Monitorování toků dat
PLATÍ PRO:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Po dokončení sestavování a ladění toku dat chcete naplánovat spuštění toku dat podle plánu v kontextu kanálu. Kanál můžete naplánovat pomocí triggerů. K testování a ladění toku dat z kanálu můžete použít tlačítko Ladit na pásu karet nebo možnost Aktivovat z Tvůrce kanálů a spustit spuštění jednoho spuštění a otestovat tok dat v kontextu kanálu.
Při spuštění kanálu můžete monitorovat kanál a všechny aktivity obsažené v kanálu, včetně aktivity Tok dat. Na levém panelu uživatelského rozhraní vyberte ikonu monitoru. Zobrazí se obrazovka podobná té, která následuje. Zvýrazněné ikony umožňují přejít k podrobnostem o aktivitách v kanálu, včetně aktivity Tok dat.
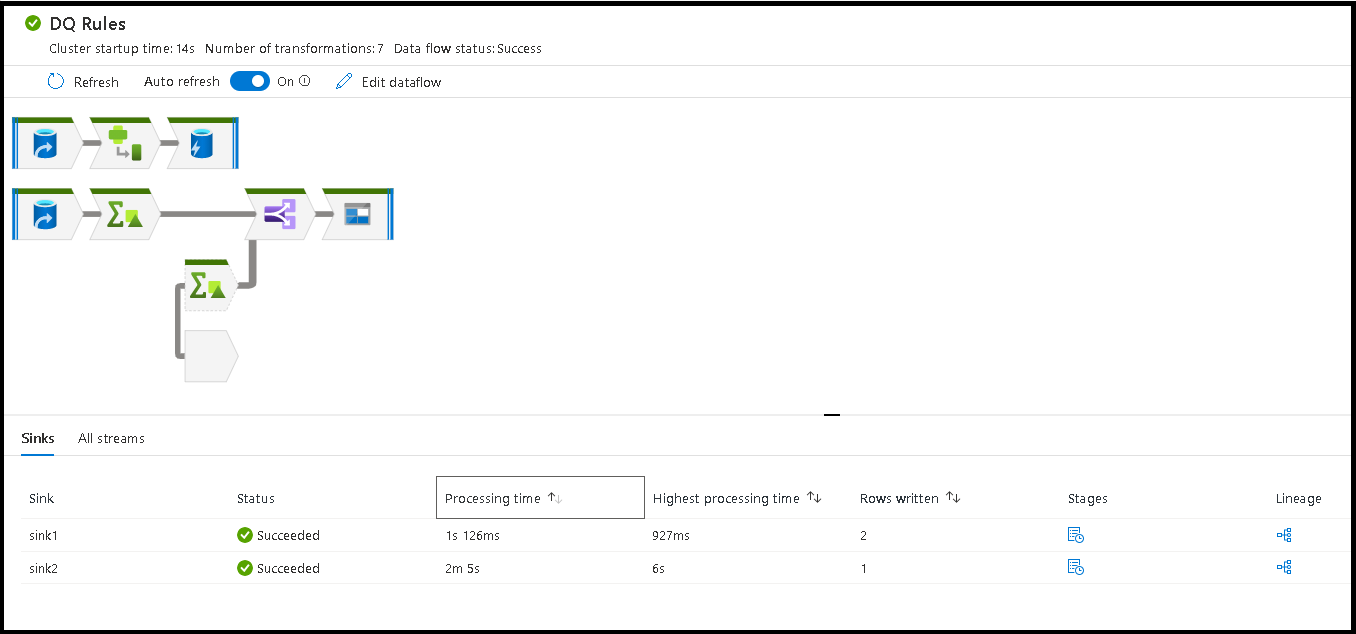
Na této úrovni se zobrazují i statistiky, včetně doby spuštění a stavu. ID spuštění na úrovni aktivity se liší od ID spuštění na úrovni kanálu. ID spuštění na předchozí úrovni je pro kanál. Výběrem brýlí získáte podrobné podrobnosti o provádění toku dat.

Když jste v grafickém zobrazení monitorování uzlů, uvidíte zjednodušenou verzi grafu toku dat, která je jen pro zobrazení. Pokud chcete zobrazit zobrazení podrobností s většími uzly grafu, které obsahují popisky fází transformace, použijte posuvník lupy na pravé straně plátna. K vyhledání částí logiky toku dat v grafu můžete použít také tlačítko hledat na pravé straně.
