Optimalizace dotazů Apache Hivu v Azure HDInsightu
Tento článek popisuje některé z nejběžnějších optimalizací výkonu, které můžete použít ke zlepšení výkonu dotazů Apache Hive.
Výběr typu clusteru
V Azure HDInsight můžete spouštět dotazy Apache Hive na několika různých typech clusterů.
Zvolte odpovídající typ clusteru, který vám pomůže optimalizovat výkon pro vaše potřeby úloh:
- Zvolte typ clusteru Interactive Query , který chcete optimalizovat pro
ad hocinteraktivní dotazy. - Zvolte typ clusteru Apache Hadoop , abyste optimalizovali dotazy Hive používané jako dávkové zpracování.
- Typy clusterů Spark a HBase můžou také spouštět dotazy Hive a můžou být vhodné, pokud tyto úlohy spouštíte.
Další informace o spouštění dotazů Hive na různé typy clusterů HDInsight najdete v tématu Co je Apache Hive a HiveQL ve službě Azure HDInsight?.
Horizontální navýšení kapacity pracovních uzlů
Zvýšení počtu pracovních uzlů v clusteru HDInsight umožňuje práci používat více mapovačů a reduktorů, které se mají spustit paralelně. Škálování ve službě HDInsight můžete zvýšit dvěma způsoby:
Při vytváření clusteru můžete určit počet pracovních uzlů pomocí webu Azure Portal, Azure PowerShellu nebo rozhraní příkazového řádku. Další informace najdete v tématu Vytvoření clusterů HDInsight. Následující snímek obrazovky ukazuje konfiguraci pracovního uzlu na webu Azure Portal:
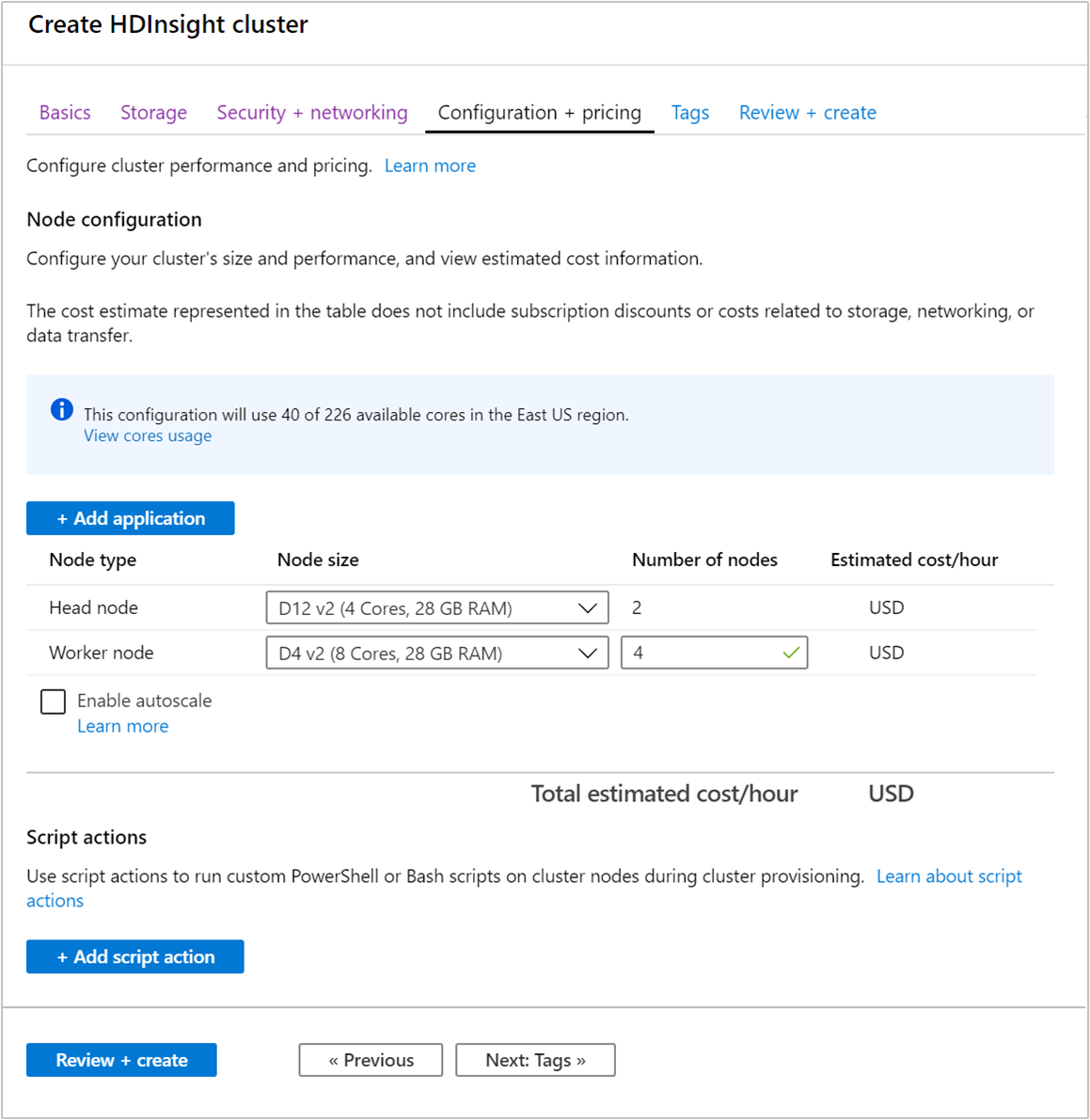
Po vytvoření můžete také upravit počet pracovních uzlů pro další horizontální navýšení kapacity clusteru, aniž byste ho vytvořili znovu:
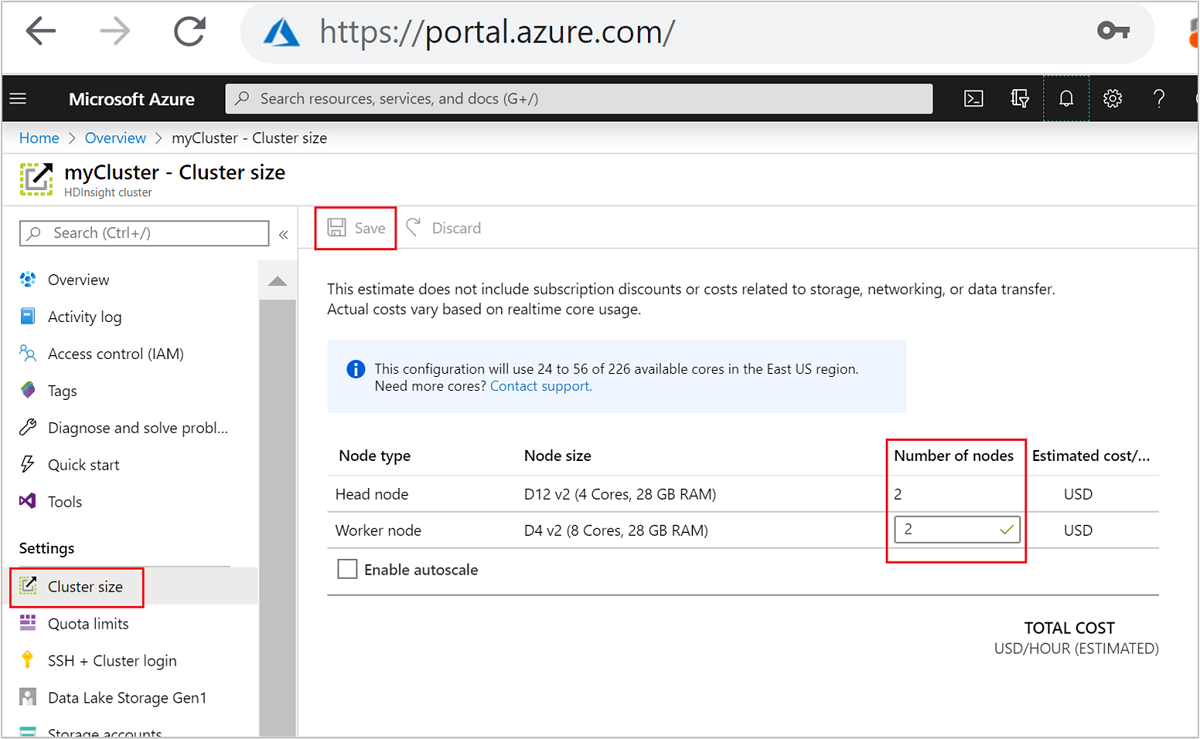
Další informace o škálování SLUŽBY HDInsight najdete v tématu Škálování clusterů HDInsight.
Použití Apache Tez místo redukce map
Apache Tez je alternativní prováděcí modul k modulu MapReduce. Clustery HDInsight se systémem Linux mají ve výchozím nastavení modul Tez povolený.
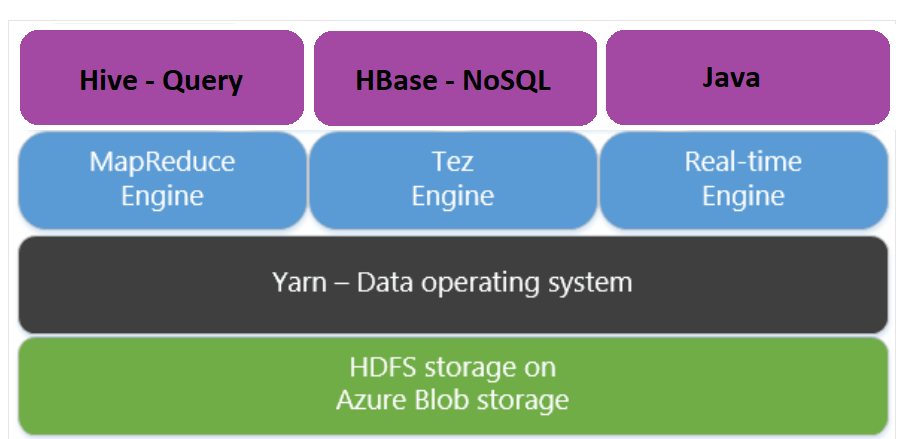
Tez je rychlejší, protože:
- V modulu MapReduce spusťte orientovaný acyklický graf (DAG) jako jednu úlohu. DAG vyžaduje, aby za každou sadou mapovačů následovala jedna sada reduktorů. Tento požadavek způsobí, že pro každý dotaz Hive se vypne několik úloh MapReduce. Tez takové omezení nemá a dokáže zpracovat komplexní DAG jako jednu úlohu, což minimalizuje režii při spouštění úlohy.
- Vyhněte se zbytečným zápisům. Ke zpracování stejného dotazu Hive v modulu MapReduce se používá více úloh. Výstup každé úlohy MapReduce je zapisován do HDFS pro zprostředkující data. Vzhledem k tomu, že Tez minimalizuje počet úloh pro každý dotaz Hive, dokáže se vyhnout zbytečným zápisům.
- Minimalizuje zpoždění při spuštění. Aplikace Tez je lépe schopna minimalizovat zpoždění při spuštění snížením počtu mapovačů, které jsou potřeba, a také zlepšením optimalizace během celého procesu.
- Znovu používá kontejnery. Kdykoli je to možné, aplikace Tez znovu použijte kontejnery, aby zajistila snížení latence při spouštění kontejnerů.
- Techniky průběžné optimalizace. Optimalizace se tradičně prováděla během fáze kompilace. Další informace o vstupech umožňují lepší optimalizaci během doby spuštění. Aplikace Tez používá techniky průběžné optimalizace, které umožňují optimalizovat plán dále do fáze doby spuštění.
Další informace o těchto konceptech najdete v tématu Apache TEZ.
Jakýkoli dotaz Hive můžete povolit zadáním předpony dotazu pomocí následujícího příkazu set:
set hive.execution.engine=tez;
Dělení Hivu
Vstupně-výstupní operace jsou hlavním kritickým bodem výkonu pro spouštění dotazů Hive. Výkon lze zlepšit, pokud je možné snížit množství dat, která je třeba číst. Ve výchozím nastavení dotazy Hive prohledávají celé tabulky Hive. U dotazů, které potřebují jenom prohledávat malé množství dat (například dotazy s filtrováním), toto chování vytváří zbytečné režie. Dělení Hive umožňuje dotazům Hive přístup pouze k potřebnému množství dat v tabulkách Hive.
Dělení Hive se implementuje tak, že změní uspořádání nezpracovaných dat do nových adresářů. Každý oddíl má svůj vlastní adresář souborů. Uživatel definuje dělení. Následující diagram znázorňuje rozdělení tabulky Hive podle sloupce Year. Pro každý rok se vytvoří nový adresář.
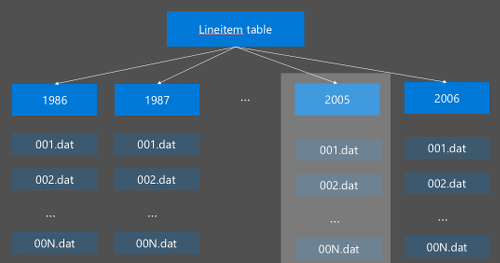
Některé aspekty dělení:
- Nedělejte oddíl – Dělení na sloupce s několika hodnotami může způsobit několik oddílů. Například dělení na pohlaví vytváří pouze dva oddíly, které se vytvoří (muž a žena), takže snižte latenci maximálně o polovinu.
- Nepřesouvejte oddíl – Na druhém extrémním případě vytvoření oddílu ve sloupci s jedinečnou hodnotou (například id uživatele) způsobí více oddílů. Over partition způsobuje velký stres na uzlu namenode clusteru, protože musí zpracovávat velký počet adresářů.
- Vyhněte se nerovnoměrné distribuci dat – Zvolte klíč dělení rozumně, aby všechny oddíly byly sudé. Například dělení ve sloupci State může zkosení distribuce dat. Vzhledem k tomu, že stát Kalifornie má populaci téměř 30x vermont, velikost oddílu je potenciálně nerovnoměrná a výkon se může výrazně lišit.
K vytvoření tabulky oddílů použijte klauzuli Partitioned By :
CREATE TABLE lineitem_part
(L_ORDERKEY INT, L_PARTKEY INT, L_SUPPKEY INT,L_LINENUMBER INT,
L_QUANTITY DOUBLE, L_EXTENDEDPRICE DOUBLE, L_DISCOUNT DOUBLE,
L_TAX DOUBLE, L_RETURNFLAG STRING, L_LINESTATUS STRING,
L_SHIPDATE_PS STRING, L_COMMITDATE STRING, L_RECEIPTDATE STRING,
L_SHIPINSTRUCT STRING, L_SHIPMODE STRING, L_COMMENT STRING)
PARTITIONED BY(L_SHIPDATE STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;
Po vytvoření dělené tabulky můžete buď vytvořit statické dělení, nebo dynamické dělení.
Statické dělení znamená, že už máte horizontálně dělená data v příslušných adresářích. Se statickými oddíly přidáte oddíly Hive ručně na základě umístění adresáře. Příkladem je následující fragment kódu.
INSERT OVERWRITE TABLE lineitem_part PARTITION (L_SHIPDATE = '5/23/1996 12:00:00 AM') SELECT * FROM lineitem WHERE lineitem.L_SHIPDATE = '5/23/1996 12:00:00 AM' ALTER TABLE lineitem_part ADD PARTITION (L_SHIPDATE = '5/23/1996 12:00:00 AM') LOCATION 'wasb://sampledata@ignitedemo.blob.core.windows.net/partitions/5_23_1996/'Dynamické dělení znamená, že chcete, aby Hive automaticky vytvářel oddíly za vás. Vzhledem k tomu, že jste už vytvořili tabulku dělení z pracovní tabulky, stačí vložit data do dělené tabulky:
SET hive.exec.dynamic.partition = true; SET hive.exec.dynamic.partition.mode = nonstrict; INSERT INTO TABLE lineitem_part PARTITION (L_SHIPDATE) SELECT L_ORDERKEY as L_ORDERKEY, L_PARTKEY as L_PARTKEY, L_SUPPKEY as L_SUPPKEY, L_LINENUMBER as L_LINENUMBER, L_QUANTITY as L_QUANTITY, L_EXTENDEDPRICE as L_EXTENDEDPRICE, L_DISCOUNT as L_DISCOUNT, L_TAX as L_TAX, L_RETURNFLAG as L_RETURNFLAG, L_LINESTATUS as L_LINESTATUS, L_SHIPDATE as L_SHIPDATE_PS, L_COMMITDATE as L_COMMITDATE, L_RECEIPTDATE as L_RECEIPTDATE, L_SHIPINSTRUCT as L_SHIPINSTRUCT, L_SHIPMODE as L_SHIPMODE, L_COMMENT as L_COMMENT, L_SHIPDATE as L_SHIPDATE FROM lineitem;
Další informace najdete v tématu Dělené tabulky.
Použití formátu ORCFile
Hive podporuje různé formáty souborů. Příklad:
- Text: výchozí formát souboru a funguje ve většině scénářů.
- Avro: funguje dobře pro scénáře interoperability.
- ORC/Parquet: nejvhodnější pro výkon.
Formát ORC (optimalizovaný sloupcový řádek) je vysoce efektivní způsob ukládání dat Hive. V porovnání s jinými formáty má ORC následující výhody:
- podpora komplexních typů, včetně dateTime a složitých a částečně strukturovaných typů.
- až 70% komprese.
- indexuje každých 10 000 řádků, což umožňuje přeskočení řádků.
- významného poklesu provádění za běhu
Pokud chcete povolit formát ORC, nejprve vytvoříte tabulku s klauzulí Uložená jako ORC:
CREATE TABLE lineitem_orc_part
(L_ORDERKEY INT, L_PARTKEY INT,L_SUPPKEY INT, L_LINENUMBER INT,
L_QUANTITY DOUBLE, L_EXTENDEDPRICE DOUBLE, L_DISCOUNT DOUBLE,
L_TAX DOUBLE, L_RETURNFLAG STRING, L_LINESTATUS STRING,
L_SHIPDATE_PS STRING, L_COMMITDATE STRING, L_RECEIPTDATE STRING,
L_SHIPINSTRUCT STRING, L_SHIPMODE STRING, L_COMMENT STRING)
PARTITIONED BY(L_SHIPDATE STRING)
STORED AS ORC;
Dále vložíte data do tabulky ORC z pracovní tabulky. Příklad:
INSERT INTO TABLE lineitem_orc
SELECT L_ORDERKEY as L_ORDERKEY,
L_PARTKEY as L_PARTKEY ,
L_SUPPKEY as L_SUPPKEY,
L_LINENUMBER as L_LINENUMBER,
L_QUANTITY as L_QUANTITY,
L_EXTENDEDPRICE as L_EXTENDEDPRICE,
L_DISCOUNT as L_DISCOUNT,
L_TAX as L_TAX,
L_RETURNFLAG as L_RETURNFLAG,
L_LINESTATUS as L_LINESTATUS,
L_SHIPDATE as L_SHIPDATE,
L_COMMITDATE as L_COMMITDATE,
L_RECEIPTDATE as L_RECEIPTDATE,
L_SHIPINSTRUCT as L_SHIPINSTRUCT,
L_SHIPMODE as L_SHIPMODE,
L_COMMENT as L_COMMENT
FROM lineitem;
Další informace o formátu ORC najdete v příručce jazyka Apache Hive.
Vektorizace
Vektorizace umožňuje službě Hive zpracovat dávku 1 024 řádků společně namísto zpracování jednoho řádku najednou. To znamená, že jednoduché operace jsou prováděny rychleji, protože stačí spustit méně interního kódu.
Pokud chcete povolit předponu vektorizace dotazu Hive s následujícím nastavením:
set hive.vectorized.execution.enabled = true;
Další informace naleznete v tématu Vektorizované spuštění dotazu.
Další metody optimalizace
Existuje více metod optimalizace, které můžete zvážit, například:
- Kontejnery Hive: technika, která umožňuje clusterovat nebo segmentovat velké sady dat za účelem optimalizace výkonu dotazů.
- Optimalizace spojení: Optimalizace plánování provádění dotazů Hive za účelem zlepšení efektivity spojení a snížení potřeby uživatelských tipů. Další informace najdete v tématu Optimalizace připojení.
- Zvyšte reduktory.
Další kroky
V tomto článku jste se naučili několik běžných metod optimalizace dotazů Hive. Další informace najdete v těchto článcích:
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro