Přizpůsobení modelu (verze 4.0 Preview)
Přizpůsobení modelu umožňuje trénovat specializovaný model analýzy obrázků pro váš vlastní případ použití. Vlastní modely můžou provádět klasifikaci obrázků (značky se vztahují na celý obrázek) nebo rozpoznávání objektů (značky se vztahují na konkrétní oblasti obrázku). Po vytvoření a vytrénování vlastního modelu patří do vašeho prostředku Vision a můžete ho volat pomocí rozhraní API pro analýzu obrázků.
Rychlé zprovoznění implementujte přizpůsobení modelu rychle a snadno:
Důležité
Vlastní model můžete trénovat pomocí služby Custom Vision nebo služby Image Analysis 4.0 s přizpůsobením modelu. Následující tabulka porovnává dvě služby.
| Oblasti | Custom Vision Service | Služba Analýza obrázků 4.0 | ||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Úlohy | Rozpoznávání objektů klasifikaceobrázků | Rozpoznávání objektů klasifikaceobrázků | ||||||||||||||||||||||||||||||||||||
| Základní model | CNN | Transformátorový model | ||||||||||||||||||||||||||||||||||||
| Popisky | Customvision.ai | AML Studio | ||||||||||||||||||||||||||||||||||||
| Webový portál | Customvision.ai | Vision Studio | ||||||||||||||||||||||||||||||||||||
| Knihovny | REST, SDK | REST, Ukázka Pythonu | ||||||||||||||||||||||||||||||||||||
| Minimální potřebná trénovací data | 15 obrázků na kategorii | 2–5 obrázků na kategorii | ||||||||||||||||||||||||||||||||||||
| Úložiště trénovacích dat | Odesláno do služby | Účet úložiště objektů blob zákazníka | ||||||||||||||||||||||||||||||||||||
| Hosting modelu | Cloud a hraniční zařízení | Pouze hostování cloudu, hostování kontejnerů Edge | ||||||||||||||||||||||||||||||||||||
| Kvalita AI |
|
|
||||||||||||||||||||||||||||||||||||
| Ceny | Ceny služby Custom Vision | Ceny analýzy obrázků |
Součásti scénáře
Hlavními komponentami systému přizpůsobení modelu jsou trénovací obrázky, soubor COCO, objekt datové sady a objekt modelu.
Trénovací obrázky
Vaše sada trénovacích obrázků by měla obsahovat několik příkladů popisků, které chcete zjistit. Po vytrénování modelu budete také chtít shromáždit několik dalších obrázků k otestování modelu. Aby bylo možné přistupovat k modelu, musí být image uložené v kontejneru Azure Storage.
K efektivnímu trénování modelu používejte obrázky s různými vizuálními možnostmi. Vyberte obrázky, které se liší podle:
- úhel kamery
- osvětlení
- pozadí
- vizuální styl
- individuální/seskupené předměty
- size
- type
Kromě toho se ujistěte, že všechny trénovací obrázky splňují následující kritéria:
- Obrázek musí být prezentován ve formátu JPEG, PNG, GIF, BMP, WEBP, ICO, TIFF nebo MPO.
- Velikost souboru obrázku musí být menší než 20 megabajtů (MB).
- Rozměry obrázku musí být větší než 50 × 50 pixelů a menší než 16 000 × 16 000 pixelů.
Soubor COCO
Soubor COCO odkazuje na všechny trénovací obrázky a přidruží je k informacím o označování. V případě detekce objektů zadal souřadnice ohraničujícího rámečku každé značky na každém obrázku. Tento soubor musí být ve formátu COCO, což je konkrétní typ souboru JSON. Soubor COCO by měl být uložený ve stejném kontejneru Azure Storage jako trénovací image.
Tip
Informace o souborech COCO
Soubory COCO jsou soubory JSON s konkrétními požadovanými poli: "images", "annotations"a "categories". Ukázkový soubor COCO bude vypadat takto:
{
"images": [
{
"id": 1,
"width": 500,
"height": 828,
"file_name": "0.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/0.jpg"
},
{
"id": 2,
"width": 754,
"height": 832,
"file_name": "1.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/1.jpg"
},
...
],
"annotations": [
{
"id": 1,
"category_id": 7,
"image_id": 1,
"area": 0.407,
"bbox": [
0.02663142641129032,
0.40691584277841153,
0.9524163571731749,
0.42766634515266866
]
},
{
"id": 2,
"category_id": 9,
"image_id": 2,
"area": 0.27,
"bbox": [
0.11803319477782331,
0.41586723392402375,
0.7765206955096307,
0.3483334397217212
]
},
...
],
"categories": [
{
"id": 1,
"name": "vegall original mixed vegetables"
},
{
"id": 2,
"name": "Amy's organic soups lentil vegetable"
},
{
"id": 3,
"name": "Arrowhead 8oz"
},
...
]
}
Referenční dokumentace k poli souboru COCO
Pokud generujete vlastní soubor COCO úplně od začátku, ujistěte se, že jsou všechna požadovaná pole vyplněná správnými podrobnostmi. Následující tabulky popisují každé pole v souboru COCO:
"images"
| Klíč | Typ | Popis | Povinné? |
|---|---|---|---|
id |
integer | Jedinečné ID obrázku od 1 | Ano |
width |
integer | Šířka obrázku v pixelech | Ano |
height |
integer | Výška obrázku v pixelech | Ano |
file_name |
string | Jedinečný název obrázku | Ano |
absolute_url nebo coco_url |
string | Cesta k obrázku jako absolutní identifikátor URI objektu blob v kontejneru objektů blob. Prostředek Vision musí mít oprávnění ke čtení souborů poznámek a všech odkazovaných souborů obrázků. | Ano |
Hodnotu pro absolute_url najdete ve vlastnostech kontejneru objektů blob:
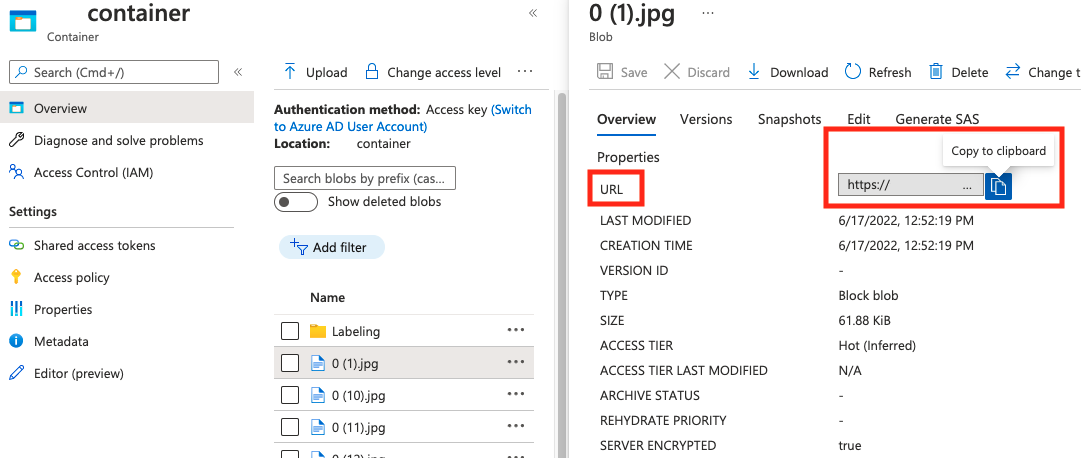
"poznámky"
| Klíč | Typ | Popis | Povinné? |
|---|---|---|---|
id |
integer | ID poznámky | Ano |
category_id |
integer | ID kategorie definované v oddílu categories |
Ano |
image_id |
integer | ID obrázku | Ano |
area |
integer | Hodnota "Width" x 'Height' (třetí a čtvrtá hodnota bbox) |
No |
bbox |
list[float] | Relativní souřadnice ohraničujícího rámečku (0 až 1) v pořadí 'Vlevo', 'Horní', 'Šířka', 'Výška' | Ano |
"categories" (kategorie)
| Klíč | Typ | Popis | Povinné? |
|---|---|---|---|
id |
integer | Jedinečné ID pro každou kategorii (třída popisku). Ty by se měly vyskytovat v annotations části. |
Ano |
name |
string | Název kategorie (třída popisku) | Ano |
Ověření souboru COCO
Ukázkový kód Pythonu můžete použít ke kontrole formátu souboru COCO.
Objekt datové sady
Objekt Dataset je datová struktura uložená službou Image Analysis Service, která odkazuje na soubor přidružení. Před vytvořením a trénování modelu je potřeba vytvořit objekt Datové sady .
Objekt modelu
Objekt Model je datová struktura uložená službou Analýza obrázků, která představuje vlastní model. Aby bylo možné provést počáteční trénování, musí být přidružená k datové sadě . Po vytrénování můžete model dotazovat zadáním jeho názvu do parametru model-name dotazu volání rozhraní API Pro analýzu obrázků.
Maximální kvóty
Následující tabulka popisuje omezení škálování vlastních projektů modelu.
| Kategorie | Obecný klasifikátor obrázků | Obecný detektor objektů |
|---|---|---|
| Maximální počet trénovacích hodin v # | 288 (12 dní) | 288 (12 dní) |
| Maximální počet trénovacích obrázků v # | 1 000 000 | 200 000 |
| Maximální počet zkušebních obrázků v # | 100 000 | 100 000 |
| Minimální počet trénovacích obrázků na kategorii | 2 | 2 |
| Maximální počet značek # na obrázek | 0 | – |
| Maximální počet oblastí # na obrázek | – | 1000 |
| Maximální počet kategorií # | 2 500 | 1000 |
| Minimální kategorie # | 2 | 0 |
| Maximální velikost obrázku (trénování) | 20 MB | 20 MB |
| Maximální velikost obrázku (předpověď) | Synchronizace: 6 MB, Dávka: 20 MB | Synchronizace: 6 MB, Dávka: 20 MB |
| Maximální šířka a výška obrázku (trénování) | 10,240 | 10,240 |
| Minimální šířka a výška obrázku (předpověď) | 50 | 50 |
| Dostupné oblasti | USA – západ 2, USA – východ, Západní Evropa | USA – západ 2, USA – východ, Západní Evropa |
| Přijaté typy obrázků | jpg, png, bmp, gif, jpeg | jpg, png, bmp, gif, jpeg |
Nejčastější dotazy
Proč při importu z úložiště objektů blob dochází k selhání importu souboru COCO?
Microsoft v současné době řeší problém, který způsobuje selhání importu souboru COCO s velkými datovými sadami při zahájení v nástroji Vision Studio. Pokud chcete trénovat pomocí velké datové sady, doporučujeme místo toho použít rozhraní REST API.
Proč trénování trvá déle nebo kratší než můj zadaný rozpočet?
Zadaný rozpočet trénování je kalibrovaný výpočetní čas, nikoli hodinový čas. Tady jsou některé běžné důvody rozdílu:
Delší než zadaný rozpočet:
- Analýza obrázků má vysoký tréninkový provoz a prostředky GPU můžou být těsné. Vaše úloha může čekat ve frontě nebo se během trénování zadržet.
- Proces trénování back-endu narazil na neočekávané chyby, které způsobily opakování logiky. Neúspěšná spuštění nespotřebovávají váš rozpočet, ale obecně to může vést k delšímu trénování.
- Vaše data se ukládají v jiné oblasti než váš prostředek zpracování obrazu, což povede k delší době přenosu dat.
Kratší než zadaný rozpočet: Následující faktory urychlují trénování za cenu použití většího rozpočtu v určitém časovém období.
- Analýza obrázků se někdy trénuje s více grafickými procesory v závislosti na vašich datech.
- Analýza obrázků někdy trénuje několik pokusů o zkoumání na více gpu najednou.
- Analýza obrázků někdy k tréningu používá skladové položky GPU premier (rychlejší).
Proč moje trénování selže a co mám dělat?
Tady jsou některé běžné důvody selhání trénování:
diverged: Trénování nemůže naučit smysluplné věci z vašich dat. Mezi běžné příčiny patří:- Data nestačí: poskytnutí dalších dat by mělo pomoct.
- Data mají nízkou kvalitu: Zkontrolujte, jestli jsou vaše obrázky nízké rozlišení, extrémní poměr stran nebo jestli jsou poznámky nesprávné.
notEnoughBudget: Zadaný rozpočet nestačí pro velikost datové sady a typu modelu, který trénujete. Zadejte větší rozpočet.datasetCorrupt: Obvykle to znamená, že zadané obrázky nejsou přístupné nebo soubor poznámek je ve špatném formátu.datasetNotFound: Datová sada nebyla nalezena.unknown: Může se jednat o problém back-endu. Spojte se s podporou šetření.
Jaké metriky se používají k vyhodnocení modelů?
Používají se následující metriky:
- Klasifikace obrázků: Průměrná přesnost, Přesnost top 1, Přesnost Top 5
- Rozpoznávání objektů: Průměrná přesnost @ 30, Průměrná přesnost @ 50, Průměrná průměrná přesnost @ 75
Proč se registrace datové sady nezdaří?