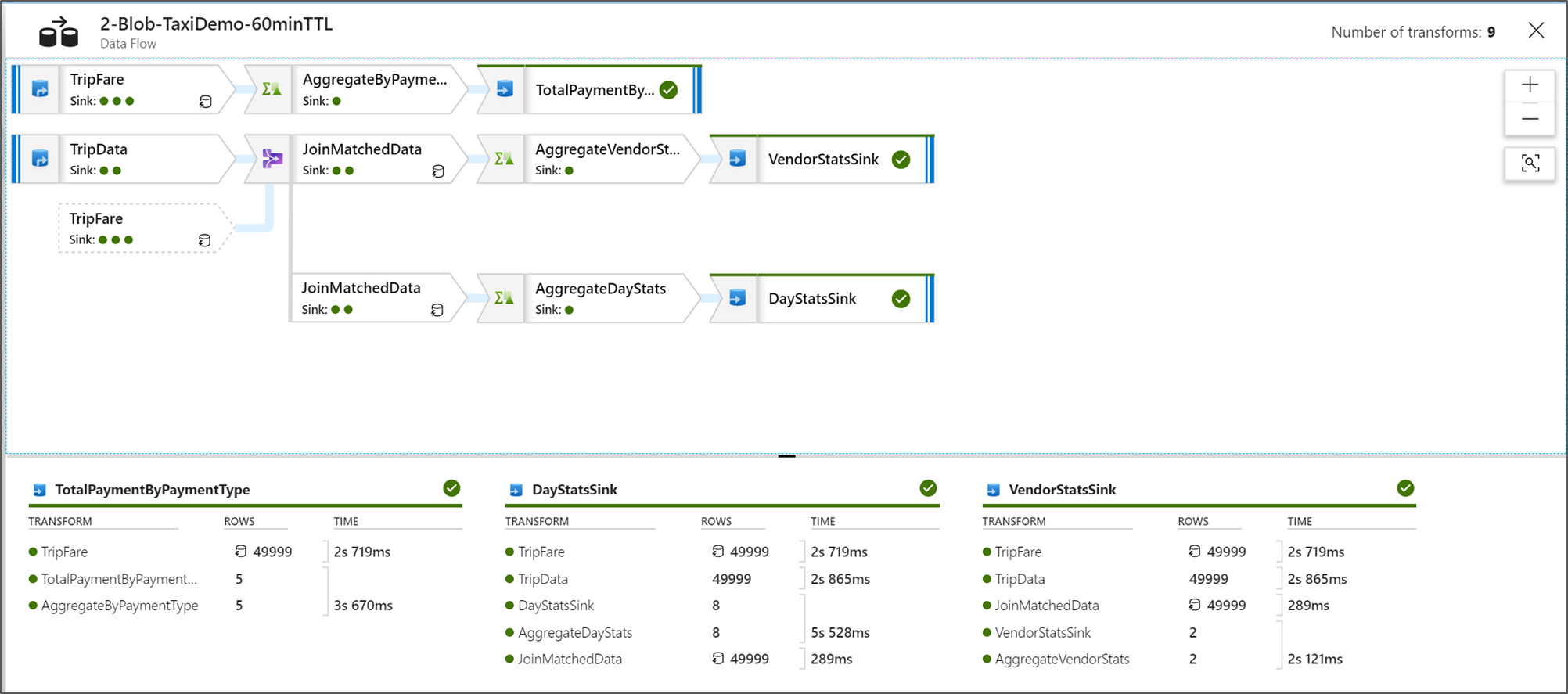
Zobrazení plánů spuštění Tok dat
Když se Tok dat spustí ve Sparku, služba určí optimální cesty kódu na základě celého toku dat. Kromě toho může dojít k cestám provádění na různých uzlech a datových oddílech se škálováním na více instancí. Graf monitorování proto představuje návrh toku s ohledem na cestu provádění transformací. Když vyberete jednotlivé uzly, uvidíte "fáze", které představují kód, který se spustil společně v clusteru. Časování a počty, které vidíte, představují tyto skupiny nebo fáze namísto jednotlivých kroků v návrhu.
Když vyberete otevřené místo v okně monitorování, statistiky v dolním podokně zobrazí časování a počet řádků pro každou jímku a transformace, které vedly k datům jímky pro rodokmen transformace.
