Graph Engine vs. C++ unordered_map: memory consumption test, Part 2
In my previous post, I demonstrated the memory management efficiency of Graph Engine against C++ unordered_map with MSVC's built-in memory allocator. Note that the test is not about unordered_map alone, but a combination with buffer allocation and deallocation. I would like to measure how does the program consume memory with all these parts coming together. The goal is not to beat C++, not to beat unordered_map, but rather to show that, even the Graph Engine key-value store is designed to manage billions of objects across multiple machines, it does not get bloated with too many abstractions when it comes down to the simplest task, and is even comparable to a bare-metal C++ built-in data structure, which is not performing bad at all. There are a lot of discussions and I'd like to thank all for the comments and feedback. Here are a few important points collected from the discussion:
1. The C++ part has memory leak concerning the overwritten entries.
2. The rand()*rand() is a bad idea. Also, using different random generators(C routine vs. C# Random class) does not produce precisely aligned semantics.
3. There are overheads invoking the random generators.
4. For the C++ part, people demand better coding style :-)
5. Plot the memory consumption chart with an origin.
6. For better performance, call reserve() on the unordered_map.
7. For better performance, embed content buffer into the cell entries.
8. Why does the C# program only allocate buffer once outside the loop?
Let me first explain why some of these proposed changes to the test are ruled out. For reserve(), it does improve the performance on the C++ side. But please note that I did not make any optimizations on the C# side either. And for the purpose of a key-value store, there should not be pre-assumed space reservations hard coded into the program, because generally if you are going to put it online, instead of doing planned experiments, you cannot know the usage patterns in advance. For similar reasons, we cannot embed fixed-length std::array into cell entries, because the value blobs stored into a key-value store may vary in size. Plus, variable length entries do not fit into a map, or we will end up storing references to these content objects, which, logically does not make a difference than a void*. The program only allocate a single C# byte array, because the Graph Engine K/V store has its own memory management subsystem, which is not allocating from the CLR managed heap.
To make the random number generation fair to both the C++ and C# test programs, I switched to a dedicated C++ program for generating test instructions for both programs. It randomly generates 64M store operations, each containing a cell id and a cell size. The maximum cell size is twice as large as in the last test so that the expected total size should be the same.
#include "stdafx.h"
#include <random>
#include <functional>
#include <unordered_map>
#include <algorithm>
#include <cstdint>
#include <cstdio>
#define ENTRY_COUNT (64<<20)
#define ENTRY_MAX_ID (ENTRY_COUNT * 4)
#define ENTRY_MAX_SIZE (314 * 2)
#define BUCKET_COUNT (64)
#define BUCKET_GRANULARITY (ENTRY_MAX_SIZE / BUCKET_COUNT)
struct param_entry
{
int64_t cell_id;
size_t cell_size;
};
int main(int argc, char* argv[])
{
std::default_random_engine rnd_gen;
