Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
platí pro:![]() SQL Server
SQL Server
Počínaje SQL Serverem 2016 je při konfiguraci skupiny dostupnosti AlwaysOn dostupná možnost detekce stavu na úrovni databáze (DB_FAILOVER). Detekce stavu na úrovni databáze zaznamená, když databáze už není ve stavu online nebo když dojde k nějaké chybě, a aktivuje automatické převzetí služeb skupiny dostupnosti. Mezi příklady, které mohou aktivovat detekci zdraví, patří databáze v podezřelém režimu, databáze je offline, databáze v obnovování (nepodařilo se obnovit). Další informace naleznete v tématu State column in sys.databases.
Detekce stavu na úrovni databáze je povolená pro skupinu dostupnosti jako celek, a proto detekce stavu na úrovni databáze monitoruje každou databázi ve skupině dostupnosti. Nelze ji povolit selektivně pro konkrétní databáze ve skupině dostupnosti.
Výhody možnosti detekce stavu na úrovni databáze
Možnost detekce stavu na úrovni databáze skupiny dostupnosti se obecně doporučuje jako vhodná možnost, která vám pomůže zaručit vysokou dostupnost vašich databází. Měli byste zvážit jeho zapnutí pro všechny skupiny dostupnosti. Pokud vaše aplikace závisí na několika databázích, které mají být vysoce dostupné, seskupte je do skupiny dostupnosti se zapnutou možností stavu databáze.
Pokud by například SQL Server nemohl zapisovat do souboru transakčního protokolu pro jednu z databází, změnil se stav této databáze tak, aby značil selhání, a skupina dostupnosti brzy převezme služby při selhání a vaše aplikace se může znovu připojit a pokračovat v práci s minimálním přerušením, jakmile budou databáze znovu online.
Povolení detekce stavu na úrovni databáze
I když se obecně doporučuje, možnost Stav databáze je ve výchozím nastavení vypnutá, aby se zachovala zpětná kompatibilita s výchozím nastavením v předchozích verzích.
Existuje několik snadných způsobů, jak povolit nastavení detekce stavu na úrovni databáze:
V aplikaci SQL Server Management Studio se připojte k databázovému stroji SQL Serveru. V okně Průzkumník objektů klikněte pravým tlačítkem myši na uzel Always On – vysoká dostupnost a spusťte Průvodce novou skupinou dostupnosti. Na stránce Zadat název zaškrtněte políčko Detekce stavu na úrovni databáze . Potom dokončete zbývající stránky průvodce.
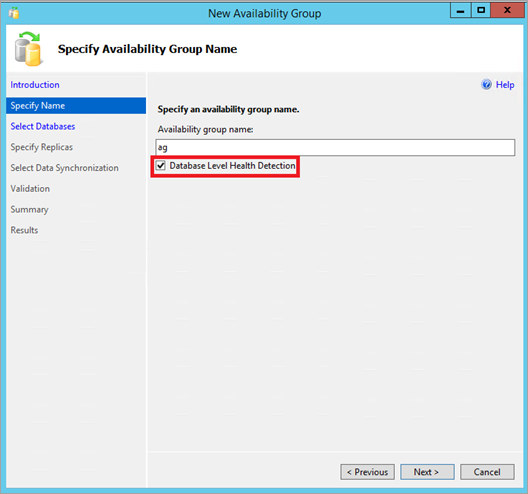
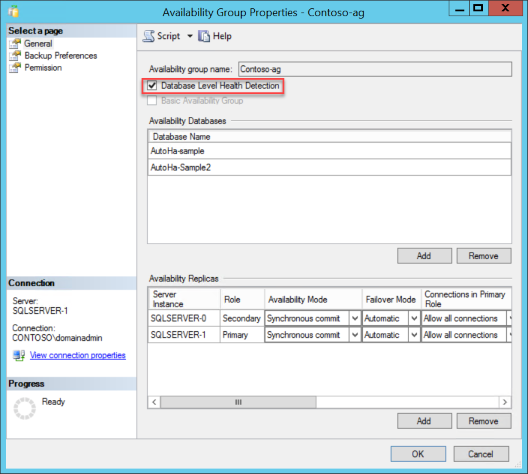
Umožňuje zobrazit vlastnosti existující skupiny dostupnosti v aplikaci SQL Server Management Studio. Připojte se k SQL Serveru. Pomocí okna Průzkumníka objektů rozbalte uzel Always On High Availability. Rozbalte skupiny dostupnosti. Klikněte pravým tlačítkem na skupinu dostupnosti a zvolte Vlastnosti. Zkontrolujte možnost Detekce stavu na úrovni databáze a klikněte na OK nebo skriptujte změnu.
Transact-SQL syntaxe pro vytvoření skupiny dostupnosti. Parametr DB_FAILOVER přijímá hodnoty ON nebo OFF.
CREATE AVAILABILITY GROUP [Contoso-ag] WITH (DB_FAILOVER=ON) FOR DATABASE [AutoHa-Sample] REPLICA ON N'SQLSERVER-0' WITH (ENDPOINT_URL = N'TCP://SQLSERVER-0.DOMAIN.COM:5022', FAILOVER_MODE = AUTOMATIC, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT), N'SQLSERVER-1' WITH (ENDPOINT_URL = N'TCP://SQLSERVER-1.DOMAIN.COM:5022', FAILOVER_MODE = AUTOMATIC, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT);Transact-SQL ALTER syntaxe pro AVAILABILITY GROUP. Parametr DB_FAILOVER přijímá hodnoty ON nebo OFF.
ALTER AVAILABILITY GROUP [Contoso-ag] SET (DB_FAILOVER = ON); ALTER AVAILABILITY GROUP [Contoso-ag] SET (DB_FAILOVER = OFF);
Upozornění
Je důležité si uvědomit, že možnost detekce zdraví na úrovni databáze v současné době nepůsobí, že by SQL Server monitoroval dobu provozu disku, a SQL Server nemonitoruje přímo dostupnost souborů databáze. Pokud disková jednotka selže nebo přestane být dostupná, samo o sobě to nemusí nutně způsobit, že skupina dostupnosti automaticky přepne na záložní řešení.
Například když je databáze nečinná bez aktivních transakcí a nedochází k žádným fyzickým zápisům, a pokud se některé soubory databáze stanou nepřístupnými, SQL Server nemusí provádět žádné čtení nebo zápis I/O do těchto souborů a nemusí okamžitě změnit stav této databáze, takže by se neaktivovalo žádné automatické převzetí služeb při selhání. Později, když dojde k kontrolnímu bodu databáze nebo k fyzickému čtení či zápisu za účelem naplnění dotazu, může si SQL Server všimnout problému se souborem a reagovat změnou stavu databáze. Následně by pak skupina dostupnosti, která má zapnuté zjišťování stavu na úrovni databáze, mohla kvůli změně stavu databáze provést převzetí služeb při selhání.
Jako další příklad platí, že když databázový stroj SQL Serveru potřebuje ke splnění dotazu načíst datovou stránku, pokud je datová stránka uložená v paměti fondu vyrovnávací paměti, nemusí být ke splnění požadavku dotazu vyžadováno žádné čtení disku s fyzickým přístupem. Chybějící nebo nedostupný datový soubor proto nemusí okamžitě aktivovat automatické přehození při selhání, i když je zapnutá možnost kontroly stavu databáze, protože stav databáze není okamžitě aktualizován.
Převzetí služeb při selhání databáze je oddělené od flexibilních zásad převzetí služeb při selhání.
Detekce stavu na úrovni databáze implementuje flexibilní zásady převzetí služeb při selhání, které konfigurují prahové hodnoty stavu procesu SQL Serveru pro zásady převzetí služeb při selhání. Detekce stavu na úrovni databáze se konfiguruje pomocí parametru DB_FAILOVER, zatímco možnost skupiny dostupnosti FAILURE_CONDITION_LEVEL je oddělená pro konfiguraci detekce stavu procesu SQL Serveru. Dvě možnosti jsou nezávislé.
Správa a monitorování detekce stavu na úrovni databáze
Dynamická zobrazení správy
Zobrazení dynamické správy systému sys.availability_groups obsahuje sloupec db_failover, který označuje, zda je možnost detekce zdravotního stavu na úrovni databáze vypnutá (0) nebo zapnutá (1).
select name, db_failover from sys.availability_groups
Příklad výstupu dmv:
| název | db_failover |
|---|---|
| Contoso-ag | 1 |
Protokol chyb
Protokol chyb SQL Serveru (nebo text z sp_readerrorlog) zobrazí chybovou zprávu 41653, když skupina dostupnosti převezme služby při selhání kvůli kontrolám stavu na úrovni databáze.
Tento výňatek z protokolu chyb například ukazuje, že zápis do transakčního protokolu selhal kvůli problému s diskem, což následně vedlo k vypnutí databáze s názvem AutoHa-Sample. To aktivovalo detekci zdravotního stavu na úrovni databáze a vedlo k přepnutí skupiny dostupnosti.
2016-04-25 12:20:21.08 spid1s Chyba: 17053, Závažnost: 16, Stav: 1.
2016-04-25 12:20:21.08 spid1s SQLServerLogMgr::LogWriter: Chyba operačního systému 21 (Zařízení není připraveno.) nastala. 2016-04-25 12:20:21.08 spid1s Chyba zápisu během vyprázdnění protokolu.
2016-04-25 12:20:21.08 spid79 Chyba: 9001, Závažnost: 21, Stav: 4.
2016-04-25 12:20:21.08 spid79 Protokol pro databázi 'AutoHa-Sample' není k dispozici. V protokolu událostí zkontrolujte související chybové zprávy. Vyřešte případné chyby a restartujte databázi.
2016-04-25 12:20:21.15 spid79 Chyba: 41653, Závažnost: 21, Stav: 1.
2016-04-25 12:20:21.15 spid79 Databáze AutoHa-Sample zjistila chybu (typ chyby: 2 "DB_SHUTDOWN") způsobující selhání skupiny dostupnosti Contoso-ag. Informace o chybách, ke kterým došlo, najdete v protokolu chyb SQL Serveru. Pokud tato podmínka přetrvává, obraťte se na správce systému.
2016-04-25 12:20:21.17 spid79 Informace o stavu databáze 'AutoHa-Sample' - Hardenovaný LSN: '(34:664:1)' Potvrzený LSN: '(34:656:1)' Čas potvrzení: '25. dubna 2016 12:19'
2016-04-25 12:20:21.19 spid15s Připojení skupin Always On dostupnosti k sekundární databázi bylo ukončeno pro primární databázi 'AutoHa-Sample' na dostupnostní replice 'SQLServer-0' s ID repliky: {c4ad5ea4-8a99-41fa-893e-189154c24b49}. Toto je pouze informační zpráva. Není nutná žádná akce uživatele.
2016-04-25 12:20:21.21 spid75 Always On: Místní replika skupiny dostupnosti 'Contoso-ag' se připravuje na přechod do role řešení v reakci na požadavek z clusteru WSFC (Windows Server Failover Clustering). Toto je pouze informační zpráva. Není nutná žádná akce uživatele.
2016-04-25 12:20:21.21 spid75 Stav místní repliky dostupnosti ve skupině dostupnosti „ag“ se změnil z „PRIMARY_NORMAL“ na „RESOLVING_NORMAL“. Stav se změnil, protože skupina dostupnosti je offline. Replika je offline, protože přidružená skupina dostupnosti byla odstraněna, nebo uživatel převedl přidruženou skupinu dostupnosti offline v konzole pro správu Windows Serveru s podporou převzetí služeb při selhání (WSFC), nebo skupina dostupnosti přebíhá na jinou instanci systému SQL Server. Další informace najdete v protokolu chyb SQL Serveru, v konzoli pro správu clusterování Windows Serveru (WSFC) nebo v protokolu WSFC.
Rozšířená událost sqlserver.availability_replica_database_fault_reporting
Od SQL Serveru 2016 se definuje nová rozšířená událost, která se aktivuje detekcí stavu na úrovni databáze. Název události je sqlserver.availability_replica_database_fault_reporting
Tato událost XEvent se aktivuje pouze na primární replice. Tato událost XEvent se aktivuje, když se zjistí problém se stavem na úrovni databáze pro databázi hostovanou ve skupině dostupnosti.
Tady je příklad vytvoření relace XEvent, která zachycuje tuto událost. Protože není zadána žádná cesta, výstupní soubor XEvent by se měl nacházet ve výchozí cestě protokolu chyb SQL Serveru. Spusťte to na primární replice vaší skupiny dostupnosti:
Příklad skriptu pro rozšířenou relaci událostí
CREATE EVENT SESSION [AlwaysOn_dbfault] ON SERVER
ADD EVENT sqlserver.availability_replica_database_fault_reporting
ADD TARGET package0.event_file(SET filename=N'dbfault.xel',max_file_size=(5),max_rollover_files=(4))
WITH (MAX_MEMORY=4096 KB,EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS,MAX_DISPATCH_LATENCY=30 SECONDS,
MAX_EVENT_SIZE=0 KB,MEMORY_PARTITION_MODE=NONE,TRACK_CAUSALITY=OFF,STARTUP_STATE=ON)
GO
ALTER EVENT SESSION AlwaysOn_dbfault ON SERVER STATE=START
GO
Rozšířený výstup události
Pomocí aplikace SQL Server Management Studio se připojte k primárnímu SQL Serveru a rozbalte uzel Správa a rozbalte položku Rozšířené události. Vyhledejte relaci (AlwaysOn_dbfault byl název v ukázce výše) a rozbalte relaci, abyste viděli výstupní soubory. Vyberte výstupní soubor a soubor události se otevře na nové kartě.
Vysvětlení polí:
| Data sloupců | Description |
|---|---|
| availability_group_id | ID skupiny dostupnosti. |
| availability_group_name | Název skupiny dostupnosti. |
| identifikátor_repliky_dostupnosti | ID repliky dostupnosti. |
| název_repliky_dostupnosti | Název repliky dostupnosti. |
| název databáze | Název databáze, která hlásí chybu. |
| database_replica_id | ID databáze repliky dostupnosti. |
| repliky připravené k přepnutí | Počet sekundárních replik s automatickým převzetím služeb při selhání, které jsou synchronizované. |
| fault_type | Hlášené ID chyby. Možné hodnoty: 0 – ŽÁDNÝ 1 – Neznámé 2. Vypnutí |
| is_critical | Tato hodnota by měla vždy vrátit true pro XEvent od verze SQL Server 2016. |
V tomto příkladu výstupu ukazuje fault_type, že v dostupnostní skupině Contoso-ag došlo k události kritické povahy na replice pojmenované SQLSERVER-1 kvůli databázi AutoHa-Sample2, s typem chyby 2 – Vypnutí.
| Obor | Hodnota |
|---|---|
| ID_skupiny_dostupnosti | 24E6FE58-5EE8-4C4E-9746-491CFBB208C1 |
| availability_group_name | Contoso-ag |
| availability_replica_id | 3EAE74D1-A22F-4D9F-8E9A-DEFF99B1F4D1 |
| název repliky dostupnosti | SQLSERVER-1 |
| název databáze | AutoHa-Sample2 |
| identifikátor_repliky_databáze | 39971379-8161-4607-82E7-098590E5AE00 |
| připravené repliky pro přepnutí | 1 |
| typ_poruchy | 2 |
| je_kritický | Pravdivé |