Developing sensitive information rule packages in Exchange 2013
Applies to: Exchange Server 2013
The XML schema and guidance in this topic will help you get started creating your own basic data loss prevention (DLP) XML files that define your own sensitive information types in a classification rule package. After you have created a well-formed XML file, you can import it by using either the Exchange admin center or the Exchange management shell in order to help create a Microsoft Exchange Server 2013 DLP solution. An XML file that is a custom DLP policy template can contain the XML that is your classification rule package. For an overview about defining your own DLP templates as XML files, see Define your own DLP templates and information types.
Overview of the rule authoring process
The rule authoring process is made up of the following general steps.
Prepare a set of test documents representative of their target environment. Key characteristics to consider for the set of test documents include: A subset of the documents contains the entity or affinity for which the rule is being authored, and a subset of the documents don't contain the entity or affinity for which the rule is being authored.
Identify the rules that meet acceptance requirements (precision and recall) to identify qualifying content. This identification effort may require the development of multiple conditions within a rule, bound with Boolean logic, which together satisfy the minimum match requirements to identify target documents.
Establish the recommended confidence level for the rules based on the acceptance requirements (precision and recall). The recommended confidence element can be thought of as the default confidence level for the rule.
Validate the rules by instantiating a policy with them and monitoring the sample test content. Based on the results, adjust the rules, or the confidence level to maximize the detected content while minimizing false positives and negatives. Continue the cycle of validation and rule adjustments until a satisfactory level of content detection is reached for both positive and negative samples.
For information about the XML schema definition for policy template files, see Developing DLP policy template files.
Rule description
Two main Rule types can be authored for the DLP sensitive information detection engine: Entity and Affinity. The Rule type chosen is based on the type of processing logic that should be applied to the processing of the content as described in the previous sections. The rule definitions are configured in an XML document in the format described by the standardized Rules XSD. The rules describe both the type of content to match and the confidence level that the described match represents the target content. Confidence level specifies the probability for the Entity to be present if a Pattern is found in the content or the probability for the Affinity to be present if Evidence is found in the content.
Basic rule structure
The Rule definition is constructed from three main components:
Entity defines the matching and counting logic for that rule
Affinity defines the matching logic for the rule
Localized Strings localization for rule names and their descriptions
Three other supporting elements are used that define the details of the processing and referenced within the main components: Keyword, Regex, and Function. By using references, a single definition of the supporting elements, like a social security number, can be used to in multiple Entity or Affinity rules. The basic rule structure in XML format can be seen as follows.
<?xml version="1.0" encoding="utf-8"?>
<RulePackage xmlns="http://schemas.microsoft.com/office/2011/mce">
<RulePack id="DAD86A92-AB18-43BB-AB35-96F7C594ADAA">
<Version major="1" minor="0" build="0" revision="0"/>
<Publisher id="619DD8C3-7B80-4998-A312-4DF0402BAC04"/>
<Details defaultLangCode="en-us">
<LocalizedDetails langcode="en-us">
<PublisherName>DLP by EPG</PublisherName>
<Name>CSO Custom Rule Pack</Name>
<Description>This is a rule package for a EPG demo.</Description>
</LocalizedDetails>
</Details>
</RulePack>
<Rules>
<!-- Employee ID -->
<Entity id="E1CC861E-3FE9-4A58-82DF-4BD259EAB378" patternsProximity="300" recommendedConfidence="75">
<Pattern confidenceLevel="75">
<IdMatch idRef="Regex_employee_id" />
<Match idRef="Keyword_employee" />
</Pattern>
</Entity>
<Regex id="Regex_employee_id">(\s)(\d{9})(\s)</Regex>
<Keyword id="Keyword_employee">
<Group matchStyle="word">
<Term>Identification</Term>
<Term>Contoso Employee</Term>
</Group>
</Keyword>
<LocalizedStrings>
<Resource idRef="E1CC861E-3FE9-4A58-82DF-4BD259EAB378">
<Name default="true" langcode="en-us">
Employee ID
</Name>
<Description default="true" langcode="en-us">
A custom classification for detecting Employee ID's
</Description>
</Resource>
</LocalizedStrings>
</Rules>
</RulePackage>
Entity rules
Entity Rules are targeted towards well-defined identifiers, such as Social Security Number, and are represented by a collection of countable patterns. Entity Rules returns a count and the confidence level of a match, where Count is the total number of instances of the entity that were found and the Confidence Level is the probability that the given entity exists in the given document. Entity contains the "Id" attribute as its unique identifier. The identifier is used for localization, versioning, and querying. The Entity ID must be a GUID. The Entity ID must not be duplicated in other entities or affinities. It's referenced in the localized strings section.
Entity rules contain optional patternsProximity attribute (default = 300) which is used when applying Boolean logic to specify the adjacency of multiple patterns required to satisfy the match condition. Entity element contains one or more child Pattern elements, where each pattern is a distinct representation of the Entity like Credit Card Entity or Driver's License Entity. The Pattern element has a required attribute of confidenceLevel that represents the pattern's precision based on sample dataset. Pattern element can have three child elements:
IdMatch - This element is required.
Match
Any
If any of the Pattern elements return "true," the Pattern is satisfied. The count for the Entity element equals the sum of all detected Pattern counts.

where k is the number of Pattern elements for the Entity.
A Pattern element must have exactly one IdMatch element. IdMatch represents the identifier that the Pattern is to match, for example a credit card number or ITIN number. The Count for a pattern is the number of IdMatches matched with the Pattern element. IdMatch element anchors the proximity window for the Match elements.
Another optional subelement of the Pattern element is the Match element that represents corroborative evidence that is required to be matched to support finding the IdMatch element. For example, the higher confidence rule may require that, in addition to finding a credit card number, extra artifacts exist in the document, within a proximity window of the credit card, like address and name. These extra artifacts would be represented through the Match element or Any element (described in detail in Matching Methods and Techniques section). Multiple Match elements can be included in a Pattern definition, which can be included directly in the Pattern element or combined using the Any element to define matching semantics. It returns true if a match is found in the proximity window anchored around the IdMatch content.
Both the IdMatch and Match elements don't define the details of what content needs to be matched but instead reference it through the idRef attribute. This referencing promotes reusability of definitions in multiple Pattern constructs.
<Entity id="..." patternsProximity="300" >
<Pattern confidenceLevel="85">
<IdMatch idRef="FormattedSSN" />
<Any minMatches="1">
<Match idRef="SSNKeyword" />
<Match idRef="USDate" />
<Match idRef="USAddress" />
<Match idRef="Name" />
</Any>
</Pattern>
<Pattern confidenceLevel="65">
<IdMatch idRef="UnformattedSSN" />
<Match idRef="SSNKeyword" />
<Any minMatches="1">
<Match idRef="USDate" />
<Match idRef="USAddress" />
<Match idRef="Name" />
</Any>
</Pattern>
</Entity>
The Entity Id element, represented in the previous XML by "..." should be a GUID and it's referenced in the Localized Strings section.
Entity pattern proximity window
Entity holds optional patternsProximity attribute value (integer, default = 300) used to find the Patterns. For each pattern, the attribute value defines the distance (in Unicode characters) from the IdMatch location for all other Matches specified for that Pattern. The proximity window is anchored by the IdMatch location, with the window extending to the left and right of the IdMatch.
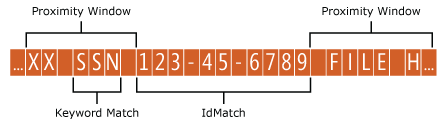
The example below illustrates how the proximity window affects the matching algorithm where the SSN IdMatch element requires at least one of address, name, or date corroborating matches. Only SSN1 and SSN4 match because for SSN2 and SSN3, either no or only partial corroborating evidence is found within the proximity window.

The message body and each attachment are treated as independent items. This condition means that the proximity window doesn't extend beyond the end of each of these items. For each item (attachment or body), both the idMatch and corroborative evidence needs to reside within each.
Entity confidence level
Entity element's confidence level is the combination of all the satisfied Pattern's confidence levels. They're combined using the following equation:

where k is the number of Pattern elements for the Entity and a Pattern that doesn't match returns a confidence level of 0.
Referring back to the example entity element structure code sample, if both patterns are matched, the entity's confidence level is 94.75% based on the following calculation:
CLEntity = 1-[(1-CL Pattern1) x (1-CLPattern1)]
= 1-[(1-0.85) x (1-0.65)]
= 1-(0.15 x 0.35)
= 94.75%
Similarly, if only the second pattern matches, the Entity's confidence level is 65% based on the following calculation:
CLEntity = 1 - [(1 - CL Pattern1) X (1 - CLPattern1)]
= 1 - [(1 - 0) X (1 - 0.65)]
= 1 - (1 X 0.35)
= 65%
These confidence values are assigned in the rules for individual patterns based on the set of test documents validated as part of the rule authoring process.
Affinity rules
Affinity rules are targeted towards content without well-defined identifiers, for example Sarbanes-Oxley or corporate financial content. For this content, no single consistent identifier can be found and instead the analysis requires determining if a collection of evidence is present. Affinity rules don't return a count, instead they return if found and the associated confidence level. Affinity content is represented as a collection of independent evidences. Evidence is an aggregation of required matches within certain proximity. For Affinity rule, the proximity is defined by the evidencesProximity attribute (default is 600) and the minimum confidence level by the thresholdConfidenceLevel attribute.
Affinity rules contain the Id attribute for its unique identifier that is used for localization, versioning and querying. Unlike Entity rules, because Affinity rules don't rely on well-defined identifiers, they don't contain the IdMatch element.
Each Affinity rule contains one or more child Evidence elements that define the evidence that is to be found and the level of confidence contributing to the Affinity rule. The affinity isn't considered found if the resulting confidence level is below the threshold level. Each Evidence logically represents corroborative evidence for this "type" of document and the confidenceLevel attribute is the precision for that Evidence on the test dataset.
Evidence elements have one or more of Match or Any child elements. If all child Match and Any elements match, the Evidence is found and the confidence level is contributed to the rules confidence level calculation. The same description applies to the Match or Any elements for Affinity rules as for Entity rules.
<Affinity id="..."
evidencesProximity="1000"
thresholdConfidenceLevel="65">
<Evidence confidenceLevel="40">
<Any>
<Match idRef="AssetsTerms" />
<Match idRef="BalanceSheetTerms" />
<Match idRef="ProfitAndLossTerms" />
</Any>
</Evidence>
<Evidence confidenceLevel="40">
<Any minMatches="2">
<Match idRef="TaxTerms" />
<Match idRef="DollarAmountTerms" />
<Match idRef="SECTerms" />
<Match idRef="SECFilingFormTerms" />
<Match idRef="DollarTotalRegex" />
</Any>
</Evidence>
</Affinity>
Affinity proximity window
The proximity window for Affinity is calculated differently than for Entity patterns. Affinity proximity follows a sliding window model. The affinity proximity algorithm attempts to find the maximum number of matching evidences in the given window. Evidences in the proximity window must have a confidence level greater than the threshold defined for the Affinity rule to be found.

Affinity confidence level
Confidence level for the Affinity equals the combination of found Evidences within the proximity window for the Affinity rule. While similar to the confidence level of Entity rule, the key difference is the application of proximity window. Similar to the Entity rules, Affinity element's confidence level is the combination of all the satisfied Evidence confidence levels, but for Affinity rule it only represents the highest combination of Evidence elements found within the proximity window. The Evidence confidence levels are combined using the following equation:

where k is the number of Evidence elements for the Affinity matched within the proximity window.
Referring back to Figure 4 Example Affinity rule structure, if all three evidences are matched within the proximity sliding window, the affinity confidence level is 85.6% based on the calculation below. This value exceeds the Affinity rule threshold of 65, which results in the rule matching.
CLAffinity = 1 - [(1 - CL Evidence 1) X (1 - CLEvidence 2) X (1 - CLEvidence 2)]
= 1 - [(1 - 0.6) X (1 - 0.4) X (1 - 0.4)]
= 1 - (0.4 X 0.6 X 0.6)
= 85.6%

Using the same example rule definition, if only the first evidence matches because the second Evidence is outside of the proximity window, the highest Affinity confidence level is 60% based on the calculation below and the Affinity rule doesn't match since the threshold of 65 wasn't met.
CLAffinity = 1 - [(1 - CL Evidence 1) X (1 - CLEvidence 2) X (1 - CLEvidence 2)]
= 1 - [(1 - 0.6) X (1 - 0) X (1 - 0) ]
= 1 - (0.4 X 1 X 1)
= 60%

Tuning confidence levels
One of the key aspects of the rule authoring process is the tuning of confidence levels for both Entity and Affinity rules. After creating the rule definitions, run the rule against the representative content and collect the accuracy data. Compare the returned results for each pattern or evidence against the expected results for the test documents.

If the rules meet acceptance requirements, that is, the Pattern or Evidence has a confidence rate above an established threshold (for example, 75%), the match expression is complete and it can be moved to the next step.
If the Pattern or Evidence doesn't meet the confidence level, then reauthor it (for example, add more corroborative evidence; remove or add extra Patterns/Evidences; etc.) and repeat this step.
Next, tune the confidence level for each Pattern or Evidence in your rules based on the results from the previous step. For each Pattern or Evidence, aggregate the number of True Positives (TP), subset of the documents that contain the entity or affinity for which the rule is being authored and that resulted in a match and the number of False Positives (FP), a subset of documents that don't contain the entity or affinity for which the rule is being authored and that also returned a match. Set confidence level for each Pattern/Evidence using the following calculation:
Confidence Level = True Positives / (True Positives + False Positives)
| Pattern or Evidence | True Positives | False Positives | Confidence Level |
|---|---|---|---|
| P1or E1 | 4 | 1 | 80% |
| P2or E2 | 2 | 2 | 50% |
| Pnor En | 9 | 10 | 47% |
Using local languages in your XML file
The rule schema supports storing of localized name and description for each of Entity and Affinity elements. Each Entity and Affinity element must contain a corresponding element in the LocalizedStrings section. To localize each element, include a Resource element as a child of the LocalizedStrings element to store name and descriptions for multiple locales for each element. The Resource element includes a required idRef attribute that matches the corresponding idRef attribute for each element that is being localized. The Locale child elements of the Resource element contain the localized name and descriptions for each specified locale.
<LocalizedStrings>
<Resource idRef="guid">
<Locale langcode="en-US" default="true">
<Name>affinity name en-us</Name>
<Description>
affinity description en-us
</Description>
</Locale>
<Locale langcode="de">
<Name>affinity name de</Name>
<Description>
affinity description de
</Description>
</Locale>
</Resource>
</LocalizedStrings>
Classification rule pack XML schema definition
<?xml version="1.0" encoding="utf-8"?>
<xs:schema xmlns:mce="http://schemas.microsoft.com/office/2011/mce"
targetNamespace="http://schemas.microsoft.com/office/2011/mce"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
elementFormDefault="qualified"
attributeFormDefault="unqualified"
id="RulePackageSchema">
<xs:simpleType name="LangType">
<xs:union memberTypes="xs:language">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:enumeration value=""/>
</xs:restriction>
</xs:simpleType>
</xs:union>
</xs:simpleType>
<xs:simpleType name="GuidType" final="#all">
<xs:restriction base="xs:token">
<xs:pattern value="[0-9a-fA-F]{8}\-([0-9a-fA-F]{4}\-){3}[0-9a-fA-F]{12}"/>
</xs:restriction>
</xs:simpleType>
<xs:complexType name="RulePackageType">
<xs:sequence>
<xs:element name="RulePack" type="mce:RulePackType"/>
<xs:element name="Rules" type="mce:RulesType">
<xs:key name="UniqueRuleId">
<xs:selector xpath="mce:Entity|mce:Affinity"/>
<xs:field xpath="@id"/>
</xs:key>
<xs:key name="UniqueProcessorId">
<xs:selector xpath="mce:Regex|mce:Keyword"></xs:selector>
<xs:field xpath="@id"/>
</xs:key>
<xs:key name="UniqueResourceIdRef">
<xs:selector xpath="mce:LocalizedStrings/mce:Resource"/>
<xs:field xpath="@idRef"/>
</xs:key>
<xs:keyref name="ReferencedRuleMustExist" refer="mce:UniqueRuleId">
<xs:selector xpath="mce:LocalizedStrings/mce:Resource"/>
<xs:field xpath="@idRef"/>
</xs:keyref>
<xs:keyref name="RuleMustHaveResource" refer="mce:UniqueResourceIdRef">
<xs:selector xpath="mce:Entity|mce:Affinity"/>
<xs:field xpath="@id"/>
</xs:keyref>
</xs:element>
</xs:sequence>
</xs:complexType>
<xs:complexType name="RulePackType">
<xs:sequence>
<xs:element name="Version" type="mce:VersionType"/>
<xs:element name="Publisher" type="mce:PublisherType"/>
<xs:element name="Details" type="mce:DetailsType">
<xs:key name="UniqueLangCodeInLocalizedDetails">
<xs:selector xpath="mce:LocalizedDetails"/>
<xs:field xpath="@langcode"/>
</xs:key>
<xs:keyref name="DefaultLangCodeMustExist" refer="mce:UniqueLangCodeInLocalizedDetails">
<xs:selector xpath="."/>
<xs:field xpath="@defaultLangCode"/>
</xs:keyref>
</xs:element>
<xs:element name="Encryption" type="mce:EncryptionType" minOccurs="0" maxOccurs="1"/>
</xs:sequence>
<xs:attribute name="id" type="mce:GuidType" use="required"/>
</xs:complexType>
<xs:complexType name="VersionType">
<xs:attribute name="major" type="xs:unsignedShort" use="required"/>
<xs:attribute name="minor" type="xs:unsignedShort" use="required"/>
<xs:attribute name="build" type="xs:unsignedShort" use="required"/>
<xs:attribute name="revision" type="xs:unsignedShort" use="required"/>
</xs:complexType>
<xs:complexType name="PublisherType">
<xs:attribute name="id" type="mce:GuidType" use="required"/>
</xs:complexType>
<xs:complexType name="LocalizedDetailsType">
<xs:sequence>
<xs:element name="PublisherName" type="mce:NameType"/>
<xs:element name="Name" type="mce:RulePackNameType"/>
<xs:element name="Description" type="mce:OptionalNameType"/>
</xs:sequence>
<xs:attribute name="langcode" type="mce:LangType" use="required"/>
</xs:complexType>
<xs:complexType name="DetailsType">
<xs:sequence>
<xs:element name="LocalizedDetails" type="mce:LocalizedDetailsType" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="defaultLangCode" type="mce:LangType" use="required"/>
</xs:complexType>
<xs:complexType name="EncryptionType">
<xs:sequence>
<xs:element name="Key" type="xs:normalizedString"/>
<xs:element name="IV" type="xs:normalizedString"/>
</xs:sequence>
</xs:complexType>
<xs:simpleType name="RulePackNameType">
<xs:restriction base="xs:token">
<xs:minLength value="1"/>
<xs:maxLength value="64"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="NameType">
<xs:restriction base="xs:normalizedString">
<xs:minLength value="1"/>
<xs:maxLength value="256"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="OptionalNameType">
<xs:restriction base="xs:normalizedString">
<xs:minLength value="0"/>
<xs:maxLength value="256"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="RestrictedTermType">
<xs:restriction base="xs:string">
<xs:minLength value="1"/>
<xs:maxLength value="512"/>
</xs:restriction>
</xs:simpleType>
<xs:complexType name="RulesType">
<xs:sequence>
<xs:choice maxOccurs="unbounded">
<xs:element name="Entity" type="mce:EntityType"/>
<xs:element name="Affinity" type="mce:AffinityType"/>
</xs:choice>
<xs:choice minOccurs="0" maxOccurs="unbounded">
<xs:element name="Regex" type="mce:RegexType"/>
<xs:element name="Keyword" type="mce:KeywordType"/>
</xs:choice>
<xs:element name="LocalizedStrings" type="mce:LocalizedStringsType"/>
</xs:sequence>
</xs:complexType>
<xs:complexType name="EntityType">
<xs:sequence>
<xs:element name="Pattern" type="mce:PatternType" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="id" type="mce:GuidType" use="required"/>
<xs:attribute name="patternsProximity" type="mce:ProximityType" use="required"/>
<xs:attribute name="recommendedConfidence" type="mce:ProbabilityType"/>
<xs:attribute name="workload" type="mce:WorkloadType"/>
</xs:complexType>
<xs:complexType name="PatternType">
<xs:sequence>
<xs:element name="IdMatch" type="mce:IdMatchType"/>
<xs:choice minOccurs="0" maxOccurs="unbounded">
<xs:element name="Match" type="mce:MatchType"/>
<xs:element name="Any" type="mce:AnyType"/>
</xs:choice>
</xs:sequence>
<xs:attribute name="confidenceLevel" type="mce:ProbabilityType" use="required"/>
</xs:complexType>
<xs:complexType name="AffinityType">
<xs:sequence>
<xs:element name="Evidence" type="mce:EvidenceType" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="id" type="mce:GuidType" use="required"/>
<xs:attribute name="evidencesProximity" type="mce:ProximityType" use="required"/>
<xs:attribute name="thresholdConfidenceLevel" type="mce:ProbabilityType" use="required"/>
<xs:attribute name="workload" type="mce:WorkloadType"/>
</xs:complexType>
<xs:complexType name="EvidenceType">
<xs:sequence>
<xs:choice maxOccurs="unbounded">
<xs:element name="Match" type="mce:MatchType"/>
<xs:element name="Any" type="mce:AnyType"/>
</xs:choice>
</xs:sequence>
<xs:attribute name="confidenceLevel" type="mce:ProbabilityType" use="required"/>
</xs:complexType>
<xs:complexType name="IdMatchType">
<xs:attribute name="idRef" type="xs:string" use="required"/>
</xs:complexType>
<xs:complexType name="MatchType">
<xs:attribute name="idRef" type="xs:string" use="required"/>
</xs:complexType>
<xs:complexType name="AnyType">
<xs:sequence>
<xs:choice maxOccurs="unbounded">
<xs:element name="Match" type="mce:MatchType"/>
<xs:element name="Any" type="mce:AnyType"/>
</xs:choice>
</xs:sequence>
<xs:attribute name="minMatches" type="xs:nonNegativeInteger" default="1"/>
<xs:attribute name="maxMatches" type="xs:nonNegativeInteger" use="optional"/>
</xs:complexType>
<xs:simpleType name="ProximityType">
<xs:restriction base="xs:positiveInteger">
<xs:minInclusive value="1"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="ProbabilityType">
<xs:restriction base="xs:integer">
<xs:minInclusive value="1"/>
<xs:maxInclusive value="100"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="WorkloadType">
<xs:restriction base="xs:string">
<xs:enumeration value="Exchange"/>
<xs:enumeration value="Outlook"/>
</xs:restriction>
</xs:simpleType>
<xs:complexType name="RegexType">
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="id" type="xs:token" use="required"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
<xs:complexType name="KeywordType">
<xs:sequence>
<xs:element name="Group" type="mce:GroupType" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="id" type="xs:token" use="required"/>
</xs:complexType>
<xs:complexType name="GroupType">
<xs:sequence>
<xs:choice>
<xs:element name="Term" type="mce:TermType" maxOccurs="unbounded"/>
</xs:choice>
</xs:sequence>
<xs:attribute name="matchStyle" default="word">
<xs:simpleType>
<xs:restriction base="xs:NMTOKEN">
<xs:enumeration value="word"/>
<xs:enumeration value="string"/>
</xs:restriction>
</xs:simpleType>
</xs:attribute>
</xs:complexType>
<xs:complexType name="TermType">
<xs:simpleContent>
<xs:extension base="mce:RestrictedTermType">
<xs:attribute name="caseSensitive" type="xs:boolean" default="false"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
<xs:complexType name="LocalizedStringsType">
<xs:sequence>
<xs:element name="Resource" type="mce:ResourceType" maxOccurs="unbounded">
<xs:key name="UniqueLangCodeUsedInNamePerResource">
<xs:selector xpath="mce:Name"/>
<xs:field xpath="@langcode"/>
</xs:key>
<xs:key name="UniqueLangCodeUsedInDescriptionPerResource">
<xs:selector xpath="mce:Description"/>
<xs:field xpath="@langcode"/>
</xs:key>
</xs:element>
</xs:sequence>
</xs:complexType>
<xs:complexType name="ResourceType">
<xs:sequence>
<xs:element name="Name" type="mce:ResourceNameType" maxOccurs="unbounded"/>
<xs:element name="Description" type="mce:DescriptionType" minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="idRef" type="mce:GuidType" use="required"/>
</xs:complexType>
<xs:complexType name="ResourceNameType">
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="default" type="xs:boolean" default="false"/>
<xs:attribute name="langcode" type="mce:LangType" use="required"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
<xs:complexType name="DescriptionType">
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="default" type="xs:boolean" default="false"/>
<xs:attribute name="langcode" type="mce:LangType" use="required"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
</xs:schema>