std::uniform_int_distribution<int64_t> cell_id_dist(0, ENTRY_MAX_ID);
std::uniform_int_distribution<int32_t> cell_size_dist(1, ENTRY_MAX_SIZE);
std::vector<param_entry> param_entries(ENTRY_COUNT);
std::unordered_map<int32_t, int32_t> size_buckets;
auto cell_id_gen = std::bind(cell_id_dist, rnd_gen);
auto cell_size_gen = std::bind(cell_size_dist, rnd_gen);
for (auto& param : param_entries)
{
param.cell_id = cell_id_gen();
param.cell_size = cell_size_gen();
}
FILE* fp;
fopen_s(&fp, "params.dat", "wb");
fwrite(param_entries.data(), sizeof(param_entry), ENTRY_COUNT, fp);
fclose(fp);
/* statictical analysis */
for (int i = 0; i < BUCKET_COUNT; ++i)
{
size_buckets[i] = 0;
}
for (auto& param : param_entries)
{
int bucket_idx = param.cell_size / BUCKET_GRANULARITY;
++size_buckets[bucket_idx];
}
std::sort(param_entries.begin(), param_entries.end(), [](param_entry &a, param_entry &b) {return a.cell_id < b.cell_id; });
auto new_end = std::unique(param_entries.begin(), param_entries.end() , [](param_entry &a, param_entry &b){ return a.cell_id == b.cell_id; });
int32_t unique_entry_count = new_end - param_entries.begin();
printf(">>>");
printf("%d total entries\n", ENTRY_COUNT);
printf(">>>");
printf("%d unique entries\n", unique_entry_count);
printf(">>>");
printf("Size histogram:\n");
for (int i = 0; i < BUCKET_COUNT; ++i)
{
printf("%-2d\t\t%d\n", i * BUCKET_GRANULARITY, size_buckets[i]);
}
return 0;
}
The resulting data file params.dat takes exactly 1GB of space, with the following statistics information:
>>>67108864 total entries
>>>59378342 unique entries
>>>Size histogram:
0 855411
9 962141
18 960462
27 961976
36 961641
45 961725
54 963224
63 961521
72 961336
81 961785
90 961053
99 964048
108 962261
117 961443
126 960895
135 962208
144 960792
153 960925
162 961486
171 961390
180 961762
189 961682
198 962320
207 962201
216 960415
225 962173
234 963833
243 960419
252 960049
261 963305
270 959831
279 959656
288 961434
297 961652
306 964231
315 963157
324 961786
333 960566
342 961645
351 961816
360 961421
369 961435
378 962095
387 960651
396 962341
405 961820
414 961355
423 961368
432 960645
441 961942
450 960869
459 962132
468 962618
477 960927
486 962067
495 960434
504 962018
513 962531
522 962315
531 961781
540 962139
549 961675
558 963721
567 961252
Uniform enough. I limited the range of cell ids to [0, 256M] to introduce some duplicated entries. And the test code, updated, here:
#include "stdafx.h"
#include <vector>
#include <iostream>
#include <unordered_map>
#include <random>
#include <functional>
#include <chrono>
#include <cstdint>
#include <ctime>
using namespace std;
#define ENTRY_COUNT (1<<20)*64
typedef int64_t cellid_t;
struct CellEntry
{
void* ptr;
int32_t len;
uint16_t cellType;
};
struct param_entry
{
int64_t cell_id;
size_t cell_size;
};
param_entry param_entries[ENTRY_COUNT];
unordered_map<cellid_t, CellEntry> LocalStorage;
int main(int argc, char** argv)
{
srand(time(NULL));
std::chrono::steady_clock::time_point start_time, end_time;
std::cout << "Preparing keys" << std::endl;
FILE* fp;
fopen_s(&fp, "params.dat", "rb");
fread(param_entries, sizeof(param_entry), ENTRY_COUNT, fp);
fclose(fp);
std::cout << "Test started." << std::endl;
start_time = std::chrono::steady_clock::now();
for (auto entry : param_entries)
{
void* cell_buf = new char[entry.cell_size];
auto upsert_result = LocalStorage.emplace(entry.cell_id, CellEntry{ cell_buf, entry.cell_size, 0 });
if (!upsert_result.second)
{
std::swap(cell_buf, upsert_result.first->second.ptr);
delete[] cell_buf;
}
if (rand() % 3 == 0)
{
delete[] upsert_result.first->second.ptr;
LocalStorage.erase(entry.cell_id);
}
}
end_time = std::chrono::steady_clock::now();
std::cout << "done." << std::endl;
std::cout << "Time = " << chrono::duration_cast<chrono::seconds>(end_time - start_time).count() << std::endl;
getchar();
return 0;
}
C#:
using System;
using System.Collections.Generic;
using System.Diagnostics;
using System.IO;
using System.Linq;
using System.Runtime.InteropServices;
using System.Text;
using System.Threading.Tasks;
using Trinity;
using Trinity.Core.Lib;
namespace MemoryConsumptionTest_CSharp
{
unsafe internal class Program
{
const int ENTRY_COUNT = (64 << 20);
const int ENTRY_MAX_SIZE = (314 * 2);
[StructLayout(LayoutKind.Explicit)]
struct param_entry
{
[FieldOffset(0)]
public long cell_id;
[FieldOffset(8)]
public int cell_size;
[FieldOffset(12)]
private int __pad;
};
[DllImport("msvcrt.dll")]
static extern void* fopen(string fname, string mode);
[DllImport("msvcrt.dll")]
static extern long fread(void* ptr, long size, long count, void* fp);
[DllImport("msvcrt.dll")]
static extern void fclose(void* fp);
static void Main(string[] args)
{
// SaveCell will alloc memory inside GE,
// so we just allocate a single buffer from C#
byte* buf = (byte*)Memory.malloc(ENTRY_MAX_SIZE);
param_entry* entries = (param_entry*)Memory.malloc((ulong)(ENTRY_COUNT * sizeof(param_entry)));
TrinityConfig.CurrentRunningMode = RunningMode.Embedded;
Stopwatch stopwach = new Stopwatch();
Random dice = new Random();
Console.WriteLine("Preparing keys");
var fp = fopen("params.dat", "rb");
fread(entries, sizeof(param_entry), ENTRY_COUNT, fp);
fclose(fp);
Console.WriteLine("Test started.");
stopwach.Start();
for(param_entry* p = entries, e = entries + ENTRY_COUNT; p != e; ++p)
{
Global.LocalStorage.SaveCell(p->cell_id, buf, p->cell_size, cellType: 0);
if (dice.Next(3) == 0)
{
Global.LocalStorage.RemoveCell(p->cell_id);
}
}
stopwach.Stop();
Console.WriteLine("Done.");
Console.WriteLine("Time = {0}", stopwach.ElapsedMilliseconds / 1000);
Console.ReadKey();
}
}
}
Updated performance result:
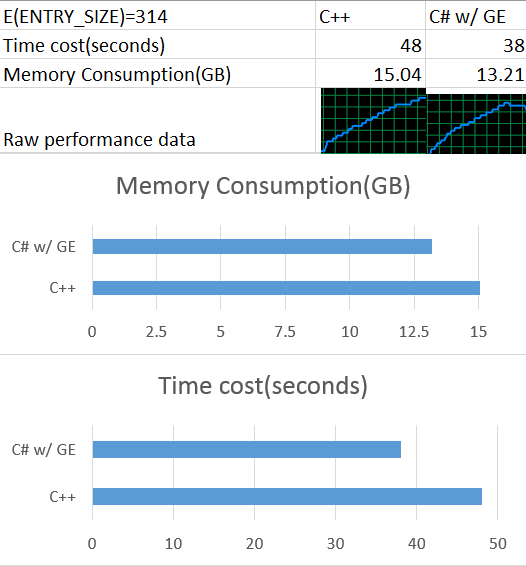
Looking forward to your comments!
Comments
Anonymous
June 07, 2015
This is a fine result, but for completeness, you should profile both tests and verify that the time being spent is actually being spent on the operation you are attempting to time.Anonymous
June 07, 2015
Out of curiosity, does the final C# memory consumption number include the drop at the end or no? I notice that both programs use 2GB of memory for param_entries. In the C++ one though, the memory is allocated in the global space. In the C# program, it's allocated on the heap. I'm not sure if the C# program will GC that memory or not (I'm not a C# expert). What was the peak memory use by both apps? I'm just having a hard time understanding how the last comparison with so many memory leaks (3.5GB) consumed only 1.9 GB more memory than GraphEngine, but now with leaks fixed still uses 1.8 GB more memory. I do agree that GraphEngine has excellent (near perfect) memory consumption characteristics, which is the ultimate point of the article, but I'm concerned the C++ app isn't getting measured correctly.