Zásady sítě Azure Kubernetes
Zásady sítě poskytují mikros segmentaci podů stejně jako skupiny zabezpečení sítě (NSG) poskytují mikros segmentaci virtuálních počítačů. Implementace Azure Network Policy Manageru podporuje standardní specifikaci zásad sítě Kubernetes. Pomocí popisků můžete vybrat skupinu podů a definovat seznam příchozích a výstupních pravidel pro filtrování provozu do a z těchto podů. Další informace o zásadách sítě Kubernetes najdete v dokumentaci k Kubernetes.
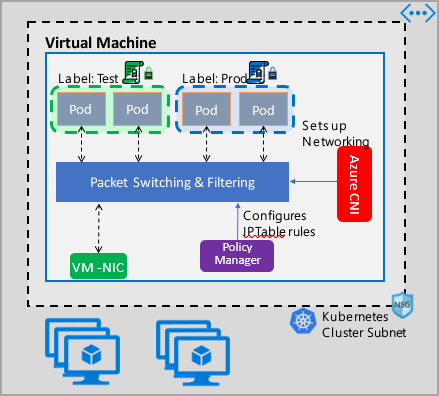
Implementace správy zásad sítě Azure funguje s Azure CNI, která poskytuje integraci virtuální sítě pro kontejnery. Správce zásad sítě se podporuje na Linuxu a Windows Serveru. Implementace vynucuje filtrování provozu konfigurací pravidel povolených a odepření PROTOKOLU IP na základě definovaných zásad v tabulkách IPTables nebo hostitelské síťové službě (HNS) ACLPolicies pro Windows Server.
Plánování zabezpečení clusteru Kubernetes
Při implementaci zabezpečení clusteru použijte skupiny zabezpečení sítě (NSG) k filtrování provozu při zadávání a opuštění podsítě clusteru (provoz na sever). Pro provoz mezi pody v clusteru (provoz mezi východem a západem) použijte Azure Network Policy Manager.
Použití Azure Network Policy Manageru
Azure Network Policy Manager je možné použít následujícími způsoby k poskytování mikrosegmentace podů.
Azure Kubernetes Service (AKS)
Správce zásad sítě je k dispozici nativně v AKS a je možné ho povolit při vytváření clusteru.
Další informace najdete v tématu Zabezpečení provozu mezi pody pomocí zásad sítě ve službě Azure Kubernetes Service (AKS).
Udělejte to sami (DIY) clustery Kubernetes v Azure
V případě clusterů DIY nejprve nainstalujte modul plug-in CNI a povolte ho na každém virtuálním počítači v clusteru. Podrobné pokyny najdete v tématu o nasazení modulu plug-in v clusteru Kubernetes, který nasazujete sami.
Po nasazení clusteru spusťte následující kubectl příkaz, který stáhne a použije démon Azure Network Policy Manageru nastavený na cluster.
V Linuxu:
kubectl apply -f https://raw.githubusercontent.com/Azure/azure-container-networking/master/npm/azure-npm.yaml
Windows:
kubectl apply -f https://raw.githubusercontent.com/Azure/azure-container-networking/master/npm/examples/windows/azure-npm.yaml
Řešení je také open source a kód je k dispozici v úložišti Azure Container Networking.
Monitorování a vizualizace konfigurací sítě pomocí Azure NPM
Azure Network Policy Manager obsahuje informativní metriky Prometheus, které umožňují monitorovat a lépe porozumět vašim konfiguracím. Poskytuje integrované vizualizace na webu Azure Portal nebo v Grafana Labs. Tyto metriky můžete začít shromažďovat pomocí služby Azure Monitor nebo serveru Prometheus.
Výhody metrik Azure Network Policy Manageru
Uživatelé dříve se dozvěděli o konfiguraci iptables sítě a ipset příkazech spouštěných uvnitř uzlu clusteru, což přináší podrobný a obtížně srozumitelný výstup.
Celkově metriky poskytují:
Počty zásad, pravidel seznamu ACL, ipset, položek ipset a položek v libovolné dané sadě ipset
Časy provádění jednotlivých volání operačního systému a zpracování událostí prostředků Kubernetes (medián, 90. percentil a 99. percentil)
Informace o selhání pro zpracování událostí prostředků Kubernetes (tyto události prostředků selžou při selhání volání operačního systému)
Příklady případů použití metrik
Výstrahy prostřednictvím správce výstrah Prometheus
Podívejte se na konfiguraci těchto výstrah následujícím způsobem.
Upozorňovat, když dojde k selhání Správce zásad sítě při volání operačního systému nebo při překladu zásad sítě.
Upozornění, když medián času použití změn pro událost vytvoření bylo více než 100 milisekund.
Vizualizace a ladění prostřednictvím řídicího panelu Grafana nebo sešitu Azure Monitoru
Podívejte se, kolik pravidel IPTables vytváří vaše zásady (s velkým počtem pravidel IPTables může mírně zvýšit latenci).
Korelují počty clusterů (například seznamy ACL) s časy provádění.
V daném pravidlu IPTables získejte popisný název ipsetu (například
azure-npm-487392představujepodlabel-role:database).
Všechny podporované metriky
Následující seznam obsahuje podporované metriky. Jakýkoli quantile popisek má možné hodnoty 0.5, 0.9a 0.99. Jakýkoli had_error popisek má možné hodnoty false a truepředstavuje, jestli operace proběhla úspěšně nebo selhala.
| Název metriky | Popis | Typ metriky Prometheus | Popisky |
|---|---|---|---|
npm_num_policies |
počet zásad sítě | Měřidlo | - |
npm_num_iptables_rules |
počet pravidel IPTables | Měřidlo | - |
npm_num_ipsets |
počet sad IPSet | Měřidlo | - |
npm_num_ipset_entries |
počet položek IP adres ve všech sadách IP adres | Měřidlo | - |
npm_add_iptables_rule_exec_time |
runtime pro přidání pravidla IPTables | Shrnutí | quantile |
npm_add_ipset_exec_time |
modul runtime pro přidání sady IPSet | Shrnutí | quantile |
npm_ipset_counts (upřesnit) |
počet položek v rámci jednotlivých sad IPSet | MěřidloVec | set_name & set_hash |
npm_add_policy_exec_time |
modul runtime pro přidání zásad sítě | Shrnutí | quantile & had_error |
npm_controller_policy_exec_time |
modul runtime pro aktualizaci nebo odstranění zásad sítě | Shrnutí | quantile & had_erroroperation (s hodnotami update nebo delete) |
npm_controller_namespace_exec_time |
runtime pro vytvoření, aktualizaci nebo odstranění oboru názvů | Shrnutí | quantile & had_erroroperation (s hodnotami create, updatenebo delete) |
npm_controller_pod_exec_time |
modul runtime pro vytváření, aktualizaci nebo odstranění podu | Shrnutí | quantile & had_erroroperation (s hodnotami create, updatenebo delete) |
Pro každou metriku souhrnu exec_time existují také metriky exec_time_count a exec_time_sum.
Metriky je možné sešrotovat prostřednictvím služby Azure Monitor pro kontejnery nebo prostřednictvím nástroje Prometheus.
Nastavení pro Azure Monitor
Prvním krokem je povolení služby Azure Monitor pro kontejnery pro váš cluster Kubernetes. Kroky najdete ve službě Azure Monitor pro kontejnery – přehled. Jakmile máte službu Azure Monitor pro kontejnery povolenou, nakonfigurujte Azure Monitor pro kontejnery ConfigMap tak, aby umožňovala integraci a shromažďování metrik Nástroje pro správu zásad sítě Prometheus.
Azure Monitor pro kontejnery ConfigMap obsahuje integrations oddíl s nastavením pro shromažďování metrik Network Policy Manageru.
Tato nastavení jsou ve výchozím nastavení v objektu ConfigMap zakázaná. Povolení základního nastavení collect_basic_metrics = trueshromažďuje základní metriky Správce zásad sítě. Povolení rozšířeného nastavení collect_advanced_metrics = true shromažďuje kromě základních metrik i pokročilé metriky.
Po úpravě objektu ConfigMap ho uložte místně a následujícím způsobem použijte objekt ConfigMap pro váš cluster.
kubectl apply -f container-azm-ms-agentconfig.yaml
Následující fragment kódu je z Azure Monitoru pro kontejnery ConfigMap, který ukazuje integraci Správce zásad sítě s pokročilou kolekcí metrik.
integrations: |-
[integrations.azure_network_policy_manager]
collect_basic_metrics = false
collect_advanced_metrics = true
Rozšířené metriky jsou volitelné a jejich zapnutí automaticky zapne základní shromažďování metrik. Rozšířené metriky aktuálně zahrnují pouze Network Policy Manager_ipset_counts.
Další informace o nastavení kolekce kontejnerů ve službě Azure Monitor najdete v mapě konfigurace.
Možnosti vizualizace pro Azure Monitor
Po povolení shromažďování metrik Network Policy Manageru můžete metriky zobrazit na webu Azure Portal pomocí přehledů kontejnerů nebo grafany.
Zobrazení na webu Azure Portal v přehledech pro cluster
Otevřete Azure Portal. Jakmile budete v přehledech clusteru, přejděte do sešitů a otevřete konfiguraci Správce zásad sítě (Network Policy Manager).
Kromě zobrazení sešitu můžete také přímo dotazovat metriky Prometheus v části Protokoly v části Přehledy. Tento dotaz například vrátí všechny shromážděné metriky.
| where TimeGenerated > ago(5h)
| where Name contains "npm_"
Můžete také dotazovat analýzy protokolů přímo pro metriky. Další informace najdete v tématu Začínáme s dotazy Log Analytics.
Zobrazení na řídicím panelu Grafana
Nastavte server Grafana a nakonfigurujte zdroj dat Log Analytics, jak je popsáno tady. Potom naimportujte řídicí panel Grafana s back-endem Log Analytics do grafana Labs.
Řídicí panel obsahuje vizuály podobné sešitu Azure. Můžete přidat panely k grafu a vizualizovat metriky Network Policy Manageru z tabulky Přehledy Metrické metriky.
Nastavení pro server Prometheus
Někteří uživatelé se můžou rozhodnout shromažďovat metriky pomocí serveru Prometheus místo služby Azure Monitor pro kontejnery. Stačí do konfigurace výstřižku přidat dvě úlohy, abyste mohli shromažďovat metriky Správce zásad sítě.
Pokud chcete nainstalovat server Prometheus, přidejte do clusteru toto úložiště Helm:
helm repo add stable https://kubernetes-charts.storage.googleapis.com
helm repo update
pak přidejte server.
helm install prometheus stable/prometheus -n monitoring \
--set pushgateway.enabled=false,alertmanager.enabled=false, \
--set-file extraScrapeConfigs=prometheus-server-scrape-config.yaml
kde prometheus-server-scrape-config.yaml se skládá z:
- job_name: "azure-npm-node-metrics"
metrics_path: /node-metrics
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
action: replace
regex: ([^:]+)(?::\d+)?
replacement: "$1:10091"
target_label: __address__
- job_name: "azure-npm-cluster-metrics"
metrics_path: /cluster-metrics
kubernetes_sd_configs:
- role: service
relabel_configs:
- source_labels: [__meta_kubernetes_namespace]
regex: kube-system
action: keep
- source_labels: [__meta_kubernetes_service_name]
regex: npm-metrics-cluster-service
action: keep
# Comment from here to the end to collect advanced metrics: number of entries for each IPSet
metric_relabel_configs:
- source_labels: [__name__]
regex: npm_ipset_counts
action: drop
Úlohu můžete také nahradit azure-npm-node-metrics následujícím obsahem nebo ji začlenit do existující úlohy pro pody Kubernetes:
- job_name: "azure-npm-node-metrics-from-pod-config"
metrics_path: /node-metrics
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_namespace]
regex: kube-system
action: keep
- source_labels: [__meta_kubernetes_pod_annotationpresent_azure_Network Policy Manager_scrapeable]
action: keep
- source_labels: [__address__]
action: replace
regex: ([^:]+)(?::\d+)?
replacement: "$1:10091"
target_label: __address__
Nastavení upozornění pro AlertManager
Pokud používáte server Prometheus, můžete nastavit Správce výstrah, jako je tomu tak. Tady je příklad konfigurace pro dvě pravidla upozorňování popsaná dříve:
groups:
- name: npm.rules
rules:
# fire when Network Policy Manager has a new failure with an OS call or when translating a Network Policy (suppose there's a scraping interval of 5m)
- alert: AzureNetwork Policy ManagerFailureCreatePolicy
# this expression says to grab the current count minus the count 5 minutes ago, or grab the current count if there was no data 5 minutes ago
expr: (npm_add_policy_exec_time_count{had_error='true'} - (npm_add_policy_exec_time_count{had_error='true'} offset 5m)) or npm_add_policy_exec_time_count{had_error='true'}
labels:
severity: warning
addon: azure-npm
annotations:
summary: "Azure Network Policy Manager failed to handle a policy create event"
description: "Current failure count since Network Policy Manager started: {{ $value }}"
# fire when the median time to apply changes for a pod create event is more than 100 milliseconds.
- alert: AzurenpmHighControllerPodCreateTimeMedian
expr: topk(1, npm_controller_pod_exec_time{operation="create",quantile="0.5",had_error="false"}) > 100.0
labels:
severity: warning
addon: azure-Network Policy Manager
annotations:
summary: "Azure Network Policy Manager controller pod create time median > 100.0 ms"
# could have a simpler description like the one for the alert above,
# but this description includes the number of pod creates that were handled in the past 10 minutes,
# which is the retention period for observations when calculating quantiles for a Prometheus Summary metric
description: "value: [{{ $value }}] and observation count: [{{ printf `(npm_controller_pod_exec_time_count{operation='create',pod='%s',had_error='false'} - (npm_controller_pod_exec_time_count{operation='create',pod='%s',had_error='false'} offset 10m)) or npm_controller_pod_exec_time_count{operation='create',pod='%s',had_error='false'}` $labels.pod $labels.pod $labels.pod | query | first | value }}] for pod: [{{ $labels.pod }}]"
Možnosti vizualizace pro Prometheus
Pokud používáte Server Prometheus, podporuje se pouze řídicí panel Grafana.
Pokud jste to ještě neudělali, nastavte server Grafana a nakonfigurujte zdroj dat Prometheus. Potom naimportujte náš řídicí panel Grafana s back-endem Prometheus do grafana Labs.
Vizuály pro tento řídicí panel jsou shodné s řídicím panelem s back-endem pro přehledy kontejnerů nebo log analytics.
Ukázkové řídicí panely
Následuje ukázkový řídicí panel pro metriky Network Policy Manageru v přehledech kontejnerů (CI) a Grafana.
Počty souhrnů CI
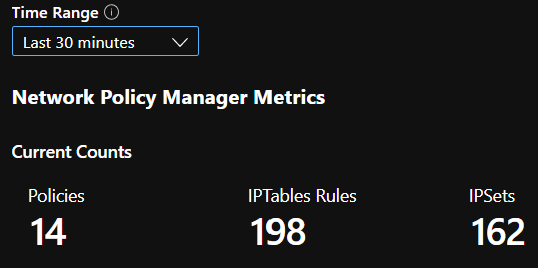
Počet CI v průběhu času

Položky CI IPSet

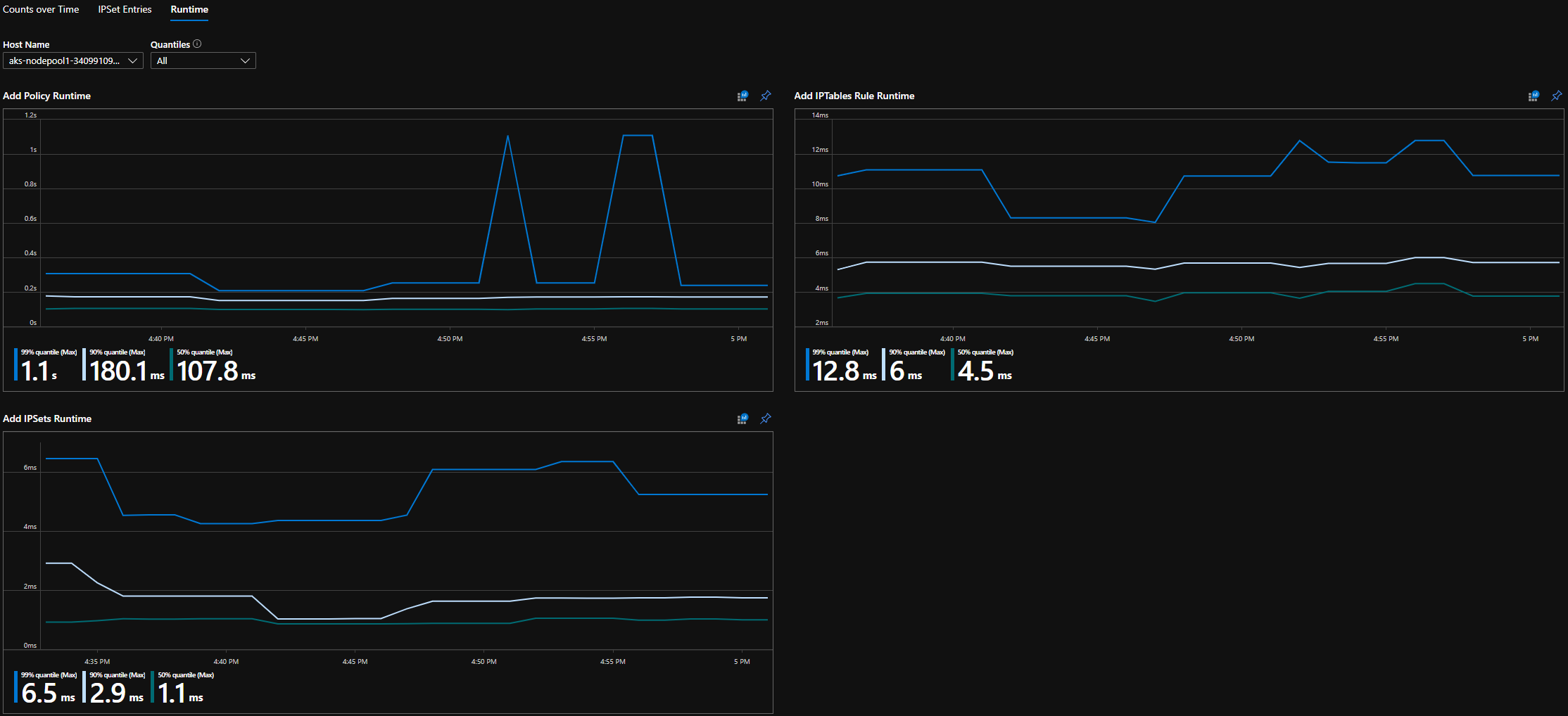
Quantiles modulu runtime CI
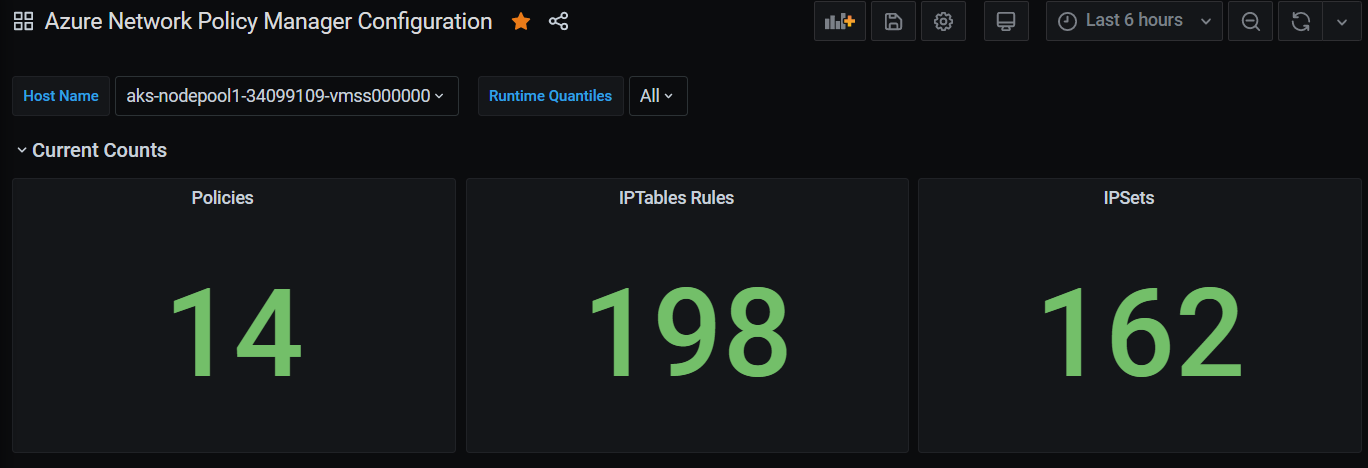
Počty souhrnů řídicího panelu Grafana
Počet řídicích panelů Grafana v průběhu času

Položky IPSet řídicího panelu Grafana

Quantiles modulu runtime řídicího panelu Grafana

Další kroky
Přečtěte si o službě Azure Kubernetes Service.
Přečtěte si o sítích kontejnerů.
Nasaďte modul plug-in pro clustery Kubernetes nebo kontejnery Dockeru.
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro