Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Scott Mitchell
Výchozí možnost stránkování ovládacího prvku prezentace dat není vhodná při práci s velkým množstvím dat, protože její podkladová správa zdrojů dat načte všechny záznamy, i když se zobrazí jenom podmnožina dat. Za takových okolností se musíme obrátit na vlastní stránkování.
Úvod
Jak jsme probrali v předchozím kurzu, stránkování se dá implementovat jedním ze dvou způsobů:
- Výchozí stránkování lze implementovat jednoduše tak, že v inteligentní značce webového ovládacího prvku dat zaškrtnete možnost Povolit stránkování. Při každém zobrazení stránky dat ale ObjectDataSource načte všechny záznamy, i když se na stránce zobrazí jenom podmnožina.
- Vlastní stránkování zlepšuje výkon výchozího stránkování načtením jenom těch záznamů z databáze, které je potřeba zobrazit pro konkrétní stránku dat požadovaných uživatelem. Vlastní stránkování ale vyžaduje trochu větší úsilí, než je implementace výchozího stránkování.
Vzhledem k snadné implementaci stačí zaškrtnout políčko a máte hotovo! výchozí stránkování je atraktivní možnost. Jeho naivní přístup při načítání všech záznamů však činí nespravděhodnou volbou při stránkování dostatečně velkých objemů dat nebo pro weby s mnoha souběžnými uživateli. Za takových okolností se musíme obrátit na vlastní stránkování, abychom zajistili responzivní systém.
Výzvou vlastního stránkování je napsat dotaz, který vrací přesnou sadu záznamů potřebných pro konkrétní stránku dat. Microsoft SQL Server 2005 naštěstí poskytuje nové klíčové slovo pro výsledky řazení, což nám umožňuje napsat dotaz, který může efektivně načíst správnou podmnožinu záznamů. V tomto kurzu se dozvíte, jak pomocí tohoto nového klíčového slova SQL Server 2005 implementovat vlastní stránkování v ovládacím prvku GridView. Uživatelské rozhraní pro vlastní stránkování je stejné jako u výchozího stránkování, ale krokování z jedné stránky na další pomocí vlastního stránkování může být o několik řádů rychlejší než výchozí stránkování.
Poznámka:
Přesný výkon vystavený vlastním stránkováním závisí na celkovém počtu stránkovaných záznamů a zatížení umístěném na databázovém serveru. Na konci tohoto kurzu se podíváme na některé přibližné metriky, které ukazují výhody výkonu získaného prostřednictvím vlastního stránkování.
Krok 1: Principy vlastního procesu stránkování
Při stránkování dat závisí přesné záznamy zobrazené na stránce na požadované stránce a počet zobrazených záznamů na stránce. Představte si například, že jsme chtěli procházet 81 produkty a zobrazit 10 produktů na stránku. Při prohlížení první stránky chceme produkty 1 až 10; při prohlížení druhé stránky bychom měli zájem o produkty 11 až 20 atd.
Existují tři proměnné, které určují, jaké záznamy je potřeba načíst a jak se má stránkovací rozhraní vykreslit:
- Spustit index řádku index prvního řádku na stránce dat, která se má zobrazit. Tento index lze vypočítat vynásobením indexu stránky záznamy, které se mají zobrazit na stránce, a přidáním jednoho. Například při stránkování záznamů 10 najednou, pro první stránku (jejíž index stránky je 0), je index počátečního řádku 0 * 10 + 1 nebo 1; pro druhou stránku (jejíž index stránky je 1), index počátečního řádku je 1 * 10 + 1 nebo 11.
- Maximální počet záznamů, které se mají zobrazit na stránce, je maximální počet řádků . Tato proměnná se označuje jako maximální počet řádků, protože na poslední stránce může být vráceno méně záznamů, než je velikost stránky. Například při stránkování 81 produktů 10 záznamů na stránku bude mít devátá a poslední stránka jenom jeden záznam. Žádná stránka ale nebude zobrazovat více záznamů, než je hodnota Maximální počet řádků.
- Total Record Count the total record Count the total number of records being paged through. I když tato proměnná není nutná k určení záznamů, které se mají načíst pro danou stránku, určuje stránkovací rozhraní. Pokud například probíhá stránkování 81 produktů, stránkovací rozhraní ví, že v uživatelském rozhraní stránkování zobrazuje devět čísel stránek.
Při výchozím stránkování se index počátečního řádku vypočítá jako součin indexu stránky a velikost stránky plus jedna, zatímco maximální počet řádků je jednoduše velikost stránky. Vzhledem k tomu, že při vykreslování jakékoli stránky dat načte výchozí stránkování všechny záznamy z databáze, je index pro každý řádek známý, takže přechod na řádek Počáteční řádek indexu představuje triviální úlohu. Celkový počet záznamů je navíc snadno dostupný, protože se jedná o jednoduše počet záznamů v tabulce DataTable (nebo jakýkoli objekt, který se používá k uložení výsledků databáze).
Vzhledem k tomu, počáteční řádek index a maximální řádky proměnné, vlastní stránkovací implementace musí vrátit pouze přesnou podmnožinu záznamů začínající indexem počátečního řádku a až maximální počet řádků záznamů po tomto. Vlastní stránkování přináší dvě výzvy:
- Musíme být schopni efektivně přidružit index řádků ke každému řádku v celých stránkovaných datech, abychom mohli začít vracet záznamy v zadaném indexu počátečního řádku.
- Musíme zadat celkový počet stránkovaných záznamů.
V dalších dvou krocích prozkoumáme skript SQL potřebný k reakci na tyto dvě výzvy. Kromě skriptu SQL budeme také muset implementovat metody v dal a BLL.
Krok 2: Vrácení celkového počtu stránkovaných záznamů
Než se podíváme, jak načíst přesnou podmnožinu záznamů pro zobrazenou stránku, pojďme se nejprve podívat, jak vrátit celkový počet stránkovaných záznamů. Tyto informace jsou potřeba k správné konfiguraci stránkovacího uživatelského rozhraní. Celkový počet záznamů vrácených konkrétním dotazem SQL lze získat pomocí COUNT agregační funkce. K určení celkového počtu záznamů v Products tabulce můžeme například použít následující dotaz:
SELECT COUNT(*)
FROM Products
Pojďme přidat metodu do naší dal, která vrátí tyto informace. Konkrétně vytvoříme metodu DAL, TotalNumberOfProducts() která spustí SELECT výše uvedený příkaz.
Začněte otevřením Northwind.xsd souboru Typed DataSet ve App_Code/DAL složce. V dalším kroku klikněte pravým tlačítkem myši na ProductsTableAdapter návrháře a zvolte Přidat dotaz. Jak jsme viděli v předchozích kurzech, to nám umožní přidat novou metodu do DAL, která při vyvolání provede konkrétní příkaz SQL nebo uloženou proceduru. Stejně jako u našich metod TableAdapter v předchozích kurzech se pro tuto možnost rozhodnete použít příkaz SQL ad hoc.
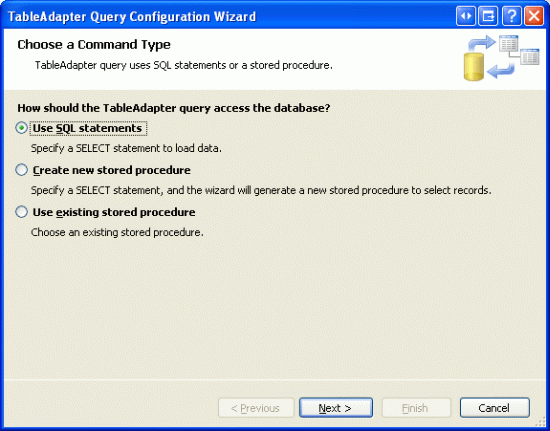
Obrázek 1: Použití ad hoc příkazu SQL
Na další obrazovce můžeme určit, jaký typ dotazu se má vytvořit. Vzhledem k tomu, že tento dotaz vrátí jednu skalární hodnotu celkového počtu záznamů v Products tabulce, zvolte SELECT , která vrátí možnost hodnoty singe.
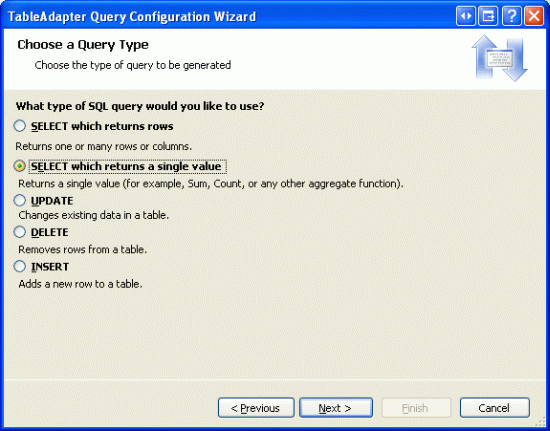
Obrázek 2: Konfigurace dotazu na použití příkazu SELECT, který vrátí jednu hodnotu
Po označení typu dotazu, který se má použít, musíme dále zadat dotaz.
