Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
VZTAHUJE SE NA: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Data Factory v Microsoft Fabric je nová generace Azure Data Factory s jednodušší architekturou, integrovanou AI a novými funkcemi. Pokud s integrací dat začínáte, začněte Fabric Data Factory. Stávající úlohy ADF lze upgradovat na Fabric pro přístup k novým funkcím v oblastech datové vědy, analýz v reálném čase a vytváření sestav.
Aktivita MapReduce služby HDInsight v Azure Data Factory nebo Synapse Analytics pipeline vyvolá program MapReduce ve vašem vlastním nebo na vyžádání clusteru HDInsight. Tento článek vychází z článku o aktivitách transformace dat, který představuje obecný přehled transformace dat a podporovaných transformačních aktivit.
Další informace najdete v úvodních článcích pro Azure Data Factory a Synapse Analytics a proveďte kurz: Tutorial: transformace dat před přečtením tohoto článku.
Podrobnosti o tom, jak spouštět skripty Pig/Hive na clusteru HDInsight pomocí aktivit Pig a Hive z pipeline, najdete v tématu Pig a Hive.
Přidání aktivity MapReduce HDInsight do kanálu pomocí uživatelského rozhraní
Chcete-li použít aktivitu MapReduce služby HDInsight do kanálu, proveďte následující kroky:
Vyhledejte MapReduce v podokně Aktivity kanálu a přetáhněte aktivitu MapReduce na plátno kanálu.
Vyberte novou aktivitu MapReduce na plátně, pokud ještě není vybraná.
Výběrem karty Cluster HDI vyberte nebo vytvořte novou propojenou službu s clusterem HDInsight, který se použije ke spuštění aktivity MapReduce.
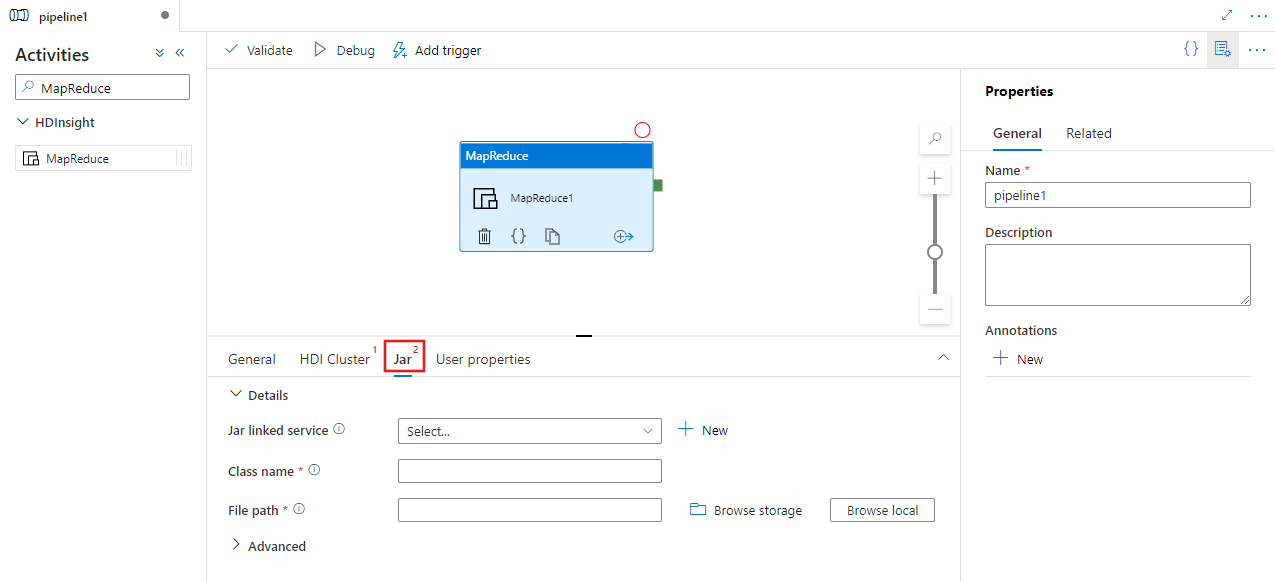
Vyberte kartu Jar a vyberte nebo vytvořte novou propojenou službu Jar s účtem Azure Storage, který bude hostovat váš skript. Zadejte název třídy, který má být spuštěn, a cestu k souboru v rámci úložiště. Můžete také nakonfigurovat pokročilé podrobnosti, včetně umístění knihovny Jar, konfigurace ladění a argumentů a parametrů, které se mají předat skriptu.
Syntaxe
{
"name": "Map Reduce Activity",
"description": "Description",
"type": "HDInsightMapReduce",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"className": "org.myorg.SampleClass",
"jarLinkedService": {
"referenceName": "MyAzureStorageLinkedService",
"type": "LinkedServiceReference"
},
"jarFilePath": "MyAzureStorage/jars/sample.jar",
"getDebugInfo": "Failure",
"arguments": [
"-SampleHadoopJobArgument1"
],
"defines": {
"param1": "param1Value"
}
}
}
Podrobnosti o syntaxi
| Vlastnost | Popis | Povinné |
|---|---|---|
| název | Název aktivity | Ano |
| popis | Text popisující, k čemu se aktivita používá | Ne |
| typ | U aktivity MapReduce je typ aktivity HDinsightMapReduce. | Ano |
| názevPrepojenéSlužby | Odkaz na cluster HDInsight zaregistrovaný jako propojená služba Další informace o této propojené službě najdete v článku o propojených službách Compute. | Ano |
| className | Název třídy, která se má spustit | Ano |
| jarLinkedService | Odkaz na propojenou službu Azure Storage sloužící k ukládání souborů JAR. Tady jsou podporované jenom Azure Blob Storage a ADLS Gen2 propojené služby. Pokud tuto propojenou službu nezadáte, použije se propojená služba Azure Storage definovaná v propojené službě HDInsight. | Ne |
| jarFilePath | Zadejte cestu k souborům Jar uloženým v Azure Storage, na které odkazuje jarLinkedService. V názvu souboru se rozlišují malá a velká písmena. | Ano |
| jarlibs | Řetězcové pole obsahující cesty k souborům knihovny Jar, na které odkazuje úloha uložená v Azure Storage, jak je definováno v jarLinkedService. V názvu souboru se rozlišují malá a velká písmena. | Ne |
| getDebugInfo | Určuje, kdy se soubory protokolu zkopírují do Azure Storage používané clusterem HDInsight (nebo) určeným službou jarLinkedService. Povolené hodnoty: Žádné, Vždy nebo Selhání. Výchozí hodnota: Žádný. | Ne |
| argumenty | Určuje pole argumentů pro úlohu Hadoop. Argumenty se předávají každému úkolu jako argumenty příkazového řádku. | Ne |
| definuje | Zadejte parametry jako páry klíč/hodnota pro odkazování v rámci skriptu Hive. | Ne |
Příklad
Aktivitu MapReduce služby HDInsight můžete použít ke spuštění libovolného souboru JAR MapReduce v clusteru HDInsight. V následující ukázkové definici JSON kanálu je aktivita HDInsight nakonfigurovaná tak, aby spustila soubor Mahout JAR.
{
"name": "MapReduce Activity for Mahout",
"description": "Custom MapReduce to generate Mahout result",
"type": "HDInsightMapReduce",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"className": "org.apache.mahout.cf.taste.hadoop.similarity.item.ItemSimilarityJob",
"jarLinkedService": {
"referenceName": "MyStorageLinkedService",
"type": "LinkedServiceReference"
},
"jarFilePath": "adfsamples/Mahout/jars/mahout-examples-0.9.0.2.2.7.1-34.jar",
"arguments": [
"-s",
"SIMILARITY_LOGLIKELIHOOD",
"--input",
"wasb://adfsamples@spestore.blob.core.windows.net/Mahout/input",
"--output",
"wasb://adfsamples@spestore.blob.core.windows.net/Mahout/output/",
"--maxSimilaritiesPerItem",
"500",
"--tempDir",
"wasb://adfsamples@spestore.blob.core.windows.net/Mahout/temp/mahout"
]
}
}
V oddílu argumentů můžete zadat libovolné argumenty pro program MapReduce. Za běhu uvidíte několik dalších argumentů (například mapreduce.job.tags) z architektury MapReduce. Pokud chcete odlišit argumenty s argumenty MapReduce, zvažte použití možnosti i hodnoty jako argumenty, jak je znázorněno v následujícím příkladu (-s,--input,--output atd., jsou možnosti bezprostředně následované jejich hodnotami).
Související obsah
Podívejte se na následující články, které vysvětlují, jak transformovat data jinými způsoby: