Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Rozdíly v konfiguracích hardwaru, softwaru a clusteru a také různé požadavky aplikací na dobu provozu a výkon vyžadují konkrétní konfiguraci pro hodnoty časového limitu zapůjčení, clusteru a kontroly stavu. Některé aplikace a úlohy vyžadují agresivnější monitorování, aby se omezil výpadek po těžkých selháních. Jiné vyžadují větší toleranci pro přechodné problémy se sítí a čekají od vysokého využití prostředků a jsou v pořádku s pomalejším převzetím služeb při selhání.
K detekci selhání pracuje více služeb na každém uzlu. Služba clusteru může zjistit ztrátu kvora, knihovna DLL prostředků může zjistit problém zjištěný detekcí stavu AlwaysOn nebo ruční převzetí služeb při selhání může být zahájeno přímo v primární instanci. Služba clusteru, hostitel prostředků a instance SQL Serveru se vzájemně synchronizují přes RPC, sdílenou paměť a T-SQL. Ve většině scénářů tyto služby úspěšně komunikují, ale tato komunikace není dokonale spolehlivá ani mezi službami na stejném počítači. Kromě toho skupina dostupnosti (AG) musí být schopná odolat událostem v celém systému, jako jsou selhání sítě a disku, což může bránit komunikaci nebo přerušení funkčnosti. U mnoha případů selhání a bez plně spolehlivé komunikace mezi službami závisí skupina dostupnosti na různých mechanismech detekce převzetí služeb při selhání, aby zjistila selhání nezávisle na sobě a reagovala na ně, takže stav clusteru je vždy konzistentní pro všechny uzly.
Vylepšená diagnostika vypršení časového limitu kontroly stavu SQL Serveru 2025
Omezení prostředků, jako je vysoké využití procesoru, latence disku nebo vyčerpání paměti, můžou aktivovat časový limit zapůjčení skupiny dostupnosti AlwaysOn. Když se v protokolu clusteru hlásí časový limit zapůjčení, v protokolu clusteru se v protokolu clusteru s podporou převzetí služeb při selhání a v protokolu clusteru s podporou převzetí služeb při selhání a vypršení časového limitu zapůjčení hlásí nejnovější data monitorování výkonu pro využití procesoru, využití paměti a latenci čtení a zápisu disku.
Omezení prostředků můžou také aktivovat časový limit kontroly stavu. Počínaje SQL Serverem 2025 (17.x) jsou nyní stejné čítače monitorování výkonu hlášeny v protokolu clusteru pro převzetí služeb při selhání ve Windows při zjištění časového limitu kontroly stavu, podobně jako diagnostický výstup při vypršení časového limitu výpůjčky.
Následuje ukázka vylepšeného výstupu protokolu clusteru s podporou převzetí služeb při selhání systému Windows pro vypršení časového limitu kontroly stavu:
[Verbose] 000035b8.00001a64::2024/04/18-23:56:35.536 ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, diagnostics heartbeat is lost
[Verbose] 000035b8.00001a64::2024/04/18-23:56:35.536 WARN [RES] SQL Server Availability Group: [hadrag] AG health check failed, logging perf counter data collected so far
[Verbose] 000035b8.00001a64::2024/04/18-23:56:35.536 WARN [RES] SQL Server Availability Group: [hadrag] Date/Time, Processor time(%), Available memory(bytes), Avg disk read(secs), Avg disk write(secs)
[Verbose] 000035b8.00001a64::2024/04/18-23:56:35.536 WARN [RES] SQL Server Availability Group: [hadrag] 4/18/2024 23:55:25.0, 21.857418, 3248349184.000000, 0.000000, 0.000253
[Verbose] 000035b8.00001a64::2024/04/18-23:56:35.536 WARN [RES] SQL Server Availability Group: [hadrag] 4/18/2024 23:55:35.0, 11.442071, 3255394304.000000, 0.000907, 0.000382
[Verbose] 000035b8.00001a64::2024/04/18-23:56:35.536 WARN [RES] SQL Server Availability Group: [hadrag] 4/18/2024 23:55:45.0, 9.979768, 3253981184.000000, 0.000415, 0.000549
[Verbose] 000035b8.00001a64::2024/04/18-23:56:35.536 WARN [RES] SQL Server Availability Group: [hadrag] 4/18/2024 23:55:55.0, 9.762850, 3251232768.000000, 0.001989, 0.000638
[Verbose] 000035b8.00001a64::2024/04/18-23:56:35.536 WARN [RES] SQL Server Availability Group: [hadrag] 4/18/2024 23:56:5.0, 9.827234, 3250462720.000000, 0.002250, 0.001418
Uzel clusteru a detekce prostředků
Každý uzel v clusteru spouští jednu službu clusteru, která provozuje cluster s podporou převzetí služeb při selhání a monitoruje všechny prostředky clusteru. Hostitel prostředků funguje jako samostatný proces a je rozhraním mezi clusterovou službou a prostředky clusteru. Hostitel prostředků provádí operace s prostředky clusteru při volání službou clusteru. Aplikace pracující s clustery, jako je SQL Server, poskytují vlastní rozhraní monitorování prostředků prostřednictvím knihoven DLL prostředků. Knihovna DLL prostředků implementuje online a offline operace a monitorování stavu pro vlastní prostředky. Hostitel prostředků je podřízený proces služby clusteru a je zabit pokaždé, když je služba clusteru zabita.
Knihovna DLL prostředků skupiny dostupnosti pro SQL Server určuje stav skupiny dostupnosti na základě mechanismu zapůjčení skupiny dostupnosti a detekce stavu AlwaysOn. Knihovna DLL prostředků skupiny dostupnosti zpřístupňuje stav prostředku prostřednictvím IsAlive operace. Monitorování prostředků se dotazuje IsAlive v intervalu prezenčního signálu clusteru, který je nastavený CrossSubnetDelay hodnotami v rámci celého clusteru a SameSubnetDelay clusteru. Na primárním uzlu služba clusteru zahájí převzetí služeb při selhání vždy, když IsAlive volání knihovny DLL prostředků vrátí, že skupina dostupnosti není v pořádku.
Služba clusteru odesílá prezenčních signálů do jiných uzlů v clusteru a bere na vědomí prezenčních signálů přijatých od nich. Když uzel zjistí selhání komunikace z řady nepotvrděných prezenčních signálů, vysílá zprávu, která způsobí, že všechny dosažitelné uzly odsouhlasí jejich zobrazení stavu uzlu clusteru. Tato událost, označovaná jako událost regroup, udržuje konzistenci stavu clusteru napříč uzly. Pokud dojde ke ztrátě kvora po události opětovného seskupení, všechny prostředky clusteru, včetně skupin AG v tomto oddílu, se převedou do offline režimu. Všechny uzly v tomto oddílu se přejdou do stavu překladu. Pokud existuje oddíl, který obsahuje kvorum, skupina dostupnosti se přiřadí k jednomu uzlu v oddílu a stane se primární replikou, zatímco všechny ostatní uzly se stanou sekundárními replikami.
Detekce stavu AlwaysOn
Knihovna DLL prostředků AlwaysOn monitoruje stav interních komponent SYSTÉMU SQL Server.
sp_server_diagnostics hlásí stav těchto komponent SQL Serveru v intervalu řízeném HealthCheckTimeout.
sp_server_diagnostics hlásí stav pěti komponent na úrovni instance: systém, prostředek, zpracování dotazů, subsystém io a události. Také hlásí stav každé skupiny dostupnosti. Při každé aktualizaci knihovna DLL prostředků aktualizuje stav prostředku skupiny dostupnosti na základě úrovně selhání skupiny dostupnosti. Když data vrátí sp_server_diagnostics, zobrazí se každá komponenta buď v čistém, upozornění, chybě nebo neznámém stavu s některými daty XML popisující stav komponenty. Pro detekci stavu knihovna DLL prostředků provede akci pouze v případě, že je komponenta v chybovém stavu.
Pokud se zjišťování stavu nepodaří nahlásit aktualizaci knihovny DLL prostředků pro více intervalů, zjistí se, že skupina dostupnosti není v pořádku a bude hlásit selhání volání IsAlive .
Mechanismus zapůjčení
Na rozdíl od jiných mechanismů převzetí služeb při selhání hraje instance SQL Serveru aktivní roli v mechanismu zapůjčení. Mechanismus zapůjčení se používá jako Looks-Alive ověřování mezi hostitelem prostředků clusteru a procesem SQL Serveru. Tento mechanismus se používá k zajištění, že obě strany (služba clusteru a služba SQL Serveru) jsou často v kontaktu, kontrolují stav sebe navzájem a nakonec brání situaci rozděleného mozku. Při přenesení skupiny dostupnosti do režimu online jako primární repliky instance SQL Serveru vytvoří vyhrazené vlákno pracovního procesu zapůjčení skupiny dostupnosti. Pracovní proces zapůjčení sdílí malou oblast paměti s hostitelem prostředků, který obsahuje události obnovení zapůjčení a zastavení zapůjčení. Pracovník zapůjčení a hostitel prostředků pracují cyklickým způsobem, signalizují příslušnou událost prodloužení zapůjčení a pak spí, čekající na to, aby druhá strana signalizovala vlastní událost prodlužování zapůjčení nebo zastavila událost. Hostitel prostředků i vlákno zapůjčení SQL Serveru udržují hodnotu time-to-live, která se aktualizuje při každém probuzení vlákna po signálu jiným vláknem. Pokud se během čekání na signál dosáhne doby trvání, zapůjčení vyprší a pak replika přejde do stavu překladu dané skupiny dostupnosti. Pokud je událost zastavení zapůjčení signalována, replika přejde na roli překladu.
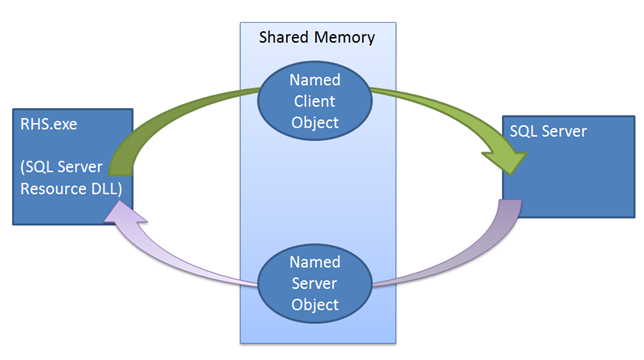
Mechanismus zapůjčení vynucuje synchronizaci mezi SQL Serverem a clusterem s podporou převzetí služeb při selhání systému Windows Server. Při vydání příkazu převzetí služeb při selhání služba clusteru Offline zavolá knihovnu DLL prostředků aktuální primární repliky. Knihovna DLL prostředků se nejprve pokusí skupinu dostupnosti převést do offline režimu pomocí uložené procedury. Pokud tato uložená procedura selže nebo vyprší časový limit, zobrazí se chyba zpět do služby clusteru, která pak vydá příkaz ukončení. Ukončení se znovu pokusí spustit stejnou uloženou proceduru, ale cluster tentokrát nečeká, až knihovna DLL prostředků oznámí úspěch nebo selhání před přenesením skupiny dostupnosti do režimu online na novou repliku. Pokud se toto druhé volání procedury nezdaří, musí hostitel prostředků spoléhat na mechanismus zapůjčení, aby instanci převedla do offline režimu. Když je volána knihovna DLL prostředků, aby se skupina dostupnosti offline, knihovna DLL prostředků signalizuje událost zastavení zapůjčení a probuzení pracovního vlákna zapůjčení SQL Serveru, aby se skupina dostupnosti převedla do režimu offline. I když tato událost zastavení není signalizovat, zapůjčení vyprší a replika přejde do stavu překladu.
Zapůjčení je primárně synchronizační mechanismus mezi primární instancí a clusterem, ale může také vytvořit podmínky selhání, kdy jinak není potřeba převzít služby při selhání. Například vysoké využití procesoru, mimo paměť (nedostatek virtuální paměti, stránkování procesů), proces SQL nereaguje při generování výpisu paměti, systém nereaguje, cluster (WSFC) přejde do režimu offline (například kvůli ztrátě kvora), může zabránit obnovení zapůjčení z instance SQL a způsobit restartování nebo převzetí služeb při selhání.
Pokyny pro hodnoty časového limitu clusteru
Pečlivě zvažte kompromisy a seznamte se s důsledky použití méně agresivního monitorování clusteru SQL Serveru. Zvýšení hodnot časového limitu clusteru zvyšuje odolnost vůči přechodným problémům se sítí, ale zpomaluje reakce na těžké selhání. Zvýšení časových limitů pro řešení tlaku prostředků nebo velké geografické latence, zvýší se doba zotavení z pevných nebo nerenovovatelných selhání. I když je to přijatelné pro mnoho aplikací, není to ideální ve všech případech.
Výchozí nastavení jsou optimalizovaná pro rychlé reakce na příznaky těžkých selhání a omezení výpadků, ale tato nastavení můžou být pro určité úlohy a konfigurace příliš agresivní. Nedoporučuje se snížit žádnou z LeaseTimeouthodnot , , CrossSubnetDelayCrossSubnetThreshold, SameSubnetDelay, SameSubnetThresholdnebo HealthCheckTimeout nad rámec jejich výchozích hodnot. Správná nastavení pro každé nasazení se liší a zjišťování pravděpodobně trvá delší dobu. Při provádění změn některé z těchto hodnot je proveďte postupně a s ohledem na vztahy a závislosti mezi těmito hodnotami.
Vztah mezi vypršením časového limitu clusteru a vypršením časového limitu zapůjčení
Primární funkcí mechanismu zapůjčení je převést prostředek SQL Serveru do offline režimu, pokud služba clusteru nemůže komunikovat s instancí při převzetí služeb při selhání do jiného uzlu. Když cluster provede offline operaci s prostředkem clusteru skupiny dostupnosti, služba clusteru provede volání RPC, aby rhs.exe převeďte prostředek do offline režimu. Knihovna DLL prostředků používá uložené procedury k tomu, aby SQL Server přešel do režimu offline, ale tato uložená procedura může selhat nebo vypršel časový limit. Hostitel prostředků také během offline volání zastaví vlastní vlákno pro prodloužení zapůjčení. V nejhorším případě SQL Server způsobí vypršení zapůjčení 1/2 * Zapůjčení a přechod instance do stavu překladu. Převzetí služeb při selhání může iniciovat několik různých stran, ale je důležité, aby zobrazení stavu clusteru bylo konzistentní napříč clusterem a instancemi SQL Serveru. Představte si například scénář, kdy primární instance ztratí připojení ke zbytku clusteru. Každý uzel v clusteru určuje selhání v podobných časech kvůli hodnotám časového limitu clusteru, ale primární uzel může komunikovat s primární instancí SQL Serveru, aby ji vynutil předat primární roli.
Z pohledu primárního uzlu služba clusteru ztratila kvorum a služba se začne ukončovat. Služba clusteru vydá volání RPC hostiteli prostředků za účelem ukončení procesu. Toto ukončování volání zodpovídá za offline převzetí skupiny dostupnosti v instanci SQL Serveru. Toto offline volání se provádí prostřednictvím T-SQL, ale nezaručuje, že připojení bude úspěšně navázáno mezi SQL a knihovnou DLL prostředků.
Z pohledu zbytku clusteru aktuálně neexistuje žádná primární replika, takže cluster hlasuje a vytvoří jeden nový primární pro zbývající uzly v clusteru. Pokud uložená procedura, která byla volána knihovnou DLL prostředků, selže nebo vyprší časový limit, může být cluster ohrožený rozděleným scénářem mozku.
Časový limit zapůjčení zabraňuje rozdělení scénářů mozku v případě chyb komunikace. I když veškerá komunikace selže, proces knihovny DLL prostředků se ukončí a nebude moci aktualizovat zapůjčení. Jakmile zapůjčení vyprší, skupina dostupnosti se sama přenese do offline režimu. Instance SQL Serveru musí mít na paměti, že už není hostitelem primární repliky, než cluster vytvoří novou repliku. Vzhledem k tomu, že zbytek clusteru, který je zodpovědný za volbu nové primární repliky, nemá žádný způsob koordinace s aktuální primární replikou, hodnoty časového limitu zajistí, že se nová primární replika nenaváže předtím, než se aktuální primární server přenese do offline režimu.
Při převzetí služeb při selhání clusteru musí instance SQL Serveru, který je hostitelem předchozí primární repliky, přejít do stavu překladu, aby byla nová primární replika online. Vlákno zapůjčení SQL Serveru má v libovolném okamžiku zbývající dobu naživo 1/2 * Zapůjčení, protože při každém prodloužení zapůjčení se nový časový limit aktualizuje na LeaseInterval dobu 1/2 * Zapůjčení. Pokud služba clusteru nebo hostitel prostředků zastaví nebo ukončí bez signalizace události zastavení zapůjčení, cluster bude po milisekundách deklarovat neaktivní SameSubnetThreshold\ SameSubnetDelay primární uzel. V této době musí platnost zapůjčení vypršet, aby primární server byl zaručený jako offline. Protože maximální časový limit zapůjčení je 1/2 * LeaseTimeout, 1/2 * LeaseTimeout musí být menší nežSameSubnetThreshold * SameSubnetDelay .
SameSubnetThreshold \<= CrossSubnetThreshold a SameSubnetDelay \<= CrossSubnetDelay měl by být pravdivý pro všechny clustery SQL Serveru.
Operace vypršení časového limitu kontroly stavu
Časový limit kontroly stavu je flexibilnější, protože na něm přímo nezávisí žádný jiný mechanismus převzetí služeb při selhání. Výchozí hodnota 30 sekund nastaví sp_server_diagnostics interval na 10 sekund s minimální hodnotou po dobu 15 sekund pro časový limit a 5sekundový interval. Obecně platí, že sp_server_diagnostics interval aktualizace je vždy 1/3 * HealthCheckTimeout. Pokud knihovna DLL prostředků neobdrží v intervalu novou sadu dat o stavu, bude nadále používat data o stavu z předchozího intervalu k určení aktuálního stavu skupiny dostupnosti a stavu instance. Zvýšení hodnoty časového limitu kontroly stavu zvyšuje odolnost primárního tlaku procesoru, což může zabránit sp_server_diagnostics v poskytování nových dat v každém intervalu, ale spoléhá na zastaralé kontroly stavu dat delší dobu. Bez ohledu na hodnotu časového limitu se po přijetí dat označujících, že replika není v pořádku, další IsAlive volání vrátí, že instance není v pořádku a služba clusteru zahájí převzetí služeb při selhání.
Úroveň stavu selhání skupiny dostupnosti změní podmínky selhání pro kontrolu stavu. Pokud je prvek skupiny dostupnosti nahlášený v sp_server_diagnostics pořádku, v případě jakékoli úrovně selhání se kontrola stavu nezdaří. Každá úroveň dědí všechny podmínky selhání z úrovní pod ní.
| Úroveň | Podmínka, pod kterou je instance považována za mrtvou |
|---|---|
| 1: OnServerDown | Kontrola stavu neprovede žádnou akci, pokud některé prostředky kromě skupiny dostupnosti selžou. Pokud data skupiny dostupnosti nejsou přijata v 5 intervalech nebo 5/3 * HealthCheckTimeout |
| 2: OnServerUnresponsive | Pokud nejsou přijata sp_server_diagnostics žádná data pro HealthCheckTimeout |
| 3: OnCriticalServerError | (Výchozí) Pokud systémová komponenta hlásí chybu |
| 4: OnModerateServerError | Pokud komponenta prostředků hlásí chybu |
| 5: PřiJakýchkoliKvalifikovanýchPodmínkáchSelhání | Pokud komponenta zpracování dotazů hlásí chybu |
Aktualizace hodnot časového limitu clusteru a AlwaysOn
Hodnoty clusteru
V konfiguraci WSFC jsou čtyři hodnoty, které zodpovídají za určení hodnot časového limitu clusteru:
- ZpožděníStejnéPodsítě
- Prahová hodnota pro stejnou podsíť
- Zpoždění mezi podsítěmi
- HranicePropojeníMezisubnety
Hodnoty zpoždění určují dobu čekání mezi prezenčními signály ze služby clusteru a prahové hodnoty nastavují počet prezenčních signálů, které nemohou přijmout žádné potvrzení z cílového uzlu nebo prostředku, než je objekt deklarován clusterem. Pokud mezi uzly ve stejné podsíti není úspěšný prezenční signál pro více než SameSubnetDelay \* SameSubnetThreshold milisekund, určí se uzel jako mrtvý. Totéž platí pro komunikaci mezi podsítěmi pomocí hodnot mezi podsítěmi.
Pokud chcete zobrazit seznam všech aktuálních hodnot clusteru, otevřete na libovolném uzlu v cílovém clusteru terminál PowerShellu se zvýšenými oprávněními. Spusťte následující příkaz:
Get-Cluster | fl *
Pokud chcete aktualizovat některou z těchto hodnot, spusťte v terminálu PowerShellu se zvýšenými oprávněními následující příkaz:
(Get-Cluster).<ValueName> = <NewValue>
Při zvýšení zpoždění * Prahový produkt, aby byl časový limit clusteru odolnější, je efektivnější nejprve zvýšit hodnotu zpoždění před zvýšením prahové hodnoty. Zvýšením zpoždění se zvýší doba mezi každým prezenčních signálem. Více času mezi prezenčními signály poskytuje více času pro přechodné problémy se sítí, aby se vyřešily a snížily zahlcení sítě vzhledem k odesílání více prezenčních signálů ve stejném období.
Časový limit zapůjčení
Mechanismus zapůjčení je řízen jednou hodnotou specifickou pro každou skupinu dostupnosti v clusteru WSFC. Časový limit zapůjčení může vést k následujícím chybám:
Error 35201:
A connection timeout has occurred while attempting to establish a connection to availability replica 'replicaname'
Error 35206:
A connection timeout has occurred on a previously established connection to availability replica 'replicaname'
Pokud chcete upravit hodnotu časového limitu zapůjčení, použijte Správce clusteru s podporou převzetí služeb při selhání a postupujte takto:
Na kartě Role vyhledejte cílovou roli skupiny dostupnosti. Vyberte cílovou roli skupiny dostupnosti.
Klikněte pravým tlačítkem myši na prostředek skupiny dostupnosti v dolní části okna a vyberte Vlastnosti.
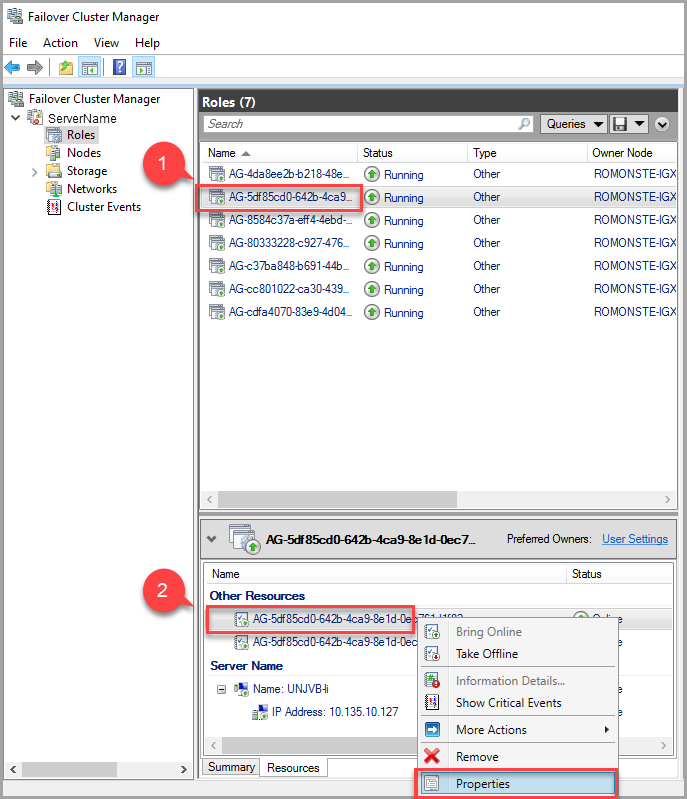
V automaticky otevíraném okně přejděte na kartu vlastností a zobrazte seznam hodnot specifických pro tuto agekci. Vyberte hodnotu Zapůjčení a změňte ji.
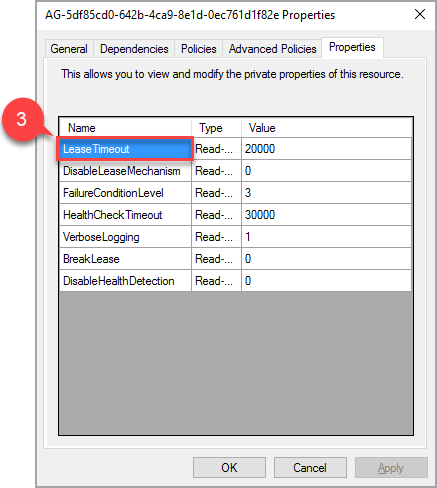
V závislosti na konfiguraci skupiny dostupnosti můžou existovat další prostředky pro naslouchací procesy, sdílené disky, sdílené složky atd., tyto prostředky nevyžadují žádnou další konfiguraci.
Poznámka:
Nová hodnota vlastnosti LeaseTimeout se projeví poté, co se prostředek přenese do offline režimu a znovu se přenese do režimu online.
Hodnoty kontroly stavu
Dvě hodnoty řídí kontrolu stavu AlwaysOn: FailureConditionLevel a HealthCheckTimeout. FailureConditionLevel označuje úroveň tolerance ke konkrétním stavům selhání hlášeným sp_server_diagnostics a HealthCheckTimeout konfiguruje dobu, po kterou může knihovna DLL prostředků přejít bez přijetí aktualizace z sp_server_diagnostics. Interval sp_server_diagnostics aktualizace je vždy HealthCheckTimeout / 3.
Ke konfiguraci úrovně podmínky převzetí služeb při selhání použijte FAILURE_CONDITION_LEVEL = <n> možnost CREATE příkazu nebo ALTERAVAILABILITY GROUP příkazu, kde <n> je celé číslo mezi 1 a 5. Následující příkaz nastaví úroveň podmínky selhání na 1 pro AG1:
ALTER AVAILABILITY GROUP AG1 SET (FAILURE_CONDITION_LEVEL = 1);
Pokud chcete nakonfigurovat časový limit kontroly stavu, použijte HEALTH_CHECK_TIMEOUT možnost příkazůCREATE.ALTERAVAILABILITY GROUP Následující příkaz nastaví časový limit kontroly stavu na 60 000 milisekund pro ag1:
ALTER AVAILABILITY GROUP AG1 SET (HEALTH_CHECK_TIMEOUT =60000);
Shrnutí pokynů k vypršení časového limitu
Snížení všech hodnot časového limitu pod jejich výchozí hodnoty se nedoporučuje.
Interval zapůjčení (1/2 * Zapůjčení) musí být kratší než SameSubnetThreshold * SameSubnetDelay.
SameSubnetThreshold <= CrossSubnetThreshold
SameSubnetDelay <= CrossSubnetDelay
| Nastavení časového limitu | Účel | Mezi | Použití | IsAlive & LooksAlive | Příčiny | Výsledek |
|---|---|---|---|---|---|---|
| Časový limit zapůjčení Výchozí hodnota: 20000 |
Zabránit rozdělení mozku | Primární do clusteru (HADR) |
Objekty událostí Systému Windows | Používá se v obou | Operační systém nereaguje, nedostatek virtuální paměti, stránkování pracovní sady, generování výpisu paměti, protokolovaný procesor, WSFC mimo provoz (ztráta kvora) | Prostředek skupiny dostupnosti offline– online, převzetí služeb při selhání |
| Časový limit relace Výchozí hodnota: 10000 |
Informace o problému komunikace mezi primárním a sekundárním | Sekundární na primární (HADR) |
Sokety TCP (zprávy odeslané přes koncový bod DBM) | Používá se v žádném z nich | Síťová komunikace, Problémy se sekundárním – mimo provoz, nereaguje operační systém, kolize prostředků |
Sekundární – ODPOJENO |
| Časový limit kontroly stavu Výchozí hodnota: 30000 |
Určení časového limitu při pokusu o zjištění stavu primární repliky | Cluster na primární (FCI a HADR) |
T-SQL sp_server_diagnostics | Používá se v obou | Splněné podmínky selhání, operační systém nereaguje, nedostatek virtuální paměti, oříznutí pracovní sady, generování výpisu paměti, WSFC (ztráta kvora), problémy s plánovačem (neaktivní uzamčené plánovače) | Prostředek skupiny dostupnosti offline nebo převzetí služeb při selhání, restartování nebo převzetí služeb při selhání FCI |