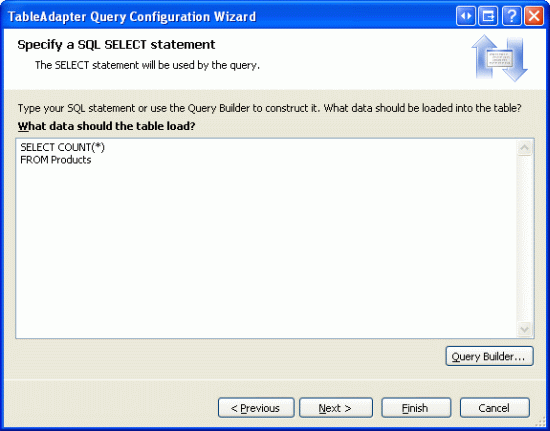
Obrázek 3: Použití dotazu SELECT COUNT(*) FROM Products
Nakonec zadejte název metody. Jak je uvedeno výše, pojďme použít TotalNumberOfProducts.
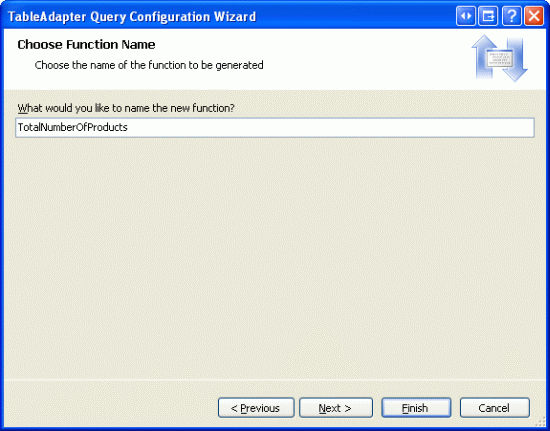
Obrázek 4: Pojmenování metody DAL TotalNumberOfProducts
Po kliknutí na Tlačítko Dokončit průvodce přidá metodu TotalNumberOfProducts do DAL. Skalární návratové metody v dal vrátit nullable typy, v případě, že výsledek dotazu SQL je NULL. Náš COUNT dotaz však vždy vrátí nehodnotuNULL . Bez ohledu na to, metoda DAL vrátí celé číslo s možnou hodnotou null.
Kromě metody DAL potřebujeme také metodu v BLL.
ProductsBLL Otevřete soubor třídy a přidejte metoduTotalNumberOfProducts, která jednoduše volá metodu DAL sTotalNumberOfProducts:
Public Function TotalNumberOfProducts() As Integer
Return Adapter.TotalNumberOfProducts().GetValueOrDefault()
End Function
Metoda DAL s TotalNumberOfProducts vrátí celé číslo s možnou hodnotou null. Vytvořili jsme však metodu ProductsBLL třídy s TotalNumberOfProducts tak, aby vrátila standardní celé číslo. Proto potřebujeme, ProductsBLL aby metoda třídy s TotalNumberOfProducts vrátila část hodnoty integer s možnou hodnotou null vrácenou metodou DAL TotalNumberOfProducts . Volání, které GetValueOrDefault() vrátí hodnotu celého čísla s možnou hodnotou null, pokud existuje. Pokud je nullvšak celé číslo s možnou hodnotou null, vrátí výchozí celočíselnou hodnotu 0.
Krok 3: Vrácení přesné podmnožině záznamů
Naším dalším úkolem je vytvořit metody v dal a BLL, které přijímají index počátečního řádku a maximální řádky proměnných probírané dříve a vrací příslušné záznamy. Než to uděláme, pojďme se nejprve podívat na potřebný skript SQL. Výzvou, na kterou čelíme, je, že musíme být schopni efektivně přiřadit index ke každému řádku v celých výsledcích, abychom mohli vrátit pouze ty záznamy začínající indexem počátečního řádku (a až do maximálního počtu záznamů).
Nejedná se o výzvu, pokud už v tabulce databáze existuje sloupec, který slouží jako index řádku. Na první pohled si můžeme představit, že Products pole tabulky ProductID bude stačit, protože první součin má ProductID hodnotu 1, druhý 2 atd. Odstraněním produktu ale v posloupnosti zůstane mezera, která tento přístup vynuluje.
