Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
VZTAHUJE SE NA: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Data Factory v Microsoft Fabric je nová generace Azure Data Factory s jednodušší architekturou, integrovanou AI a novými funkcemi. Pokud s integrací dat začínáte, začněte Fabric Data Factory. Stávající úlohy ADF lze upgradovat na Fabric pro přístup k novým funkcím v oblastech datové vědy, analýz v reálném čase a vytváření sestav.
Někdy chcete provést rozsáhlou migraci dat z data lake nebo podnikového datového skladu (EDW) na Azure. Jindy chcete ingestovat velké objemy dat z různých zdrojů do Azure pro analýzu velkých objemů dat. V každém případě je důležité dosáhnout optimálního výkonu a škálovatelnosti.
kanály Azure Data Factory a Azure Synapse Analytics poskytují mechanismus příjmu dat s následujícími výhodami:
- Zpracovává velké objemy dat.
- Je vysoce výkonný
- Je nákladově efektivní
Tyto výhody jsou vynikající pro datové inženýry, kteří chtějí vytvářet škálovatelné kanály pro příjem dat, které jsou vysoce výkonné.
Po přečtení tohoto článku budete moct odpovědět na následující otázky:
- Jakou úroveň výkonu a škálovatelnosti můžu dosáhnout pomocí aktivity kopírování pro scénáře migrace dat a příjmu dat?
- Jaké kroky mám provést při ladění výkonu aktivity kopírování?
- Jaké optimalizace výkonu můžu využít pro spuštění jedné aktivity kopírování?
- Jaké další externí faktory je potřeba vzít v úvahu při optimalizaci výkonu kopírování?
Note
Pokud obecně neznáte aktivitu kopírování, podívejte se na přehled aktivity kopírování, než si přečtete tento článek.
Výkon a škálovatelnost dosažitelné pomocí kanálů Azure Data Factory a Synapse
Azure Data Factory a kanály Synapse nabízejí bezserverovou architekturu, která umožňuje paralelismus na různých úrovních.
Tato architektura umožňuje vyvíjet kanály, které maximalizují propustnost přesunu dat pro vaše prostředí. Tyto kanály plně využívají následující prostředky:
- Šířka pásma sítě mezi zdrojovým a cílovým úložištěm dat
- Vstupně-výstupní operace zdrojového nebo cílového úložiště dat za sekundu (IOPS) a šířku pásma
Toto úplné využití znamená, že můžete odhadnout celkovou propustnost měřením minimální dostupné propustnosti s následujícími prostředky:
- Zdrojové úložiště dat
- Cílové úložiště dat
- Šířka pásma sítě mezi zdrojovým a cílovým úložištěm dat
Následující tabulka ukazuje výpočet doby trvání přesunu dat. Doba trvání v každé buňce se vypočítá na základě dané sítě a šířky pásma úložiště dat a dané velikosti datové části.
Note
Níže uvedená doba trvání představuje dosažitelný výkon v komplexním řešení integrace dat pomocí jedné nebo více technik optimalizace výkonu popsaných v funkcích optimalizace výkonu kopírování, včetně použití forEach k rozdělení a vytvoření více souběžných aktivit kopírování. Doporučujeme postupovat podle kroků ladění výkonu, abyste optimalizovali výkon kopírování pro konkrétní datovou sadu a konfiguraci systému. Měli byste použít čísla získaná v testech ladění výkonu pro plánování produkčního nasazení, plánování kapacity a odhad fakturace.
| Velikost dat / šířka pásma |
50 Mb/s | 100 Mb/s | 500 Mb/s | 1 Gbit/s | 5 Gb/s | 10 Gbps | 50 Gb/s |
|---|---|---|---|---|---|---|---|
| 1 GB | 2,7 min | 1,4 min | 0,3 min | 0,1 min | 0,03 min | 0,01 min | 0,0 min |
| 10 GB | 27,3 min | 13,7 min | 2,7 min | 1,3 min | 0,3 min | 0,1 min | 0,03 min |
| 100 GB | 4,6 hod. | 2,3 hod. | 0,5 hod. | 0,2 hod. | 0,05 hod. | 0,02 hod. | 0,0 hod. |
| 1 TB | 46,6 hod. | 23,3 hod. | 4,7 hod. | 2,3 hod. | 0,5 hod. | 0,2 hod. | 0,05 hod. |
| 10 TB | 19,4 dní | 9,7 dní | 1,9 dne | 0,9 dní | 0,2 dny | 0,1 dne | 0,02 dní |
| 100 TB | 194,2 dní | 97,1 dní | 19,4 dní | 9,7 dní | 1,9 dne | 1 den | 0,2 dny |
| 1 PB | 64,7 mo | 32,4 mo | 6,5 mo | 3,2 mo | 0,6 mo | 0,3 mo | 0,06 mo |
| 10 PB | 647,3 mo | 323,6 mo | 64,7 mo | 31,6 mo | 6,5 mo | 3,2 mo | 0,6 mo |
Kopírování je škálovatelné na různých úrovních:
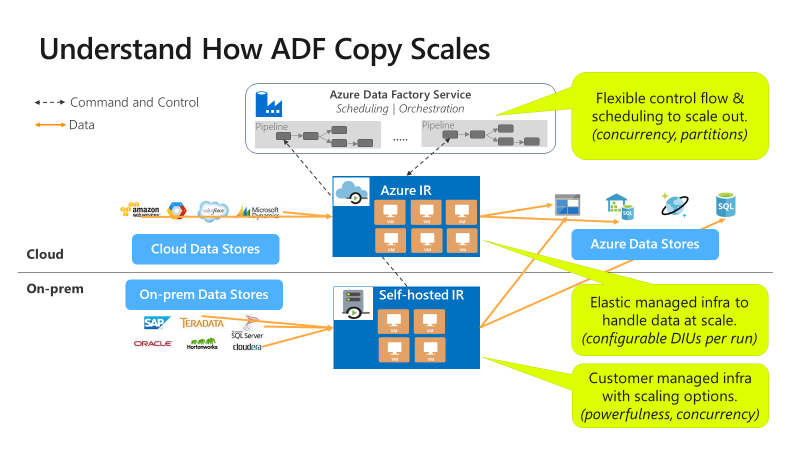
Tok řízení může paralelně spouštět více aktivit kopírování, například pomocí smyčky For Each.
Jedna aktivita kopírování může využívat škálovatelné výpočetní prostředky.
- Při použití prostředí Azure Integration Runtime (IR) můžete zadat až 256 jednotek integrace dat (DIU) pro každou aktivitu kopírování bez serveru.
- Při použití místního prostředí IR můžete použít některý z následujících přístupů:
- Ručně navyšte kapacitu stroje.
- Rozšíření na více počítačů (až 4 uzly) a jeden kopírovací úkon rozdělí jejich sadu souborů mezi všechny uzly.
Jedna aktivita kopírování pomocí více vláken současně čte z úložiště dat a zapisuje do něj.
Kroky ladění výkonu
Provedením následujících kroků vylaďte výkon vaší služby aktivitou kopírování:
Vyberte testovací datovou sadu a vytvořte směrný plán.
Během vývoje otestujte pipeline pomocí kopírovací aktivity na reprezentativním vzorku dat. Zvolená datová sada by měla představovat typické vzory dat s následujícími atributy:
- Struktura složek
- Vzor souboru
- Datové schéma
A vaše datová sada by měla být dostatečně velká k vyhodnocení výkonu kopírování. Aby bylo dokončení kopírovací aktivity možné v přijatelném čase, musí trvat alespoň 10 minut. Shromážděte podrobnosti o spuštění a charakteristiky výkonu po monitorování aktivity kopírování.
Jak maximalizovat výkon jedné aktivity kopírování:
Doporučujeme nejprve maximalizovat výkon pomocí jedné aktivity kopírování.
Pokud se aktivita kopírování spouští na Azure Integration Runtime:
Začněte s výchozími hodnotami pro Jednotky Datové Integrace (DIU) a nastavením paralelního kopírování.
Pokud se aktivita kopírování spouští v místním prostředí Integration Runtime:
K hostování prostředí IR doporučujeme použít vyhrazený počítač. Počítač by měl být oddělený od serveru, který je hostitelem úložiště dat. Začněte s výchozími hodnotami pro nastavení paralelního kopírování a použitím jednoho uzlu pro místní prostředí IR.
Proveďte test výkonnosti. Poznamenejte si dosažené výsledky. Uveďte skutečné použité hodnoty, jako jsou jednotky DIU a paralelní kopie. Informace o tom, jak shromažďovat výsledky spuštění a použitá nastavení výkonu, najdete v monitorování aktivit kopírování. Zjistěte, jak řešit výkonnostní potíže kopírovací aktivity, abyste identifikovali a odstranili kritické body.
Iterujte, abyste provedli více spuštění testů výkonu podle pokynů pro řešení potíží a ladění. Jakmile spuštění jedné aktivity kopírování nedokáže dosáhnout lepší propustnosti, zvažte, jestli chcete maximalizovat agregovanou propustnost spuštěním více kopií současně. Tato možnost je popsána v další číslované odrážce.
Jak maximalizovat agregovanou propustnost spuštěním více kopií současně:
Nyní jste maximalizovali výkon jedné aktivity kopírování. Pokud jste ještě nedosáhli horních limitů propustnosti vašeho prostředí, můžete paralelně spustit více aktivit kopírování. Pomocí řídicích konstrukcí můžete spouštět paralelně. Jedním z takových konstrukcí je For Each smyčka. Další informace najdete v následujících článcích o šablonách řešení:
Rozšiřte konfiguraci pro celou datovou sadu.
Až budete spokojeni s výsledky provádění a výkonem, můžete rozšířit definici a kanál tak, aby pokrývala celou datovou sadu.
Řešení problémů s výkonem kopírovací aktivity
Postupujte podle kroků ladění výkonu a naplánujte a proveďte test výkonu pro váš scénář. Informace o řešení potíží s výkonem jednotlivých spuštění aktivit kopírování najdete v tématu Řešení potíží s výkonem aktivity kopírování.
Kopírování funkcí optimalizace výkonu
Služba poskytuje následující funkce optimalizace výkonu:
- Jednotky integrace dat
- Škálovatelnost místního prostředí Integration Runtime
- Paralelní kopírování
- Fázovaná kopie
Jednotky integrace dat
Jednotka integrace dat (DIU) je míra, která představuje výkon jedné jednotky v kanálech Azure Data Factory a Synapse. Kombinace výkonu zahrnuje přidělení prostředků procesoru, paměti a síťových zdrojů. DIU se vztahuje jenom na Azure Integration Runtime. DIU se nevztahuje na místní prostředí Integration Runtime. Další informace najdete tady.
Škálovatelnost místního prostředí Integration Runtime
Možná budete chtít hostovat rostoucí souběžnou úlohu. Nebo můžete chtít dosáhnout vyššího výkonu na úrovni současné úlohy. Škálování zpracování můžete vylepšit následujícími přístupy:
- Můžete vertikálně navýšit kapacitu místního prostředí IR zvýšením počtu souběžných úloh, které se můžou spouštět na uzlu.
Vertikální navýšení kapacity funguje jenom v případě, že procesor a paměť uzlu nejsou plně využité. - IR lokálně hostovaný můžete škálovat přidáním dalších uzlů (počítačů).
Další informace naleznete v tématu:
- funkce optimalizace výkonu Copy activity: škálovatelnost prostředí Integration Runtime v místním prostředí
- Vytvoření a konfigurace místního prostředí Integration Runtime: Aspekty škálování
Paralelní kopírování
Můžete nastavit parallelCopies tak, aby označil paralelismus, který má být při kopírovací aktivitě použit. Tuto vlastnost si můžete představit jako maximální počet vláken v aktivitě kopírování. Vlákna fungují paralelně. Vlákna buď čtou ze zdroje, nebo zapisují do úložišť dat jímky.
Další informace.
Fázovaná kopie
Operace kopírování dat může odesílat data přímo do úložiště dat jímky. Alternativně můžete použít úložiště objektů blob jako dočasné přípravné úložiště. Další informace.
Související obsah
Podívejte se na další články o aktivitě kopírování:
- Přehled aktivity kopírování
- Řešení problémů s výkonem kopírovací aktivity
- Funkce optimalizace výkonu Copy activity
- Použití Azure Data Factory k migraci dat z datového jezera nebo datového skladu do Azure
- Migrace dat z Amazon S3 do Azure úložiště