Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
platí pro:![]() SQL Server
SQL Server
Při upgradu instance SQL Serveru, která je hostitelem skupiny dostupnosti Always On (AG), na novou verzi SQL Serveru, novou aktualizaci Service Pack nebo kumulativní aktualizaci SQL Serveru, nebo při instalaci nové aktualizace Service Pack nebo kumulativní aktualizace Windows, můžete snížit prostoje primární repliky jen na jedno ruční převzetí služeb při selhání provedením postupného upgradu (nebo na dvě ruční převzetí, pokud přebíráte služby zpět do původní primární).
Během procesu upgradu nebude sekundární replika dostupná pro převzetí služeb při selhání ani pro operace jen pro čtení a po upgradu může trvat nějakou dobu, než sekundární replika zachytí uzel primární repliky v závislosti na objemu aktivity na uzlu primární repliky (takže očekáváte vysoký síťový provoz).
Mějte také na paměti, že po počátečním přepnutí na sekundární repliku s novější verzí SQL Serveru projdou databáze ve skupině dostupnosti procesem upgradu na nejnovější verzi. Během této doby nebudou žádné čitelné repliky pro žádnou z těchto databází. Výpadek po počátečním převzetí služeb při selhání závisí na počtu databází ve skupině dostupnosti. Pokud plánujete přepnout zpět na původní primární server, tento krok se při přepnutí zpět nebude opakovat.
Poznámka
Tento článek omezuje diskuzi na samotný upgrade SQL Serveru. Nevztahuje se na upgrade operačního systému obsahujícího cluster s podporou převzetí služeb při selhání Windows Serveru (WSFC). Aktualizace operačního systému Windows, který podporuje cluster s převzetím služeb při selhání, není podporována pro operační systémy před Windows Server 2012 R2. Pokud chcete upgradovat uzel clusteru spuštěný v systému Windows Server 2012 R2, podívejte se na Postupný upgrade operačního systému clusteru.
Požadavky
Než začnete, projděte si následující důležité informace:
Podporované verze a upgrady edic: Ověřte, zda můžete upgradovat na nejnovější verzi SQL Serveru z vaší verze operačního systému Windows a verze SQL Serveru. Pokud například upgradujete přímo z instance SYSTÉMU SQL Server 2005, upgraduje se úroveň kompatibility databáze.
Zvolte metodu upgradu databázového stroje: Chcete-li provést upgrade ve správném pořadí, vyberte odpovídající metodu upgradu a kroky na základě kontroly podporovaných upgradů verzí a edic a také na základě dalších komponent nainstalovaných ve vašem prostředí.
Naplánujte a otestujte plán upgradu databázového stroje: Projděte si poznámky k verzi a známé problémy s upgradem, kontrolní seznam předběžného nasazení a vývoj a testování plánu upgradu.
Požadavky na hardware a software pro instalaci sql Serveru: Přečtěte si požadavky na software pro instalaci SQL Serveru. Pokud je potřeba další software, nainstalujte ho na každý uzel před zahájením procesu upgradu, abyste minimalizovali případné výpadky.
Zkontrolujte, zda se pro jakoukoli databázi skupiny dostupnostipoužívá zachytávání dat změn (CDC) nebo replikace. Pokud jsou pro zachytávání změn dat povoleny nějaké databáze ve skupině dostupnosti (CDC), dokončete tyto pokyny.
Poznámka
- Kombinování verzí instancí SQL Serveru ve stejné skupině dostupnosti není podporováno mimo postupný upgrade a nemělo by v tomto stavu existovat po delší dobu, protože by se upgrade měl provést rychle. Další možností upgradu SQL Serveru 2016 (13.x) a novějších verzí je použití distribuované skupiny dostupnosti.
- Použití funkce Cluster-Aware Aktualizace (CAU) systému Windows k aktualizaci skupin dostupnosti AlwaysOn není podporována.
Základy postupného upgradu pro skupiny dostupnosti
Při provádění upgradů nebo aktualizací serveru dodržujte následující pokyny, abyste minimalizovali výpadky služeb a ztrátu dat pro vaše AGs:
Než začnete s postupným upgradem:
Proveďte praktické ruční převzetí služeb při selhání alespoň u jedné z instancí replik synchronního potvrzení.
Chraňte svá data provedením úplného zálohování databáze pro každou databázi dostupnosti.
Spusťte
DBCC CHECKDBpro každou databázi dostupnosti.
Vždy upgradujte nejprve instance sekundární vzdálené repliky, poté instance sekundární místní repliky a nakonec instance primární repliky.
Zálohy se nedají provést v databázi, která se právě upgraduje. Před upgradem sekundárních replik nakonfigurujte předvolbu automatizovaného zálohování tak, aby spouštěla zálohy pouze na primární replice. Během upgradu verze nejsou žádné repliky čitelné ani dostupné pro zálohy. Během neverzní aktualizace můžete nakonfigurovat automatické zálohy, aby běžely na sekundárních replikách před upgradem primární repliky.
Během upgradu verze nelze číst z čitelných sekundárních replik po jejich upgradu a před tím, než je proveden převod primární repliky na upgradovanou sekundární, nebo než je upgradována primární replika.
Pokud chcete zabránit neúmyslnému převzetí služeb při selhání skupiny dostupnosti během procesu upgradu, odeberte převzetí služeb při selhání dostupnosti ze všech replik synchronního potvrzení před tím, než začnete.
Než přenesete skupinu dostupnosti na upgradovanou instanci se sekundární replikou, neupgradujte instanci primární repliky. V opačném případě můžou klientské aplikace během upgradu na instanci primární repliky dojít k delšímu výpadku.
Vždy přepněte při selhání na sekundární repliku se synchronním potvrzením ve skupině dostupnosti. Pokud přepnete na instanci sekundární repliky s asynchronním potvrzením, budou databáze ohroženy ztrátou dat a pohyb dat se automaticky pozastaví, dokud ho ručně neobnovíte.
Před upgradem ani aktualizací jiné sekundární instance repliky neupgradujte instanci primární repliky. Upgradovaná primární replika už nemůže odesílat protokoly do žádné sekundární repliky, jejíž instance SQL Serveru ještě nebyla upgradována na stejnou verzi. Pokud je přesun dat do sekundární repliky pozastavený, nemůže pro tuto repliku dojít k automatickému převzetí služeb při selhání a databáze dostupnosti jsou ohroženy ztrátou dat. To platí také při postupném upgradu, při kterém ručně převezmete služby při selhání ze starého primárního serveru na nový primární server. Proto po upgradu původního primárního serveru možná budete muset pokračovat v synchronizaci.
Před provedením přepnutí skupiny dostupnosti ověřte, zda je synchronizační stav cílového zařízení pro přepnutí
SYNCHRONIZED.Varování
Instalace nové instance nebo nové verze SQL Serveru na server, který má nainstalovanou starší verzi SQL Serveru, může neúmyslně způsobit výpadek jakékoli skupiny dostupnosti hostované starší verzí SQL Serveru. Důvodem je upgrade modulu vysoké dostupnosti (
RHS.EXE) SQL Serveru během instalace instance nebo verze SQL Serveru. Výsledkem je dočasné přerušení stávajících skupin dostupnosti, které mají na serveru primární roli. Proto důrazně doporučujeme provést jednu z následujících věcí při instalaci novější verze SQL Serveru do systému, který již hostuje starší verzi SQL Serveru se skupinou dostupnosti:Nainstalujte novou verzi SQL Serveru během časového období údržby.
Převzetí služeb při selhání skupiny dostupnosti sekundární replice, aby nebyla primární během instalace nové instance SQL Serveru.
Proces postupného upgradu
Přesný proces v praxi závisí na faktorech, jako je topologie nasazení vašich AGs a režim potvrzení každé repliky. V nejjednodušším scénáři je ale postupný upgrade proces s více fázemi, který v nejjednodušší podobě zahrnuje následující kroky:
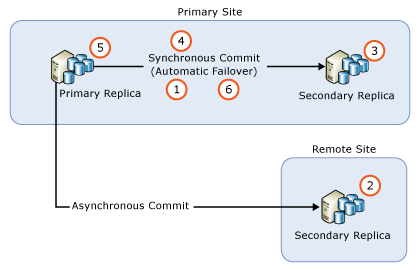
- Odebrat automatické selhání pro všechny synchronní repliky commit
- Upgradujte všechny instance sekundární repliky s asynchronním potvrzováním.
- Upgradujte všechny instance sekundární repliky se vzdáleným synchronním potvrzením.
- Upgradujte všechny místní instance sekundární repliky synchronního potvrzení.
- Ručně proveďte převzetí skupiny dostupnosti na sekundární repliku synchronního potvrzení (která byla nově upgradována).
- Proveďte upgrade nebo aktualizaci instance místní repliky, která dříve hostila primární repliku.
- Podle potřeby nakonfigurujte partnery s automatickým převzetím služeb při selhání.
V případě potřeby můžete ručně provést převzetí služeb při selhání, aby se skupina dostupnosti (AG) vrátila do původní konfigurace.
Upgrade synchronní repliky potvrzení a jeho přechod do režimu offline nezpozdí transakce na primárním serveru. Po odpojení sekundární repliky se transakce potvrdí na primárním serveru bez čekání na posílení zabezpečení protokolů na sekundární replice.
Pokud je REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT nastaven na 1 nebo 2, primární replika může být pro čtení a zápis nedostupná, pokud během procesu aktualizace není k dispozici odpovídající počet sekundárních synchronních replik.
Když provedete přímý upgrade sekundární repliky na novější verzi SQL Serveru, zůstane databáze v rámci skupiny dostupnosti ve stavu Synchronizing / In recovery nebo Synchronized / In Recovery, dokud nedojde k ručnímu převzetí služeb při selhání, což dokončí obnovení a upgraduje databázi. Upgradovaná primární replika už nemůže odesílat protokoly do žádné sekundární repliky nižší verze a zastavení přesunu dat, u této repliky se nemůže vyskytnout žádné automatické převzetí služeb při selhání a databáze dostupnosti jsou ohroženy ztrátou dat. Po upgradu starého primárního serveru možná budete muset pokračovat v synchronizaci. Před převzetím služeb při selhání na repliku s novou verzí doporučujeme upgradovat všechny sekundární repliky. Díky tomu máte možnost provést převzetí služeb při selhání po upgradu databází na nový formát.
Skupina dostupnosti (AG) s jednou vzdálenou sekundární replikou
Pokud jste nasadili skupinu dostupnosti pouze pro zotavení po havárii, možná budete muset provést přepnutí na sekundární repliku s asynchronním potvrzením. Následující obrázek znázorňuje takovou konfiguraci:
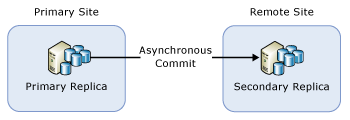
V takovém případě musíte provést převzetí služeb při selhání na sekundární repliku s asynchronním potvrzením během postupného upgradu. Pokud chcete zabránit ztrátě dat, změňte režim potvrzení na synchronní potvrzení a počkejte na synchronizaci sekundární repliky před převzetím služeb při selhání skupiny dostupnosti. Proces postupného upgradu proto může vypadat takto:
- Upgradujte instanci sekundární repliky ve vzdálené lokalitě.
- Změňte režim potvrzení na synchronní potvrzení.
- Počkejte, až bude
SYNCHRONIZEDstav synchronizace . - Převzetí služeb při selhání skupiny dostupnosti na sekundární repliku ve vzdálené lokalitě.
- Upgradujte nebo aktualizujte místní instanci repliky (primární lokality).
- Převzetí služeb při selhání skupiny dostupnosti zpět do primární lokality.
- Změňte režim potvrzení na asynchronní potvrzení.
Vzhledem k tomu, že režim synchronního potvrzení není doporučeným nastavením synchronizace dat do vzdálené lokality, klientské aplikace si můžou po změně nastavení všimnout okamžitého zvýšení latence databáze. Kromě toho provedení převzetí služeb při selhání vede k tomu, že se všechny nepotvrzené zprávy protokolu zahodí. Počet zahozených zpráv protokolu může být významný kvůli vysoké latenci sítě mezi těmito dvěma lokalitami, což způsobuje, že klienti mají velký objem transakčních selhání. Účinek na klientské aplikace můžete minimalizovat provedením následujících akcí:
Pečlivě vyberte časové období údržby během nízkého provozu klienta.
Při upgradu nebo aktualizaci SQL Serveru v primární lokalitě změňte režim dostupnosti zpět na asynchronní potvrzení a potom se vraťte k synchronnímu potvrzení, až budete připraveni převzít služby při selhání do primární lokality znovu.
Skupina dostupnosti s uzly instancí clusteru s podporou převzetí služeb při selhání
Pokud skupina dostupnosti obsahuje uzly instance převzetí služeb při selhání (FCI), měli byste před upgradem aktivních uzlů upgradovat neaktivní uzly. Následující obrázek znázorňuje běžný scénář skupiny dostupnosti s FCI pro místní vysokou dostupnost a asynchronní potvrzení mezi FCI pro vzdálené zotavení po havárii a sekvencí upgradu.
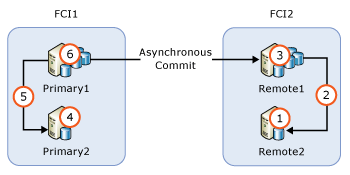
- Upgrade nebo aktualizace
REMOTE2 - Převzetí služeb při selhání FCI2 na
REMOTE2 - Upgrade nebo aktualizace
REMOTE1 - Upgrade nebo aktualizace
PRIMARY2 - Selhání přepnutí FCI1 na
PRIMARY2 - Upgrade nebo aktualizace
PRIMARY1
Upgrade nebo aktualizace instancí SQL Serveru s několika skupinami AG
Pokud používáte více skupin dostupnosti s primárními replikami na samostatných serverových uzlech (konfigurace Aktivní/Aktivní), cesta upgradu zahrnuje další kroky pro failover, které v procesu zachovají vysokou dostupnost. Předpokládejme, že spouštíte tři skupiny AG na třech serverových uzlech se všemi replikami v synchronním režimu potvrzení, jak je znázorněno v následující tabulce:
| AG | Node1 | Node2 | Node3 |
|---|---|---|---|
| AG1 | Primární | ||
| AG2 | Primární | ||
| AG3 | Primární |
Ve vaší situaci může být vhodné provést postupný upgrade s vyrovnáváním zatížení v následujícím pořadí:
- Přepnout skupinu dostupnosti 2 na
Node3(uvolněníNode2) - Upgrade nebo aktualizace
Node2 - Přepnutí při selhání AG1 na
Node2, aby se uvolnilNode1. - Upgrade nebo aktualizace
Node1 - Přesuňte převzetí služeb při selhání pro obě AG2 a AG3 na
Node1(aby se uvolniloNode3) - Upgrade nebo aktualizace
Node3 - Přepnout AG3 na
Node3
Tato sekvence upgradu má průměrný výpadek kratší než dvě převzetí služeb pro každou AG. Výsledná konfigurace je znázorněna v následující tabulce.
| AG | Node1 | Node2 | Node3 |
|---|---|---|---|
| AG1 | Primární | ||
| AG2 | Primární | ||
| AG3 | Primární |
V závislosti na vaší konkrétní implementaci se cesta upgradu může lišit, stejně jako se může lišit i délka výpadku, které zažívají klientské aplikace.
Poznámka
V mnoha případech po dokončení postupného upgradu provedete navrácení na původní primární repliku.
Postupný upgrade distribuované skupiny dostupnosti
Pokud chcete provést postupný upgrade distribuované skupiny dostupnosti, nejprve upgradujte všechny sekundární repliky. V dalším kroku převeďte služby předávání služeb při selhání a upgradujte poslední zbývající instanci druhé skupiny dostupnosti. Po upgradu všech ostatních replik převezme služby při selhání globální primární primární instance a upgraduje poslední zbývající instanci první skupiny dostupnosti. Podrobný diagram s kroky najdete v další části.
V závislosti na vaší konkrétní implementaci se cesta upgradu může lišit, stejně jako se může lišit i délka výpadku, které zažívají klientské aplikace.
Poznámka
V mnoha případech po dokončení postupného upgradu se vrátíte na původní primární repliky.
Obecné kroky pro aktualizaci distribuované skupiny dostupnosti
- Zálohujte všechny databáze, včetně systémových databází a těch, kteří se účastní skupiny dostupnosti.
- Upgradujte a restartujte všechny sekundární repliky druhé skupiny dostupnosti (sekundární skupiny).
- Aktualizujte a restartujte všechny sekundární repliky první skupiny dostupnosti (upstream).
- Přepnout primární server předávajícího na upgradovanou sekundární repliku sekundární skupiny dostupnosti.
- Počkejte na synchronizaci dat. Databáze by se měly zobrazovat jako synchronizované u všech replik s potvrzením synchronní transakce a globální primární server by se měl synchronizovat s předávacím serverem.
- Upgradujte a restartujte poslední zbývající instanci sekundární skupiny dostupnosti.
- Proveďte přepnutí globálního primárního serveru na upgradovanou sekundární repliku v první skupině dostupnosti.
- Upgradujte poslední zbývající instanci primární skupiny dostupnosti.
- Restartujte nově upgradovaný server.
- (volitelné) Proveďte převod obou skupin dostupnosti zpět na původní primární repliky.
Důležitý
Ověřte synchronizaci mezi každým krokem. Než budete pokračovat k dalšímu kroku, ověřte, že se repliky synchronního potvrzení synchronizují v rámci skupiny dostupnosti a že se globální primární server synchronizuje se službou předávání v distribuované skupině dostupnosti.
doporučení: Při každém ověření synchronizace aktualizujte jak databázový uzel, tak uzel AG (skupina dostupnosti) v aplikaci SQL Server Management Studio. Po synchronizaci všeho uložte snímek obrazovky se stavem každé repliky. To vám pomůže sledovat, jaký krok používáte, poskytuje důkazy o tom, že všechno fungovalo správně před dalším krokem, a pomůže vám s řešením potíží, pokud se něco nepovede.
Diagram příkladu postupného upgradu distribuované skupiny dostupnosti
| Skupina dostupnosti | Primární replika | Sekundární replika |
|---|---|---|
| AG1 | NODE1\SQLAG |
NODE2\SQLAG |
| AG2 | NODE3\SQLAG |
NODE4\SQLAG |
| DistributedAG | AG1 (globální) | Skupina dostupnosti 2 (přesměrovávač) |
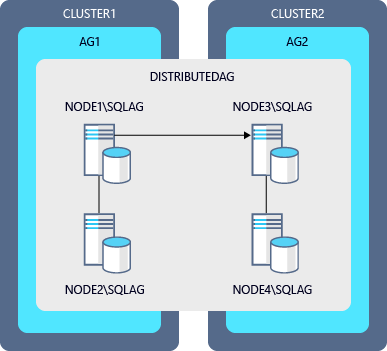
Kroky pro upgrade instancí v tomto diagramu:
- Zálohujte všechny databáze, včetně systémových databází a těch, kteří se účastní skupiny dostupnosti.
- Vylepšete
NODE4\SQLAG(sekundární AG2) a restartujte server. - Upgradujte
NODE2\SQLAG(sekundární AG1) a restartujte server. - Přepnutí při selhání z AG2 z
NODE3\SQLAGnaNODE4\SQLAG. - Upgradujte
NODE3\SQLAGa restartujte server. - Převzetí služeb při selhání skupiny dostupnosti AG1 z
NODE1\SQLAGnaNODE2\SQLAG. - Upgradujte
NODE1\SQLAGa restartujte server. - (volitelné) Vrácení na původní primární repliky.
- Převzetí skupiny dostupnosti 2 z
NODE4\SQLAGzpět doNODE3\SQLAG. - Přepnutí při selhání AG1 z
NODE2\SQLAGzpět doNODE1\SQLAG.
- Převzetí skupiny dostupnosti 2 z
Pokud v každé skupině dostupnosti existovala třetí replika, upgradovali byste ji před NODE3\SQLAG a NODE1\SQLAG.
Důležitý
Ověřte synchronizaci mezi každým krokem. Než budete pokračovat k dalšímu kroku, ověřte, že se repliky synchronního potvrzení synchronizují v rámci skupiny dostupnosti a že se globální primární server synchronizuje se službou předávání v distribuované skupině dostupnosti.
Doporučení: Pokaždé, když ověříte synchronizaci, aktualizujte databázový uzel i uzel distribuované skupiny dostupnosti v SQL Server Management Studio. Po synchronizaci všeho udělejte snímek obrazovky a uložte ho. To vám pomůže sledovat, jaký krok používáte, poskytuje důkazy o tom, že všechno fungovalo správně před dalším krokem, a pomůže vám s řešením potíží, pokud se něco nepovede.
Speciální kroky pro zachytávání nebo replikaci dat změn
V závislosti na právě aplikované aktualizaci se můžou vyžadovat další kroky pro databáze replik AG, které jsou povolené pro zachytávání změn dat nebo replikaci. Projděte si poznámky k verzi aktualizace a zjistěte, jestli jsou potřeba následující kroky:
Upgradujte každou sekundární repliku.
Po upgradu všech sekundárních replik převezme služby při selhání skupiny dostupnosti na upgradovanou instanci.
V instanci, která je hostitelem primární repliky, spusťte následující Transact-SQL:
EXECUTE [master].[sys].[sp_vupgrade_replication];Poznámka
Spuštění tohoto příkazu může trvat několik minut. Pokud používáte SQL Server 2019 CU1 nebo novější, tento krok přeskočte. Další informace najdete v KB4530283.
Upgradujte instanci, která byla původně primární replikou.
Pro další informace viz Funkcionalita CDC může přestat fungovat po upgradu na nejnovější CU.