Poznámka
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Automatické škálování služby Azure Monitor vám pomůže mít správné množství spuštěných prostředků pro zvládnutí zatížení vaší aplikace. Umožňuje přidávat prostředky pro zpracování nárůstu zatížení a také ušetřit peníze odebráním prostředků, které jsou nečinné. Můžete škálovat podle plánu, pevného data a času nebo metriky prostředku, kterou zvolíte. Další informace najdete v tématu Přehled automatického škálování.
Služba automatického škálování poskytuje metriky a protokoly, které vám pomůžou pochopit, k jakým akcím škálování došlo, a vyhodnocení podmínek, které tyto akce vedly. Odpovědi na otázky, jako jsou:
- Proč se moje služba škálovala na více instancí nebo se škálováním na více instancí?
- Proč se moje služba škálovala?
- Proč se akce automatického škálování nezdařila?
- Proč akce automatického škálování provádí čas škálování?
Flex škálovací sady virtuálních strojů (Flex Virtual Machine Scale Sets)
Akce automatického škálování se zpozdí až několik hodin po použití akce ručního škálování na prostředek Flex Microsoft.Compute/virtualMachineScaleSets (VMSS) pro konkrétní sadu operací virtuálních počítačů.
Například odstranění rozhraní příkazového řádku virtuálního počítače Azure nebo odstranění rozhraní REST API virtuálního počítače Azure, kde se operace provádí na jednotlivém virtuálním počítači.
V těchto případech služba automatického škálování neví o jednotlivých operacích virtuálních počítačů.
Pokud se chcete tomuto scénáři vyhnout, použijte stejnou operaci, ale na úrovni škálovací sady virtuálních počítačů. Například instance odstranění rozhraní příkazového řádku Azure VMSS nebo instance odstranění rozhraní REST API služby Azure VMSS. Automatické škálování detekuje změnu počtu instancí ve škálovací sadě virtuálních počítačů a provede příslušné akce škálování.
Metriky automatického škálování
Automatické škálování poskytuje čtyři metriky, které vám porozumí její operaci:
- Pozorovaná hodnota metriky: Hodnota metriky, u které jste se rozhodli provést akci škálování, jak je vidět nebo vypočítává modul automatického škálování. Vzhledem k tomu, že jedno nastavení automatického škálování může mít více pravidel a proto více zdrojů metrik, můžete filtrovat pomocí "zdroje metriky" jako dimenze.
- Prahová hodnota metriky: Prahová hodnota, kterou jste nastavili pro provedení akce škálování. Vzhledem k tomu, že jedno nastavení automatického škálování může mít více pravidel a proto více zdrojů metrik, můžete filtrovat pomocí "pravidla metriky" jako dimenze.
- Pozorovaná kapacita: Aktivní počet instancí cílového prostředku, jak je vidět modul automatického škálování.
- Zahájené akce škálování: Počet akcí horizontálního navýšení kapacity a horizontálního navýšení kapacity iniciovaných modulem automatického škálování Můžete filtrovat podle horizontálního navýšení kapacity a akcí horizontálního snížení kapacity.
Pomocí Průzkumníka metrik můžete zobrazit předchozí metriky na jednom místě. Graf by měl zobrazit:
- Skutečná metrika
- Metrika, jak je vidět nebo vypočítává modul automatického škálování.
- Prahová hodnota akce škálování
- Změna kapacity
Příklad 1: Analýza pravidla automatického škálování
Nastavení automatického škálování pro škálovací sadu virtuálních počítačů:
- Škáluje kapacitu, když je průměrné procento procesoru sady větší než 70 % po dobu 10 minut.
- Škáluje se, když je procento procesoru sady menší než 5 % po dobu více než 10 minut.
Pojďme se podívat na metriky ze služby automatického škálování.
Následující graf ukazuje metriku procentuálního využití procesoru pro škálovací sadu virtuálních počítačů.

Následující graf zobrazuje metriku pozorované hodnoty metriky pro nastavení automatického škálování.

Konečný graf zobrazuje metriky prahové hodnoty metriky a metriky pozorované kapacity . Metrika prahové hodnoty metriky v horní části pravidla horizontálního navýšení kapacity je 70. Metrika Pozorovaná kapacita v dolní části zobrazuje počet aktivních instancí, které jsou aktuálně 3.

Poznámka:
Prahovou hodnotu metriky můžete filtrovat podle pravidla horizontálního navýšení kapacity (zvýšení) a zobrazit prahovou hodnotu horizontálního navýšení kapacity a pravidlo horizontálního navýšení kapacity (snížení).
Příklad 2: Pokročilé automatické škálování pro škálovací sadu virtuálních počítačů
Nastavení automatického škálování umožňuje škálovací sadě virtuálních počítačů horizontálně na více instancí na základě vlastní metriky odchozích toků . Je vybrána možnost Dělit metriku podle počtu instancí pro prahovou hodnotu metriky.
Pravidlo akce škálování je v případě, že hodnota Odchozí tok na instanci je větší než 10, měla by služba automatického škálování horizontálně navětšovat kapacitu o 1 instanci.
V tomto případě se pozorovaná hodnota metriky modulu automatického škálování vypočítá jako skutečná hodnota metriky dělená počtem instancí. Pokud je pozorovaná hodnota metriky menší než prahová hodnota, není zahájena žádná akce horizontálního navýšení kapacity.
Následující snímky obrazovky ukazují dva grafy metrik.
Graf Průměrné odchozí toky zobrazuje hodnotu metriky Odchozí toky . Skutečná hodnota je 6.

Následující graf ukazuje několik hodnot:
- Metrika pozorované hodnoty metriky uprostřed je 3, protože existují 2 aktivní instance a 6 děleno 2 je 3.
- Metrika Pozorovaná kapacita v dolní části zobrazuje počet instancí zobrazený modulem automatického škálování.
- Metrika prahové hodnoty metriky v horní části je nastavená na 10.
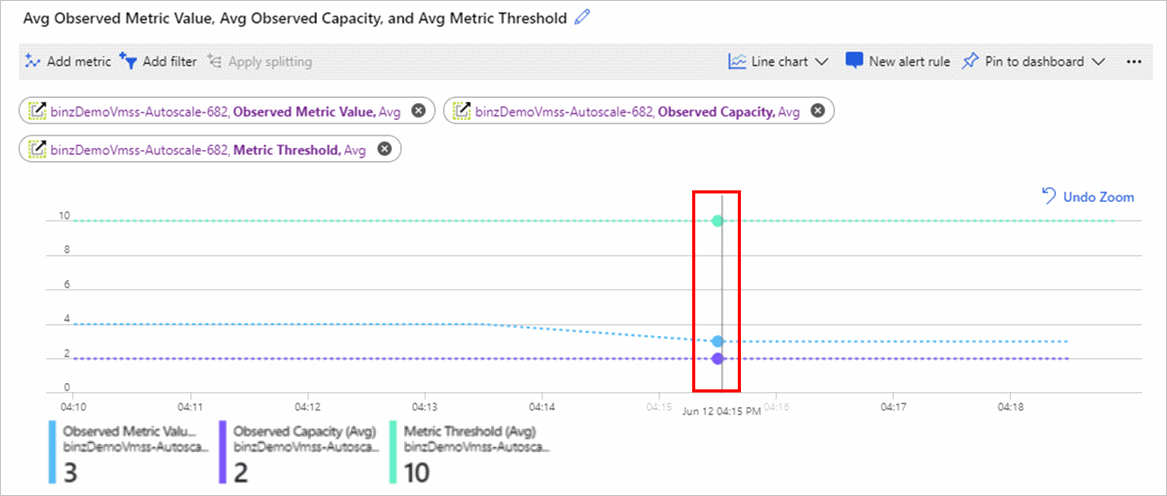

Pokud existuje více pravidel akcí škálování, můžete použít rozdělení nebo možnost přidání filtru v grafu Průzkumníka metrik a podívat se na metriku podle konkrétního zdroje nebo pravidla. Další informace o rozdělení grafu metrik najdete v tématu Pokročilé funkce grafů metrik – rozdělení.
Příklad 3: Vysvětlení událostí automatického škálování
Na obrazovce nastavení automatického škálování přejděte na kartu Historie spuštění a zobrazte nejnovější akce škálování. Na kartě se také zobrazuje změna pozorované kapacity v průběhu času. Další informace o všech akcích automatického škálování, včetně operací, jako jsou aktualizace nebo odstranění nastavení automatického škálování, najdete v protokolu aktivit a filtrování podle operací automatického škálování.

Automatické škálování protokolů prostředků
Služba automatického škálování poskytuje protokoly prostředků. Existují dvě kategorie protokolů:
- Vyhodnocení automatického škálování: Modul automatického škálování zaznamenává položky protokolu pro každé vyhodnocení každé podmínky pokaždé, když provede kontrolu. Položka obsahuje podrobnosti o pozorovaných hodnotách metrik, vyhodnocených pravidlech a o tom, jestli vyhodnocení vedlo k akci škálování nebo ne.
- Akce automatického škálování: Modul zaznamenává události akce škálování iniciované službou automatického škálování a výsledky těchto akcí škálování (úspěch, selhání a počet výskytů škálování, jak je vidět ve službě automatického škálování).
Stejně jako u jakékoli podporované služby Azure Monitor můžete pomocí nastavení diagnostiky směrovat tyto protokoly na:
- Váš pracovní prostor služby Log Analytics pro podrobnou analýzu
- Azure Event Hubs a pak do nástrojů mimo Azure.
- Váš účet Azure Storage pro archivaci

Předchozí snímek obrazovky ukazuje podokno nastavení diagnostiky automatického škálování na webu Azure Portal. Tam můžete vybrat kartu Protokoly diagnostiky nebo prostředků a povolit shromažďování a směrování protokolů. Stejnou akci můžete provést také pomocí rozhraní REST API, Azure CLI, PowerShellu a šablon Azure Resource Manageru pro nastavení diagnostiky tak, že zvolíte typ prostředku jako Microsoft.Insights/AutoscaleSettings.
Řešení potíží s využitím protokolů automatického škálování
Pokud chcete co nejlépe řešit potíže, doporučujeme při vytváření nastavení automatického škálování směrovat protokoly do protokolů služby Azure Monitor (Log Analytics) do pracovního prostoru. Tento proces se zobrazí na snímku obrazovky v předchozí části. Vyhodnocení a akce škálování můžete ověřit lépe pomocí Log Analytics.
Jakmile nakonfigurujete odesílání protokolů automatického škálování do pracovního prostoru služby Log Analytics, můžete zkontrolovat protokoly spuštěním následujících dotazů.
Pokud chcete začít, zkuste tento dotaz zobrazit nejnovější protokoly vyhodnocení automatického škálování:
AutoscaleEvaluationsLog
| limit 50
Nebo zkuste následující dotaz zobrazit nejnovější protokoly akcí škálování:
AutoscaleScaleActionsLog
| limit 50
Odpovědi na tyto otázky najdete v následujících částech.
Došlo k akci škálování, kterou jste nečekali
Nejprve spusťte dotaz na akci škálování a najděte akci škálování, kterou vás zajímá. Pokud se jedná o nejnovější akci škálování, použijte následující dotaz:
AutoscaleScaleActionsLog
| take 1
CorrelationId Vyberte pole z protokolu akcí škálování. Slouží CorrelationId k vyhledání správného protokolu vyhodnocení. Spuštěním následujícího dotazu se zobrazí všechna pravidla a podmínky, které byly vyhodnoceny a které vedly k této akci škálování.
AutoscaleEvaluationsLog
| where CorrelationId = "<correliationId>"
Jaký profil způsobil akci škálování?
Došlo k škálované akci, ale máte překrývající se pravidla a profily a potřebujete zjistit, která akce způsobila.
CorrelationId Najděte akci škálování, jak je vysvětleno v příkladu 1. Pak spusťte dotaz na protokoly vyhodnocení, abyste se dozvěděli více o profilu.
AutoscaleEvaluationsLog
| where CorrelationId = "<correliationId_Guid>"
| where ProfileSelected == true
| project ProfileEvaluationTime, Profile, ProfileSelected, EvaluationResult
Vyhodnocení celého profilu je také možné lépe pochopit pomocí následujícího dotazu:
AutoscaleEvaluationsLog
| where TimeGenerated > ago(2h)
| where OperationName contains == "profileEvaluation"
| project OperationName, Profile, ProfileEvaluationTime, ProfileSelected, EvaluationResult
Nedošlo k akci škálování.
Očekávali jste akci škálování a nedošlo k ní. Nemusí existovat žádné události nebo protokoly akcí škálování.
Pokud používáte pravidlo škálování na základě metrik, projděte si metriky automatického škálování. Je možné, že hodnota pozorované metriky nebo pozorovaná kapacita nejsou to, co jste očekávali, takže se pravidlo škálování neaktivovalo. Stále byste viděli vyhodnocení, ale ne pravidlo horizontálního navýšení kapacity. Je také možné, že doba studeného výpadku udržovala akci škálování před výskytem.
Zkontrolujte protokoly vyhodnocení automatického škálování během časového období, kdy jste očekávali, že dojde k akci škálování. Projděte si všechna vyhodnocení, která udělala, a proč se rozhodla neaktivovat akci škálování.
AutoscaleEvaluationsLog
| where TimeGenerated > ago(2h)
| where OperationName == "MetricEvaluation" or OperationName == "ScaleRuleEvaluation"
| project OperationName, MetricData, ObservedValue, Threshold, EstimateScaleResult
Akce škálování selhala.
Může se jednat o případ, kdy služba automatického škálování provedla akci škálování, ale systém se rozhodl, že se škáluje nebo se nepodařilo dokončit akci škálování. Pomocí tohoto dotazu vyhledejte neúspěšné akce škálování:
AutoscaleScaleActionsLog
| where ResultType == "Failed"
| project ResultDescription
Vytvořte pravidla upozornění, která budou dostávat oznámení o akcích nebo selháních automatického škálování. Můžete také vytvořit pravidla upozornění, která budou dostávat oznámení o událostech automatického škálování.
Schéma protokolů prostředků automatického škálování
Další informace najdete v tématu Protokoly prostředků automatického škálování.
Další kroky
Přečtěte si informace o osvědčených postupech automatického škálování.