Odpovědi rozhraní API by měly být dostatečně informativní. Mezi ně patří:
DatasetAlreadyExists: Datová sada se stejným názvem existuje.DatasetInvalidAnnotationUri: "Mezi identifikátory URI poznámek v době registrace datové sady byl poskytnut neplatný identifikátor URI.
Kolik obrázků se vyžaduje pro rozumnou/dobrou/nejlepší kvalitu modelu?
I když modely Florencie mají skvělé možnosti s několika snímky (dosažení skvělého výkonu modelu v omezené dostupnosti dat), obecně více dat zlepší a robustnější trénovaný model. Některé scénáře vyžadují málo dat (jako je klasifikace jablka proti banánu), ale jiné vyžadují více (například detekce 200 druhů hmyzu v deštném deštu). To ztěžuje poskytnutí jediného doporučení.
Pokud je rozpočet popisků dat omezený, doporučujeme tento pracovní postup zopakovat:
Shromážděte
Nobrázky na každou třídu, kdeNmůžete snadno shromažďovat obrázky (napříkladN=3)Vytrénujte model a otestujte ho na testovací sadě.
Pokud je výkon modelu následující:
- Dostatečně dobrý (výkon je lepší než vaše očekávání nebo výkon blízko předchozího experimentu s méně shromážděnými daty): Zastavte se zde a použijte tento model.
- Není dobré (výkon je stále pod vaším očekáváním nebo lepší než předchozí experiment s méně shromážděnými daty na přiměřeném okraji):
- Shromážděte další obrázky pro každou třídu – číslo, které můžete snadno shromáždit – a vraťte se ke kroku 2.
- Pokud si všimnete, že se výkon po několika iteracích už nezlepšuje, může to být proto, že:
- tento problém není dobře definovaný nebo je příliš tvrdý. Spojte se s námi s případnou analýzou.
- trénovací data můžou mít nízkou kvalitu: Zkontrolujte, jestli neexistují nesprávné poznámky nebo obrázky s velmi nízkými pixely.
Kolik rozpočtu školení mám zadat?
Měli byste zadat horní limit rozpočtu, který jste ochotni spotřebovat. Analýza obrázků používá v back-endu systém AutoML k vyzkoušení různých modelů a návodů k trénování, aby našli nejlepší model pro váš případ použití. Čím vyšší je rozpočet, tím vyšší je šance najít lepší model.
Systém AutoML se také zastaví automaticky, pokud dojde k závěru, že není nutné zkoušet více, i když ještě zbývá rozpočet. Proto se vždy nevyčerpá zadaný rozpočet. Je zaručeno, že se vám neúčtuje zadaný rozpočet.
Můžu řídit hyperparametry nebo při trénování používat vlastní modely?
Ne, služba přizpůsobení modelu analýzy obrázků používá trénovací systém AutoML s nízkým kódem, který zpracovává vyhledávání hyper-param a výběr základního modelu v back-endu.
Můžu model po trénování exportovat?
Rozhraní API pro predikce se podporuje pouze prostřednictvím cloudové služby.
Proč vyhodnocení modelu detekce objektů selže?
Níže jsou uvedené možné důvody:
internalServerError: Došlo k neznámé chybě. Zkuste to později.modelNotFound: Zadaný model nebyl nalezen.datasetNotFound: Zadaná datová sada nebyla nalezena.datasetAnnotationsInvalid: Při pokusu o stažení nebo parsování poznámek základní pravdy přidružené k testovací datové sadě došlo k chybě.datasetEmpty: Testovací datová sada neobsahovala žádné poznámky "základní pravdy".
Jaká je očekávaná latence předpovědí s vlastními modely?
Nedoporučujeme používat vlastní modely pro důležitá obchodní prostředí kvůli potenciální vysoké latenci. Když zákazníci trénují vlastní modely v nástroji Vision Studio, patří tyto vlastní modely do prostředku Azure AI Vision, pod kterým byli natrénováni, a zákazník může k těmto modelům volat pomocí rozhraní API pro analýzu obrázků . Při těchto voláních se vlastní model načte do paměti a inicializuje se infrastruktura předpovědi. I když k tomu dojde, zákazníci můžou zaznamenat delší, než očekávanou latenci, aby mohli přijímat výsledky předpovědi.
Ochrana osobních údajů a zabezpečení dat
Stejně jako u všech služeb Azure AI by vývojáři, kteří používají přizpůsobení modelu analýzy obrázků, měli vědět o zásadách Microsoftu na zákaznických datech. Další informace najdete na stránce služeb Azure AI v Centru zabezpečení Microsoftu.
Další kroky
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro