověřený, ale nepatřičný (toto je šedá zóna) přístup třetích stran k vašim modelům riziko, protože může fungovat jako prezentační vrstva nad službou od Microsoftu.
Otázky, které byste si měli položit při kontrole zabezpečení
Kteří zákazníci nebo partneři mají oprávnění k přístupu k vašemu modelu nebo rozhraním API vaší služby?
– Můžou fungovat jako prezentační vrstva nad vaší službou?
– Můžete v případě napadení rychle odvolat jejich přístup?
– Jaká je vaše strategie zotavení v případě zneužití vaší služby nebo závislostí?
Může třetí strana kolem vašeho modelu vytvořit adaptační vrstvu, kterou může změnit jeho účel a poškodit Microsoft nebo jeho zákazníky?
Poskytují vám zákazníci trénovací data přímo?
– Jakým způsobem zajišťujete zabezpečení těchto dat?
– Co když jsou data škodlivá a cílem je vaše služba?
Jak v tomto případě vypadá falešně pozitivní výsledek? Jaký je dopad falešně pozitivního výsledku?
Můžete sledovat a měřit odchylky měr pravdivě pozitivních výsledků a falešně pozitivních výsledků napříč různými modely?
Jaký druh telemetrie potřebujete k prokázání důvěryhodnosti výstupu vašeho modelu zákazníkům?
Identifikujte ve vašem dodavatelském řetězci trénovacích dat pro strojové učení všechny závislosti na třetích stranách, a to nejen na open source softwaru, ale i na poskytovatelích dat.
– Proč je používáte a jak ověřujete jejich důvěryhodnost?
Používáte předem připravené modely od třetích stran nebo odesíláte data externím poskytovatelům strojového učení jako služby?
Vytvořte si seznam nejnovějších zpráv o útocích na podobné produkty nebo služby. Když víte, ke kolika hrozbám AI/ML u různých typů modelů dochází, jaký dopad by tyto útoky měly na vaše vlastní produkty?
Související hrozby a omezení rizik v tomto dokumentu
Přeprogramování neuronové sítě
Nežádoucí příklad ve fyzickém světě
Poskytovatelé strojového učení se zlými úmysly obnovující trénovací data
Útoky na dodavatelský řetězec strojového učení
Model implementovaný zadními vrátky
Napadení závislostí specifických pro strojové učení
Příklady útoků
Poskytovatel strojového učení se zlými úmysly, který do vašeho modelu s využitím určitého obejití nasadí trojského koně
Nepřátelský zákazník, který zjistí ohrožení zabezpečení v závislosti na běžném open source softwaru, kterou využíváte, a za účelem ohrožení vaší služby nahraje speciálně sestavenou datovou část trénovacích dat
Bezskrupulózní partner, který s využitím rozhraní API pro rozpoznávání obličeje vytvoří nad vaší službou prezentační vrstvu, která generuje tzv. deep fakes (realistické fotomontáže a videomontáže)
Hrozby specifické pro AI/ML a omezení jejich rizik
Č. 1: Nežádoucí perturbace
Popis
Při útocích ve stylu perturbace útočník nepozorovaně upraví dotaz tak, aby z modelu nasazeného v produkčním prostředí získal požadovanou odpověď [1]. Jedná se o porušení integrity vstupů modelu, které vede k útokům ve stylu testování neplatnými vstupními daty, jehož konečným důsledkem nemusí nutně být porušení přístupu nebo EOP, ale ohrožení výkonu klasifikace modelu. Toho můžou využít také tzv. trollové, kteří používají určitá cílová slova takovým způsobem, že je umělá inteligence zakáže, a tím efektivně zajistí odepření služeb legitimním uživatelům se jménem, které odpovídá zakázanému slovu.
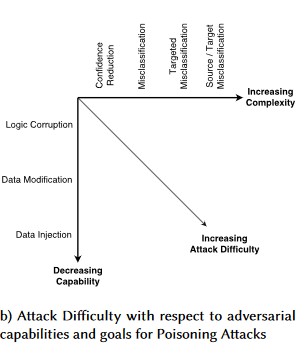 [24]
[24]
Variantní #1a: Cílová chybná klasifikace
V tomto případě útočníci vygenerují ukázku, která není ve vstupní třídě cílového klasifikátoru, ale model ji klasifikuje jako tuto konkrétní vstupní třídu. Nežádoucí ukázka může z lidského pohledu vypadat jako náhodný šum, ale útočníci mají určité znalosti cílového systému strojového učení, které jim umožňují vygenerovat bílý šum, který není náhodný, ale zneužívá určité aspekty cílového modelu. Nežádoucí osoba poskytne vstupní ukázku, která není legitimní, ale cílový systém ji klasifikuje jako legitimní třídu.