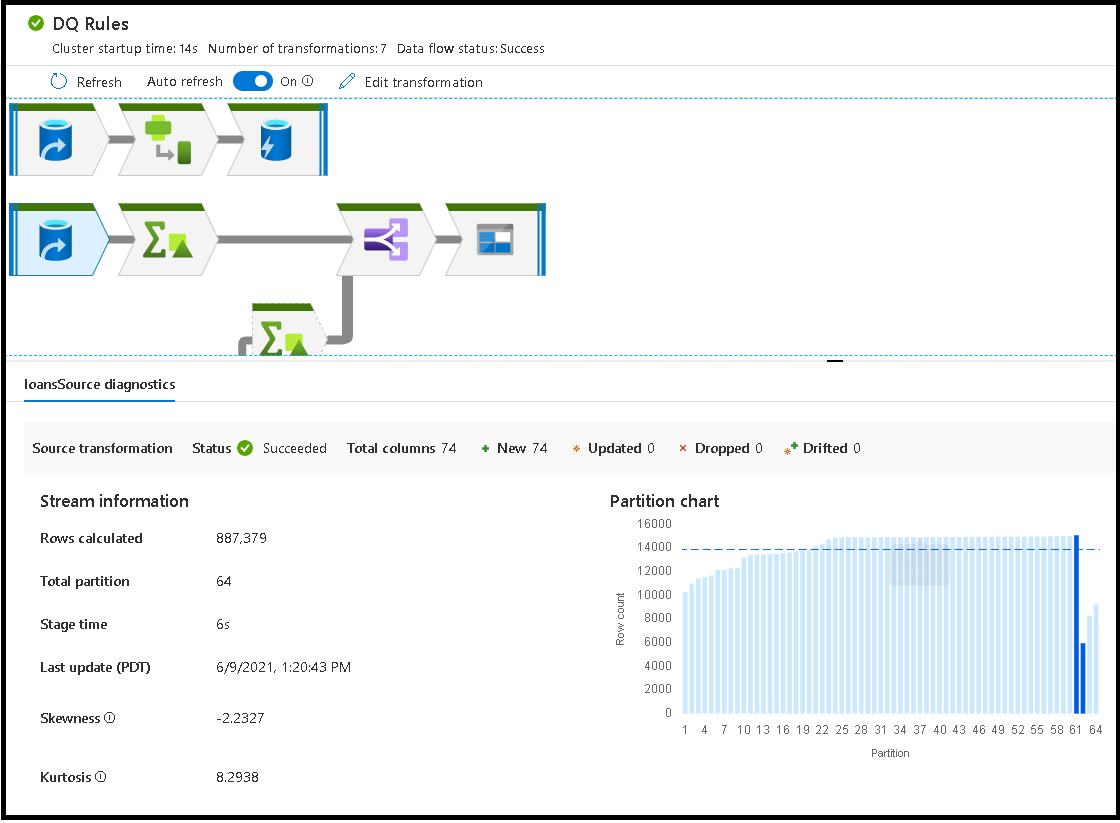
Když vyberete jednotlivé transformace, dostanete na pravém panelu další zpětnou vazbu, která zobrazuje statistiky oddílů, počty sloupců, nerovnoměrnou distribuci dat (jak rovnoměrně se distribuují data napříč oddíly) a kurtóza (jak spiky jsou data).
Řazení podle doby zpracování vám pomůže zjistit, které fáze toku dat trvaly nejvíce času.
Pokud chcete zjistit, které transformace v jednotlivých fázích trvaly nejvíce času, seřaďte je podle nejvyšší doby zpracování.
Zapsané *řádky jsou také seřazené jako způsob, jak identifikovat, které datové proudy uvnitř toku dat zapisují nejvíce dat.
Když v zobrazení uzlu vyberete jímku, zobrazí se rodokmen sloupců. Existují tři různé metody, které se ve vašem toku dat nashromáždí, aby se sloupce nashromažďovaly do jímky. Mezi ně patří:
- Vypočítané: Použijete sloupec pro podmíněné zpracování nebo ve výrazu ve vašem toku dat, ale nepřistane ho do jímky.
- Odvozeno: Sloupec je nový sloupec, který jste vygenerovali ve svém toku, to znamená, že nebyl ve zdroji.
- Namapováno: Sloupec pochází ze zdroje a mapujete ho na pole jímky.
- Stav toku dat: Aktuální stav spuštění
- Doba spuštění clusteru: Doba získání výpočetního prostředí JIT Spark pro provádění toku dat
- Počet transformací: Kolik kroků transformace se provádí ve vašem toku

Celková doba zpracování jímky vs. doba zpracování transformace
Každá fáze transformace zahrnuje celkovou dobu dokončení této fáze s časem spuštění každého oddílu dohromady. Když vyberete jímku, zobrazí se "Doba zpracování jímky". Tento čas zahrnuje celkový čas transformace a čas V/V, který trvalo zápis dat do cílového úložiště. Rozdíl mezi časem zpracování jímky a celkovým součtem transformace je doba vstupně-výstupních operací pro zápis dat.
Pokud otevřete výstup JSON z aktivity toku dat v zobrazení monitorování kanálu, můžete si také prohlédnout podrobné časování jednotlivých kroků transformace oddílů. Json obsahuje časování milisekund pro každý oddíl, zatímco zobrazení monitorování uživatelského rozhraní představuje agregované časování oddílů přidaných dohromady:
{
"stage": 4,
"partitionTimes": [
14353,
14914,
14246,
14912,
...
]
}
Doba zpracování jímky
Když v mapě vyberete ikonu transformace jímky, na pravé straně se na panelu snímků zobrazí další datový bod s názvem "doba zpracování po zpracování" v dolní části. Jedná se o dobu strávenou spuštěním úlohy v clusteru Spark po načtení, transformaci a zápisu dat. Tento čas může zahrnovat zavření fondů připojení, vypnutí ovladače, odstranění souborů, spojování souborů atd. Když ve svém toku provedete akce, jako je přesunutí souborů a výstup do jednoho souboru, pravděpodobně se zvýší hodnota doby zpracování po zpracování.
- Doba trvání fáze zápisu: Doba zápisu dat do přípravného umístění pro Synapse SQL
- Doba trvání operace tabulky SQL: Doba strávená přesunem dat z dočasných tabulek do cílové tabulky
- Doba trvání před SQL a post SQL: Doba strávená před nebo po spuštění příkazů SQL
- Doba trvání příkazů před příkazy a doba trvání příkazů: Doba strávená spuštěním jakýchkoli operací před a po spuštění pro zdroj nebo jímky založené na souborech. Například po zpracování soubory přesuňte nebo odstraňte.
- Doba trvání sloučení: Doba strávená sloučením souboru, slučovací soubory se používají pro jímky založené na souborech při zápisu do jednoho souboru nebo při použití názvu souboru jako dat sloupců. Pokud v této metrice strávíte významný čas, měli byste se těmto možnostem vyhnout.
- Doba fáze: Celková doba strávená uvnitř Sparku k dokončení operace jako fáze.
- Dočasná pracovní stabilní fáze: Název dočasné tabulky používané toky dat k vytvoření dat v databázi.
Chybové řádky
Povolení zpracování chybových řádků v jímce toku dat se projeví ve výstupu monitorování. Když nastavíte jímku na "ohlásit úspěch při chybě", výstup monitorování zobrazí počet úspěšných a neúspěšných řádků, když vyberete uzel monitorování jímky.
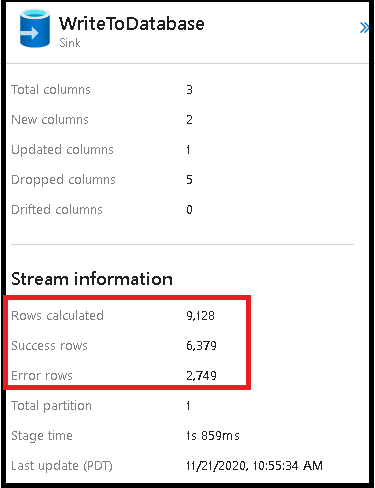
Když vyberete "Ohlásit selhání při chybě", zobrazí se stejný výstup pouze ve výstupním textu monitorování aktivit. Důvodem je to, že aktivita toku dat vrací selhání spuštění a podrobné zobrazení monitorování není k dispozici.
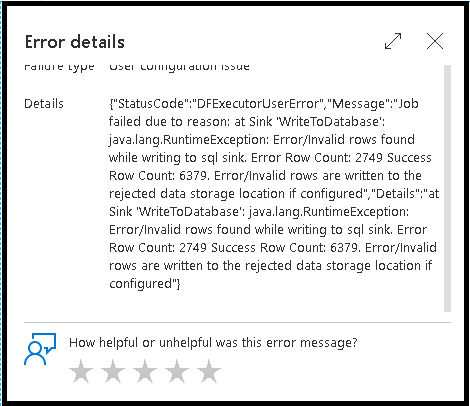
Ikony monitorování
Tato ikona znamená, že transformační data už byla uložená v mezipaměti clusteru, takže časování a cesta provádění se zohlednily takto:
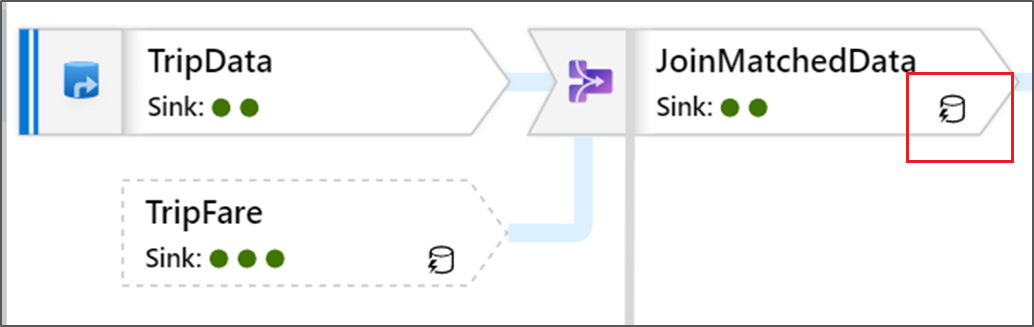
V transformaci se také zobrazují ikony zeleného kruhu. Představují počet jímek, do které data proudí.
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro