Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
V tomto článku provedete následující kroky.
Spuštěním vlastního skriptu nainstalujte sadu Microsoft Cognitive Toolkit do clusteru Azure HDInsight Spark.
Nahrajte poznámkový blok Jupyter do clusteru Apache Spark, abyste zjistili, jak aplikovat natrénovaný model deep learningu Microsoft Cognitive Toolkit na soubory v účtu služby Azure Blob Storage využitím rozhraní Spark Python API (PySpark).
Požadavky
Cluster Apache Spark ve službě HDInsight. Viz Vytvoření clusteru Apache Spark.
Znalost používání poznámkových bloků Jupyter se Sparkem ve službě HDInsight. Další informace najdete v tématu Načtení dat a spouštění dotazů pomocí Apache Sparku ve službě HDInsight.
Jak funguje toto řešení?
Toto řešení je rozdělené mezi tento článek a Jupyter Notebook, který nahrajete jako součást tohoto článku. V tomto článku provedete následující kroky:
- Spuštěním akce skriptu v clusteru HDInsight Spark nainstalujte balíčky Microsoft Cognitive Toolkit a Pythonu.
- Nahrajte poznámkový blok Jupyter, který spouští řešení do clusteru HDInsight Spark.
V poznámkovém bloku Jupyter jsou popsané následující zbývající kroky.
- Načtěte ukázkové obrázky do Resilient Distributed Dataset (RDD) Sparku.
- Načtěte moduly a definujte přednastavení.
- Stáhněte datovou sadu místně v clusteru Spark.
- Převeďte datovou sadu na RDD.
- Ohodnoťte obrázky pomocí trénovaného modelu Cognitive Toolkit.
- Stáhněte natrénovaný model Cognitive Toolkit do clusteru Spark.
- Definujte funkce, které mají být používány pracovními uzly.
- Ohodnoťte obrázky na pracovních uzlech.
- Vyhodnocení přesnosti modelu
Instalace sady Microsoft Cognitive Toolkit
Sadu Microsoft Cognitive Toolkit můžete nainstalovat do clusteru Spark pomocí akce skriptu. Akce skriptu používá vlastní skripty k instalaci komponent do clusteru, které nejsou ve výchozím nastavení dostupné. Vlastní skript můžete použít z webu Azure Portal, pomocí sady HDInsight .NET SDK nebo pomocí Azure PowerShellu. Skript můžete použít také k instalaci sady nástrojů v rámci vytváření clusteru nebo po spuštění clusteru.
V tomto článku použijeme portál k instalaci sady nástrojů po vytvoření clusteru. Další způsoby spuštění vlastního skriptu najdete v tématu Přizpůsobení clusterů HDInsight pomocí akce skriptu.
Pomocí webu Azure Portal
Pokyny k použití webu Azure Portal ke spuštění akce skriptu najdete v tématu Přizpůsobení clusterů HDInsight pomocí akce skriptu. Ujistěte se, že pro instalaci sady Microsoft Cognitive Toolkit zadáte následující vstupy. Pro akci skriptu použijte následující hodnoty:
| Vlastnictví | Hodnota |
|---|---|
| Typ skriptu | - Na míru |
| Název | Nainstalujte MCT |
| URI skriptu Bash | https://raw.githubusercontent.com/Azure-Samples/hdinsight-pyspark-cntk-integration/master/cntk-install.sh |
| Typy uzlů: | Vedoucí, Pracovník |
| Parametry | Žádné |
Nahrání poznámkového bloku Jupyter do clusteru Azure HDInsight Spark
Pokud chcete používat sadu Microsoft Cognitive Toolkit s clusterem Azure HDInsight Spark, musíte do clusteru Azure HDInsight Spark načíst Jupyter Notebook CNTK_model_scoring_on_Spark_walkthrough.ipynb. Tento poznámkový blok je k dispozici na GitHubu na adrese https://github.com/Azure-Samples/hdinsight-pyspark-cntk-integration.
Stáhnout a rozbalit https://github.com/Azure-Samples/hdinsight-pyspark-cntk-integration.
Ve webovém prohlížeči navigujte na
https://CLUSTERNAME.azurehdinsight.net/jupyter, kdeCLUSTERNAMEje název vašeho clusteru.V poznámkovém bloku Jupyter vyberte Nahrát v pravém horním rohu a pak přejděte na stažený soubor a vyberte soubor
CNTK_model_scoring_on_Spark_walkthrough.ipynb.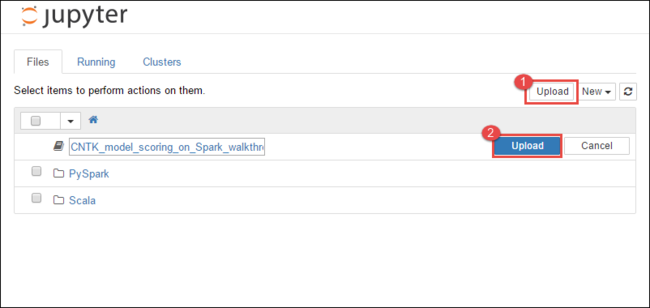
Znovu vyberte Nahrát .
Po nahrání poznámkového bloku klikněte na název poznámkového bloku a postupujte podle pokynů v samotném poznámkovém bloku, jak načíst sadu dat a provést článek.
Viz také
Scénáře
- Apache Spark s BI: Provádění interaktivní analýzy dat pomocí Sparku ve službě HDInsight s nástroji BI
- Apache Spark se službou Machine Learning: Použití Sparku ve službě HDInsight k analýze teploty budovy pomocí dat TVK
- Apache Spark se službou Machine Learning: Použití Sparku ve službě HDInsight k predikci výsledků kontroly potravin
- Analýza webových protokolů pomocí Apache Sparku ve službě HDInsight
- Analýza telemetrických dat Application Insights pomocí Apache Sparku ve službě HDInsight
Vytvoření a spouštění aplikací
- Vytvoření samostatné aplikace pomocí Scala
- Vzdálené spouštění úloh v clusteru Apache Spark pomocí Apache Livy
Nástroje a rozšíření
- Použijte plugin HDInsight Tools pro IntelliJ IDEA k vytvoření a odeslání Scala aplikací Spark
- Vzdálené ladění aplikací Apache Spark pomocí modulu plug-in nástrojů HDInsight pro IntelliJ IDEA
- Použití poznámkových bloků Apache Zeppelin s clusterem Apache Spark ve službě HDInsight
- Dostupná jádra pro Jupyter Notebook v clusteru Apache Spark pro HDInsight
- Používání externích balíčků v Jupyter Notebooku
- Instalace Jupyteru do počítače a připojení ke clusteru HDInsight Spark