Příklady
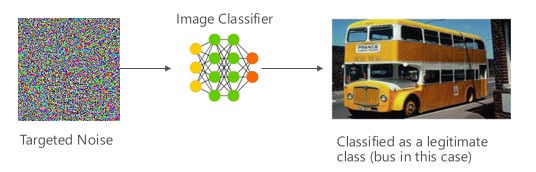 [6]
[6]
Omezení rizik
Posílení nežádoucí robustnosti pomocí modelové spolehlivosti vyvolané nežádoucím trénováním [19]: Autoři navrhují vysoce sebevědomý blízký soused (HCNN), architekturu, která kombinuje informace o spolehlivosti a hledání nejbližších sousedů, aby posílili nežádoucí odolnost základního modelu. To může pomoct odlišovat mezi správnými a chybnými predikcemi modelu v okolí bodu ze základní distribuce trénování.
Atribution-driven Kauzal analysis [20]: Autoři studují propojení mezi odolností vůči nežádoucím perturbacím a vysvětlením jednotlivých rozhodnutí generovaných modely strojového učení. Uvádějí, že nežádoucí vstupy nejsou robustní v oblasti přisuzování, tj. že maskování některých funkcí s vysokou mírou přisuzování vede u nežádoucích příkladů k nerozhodnosti modelu strojového učení ohledně změn. Naproti tomu přirozené vstupy jsou v oblasti přisuzování robustní.
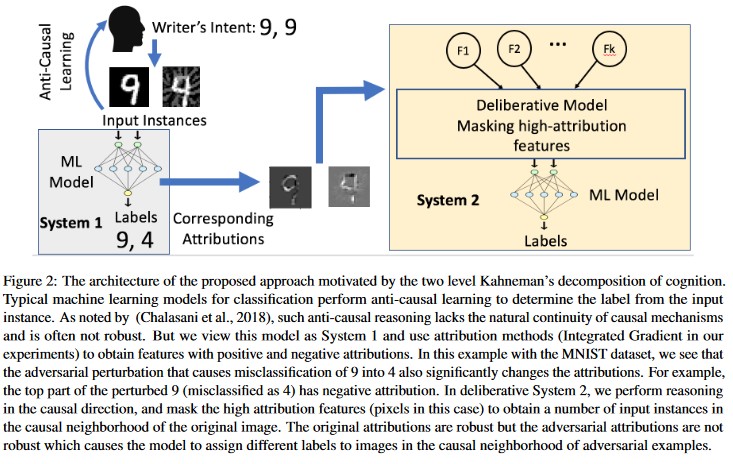 [20]
[20]
Tyto přístupy můžou zvýšit odolnost modelů strojového učení vůči nežádoucím útokům, protože oklamání tohoto dvouvrstvého kognitivního systému vyžaduje nejen útok na původní model, ale také zajištění, aby přisouzení vygenerované pro nežádoucí příklad bylo podobné původním příkladům. Aby byl nežádoucí útok úspěšný, muselo by dojít k napadení obou systémů současně.
Tradiční obdoby
Vzdálené zvýšení oprávnění, protože útočník teď má kontrolu nad vaším modelem
Závažnost
Kritické
Variantní #1b: Chybná klasifikace zdroje nebo cíle
Tato varianta je charakterizovaná jako snaha útočníka donutit model, aby pro zadaný vstup vrátil požadovaný popisek. Tím se obvykle vynutí vrácení falešně pozitivního nebo falešně negativního výsledku z modelu. Konečným výsledkem je rafinované převzetí kontroly nad přesností klasifikace modelu, čímž útočník získá možnost libovolně vytvářet určitá obcházení.
Přestože má tento útok výrazně škodlivý dopad na přesnost klasifikace, také jeho provedení může být časově náročnější, protože nežádoucí osoba musí zmanipulovat zdrojová data nejen tak, aby se už nepopisovala správně, ale také tak, aby se popisovala s použitím konkrétního požadovaného podvodného popisku. Tyto útoky často zahrnují několik kroků nebo pokusů o vynucení chybné klasifikace [3]. Pokud je model náchylný k útokům na transferové učení, které vynucují cílenou chybnou klasifikaci, nemusí existovat žádné zjistitelné stopy provozu útočníka, protože testovací útoky je možné provádět offline.
Příklady
Vynucení klasifikace neškodných e-mailů jako spamu nebo zajištění neodhalení škodlivého příkladu. Tyto útoky se označují také jako útoky spočívající ve vyhýbání se modelu nebo v napodobování.
Omezení rizik
Reaktivní nebo obranná opatření v případě odhalení
- Implementujte prahovou hodnotu minimální doby mezi voláními rozhraní API, které poskytuje výsledky klasifikace. Tím se zpomalí vícekrokové testování útoků, protože se zvýší množství času potřebné k nalezení úspěšné perturbace.
Proaktivní nebo ochranná opatření
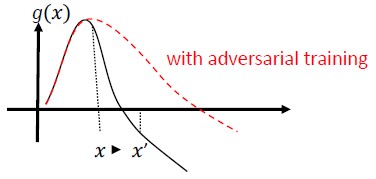
Funkce Denoising for Improving Adversarial Robustness [22]: Autoři vyvíjejí novou síťovou architekturu, která zvyšuje nežádoucí odolnost provedením označení funkcí. Sítě konkrétně obsahují bloky, které pomocí jiných než místních prostředků nebo dalších filtrů odstraňují šum z vlastností a celé sítě jsou kompletně natrénované. V kombinaci s trénováním proti nežádoucím vlivům sítě s odstraňováním šumu z vlastností výrazně zvyšují úroveň odolnosti vůči nežádoucím vlivům v případě útoků typu bílá i černá skříňka.
Nežádoucí trénování a regularizace: Trénování se známými nežádoucími ukázkami za účelem vytvoření odolnosti a odolnosti proti škodlivým vstupům. Můžete se na to dívat také jako na formu uspořádání, která penalizuje normu vstupních gradientů a usnadňuje fungování funkce předpovědi klasifikátoru (zvětšuje rozpětí vstupů). To zahrnuje správné klasifikace s nižší mírou spolehlivosti.
Investujte do vývoje monotónní klasifikace a využijte možnost výběru z monotónních funkcí. Tím se zajistí, že nežádoucí osoba nebude moct obejít klasifikátor jednoduchým doplněním vlastností z negativní třídy [13].
Stlačování vlastností [18] umožňuje posílit modely DNN prostřednictvím rozpoznávání nežádoucích příkladů. Omezuje prostor pro hledání, který má nežádoucí osoba k dispozici, tím, že spojuje ukázky, které odpovídají mnoha různým vektorům vlastností v původním prostoru, do jediné ukázky. Díky porovnávání předpovědi modelu DNN pro původní vstup s předpovědí pro stlačený vstup může stlačování vlastností pomoct odhalit nežádoucí příklady. Pokud model pro původní a stlačený příklad vygeneruje výrazně odlišné výstupy, vstup je pravděpodobně nežádoucí. Díky měření neshody mezi předpověďmi a výběru prahové hodnoty může systém pro legitimní příklady vygenerovat výstup se správnou předpovědí a nežádoucí vstupy zamítnout.

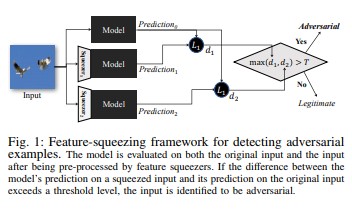 [18]
[18]Certified Defenses against Adversarial Examples [22]: Autoři navrhují metodu založenou na částečně jednoznačném uvolnění, které vypíše certifikát, který pro danou síť a testovací vstup, žádný útok nemůže vynutit, aby chyba překročila určitou hodnotu. Vzhledem k tomu, že je tento certifikát rozlišitelný, autoři ho dále společně optimalizují s využitím parametrů sítě a nabízí adaptivní regularizátor, který podporuje odolnost vůči všem útokům.
Opatření v rámci reakce
- Vydávejte upozornění na výsledky klasifikace s vysokou variancí mezi klasifikátory, zejména pokud data pochází od jednoho uživatele nebo malé skupiny uživatelů.
Tradiční obdoby
Vzdálené zvýšení oprávnění
Závažnost
Kritické
Variantní #1c: Náhodné chybné klasifikace
Toto je zvláštní varianta, kde cílovou klasifikací útočníka může být cokoli jiného než legitimní klasifikace zdroje. Útok obvykle zahrnuje náhodnou injektáž šumu do klasifikovaných zdrojových dat za účelem snížit pravděpodobnost použití správné klasifikace v budoucnu [3].
Příklady
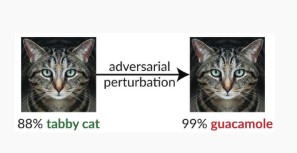
Omezení rizik
Stejné jako u varianty 1a.
Tradiční obdoby
Dočasné odepření služeb
Závažnost
Důležité
Variantní #1d: Snížení spolehlivosti
Útočník může sestavit vstupy tak, aby snížil úroveň spolehlivosti správné klasifikace, a to zejména ve vysoce rizikových scénářích. Tento typ útoku může mít také podobu velkého množství falešně pozitivních výsledků, které mají zahltit správce nebo monitorovací systémy podvodnými upozornění, která jsou k nerozeznání od legitimních upozornění [3].
Příklady

Omezení rizik
- Kromě akcí popsaných ve variantě #1a je možné omezení událostí použít ke snížení objemu výstrah z jednoho zdroje.
Tradiční obdoby
Dočasné odepření služeb
Závažnost
Důležité
#2a cílené otravy dat
Popis
Cílem útočníka je kontaminovat strojový model vygenerovaný ve fázi trénování, aby se předpovědi na základě nových dat upravovaly ve fázi testování [1]. Při cílených útocích falešnými záznamy chce útočník nesprávně klasifikovat konkrétní příklady a tím způsobit provedení nebo vynechání konkrétních akcí.
Příklady
Odeslání antivirového softwaru jako malwaru, vynucení jeho chybné klasifikace jako škodlivého softwaru a zabránění použití cílového antivirového softwaru v klientských systémech
Omezení rizik
Definování senzorů anomálií, které budou na denní bázi kontrolovat distribuci dat a upozorňovat na odchylky
– Každodenní měření odchylek v trénovacích datech a nerovnoměrné distribuce nebo posunu dat v telemetrii
Ověřování vstupu s využitím sanitizace i kontroly integrity
Při útoku falešnými záznamy se vkládají trénovací ukázky vybočující z normálu. Dvě hlavní strategie reakce na tuto hrozbu:
– Sanitizace a ověřování dat: odebrání škodlivých ukázek z trénovacích dat. Boj proti útokům falešnými záznamy s využitím negativního výběru [14]
– Obrana RONI (Reject on Negative Impact) [15]
-Robustní Učení: Vyberte algoritmy učení, které jsou robustní v přítomnosti vzorků otravy.
-Jeden takový přístup je popsán v [21], kde autoři řeší problém otravy dat ve dvou krocích: 1) zavedení nové robustní maticové faktorizační metody pro obnovení skutečného podprostoru a 2) nové robustní hlavní regrese komponent, aby vyřazuje nežádoucí instance na základě základu obnoveného v kroku (1). Charakterizují nezbytné a postačující podmínky pro úspěšné obnovení pravého podprostoru a představují hranici očekávaných ztrát předpovědí v porovnání se „základní pravdou“ (ground truth).
Tradiční obdoby
Hostitel s trojským koněm, prostřednictvím kterého může útočník přetrvávat v síti. Jsou ohrožená trénovací nebo konfigurační data, která se ingestují nebo kterým se důvěřuje při vytváření modelů.
Závažnost
Kritické
#2b nerozlišující otravu dat
Popis
Cílem tohoto útoku je narušit kvalitu nebo integritu cílové sady dat. Mnoho sad dat je veřejných, nedůvěryhodných nebo nekurátorovaných, takže vznikají další obavy ohledně možnosti taková porušení integrity dat v první řadě vůbec identifikovat. Trénování na základě neznámým způsobem napadených dat představuje situaci s nesmyslným vstupem a výstupem. Po zjištění takové situace je potřeba provést posouzení, aby se zjistilo, v jakém rozsahu došlo k porušení zabezpečení dat, a provést umístění do karantény a přetrénování.
Příklady
Společnost scrapuje z dobře známého a důvěryhodného webu data o futures kontraktech na ropu pro trénování vlastních modelů. Web poskytovatele dat je následně ohrožený útokem prostřednictvím injektáže SQL. Útočník může datovou sadu libovolně poškodit a trénovaný model nemůže nijak zjistit, že došlo k poškození dat.
Omezení rizik
Stejné jako u varianty 2a.
Tradiční obdoby
Ověřené odepření služeb pro prostředek s vysokou hodnotou
Závažnost
Důležité
Útoky na inverzi modelů č. 3
Popis
Privátní funkce používané v modelech strojového učení je možné obnovit [1]. To zahrnuje rekonstrukci privátních trénovacích dat, ke kterým útočník nemá přístup. V biometrické komunitě se tyto útoky označují také jako gradientní útoky [16, 17]. Toho se dosáhne nalezením vstupu, který maximalizuje vrácenou úroveň spolehlivosti v závislosti na klasifikaci odpovídající cíli [4].
Příklady
 [4]
[4]
Omezení rizik
Rozhraní modelů natrénovaných na základě citlivých dat vyžadují silné řízení přístupu.
Omezte četnost dotazů, které model povoluje.
Implementujte mezi uživatele/volající a skutečný model brány, které budou provádět ověřování vstupu u všech navrhovaných dotazů, zamítat vše, co neodpovídá definici modelu ohledně správnosti vstupu, a vracet pouze minimální potřebné množství informací k tomu, aby byly užitečné.
Tradiční obdoby
Cílené zpřístupnění tajných informací
Závažnost
Na standardním panelu chyby SDL je výchozí závažnost Důležitá, ale v případě extrahování citlivých nebo identifikovatelných osobních údajů by se zvýšila na Kritickou.
Útok na odvození členství č. 4
Popis
Útočník může zjistit, jestli byl daný datový záznam součástí trénovací sady dat vašeho modelu, nebo ne [1]. Výzkumní pracovníci dokázali předpovědět hlavní postup pacienta (např. operaci, po které pacient prošel) na základě atributů (např. věk, pohlaví, nemocnice) [1].
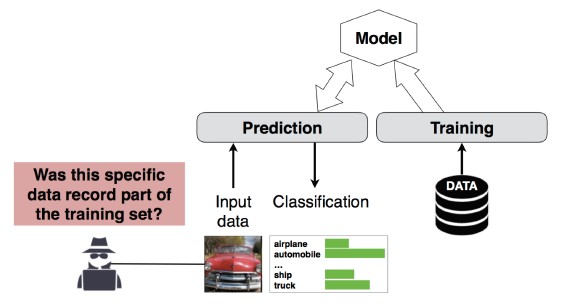 [12]
[12]
Omezení rizik
Výzkumné studie prokazující proveditelnost tohoto útoku naznačují, že by při omezování rizik mohla být účinná rozdílová ochrana soukromí [4, 9]. V Microsoftu se stále jedná o novou oblast a pracovní skupina AETHER zabývající se bezpečnostním inženýrstvím doporučuje rozvíjet dovednosti a investovat do výzkumu v této oblasti. Tento výzkum by musel vyjmenovat funkce rozdílové ochrany soukromí a vyhodnotit jejich praktickou efektivitu při omezování rizik a následně navrhnout způsob, jakým by se tato ochrana mohla transparentně dědit na našich platformách online služeb podobně, jako kompilace kódu v sadě Visual Studio poskytuje ve výchozím nastavení zapnutou ochranu transparentní pro vývojáře i uživatele.
Do jisté míry může být při omezování rizik efektivní využít vyřazování neuronů a vrstvení modelů. Využitím vyřazování neuronů se kromě zvýšení odolnosti neuronové sítě vůči tomuto typu útoku zvýší také výkon modelů [4].
Tradiční obdoby
Ochrana osobních údajů v datech. Odvozují se informace o zahrnutí datového bodu v trénovací sadě, ale samotná trénovací data se nezpřístupňují.
Závažnost
Toto je problém s ochranou osobních údajů, a ne problém se zabezpečením. Vzhledem k překrývání domén se tento problém řeší v doprovodných materiálech k modelování hrozeb, ale jakákoli odpověď na tomto místě by se řídila ochranou osobních údajů, a ne zabezpečením.
Č. 5 Krádež modelu
Popis
Útočníci na základě legitimního dotazování modelu znovu vytvoří základní model. Funkce nového modelu jsou stejné jako funkce základního modelu [1]. Po opětovném vytvoření modelu je možné jeho invertováním získat informace o funkcích a odvozovat závěry z trénovacích dat.
Řešení rovnic – V případě modelu, který prostřednictvím výstupu rozhraní API vrací pravděpodobnosti tříd, může útočník sestavit dotazy, kterými zjistí neznámé proměnné v modelu.
Hledání cesty – Útok, který zneužívá zvláštnosti rozhraní API k extrahování „rozhodnutí“ rozhodovacího stromu při klasifikaci vstupu [7].
Útok na přenosnost – Nežádoucí osoba může natrénovat místní model, například odesíláním dotazů předpovědí do cílového modelu, a pomocí něj sestavit nežádoucí příklady, které se přenesou do cílového modelu [8]. Pokud útočník extrahuje kopii vašeho modelu a zjistí, že je zranitelný vůči určitému typu nežádoucího vstupu, může vyvíjet nové útoky na váš model nasazený v produkčním prostředí zcela offline.
Příklady
V prostředích, kde model strojového učení slouží k detekci nežádoucího chování, jako je identifikace spamu, klasifikace malwaru nebo detekce síťových anomálií, může extrakce modelu usnadnit útoky spočívající ve vyhýbání se obraně [7].
Omezení rizik
Proaktivní nebo ochranná opatření
Minimalizujte nebo znepřehledněte podrobnosti vracené v rozhraní API pro předpovědi při zachování jejich užitečnosti pro „poctivé“ aplikace [7].
Definujte pro vstupy vašeho modelu dotaz ve správném formátu a vracejte výsledky pouze v reakci na dokončené vstupy v definovaném správném formátu.
Vracejte zaokrouhlené hodnoty spolehlivosti. Většina legitimních volajících nepotřebuje výsledek s přesností na několik desetinných míst.
Tradiční obdoby
Neověřené úmyslné poškozování systémových dat v režimu jen pro čtení cílené na zpřístupnění informací s vysokou hodnotou
Závažnost
Důležitá v modelech citlivých na zabezpečení, jinak Střední
#6 Přeprogramování neurální sítě
Popis
Pomocí speciálně sestaveného dotazu může nežádoucí osoba přeprogramovat systémy strojového učení na úkol, který se liší od původního záměru tvůrce [1].
Příklady
Slabé řízení přístupu k rozhraní API pro rozpoznávání obličeje umožňující třetím stranám začlenit aplikace s cílem poškodit zákazníky Microsoftu, jako je například generátor tzv. deep fakes (realistické fotomontáže a videomontáže).
Omezení rizik
Silné vzájemné ověřování na klientském<> serveru a řízení přístupu k rozhraním modelu
Vyřazení problémových účtů
Identifikujte a vynucujte pro vaše rozhraní API smlouvu SLA. Určete přijatelnou dobu potřebnou k vyřešení problému po jeho nahlášení a zajistěte, aby se problém po vypršení platnosti smlouvy SLA dál nereprodukoval.
Tradiční obdoby
Toto je scénář zneužití. V tomto případě byste místo otevírání incidentu zabezpečení měli spíše jednoduše zakázat účet pachatele.
Závažnost
Důležitá až kritická
#7 Nežádoucí příklad ve fyzické doméně (bity-atomy>)
Popis
Nežádoucím příkladem je vstup a dotaz ze škodlivé entity odeslané s jediným cílem zavádějícího systému strojového učení [1]
Příklady
Tyto příklady se můžou projevit ve fyzickém světě, například v případě autonomního vozidla zmanipulovaného k jízdě přes značku STOP jejím nasvícením určitou barvou světla (nežádoucí vstup), což přinutí systém rozpoznávání obrazu, aby ji ignoroval.
Tradiční obdoby
Zvýšení oprávnění, vzdálené spuštění kódu
Omezení rizik
Tyto útoky se objevují, protože se nevyřešily problémy na úrovni strojového učení (vrstva dat a algoritmů pod rozhodováním založeným na AI). Stejně jako u jakéhokoli jiného softwarového *nebo* fyzického systému může být vrstva pod cílem vždy napadena tradičními vektory. Z tohoto důvodu jsou tradiční postupy zabezpečení důležitější než kdy dřív, a to zejména u vrstvy nezmírněných ohrožení zabezpečení (vrstva dat a algoritmů), která se používá mezi AI a tradičním softwarem.
Závažnost
Kritické
#8 Poskytovatelé strojového učení se zlými úmysly, kteří můžou obnovit trénovací data
Popis
Poskytovatel se zlými úmysly zadními vrátky implementuje algoritmus, kterým získá privátní trénovací data. Pouze na základě modelu se potom podařilo rekonstruovat obličeje a texty.
Tradiční obdoby
Cílené zpřístupnění informací
Omezení rizik
Výzkumné studie prokazující proveditelnost tohoto útoku naznačují, že by při omezování rizik mohlo být účinné homomorfní šifrování. V Microsoftu se do této oblasti v současné době příliš neinvestuje a pracovní skupina AETHER zabývající se bezpečnostním inženýrstvím doporučuje rozvíjet dovednosti a investovat do výzkumu v této oblasti. Tento výzkum by musel vyjmenovat principy homomorfního šifrování a vyhodnotit jejich praktickou efektivitu při omezování rizik v případě setkání s poskytovateli strojového učení jako služby se zlými úmysly.
Závažnost
Důležitá, pokud jde o identifikovatelné osobní údaje, jinak Střední
#9: Útok na dodavatelský řetězec ML
Popis
Vzhledem k velkým prostředkům (datům a výpočtům) potřebným k trénování algoritmů je aktuálním postupem opětovné použití modelů natrénovaných velkými společnostmi a jejich úpravou po ruce pro úkoly (např. ResNet je oblíbený model rozpoznávání obrázků od Microsoftu). Tyto modely se spravují v Model Zoo (Caffe hostuje oblíbené modely rozpoznávání obrazu). Při tomto útoku nežádoucí osoba útočí na modely hostované v Caffe a tím poškozuje zdroj pro všechny ostatní. [1]
Tradiční obdoby
Ohrožení zabezpečení závislosti na třetí straně nesouvisející se zabezpečením
Nevědomé hostování malwaru na App Storu
Omezení rizik
Pokud je to možné, minimalizujte pro modely a data množství závislostí na třetích stranách.
Začleňte tyto závislosti do svého procesu modelování hrozeb.
Využijte silné ověřování, řízení přístupu a šifrování mezi systémy Microsoftu a systémy třetích stran.
Závažnost
Kritické
Č. 10 Backdoor Machine Učení
Popis
Proces trénování zajišťuje externě třetí strana se zlými úmysly, která úmyslně poškozuje trénovací data a doručila model s trojským koněm, který vynucuje cílené chybné klasifikace, například klasifikaci určitého viru jako neškodného [1]. Jedná se o riziko scénáře generování modelů strojového učení jako služby.
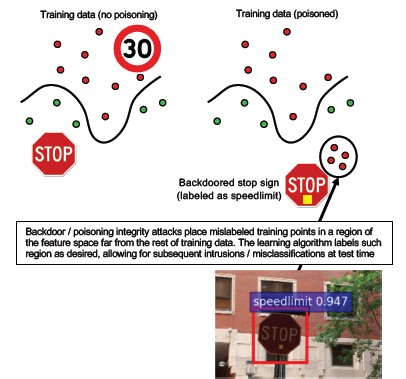 [12]
[12]
Tradiční obdoby
Ohrožení zabezpečení závislosti na třetí straně související se zabezpečením
Ohrožení zabezpečení mechanismu aktualizace softwaru
Ohrožení zabezpečení certifikační autority
Omezení rizik
Reaktivní nebo obranná opatření v případě odhalení
- Když se zjistí tato hrozba, ke škodě již došlo, takže modelu ani jakýmkoli trénovacím datům od poskytovatele se zlými úmysly není možné důvěřovat.
Proaktivní nebo ochranná opatření
Trénujte všechny citlivé modely interně.
Katalogizujte trénovací data a ujistěte se, že pocházejí od důvěryhodné třetí strany se silnými postupy zabezpečení.
Vytvořte model hrozeb pro interakce mezi poskytovatelem strojového učení jako služby a vašimi vlastními systémy.
Opatření v rámci reakce
- Stejná jako v případě ohrožení zabezpečení externí závislosti
Závažnost
Kritické
Č. 11 Zneužít softwarové závislosti systému ML
Popis
Při tomto útoku útočník NEMANIPULUJE s algoritmy. Místo toho zneužívá chyby zabezpečení softwaru, jako jsou přetečení vyrovnávací paměti nebo skriptování mezi weby [1]. Pořád je jednodušší napadnout vrstvy softwaru pod AI/ML než útočit přímo na vrstvu učení, a proto jsou nezbytné tradiční postupy snižování rizik při ohrožení zabezpečení podrobně popsané v Security Development Lifecycle.
Tradiční obdoby
Ohrožení zabezpečení závislosti na open source softwaru
Ohrožení zabezpečení webového serveru (XSS, CSRF, chyba ověřování vstupu rozhraní API)
Omezení rizik
Spojte se se svým týmem zabezpečení a postupujte podle příslušných osvědčených postupů pro Security Development Lifecycle a kontrolu provozního zabezpečení.
Závažnost
Proměnná až do úrovně Kritická v závislosti na typu ohrožení zabezpečení tradičního softwaru
Bibliografie
[1] Režimy selhání ve strojových Učení, Ram Shankar Siva Kumar, David O'Brien, Kendra Albert, Salome Viljoen a Jeffrey Snover,https://learn.microsoft.com/security/failure-modes-in-machine-learning
[2] Pracovní skupina AETHER zabývající se bezpečnostním inženýrstvím, virtuální tým zabývající se původem a rodokmenem dat
[3] Nežádoucí příklady v hlubokém Učení: Charakterizace a divergence, Wei, et al,https://arxiv.org/pdf/1807.00051.pdf
[4] Ml-Leaks: Útoky na odvozování modelů a nezávislých na základě členství a ochrany dat na strojových Učení modelech, Salem, et al,https://arxiv.org/pdf/1806.01246v2.pdf
[5] M. Fredrikson, S. Jha a T. Ristenpart. Model inversion attacks that exploit confidence information and basic countermeasures. In: Proceedings of the 2015 ACM SIGSAC Conference on Computer and Communications Security (CCS).
[6] Nicolas Papernot a Patrick McDaniel. Adversarial examples in machine learning AIWTB 2017
[7] Florian Tramèr (École Polytechnique Fédérale de Lausanne (EPFL)), Fan Zhang (Cornell University), Ari Juels (Cornell Tech), Michael K. Reiter (The University of North Carolina at Chapel Hill) a Thomas Ristenpart (Cornell Tech). Stealing machine learning models via prediction APIs
[8] Florian Tramèr, Nicolas Papernot, Ian Goodfellow, Dan Boneh a Patrick McDaniel. The space of transferable adversarial examples
[9] Yunhui Long, Vincent Bindschaedler, Lei Wang, Diyue Bu, Xiaofeng Wang, Haixu Tang, Carl A. Gunter a Kai Chen. Understanding membership inferences on well-generalized learning models
[10] Simon-Gabriel a kol. Adversarial vulnerability of neural networks increases with input dimension, ArXiv 2018
[11] Lyu a kol. A unified gradient regularization family for adversarial examples, ICDM 2015
[12] Divoké vzory: Deset let po vzestupu nežádoucího stroje Učení - NeCS 2019 Battista Biggioa, Fabio Roli
[13] Inigo Incer a kol. Adversarially robust malware detection using monotonic classification
[14] Battista Biggio, Igino Corona, Giorgio Fumera, Giorgio Giacinto a Fabio Roli. Bagging classifiers for fighting poisoning attacks in adversarial classification tasks
[15] Vylepšené odmítnutí negativního dopadu obrany Hongjiang Li a Patrick P.K. Chan
[16] Adler. Vulnerabilities in biometric encryption systems. 5th Int’l Conf. AVBPA, 2005
[17] Galbally, McCool, Fierrez, Marcel a Ortega-Garcia. On the vulnerability of face verification systems to hill-climbing attacks. Patt. Rec., 2010
[18] Weilin Xu, David Evans a Yanjun Qi. Vyřazování funkcí: Detekce nežádoucích příkladů v hlubokých neurálních sítích 2018 Network and Distributed System Security Symposium. 18–21 února
[19] Xi Wu, Uyeong Jang, Jiefeng Chen, Lingjiao Chen a Somesh Jha. Reinforcing adversarial robustness using model confidence induced by adversarial training
[20] Susmit Jha, Sunny Raj, Steven Fernandes, Sumit Kumar Jha, Somesh Jha, Gunjan Verma, Brian Jalaian a Ananthram Swami. Attribution-driven causal analysis for detection of adversarial examples
[21] Chang Liu a kol. Robust linear regression against training data poisoning
[22] Cihang Xie, Yuxin Wu, Laurens van der Maaten, Alan Yuille a Kaiming He. Feature denoising for improving adversarial robustness
[23] Aditi Raghunathan, Jacob Steinhardt a Percy Liang. Certified defenses against adversarial examples
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro