Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
VZTAHUJE SE NA: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Návod
Data Factory v Microsoft Fabric je nová generace Azure Data Factory s jednodušší architekturou, integrovanou AI a novými funkcemi. Pokud s integrací dat začínáte, začněte Fabric Data Factory. Stávající úlohy ADF lze upgradovat na Fabric pro přístup k novým funkcím v oblastech datové vědy, analýz v reálném čase a vytváření sestav.
V tomto kurzu použijete portál Azure k vytvoření datové továrny. Pak použijete nástroj pro kopírování dat k vytvoření kanálu, který přírůstkově kopíruje nové a změněné soubory, pouze z úložiště objektů blob Azure do Azure Blob Storage. Používá LastModifiedDate k určení souborů, které se mají kopírovat.
Po dokončení tohoto postupu Azure Data Factory zkontroluje všechny soubory ve zdrojovém úložišti, použije filtr souborů podle LastModifiedDate a zkopíruje do cílového úložiště jenom soubory, které jsou nové nebo byly od poslední doby aktualizovány. Mějte na paměti, že pokud Data Factory prohledá velký počet souborů, měli byste stále očekávat dlouhé doby trvání. Kontrola souborů je časově náročná, i když se sníží množství zkopírovaných dat.
Poznámka:
Pokud se službou Data Factory začínáte, přečtěte si téma Introduction Azure Data Factory.
V tomto kurzu dokončíte tyto úlohy:
- Vytvoření datové továrny
- Použijte nástroj pro kopírování dat k vytvoření kanálu.
- Monitorujte pipeline a spuštění aktivit.
Požadavky
- Azure předplatné: Pokud ještě nemáte předplatné Azure, vytvořte si účet free než začnete.
- Azure Storage account: Pro zdrojová a cílová datová úložiště použijte úložiště typu Blob. Pokud účet Azure Storage nemáte, postupujte podle pokynů v tématu Vytvoření účtu úložiště.
Vytvořte dva kontejnery v Blob úložišti
Připravte si úložiště objektů blob pro kurz provedením těchto kroků:
Vytvořte kontejner pojmenovaný zdroj. K provedení této úlohy můžete použít různé nástroje, například Azure Storage Explorer.
Vytvořte kontejner s názvem cíl.
Vytvoření datové továrny
V horní nabídce vyberte Vytvořit prostředek>Analýza>Datová továrna:
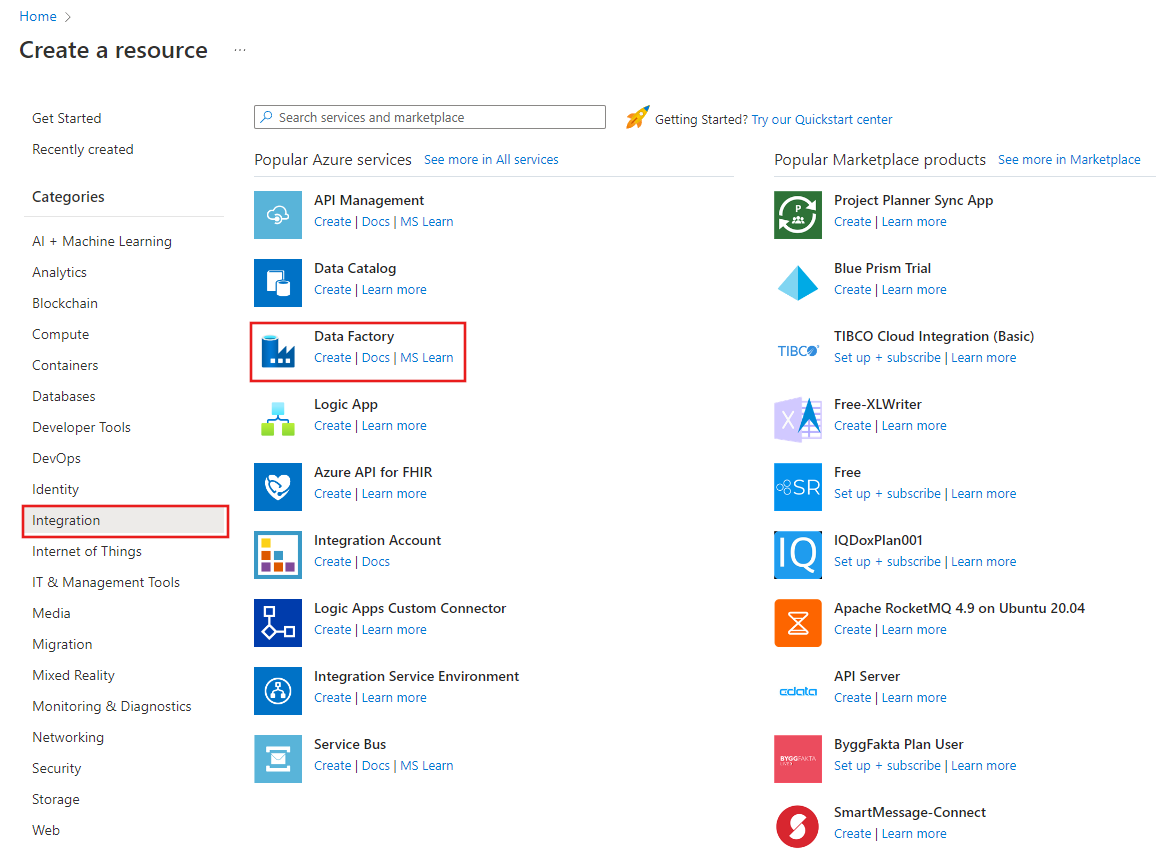
Na stránce Nová datová továrna v části Název zadejte ADFTutorialDataFactory.
Název vaší datové továrny musí být unikátní na celosvětové úrovni. Může se zobrazit tato chybová zpráva:
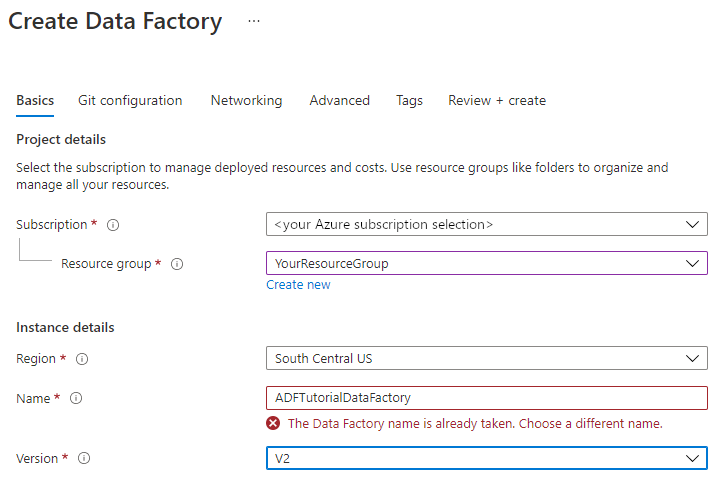
Pokud se zobrazí chybová zpráva týkající se hodnoty názvu, zadejte jiný název datové továrny. Použijte například název vaše_jménoADFTutorialDataFactory. Pravidla pojmenování artefaktů služby Data Factory najdete v tématu Data Factory – pravidla pojmenování.
V části Subscription vyberte Azure předplatné, ve kterém vytvoříte novou datovnu.
Proveďte jeden z těchto kroků v části Skupina prostředků.
Vyberte Použít existující a pak v seznamu vyberte existující skupinu prostředků.
Vyberte Vytvořit nový a zadejte název skupiny prostředků.
Další informace o skupinách prostředků najdete v tématu Užití skupin prostředků ke správě prostředků Azure.
Jako Verzi vyberte V2.
V části Umístění vyberte umístění datové továrny. V seznamu se zobrazí jenom podporovaná umístění. Úložiště dat (například Azure Storage a Azure SQL Database) a výpočty (například Azure HDInsight), které vaše datová továrna používá, můžou být v jiných umístěních a oblastech.
Vyberte Vytvořit.
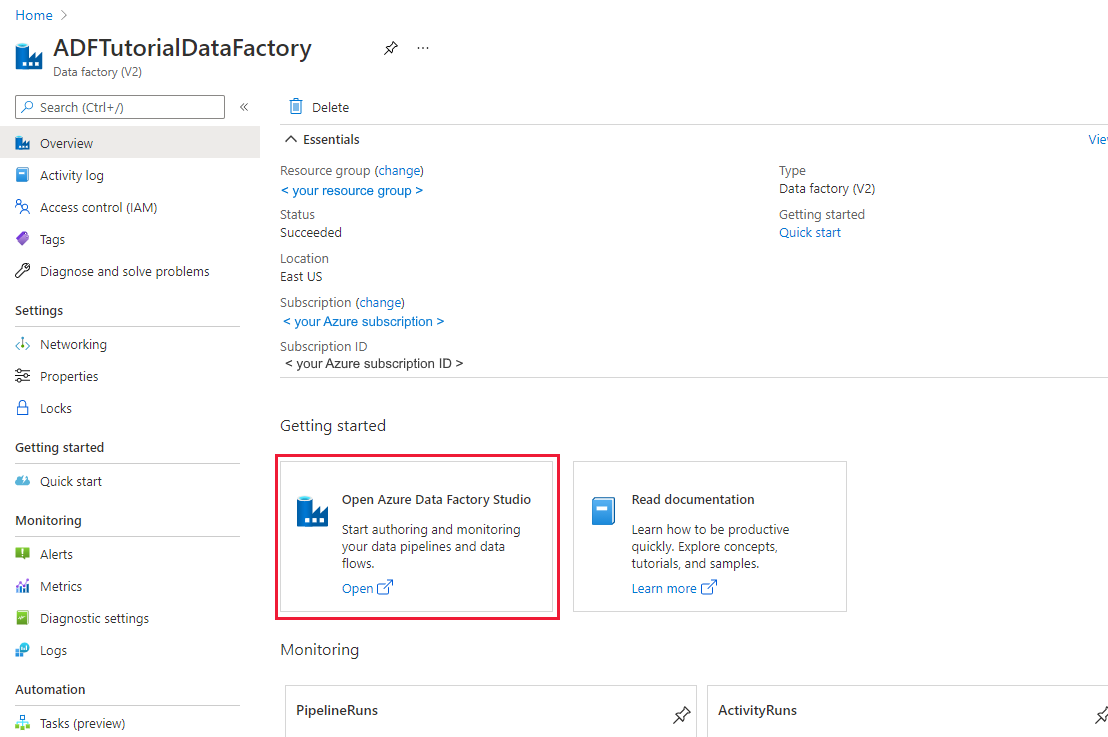
Po vytvoření datové továrny se zobrazí domovská stránka datové továrny.
Pokud chcete otevřít uživatelské rozhraní Azure Data Factory na samostatné kartě, vyberte Open na dlaždici Open Azure Data Factory Studio:
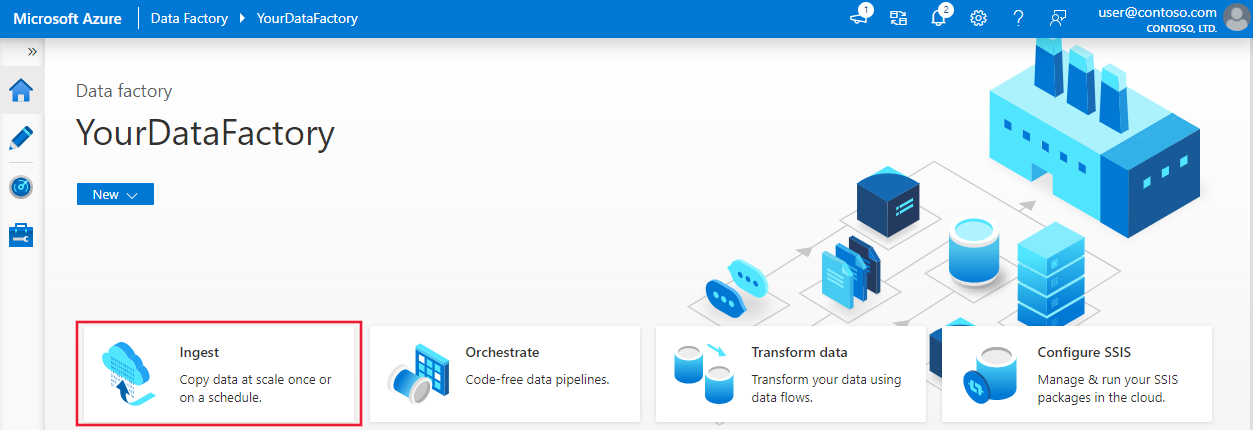
Vytvoření kanálu pomocí nástroje pro kopírování dat
Na domovské stránce Azure Data Factory vyberte dlaždici Ingest a otevřete nástroj Pro kopírování dat:
Na stránce Vlastnosti proveďte následující kroky:
V části Typ úkolu vyberte Předdefinovaný úkol kopírování.
V části Tempo úkolu nebo plán úkolu vyberte Přeskakující okno.
V části Opakování zadejte 15 minut.
Vyberte Další.
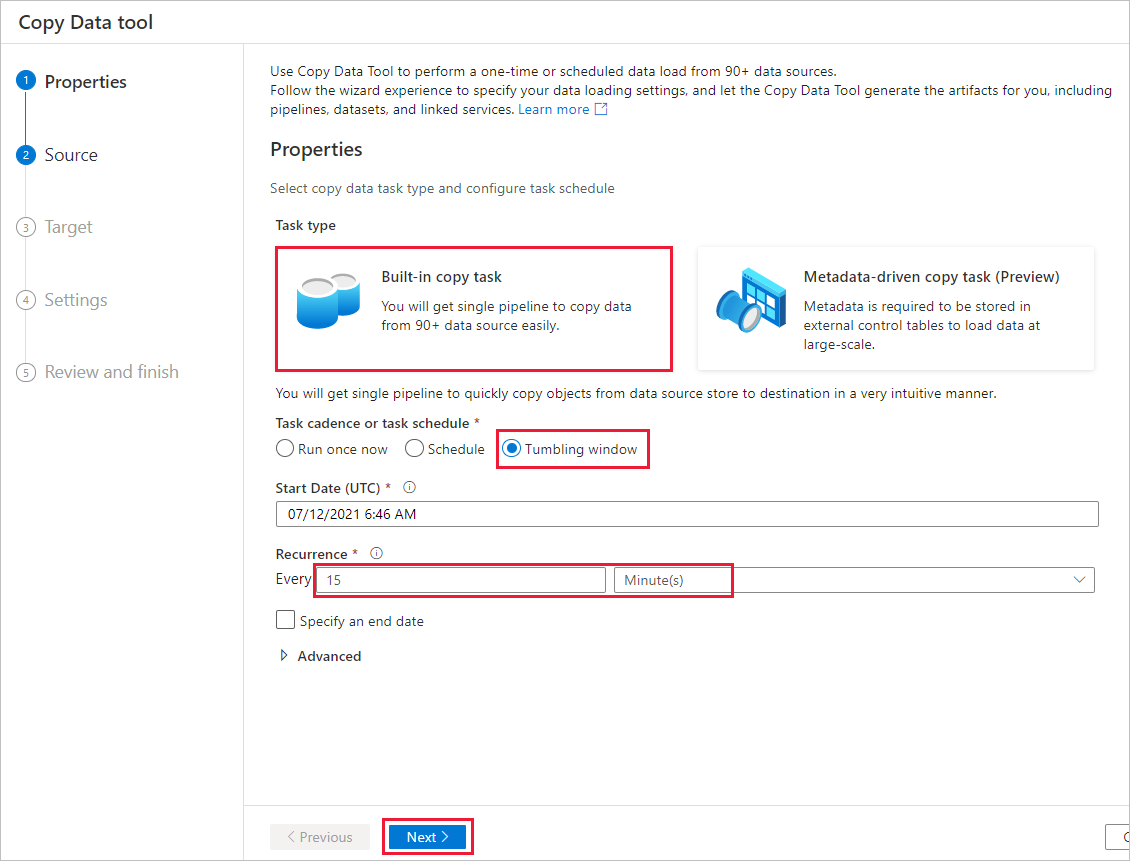
Na stránce Zdrojové úložiště dat proveďte následující kroky:
Pokud chcete přidat připojení, vyberte + Nové připojení .
V galerii vyberte Azure Blob Storage a pak vyberte Continue:

Na stránce Nové připojení (Azure Blob Storage) vyberte své předplatné Azure ze seznamu Azure předplatné a ze seznamu Storage. Otestujte připojení a pak vyberte Vytvořit.
V bloku připojení vyberte nově vytvořené připojení.
V části Soubor nebo složka vyberte Procházet a zvolte zdrojovásložka a pak vyberte OK.
V části Chování načítání souboru vyberte Přírůstkové načtení: LastModifiedDate a zvolte Binární kopie.
Vyberte Další.
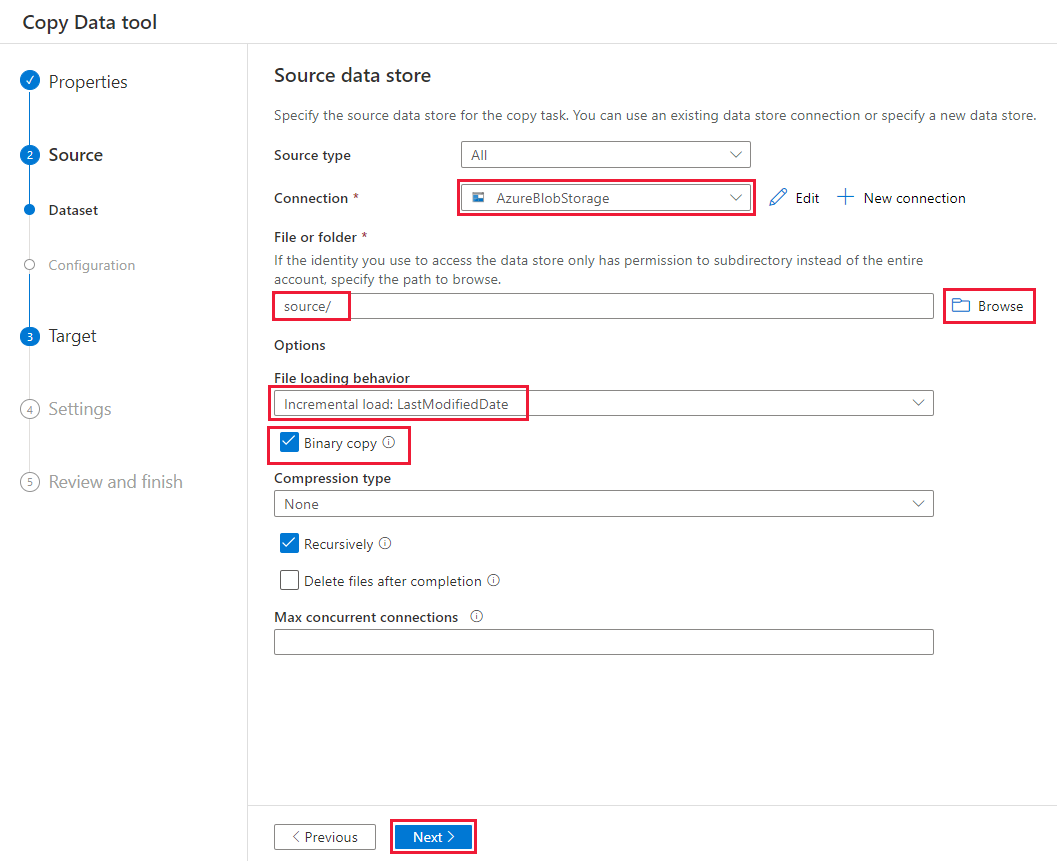
Na stránce Cílové úložiště dat proveďte následující kroky:
Vyberte připojení AzureBlobStorage, které jste vytvořili. Jedná se o stejný účet úložiště jako zdrojové úložiště dat.
V části Cesta ke složce vyhledejte a vyberte cílovou složku a pak vyberte OK.
Vyberte Další.
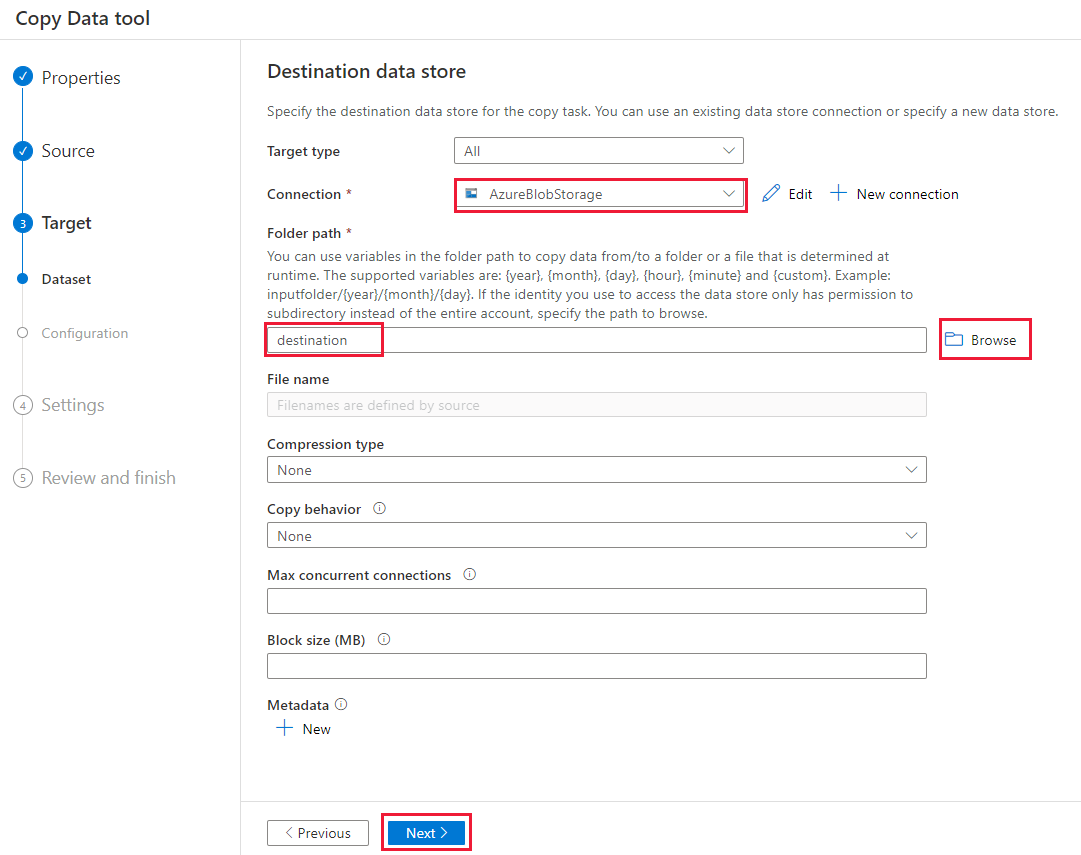
Na stránce Nastavení v části Název úlohy zadejte DeltaCopyFromBlobPipeline a pak vyberte Další. Data Factory vytvoří kanál se zadaným názvem úlohy.
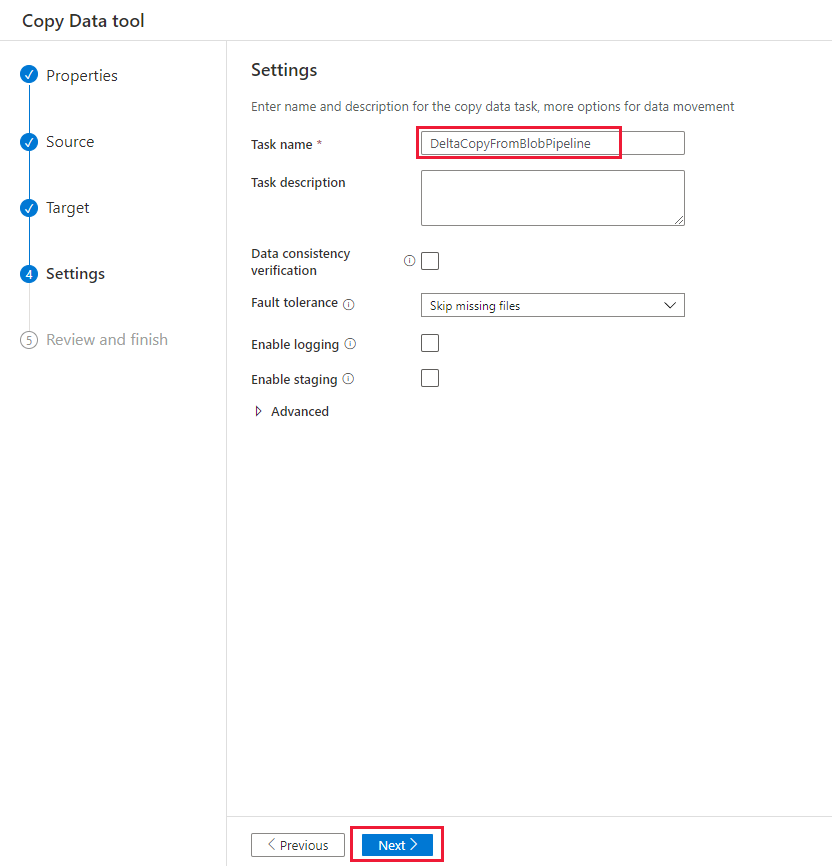
Na stránce Souhrn zkontrolujte nastavení a pak vyberte Další.
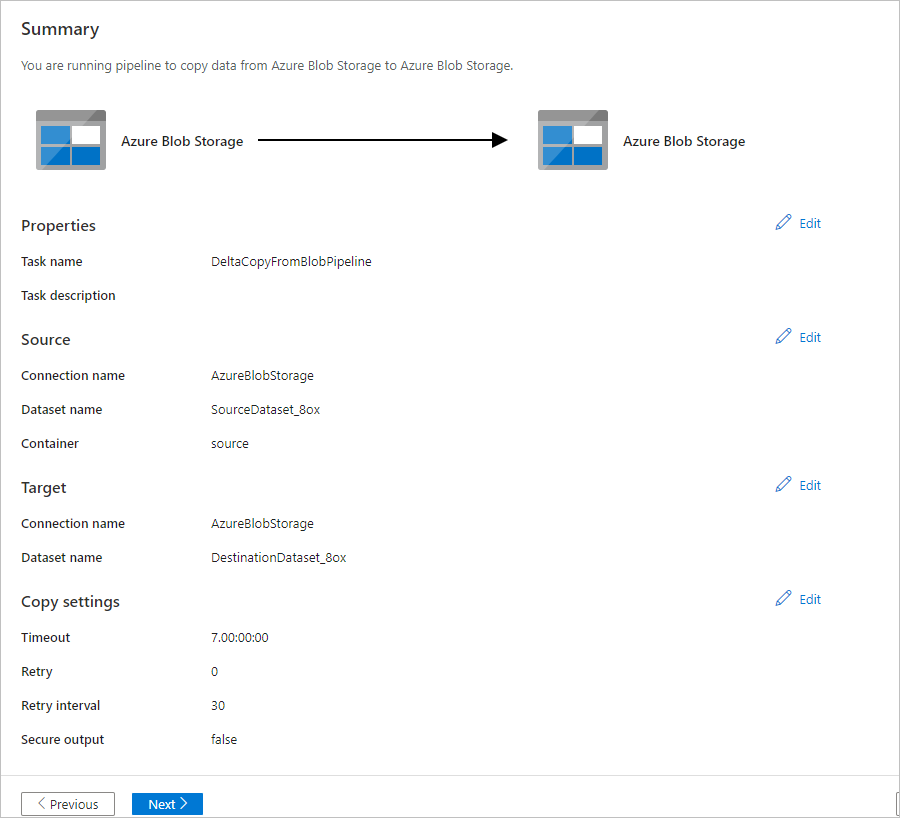
Na stránce Nasazení vyberte Monitorovat a začněte monitorovat kanál (úlohu).
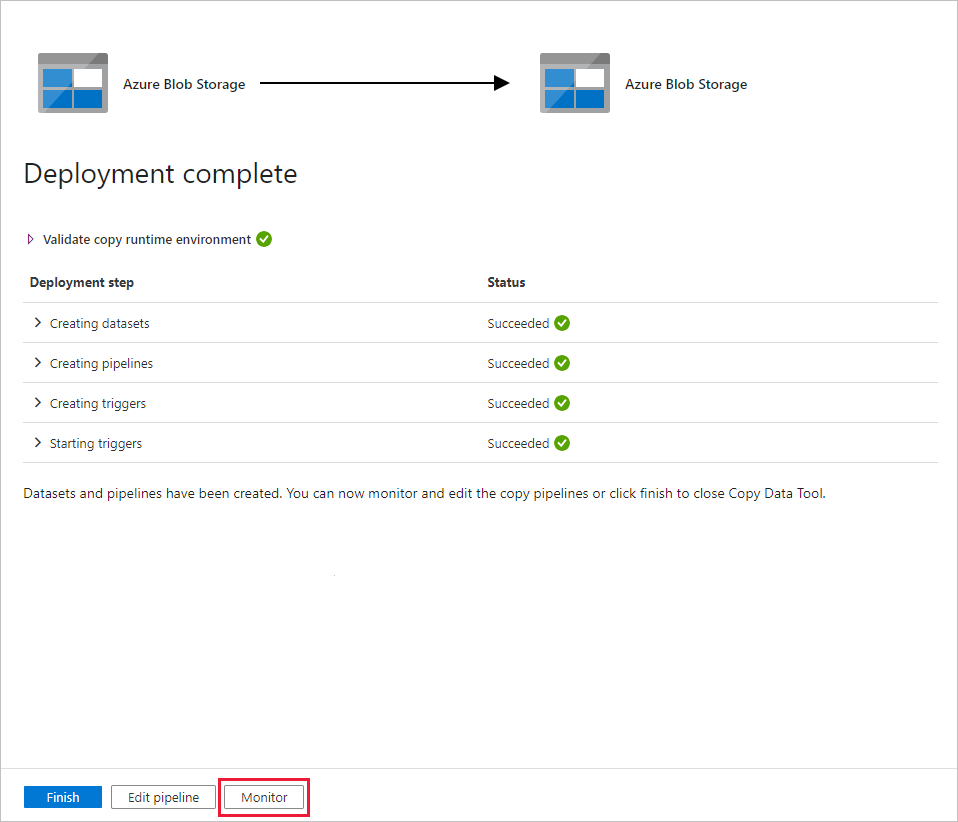
Všimněte si, že je vlevo automaticky vybraná karta Monitorování. Aplikace se přepne na kartu Monitorování . Zobrazí se stav kanálu. Seznam můžete aktualizovat kliknutím na Aktualizovat. Výběrem odkazu v části Název kanálu zobrazte podrobnosti o spuštění aktivity nebo znovu spusťte kanál.
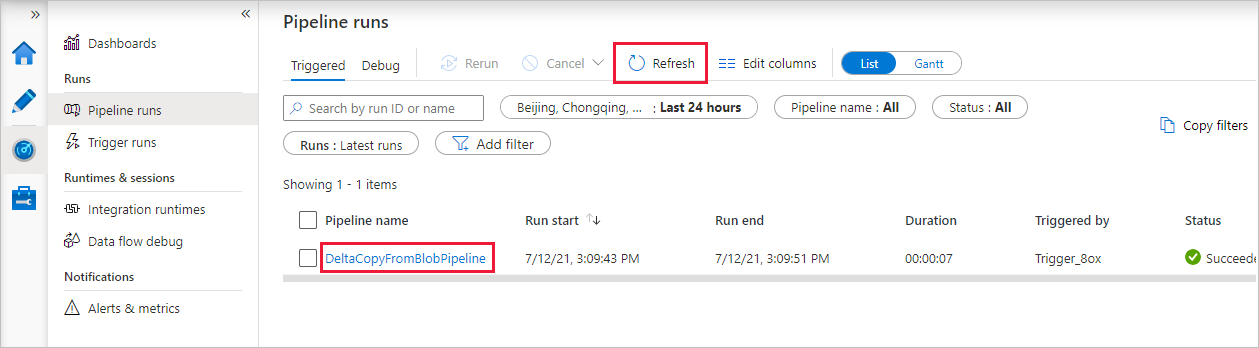
V datovém kanálu je jen jedna aktivita (kopírovací aktivita), takže uvidíte pouze jednu položku. Podrobnosti o operaci kopírování zjistíte na stránce Aktivity, když ve sloupci Název aktivity vyberete odkaz Podrobnosti (ikona s podobou brýlí). Podrobnosti o vlastnostech najdete v tématu Přehled aktivity kopírování.
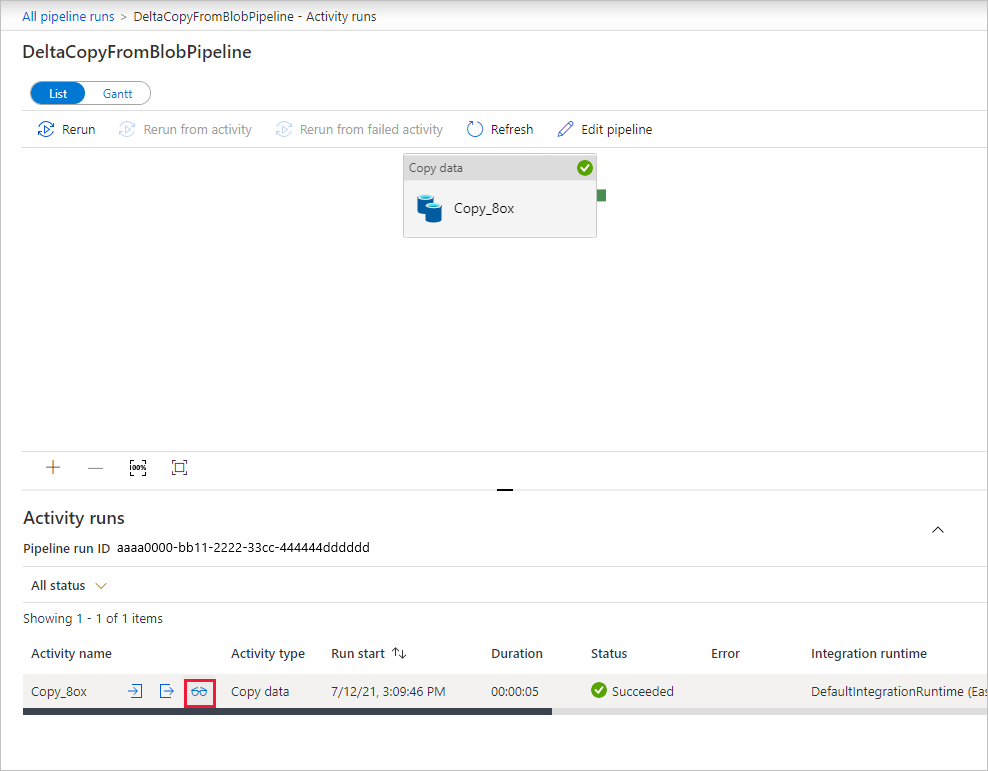
Vzhledem k tomu, že ve zdrojovém kontejneru v účtu úložiště blob nejsou žádné soubory, neuvidíte v účtu žádné soubory zkopírované do cílového kontejneru:
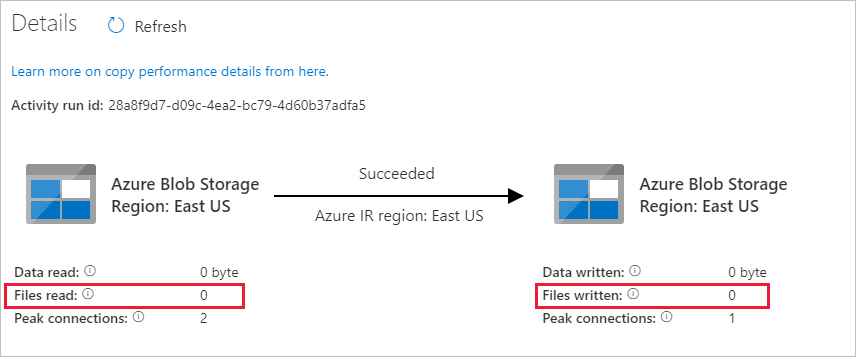
Vytvořte prázdný textový soubor a pojmenujte ho file1.txt. Nahrajte tento textový soubor do kontejneru zdroje ve vašem úložném účtu. K provádění těchto úloh můžete použít různé nástroje, například Azure Storage Explorer.
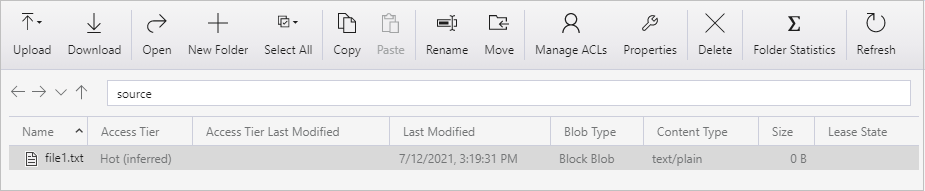
Pokud se chcete vrátit do zobrazení spuštění kanálu, vyberte odkaz Všechny spuštění kanálu v nabídce navigační cesty na stránce Spuštění aktivit a počkejte, až se stejný kanál automaticky aktivuje.
Po dokončení spuštění druhého workflowu postupujte podle stejných kroků zmíněných dříve a zkontrolujte podrobnosti o aktivitě.
Uvidíte, že se jeden soubor (file1.txt) zkopíroval ze zdrojového kontejneru do cílového kontejneru vašeho účtu blob storage:
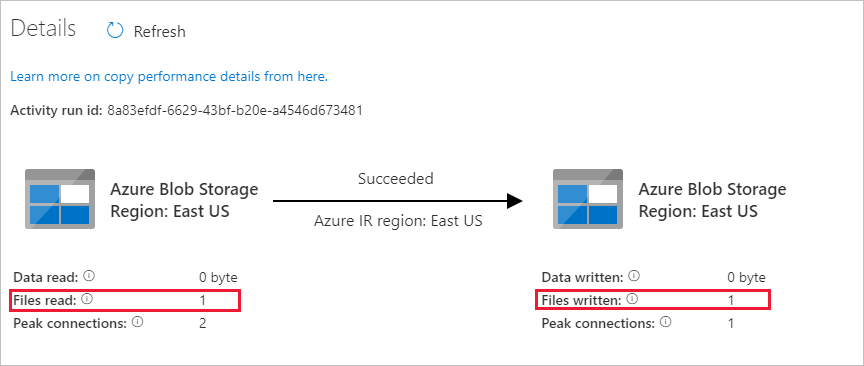
Vytvořte další prázdný textový soubor a pojmenujte ho file2.txt. Nahrajte tento textový soubor do zdrojového kontejneru v účtu úložiště objektů blob.
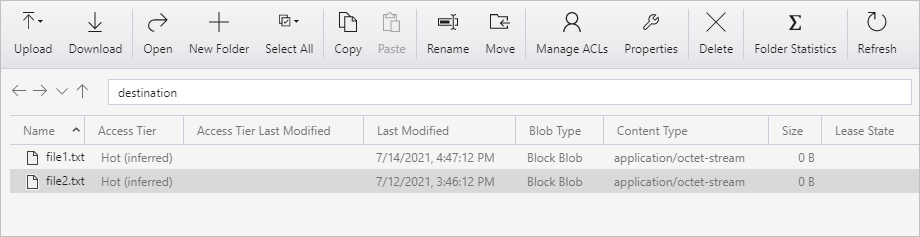
Opakujte kroky 11 a 12 pro druhý textový soubor. Uvidíte, že se během tohoto spuštění kanálu zkopíroval jenom nový soubor (file2.txt) ze zdrojového kontejneru do cílového kontejneru vašeho účtu úložiště.
Pomocí nástroje Azure Storage Explorer můžete také ověřit, že se zkopíroval jenom jeden soubor ke skenování souborů:
Související obsah
V následujícím kurzu se dozvíte, jak transformovat data pomocí clusteru Apache Spark na Azure: