Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
In this article, you'll learn how to write a query using serverless Synapse SQL pool to read Delta Lake files. Delta Lake is an open-source storage layer that brings ACID (atomicity, consistency, isolation, and durability) transactions to Apache Spark and big data workloads. You can learn more from the how to query delta lake tables video.
Important
The serverless SQL pools can query Delta Lake version 1.0. The changes that have been introduced since the Delta Lake 1.2 version (like renaming columns) aren't supported in serverless. If you're using the higher versions of Delta with delete vectors, v2 checkpoints, and others, you should consider using other query engine like Microsoft Fabric SQL endpoint for Lakehouses.
The serverless SQL pool in Synapse workspace enables you to read the data stored in Delta Lake format, and serve it to reporting tools. A serverless SQL pool can read Delta Lake files that are created using Apache Spark, Azure Databricks, or any other producer of the Delta Lake format.
Apache Spark pools in Azure Synapse enable data engineers to modify Delta Lake files using Scala, PySpark, and .NET. Serverless SQL pools help data analysts to create reports on Delta Lake files created by data engineers.
Important
Querying Delta Lake format using the serverless SQL pool is Generally available functionality. However, querying Spark Delta tables is still in public preview and not production ready. There are known issues that might happen if you query Delta tables created using the Spark pools. See the known issues in Serverless SQL pool self-help.
Prerequisites
Important
Data sources can be created only in custom databases (not in the master database or the databases replicated from Apache Spark pools).
To use the samples in this article, you'll need to complete the following steps:
- Create a database with a datasource that references NYC Yellow Taxi storage account.
- Initialize the objects by executing setup script on the database you created in step 1. This setup script will create the data sources, database scoped credentials, and external file formats that are used in these samples.
If you created your database, and switched the context to your database (using USE database_name statement or dropdown for selecting database in some query editor), you can create your external data source containing the root URI to your data set and use it to query Delta Lake files. For example:
CREATE EXTERNAL DATA SOURCE DeltaLakeStorage
WITH ( LOCATION = 'https://<yourstorageaccount>.blob.core.windows.net/delta-lake/' );
GO
SELECT TOP 10 *
FROM OPENROWSET(
BULK 'covid',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta'
) as rows;
If a data source is protected with SAS key or custom identity, you can configure data source with database scoped credential.
You can create an external data source with the location that points to the root folder of the storage. Once you've created the external data source, use the data source and the relative path to the file in the OPENROWSET function. This way you don't need to use the full absolute URI to your files. You can also then define custom credentials to access the storage location.
Read Delta Lake folder
Important
Use the setup script in the prerequisites to set up the sample data sources and tables.
The OPENROWSET function enables you to read the content of Delta Lake files by providing the URL to your root folder.
The easiest way to see to the content of your DELTA file is to provide the file URL to the OPENROWSET function and specify DELTA format. If the file is publicly available or if your Microsoft Entra identity can access this file, you should be able to see the content of the file using a query like the one shown in the following example:
SELECT TOP 10 *
FROM OPENROWSET(
BULK '/covid/',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta') as rows;
Column names and data types are automatically read from Delta Lake files. The OPENROWSET function uses best guess types like VARCHAR(1000) for the string columns.
The URI in the OPENROWSET function must reference the root Delta Lake folder that contains a subfolder called _delta_log.
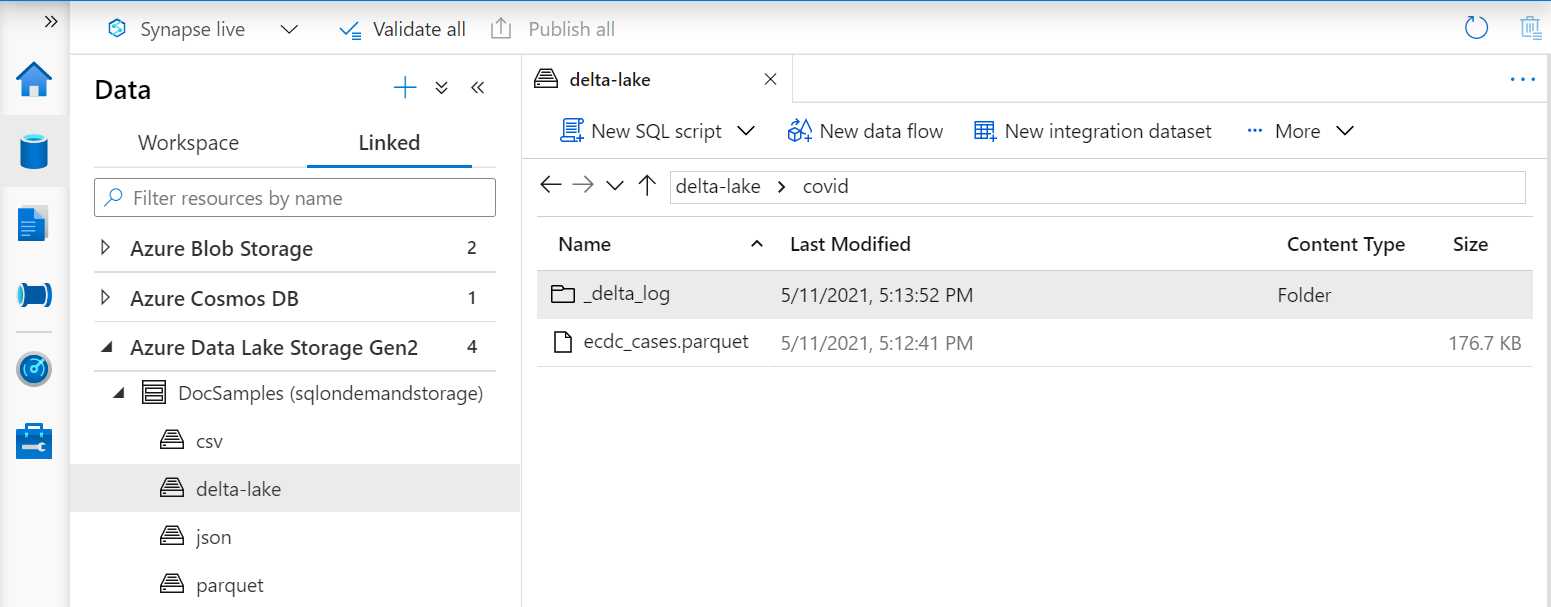
If you don't have this subfolder, you aren't using Delta Lake format. You can convert your plain Parquet files in the folder to Delta Lake format using a script like the following example Apache Spark Python script:
%%pyspark
from delta.tables import DeltaTable
deltaTable = DeltaTable.convertToDelta(spark, "parquet.`abfss://delta-lake@sqlondemandstorage.dfs.core.windows.net/covid`")
To improve the performance of your queries, consider specifying explicit types in the WITH clause.
Note
The serverless Synapse SQL pool uses schema inference to automatically determine columns and their types. The rules for schema inference are the same used for Parquet files. For Delta Lake type mapping to SQL native type check type mapping for Parquet.
Make sure you can access your file. If your file is protected with SAS key or custom Azure identity, you'll need to set up a server level credential for sql login.
Important
Ensure you're using a UTF-8 database collation (for example Latin1_General_100_BIN2_UTF8) because string values in Delta Lake files are encoded using UTF-8 encoding.
A mismatch between the text encoding in the Delta Lake file and the collation may cause unexpected conversion errors.
You can easily change the default collation of the current database using the following T-SQL statement:
ALTER DATABASE CURRENT COLLATE Latin1_General_100_BIN2_UTF8; For more information on collations, see Collation types supported for Synapse SQL.
Explicitly specify schema
OPENROWSET enables you to explicitly specify what columns you want to read from the file using WITH clause:
SELECT TOP 10 *
FROM OPENROWSET(
BULK 'covid',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta'
)
WITH ( date_rep date,
cases int,
geo_id varchar(6)
) as rows;
With the explicit specification of the result set schema, you can minimize the type sizes and use the more precise types VARCHAR(6) for string columns instead of pessimistic VARCHAR(1000). Minimization of types might significantly improve performance of your queries.
Important
Make sure that you're explicitly specifying a UTF-8 collation (for example Latin1_General_100_BIN2_UTF8) for all string columns in WITH clause or set a UTF-8 collation at the database level.
Mismatch between text encoding in the file and string column collation might cause unexpected conversion errors.
You can easily change default collation of the current database using the following T-SQL statement:
alter database current collate Latin1_General_100_BIN2_UTF8 You can easily set collation on the column types using the following definition: geo_id varchar(6) collate Latin1_General_100_BIN2_UTF8
Dataset
NYC Yellow Taxi dataset is used in this sample. The original PARQUET data set is converted to DELTA format, and the DELTA version is used in the examples.
Query partitioned data
The data set provided in this sample is divided (partitioned) into separate subfolders.
Unlike Parquet, you don't need to target specific partitions using the FILEPATH function. The OPENROWSET will identify partitioning columns in your Delta Lake folder structure and enable you to directly query data using these columns. This example shows fare amounts by year, month, and payment_type for the first three months of 2017.
SELECT
YEAR(pickup_datetime) AS year,
passenger_count,
COUNT(*) AS cnt
FROM
OPENROWSET(
BULK 'yellow',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT='DELTA'
) nyc
WHERE
nyc.year = 2017
AND nyc.month IN (1, 2, 3)
AND pickup_datetime BETWEEN CAST('1/1/2017' AS datetime) AND CAST('3/31/2017' AS datetime)
GROUP BY
passenger_count,
YEAR(pickup_datetime)
ORDER BY
YEAR(pickup_datetime),
passenger_count;
The OPENROWSET function will eliminate partitions that don't match the year and month in the where clause. This file/partition pruning technique will significantly reduce your data set, improve performance, and reduce the cost of the query.
The folder name in the OPENROWSET function (yellow in this example) is concatenated using the LOCATION in DeltaLakeStorage data source, and must reference the root Delta Lake folder that contains a subfolder called _delta_log.
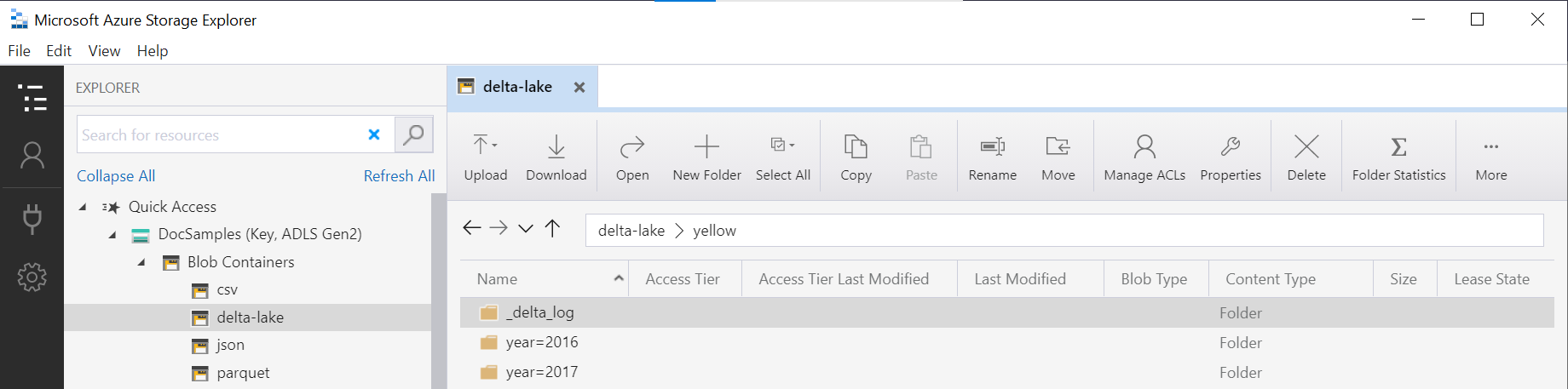
If you don't have this subfolder, you aren't using Delta Lake format. You can convert your plain Parquet files in the folder to Delta Lake format using the following Apache Spark Python script:
%%pyspark
from delta.tables import DeltaTable
deltaTable = DeltaTable.convertToDelta(spark, "parquet.`abfss://delta-lake@sqlondemandstorage.dfs.core.windows.net/yellow`", "year INT, month INT")
The second argument of DeltaTable.convertToDeltaLake function represents the partitioning columns (year and month) that are a part of folder pattern (year=*/month=* in this example) and their types.
Limitations
- Review the limitations and the known issues on Synapse serverless SQL pool self-help page.
Related content
Advance to the next article to learn how to Query Parquet nested types. If you want to continue building Delta Lake solution, learn how to create views or external tables on the Delta Lake folder.