K efektivnímu přidružení indexu řádku k datům na stránku existují dvě obecné techniky, které umožňují načtení přesné podmnožin záznamů:
ROW_NUMBER()SQL Server 2005 s new to SQL Server 2005,ROW_NUMBER()klíčové slovo přidruží pořadí k jednotlivým vráceným záznamům na základě určité řazení. Toto řazení lze použít jako index řádku pro každý řádek.Použití proměnné tabulky a
SET ROWCOUNTpříkazu SQL ServeruSET ROWCOUNTlze použít k určení, kolik celkových záznamů by dotaz měl zpracovat před ukončením; Proměnné tabulky jsou místní proměnné T-SQL, které můžou obsahovat tabulková data, která se můžou podobat dočasným tabulkám. Tento přístup funguje stejně dobře s Microsoft SQL Serverem 2005 i SQL Serverem 2000 (zatímcoROW_NUMBER()přístup funguje jenom s SQL Serverem 2005).Cílem je vytvořit proměnnou tabulky, která má
IDENTITYsloupec a sloupce pro primární klíče tabulky, jejichž data se stránkují. Dále se obsah tabulky, jejíž data jsou stránkována, vypíše do proměnné tabulky, čímž se přidružuje index sekvenčního řádku (prostřednictvímIDENTITYsloupce) pro každý záznam v tabulce. Jakmile je proměnná tabulky vyplněná,SELECTje možné spustit příkaz pro proměnnou tabulky, který je spojený s podkladovou tabulkou, a vytáhnout tak konkrétní záznamy. TentoSET ROWCOUNTpříkaz slouží k inteligentnímu omezení počtu záznamů, které je potřeba vypsat do proměnné tabulky.Efektivita tohoto přístupu je založená na požadovaném počtu stránek, protože
SET ROWCOUNThodnota je přiřazena hodnota indexu počátečního řádku plus maximální počet řádků. Při stránkování přes stránky s nízkým číslem, jako je například prvních pár stránek dat, je tento přístup velmi efektivní. Při načítání stránky blízko konce ale vykazuje výchozí výkon podobný stránkování.
Tento kurz implementuje vlastní stránkování pomocí klíčového ROW_NUMBER() slova. Další informace o použití proměnné tabulky a SET ROWCOUNT techniky naleznete v tématu Efektivnější metoda stránkování prostřednictvím velkých sad výsledků.
Klíčové ROW_NUMBER() slovo přidružené k řazení ke každému záznamu vráceného přes konkrétní řazení pomocí následující syntaxe:
SELECT columnList,
ROW_NUMBER() OVER(orderByClause)
FROM TableName
ROW_NUMBER() vrátí číselnou hodnotu, která určuje pořadí pro každý záznam s ohledem na uvedené řazení. Pokud například chcete zobrazit pořadí pro každý produkt seřazený od nejlevnějších po nejmenší, mohli bychom použít následující dotaz:
SELECT ProductName, UnitPrice,
ROW_NUMBER() OVER(ORDER BY UnitPrice DESC) AS PriceRank
FROM Products
Obrázek 5 ukazuje výsledky tohoto dotazu při spuštění okna dotazu v sadě Visual Studio. Všimněte si, že produkty jsou seřazené podle ceny spolu s pořadím cen pro každý řádek.
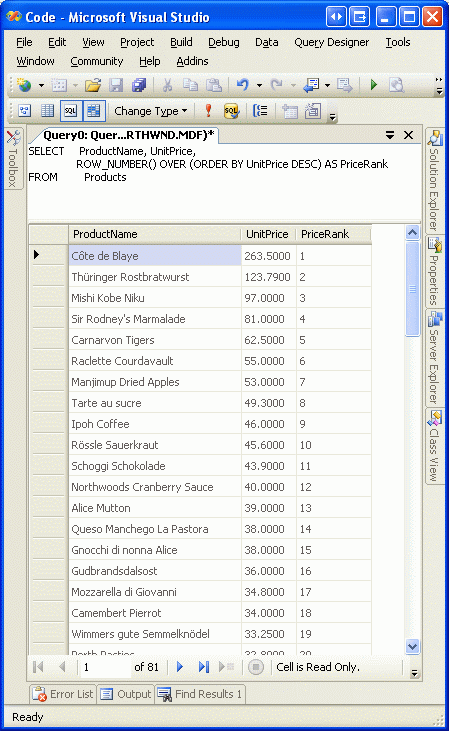
Obrázek 5: Pořadí cen je zahrnuto pro každý vrácený záznam
Poznámka:
ROW_NUMBER() je jen jednou z mnoha nových funkcí řazení dostupných v SQL Serveru 2005. Podrobnější diskuzi o funkcích ROW_NUMBER()řazení a dalších funkcích řazení najdete v ROW_NUMBER dokumentaci.
Při řazení výsledků podle zadaného ORDER BY sloupce v OVER klauzuli (UnitPricev předchozím příkladu) musí SQL Server výsledky seřadit. Jedná se o rychlou operaci, pokud je ve sloupci clusterovaný index, podle kterého se výsledky řazuje, nebo pokud existuje krytý index, ale může být nákladnější jinak. Pokud chcete zvýšit výkon dostatečně velkých dotazů, zvažte přidání neskupovaného indexu pro sloupec, podle kterého jsou výsledky seřazeny.
Podrobnější informace o aspektech výkonu najdete v tématu Funkce řazení a výkon v SQL Serveru 2005.
Informace o řazení vrácené ROW_NUMBER() klauzulí nelze přímo použít v klauzuli WHERE . Odvozenou tabulku lze však použít k vrácení výsledku ROW_NUMBER() , který se pak může objevit v klauzuli WHERE . Například následující dotaz používá odvozenou tabulku k vrácení sloupců ProductName a UnitPrice spolu s ROW_NUMBER() výsledkem a potom pomocí klauzule vrátí WHERE pouze ty produkty, jejichž cena je mezi 11 a 20:
SELECT PriceRank, ProductName, UnitPrice
FROM
(SELECT ProductName, UnitPrice,
ROW_NUMBER() OVER(ORDER BY UnitPrice DESC) AS PriceRank
FROM Products
) AS ProductsWithRowNumber
WHERE PriceRank BETWEEN 11 AND 20
Rozšířením tohoto konceptu o něco dál můžeme tento přístup využít k načtení konkrétní stránky dat s ohledem na požadovaný index počátečního řádku a maximální hodnoty řádků:
SELECT PriceRank, ProductName, UnitPrice
FROM
(SELECT ProductName, UnitPrice,
ROW_NUMBER() OVER(ORDER BY UnitPrice DESC) AS PriceRank
FROM Products
) AS ProductsWithRowNumber
WHERE PriceRank > <i>StartRowIndex</i> AND
PriceRank <= (<i>StartRowIndex</i> + <i>MaximumRows</i>)
Poznámka:
Jak uvidíme později v tomto kurzu, StartRowIndex zadaný ObjectDataSource je indexován od nuly, zatímco ROW_NUMBER() hodnota vrácená SQL Serverem 2005 je indexována od 1. Klauzule WHERE proto vrátí tyto záznamy, kde PriceRank je přísně větší než StartRowIndex a menší než nebo rovnoStartRowIndex + MaximumRows .
Teď, když jsme probrali, jak ROW_NUMBER() lze použít k načtení konkrétní stránky dat s ohledem na hodnoty indexu počátečního řádku a maximálního počtu řádků, teď musíme tuto logiku implementovat jako metody v DAL a BLL.
Při vytváření tohoto dotazu musíme rozhodnout o pořadí, podle kterého budou výsledky seřazeny; pojďme produkty seřadit podle jejich názvu v abecedním pořadí. To znamená, že s vlastní implementací stránkování v tomto kurzu nebudeme moct vytvořit vlastní stránkovanou sestavu, než je možné řadit. V dalším kurzu se ale podíváme, jak se tyto funkce dají poskytnout.
V předchozí části jsme vytvořili metodu DAL jako ad hoc příkaz SQL. Analyzátor T-SQL v sadě Visual Studio používaný průvodcem TableAdapter se bohužel nelíbí OVER syntaxi používané funkcí ROW_NUMBER() . Proto musíme tuto metodu DAL vytvořit jako uloženou proceduru. V nabídce Zobrazit vyberte Průzkumníka serveru (nebo stiskněte Ctrl+Alt+S) a rozbalte NORTHWND.MDF uzel. Pokud chcete přidat novou uloženou proceduru, klikněte pravým tlačítkem myši na uzel Uložené procedury a zvolte Přidat novou uloženou proceduru (viz obrázek 6).
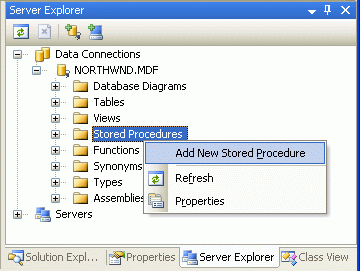
Obrázek 6: Přidání nové uložené procedury pro stránkování prostřednictvím produktů
Tato uložená procedura by měla přijmout dva celočíselné vstupní parametry @startRowIndex – a @maximumRows použít ROW_NUMBER() funkci seřazenou podle ProductName pole, která vrací pouze ty řádky větší než zadané @startRowIndex a menší než nebo rovno @startRowIndex + @maximumRow . Do nové uložené procedury zadejte následující skript a kliknutím na ikonu Uložit přidejte uloženou proceduru do databáze.
CREATE PROCEDURE dbo.GetProductsPaged
(
@startRowIndex int,
@maximumRows int
)
AS
SELECT ProductID, ProductName, SupplierID, CategoryID, QuantityPerUnit,
UnitPrice, UnitsInStock, UnitsOnOrder, ReorderLevel, Discontinued,
CategoryName, SupplierName
FROM
(
SELECT ProductID, ProductName, SupplierID, CategoryID, QuantityPerUnit,
UnitPrice, UnitsInStock, UnitsOnOrder, ReorderLevel, Discontinued,
(SELECT CategoryName
FROM Categories
WHERE Categories.CategoryID = Products.CategoryID) AS CategoryName,
(SELECT CompanyName
FROM Suppliers
WHERE Suppliers.SupplierID = Products.SupplierID) AS SupplierName,
ROW_NUMBER() OVER (ORDER BY ProductName) AS RowRank
FROM Products
) AS ProductsWithRowNumbers
WHERE RowRank > @startRowIndex AND RowRank <= (@startRowIndex + @maximumRows)
Jakmile vytvoříte uloženou proceduru, chvíli ji otestujte. V Průzkumníku GetProductsPaged serveru klikněte pravým tlačítkem myši na název uložené procedury a zvolte možnost Spustit. Visual Studio vás pak vyzve k zadání vstupních parametrů @startRowIndex a @maximumRow s (viz obrázek 7). Zkuste různé hodnoty a prohlédněte si výsledky.
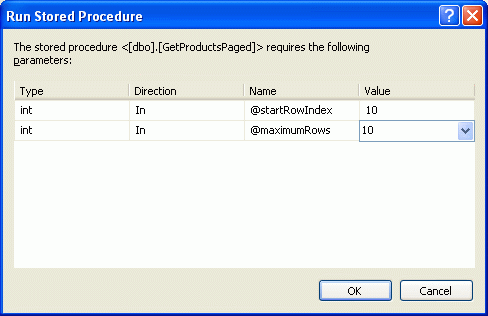 @startRowIndex a @maximumRows parametry / >
@startRowIndex a @maximumRows parametry / >
Obrázek 7: Zadání hodnoty pro parametry @startRowIndex@maximumRows
Po výběru těchto hodnot vstupních parametrů se v okně Výstup zobrazí výsledky. Obrázek 8 ukazuje výsledky při předávání 10 pro @startRowIndex parametry i @maximumRows parametry.
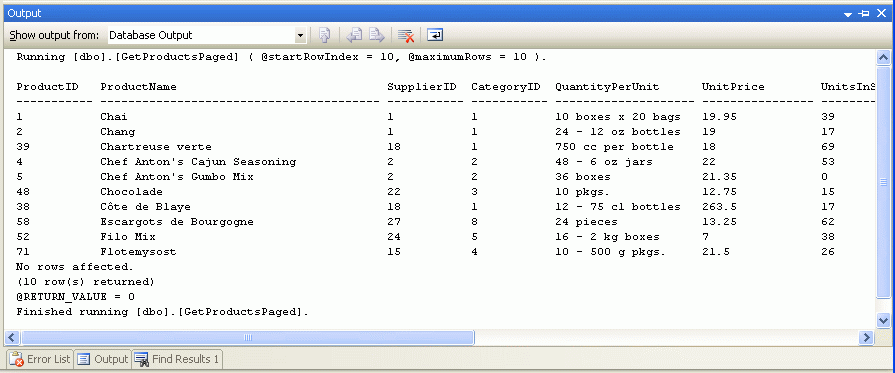
Obrázek 8: Záznamy, které by se zobrazily na druhé stránce dat, se vrátí (kliknutím zobrazíte obrázek v plné velikosti).
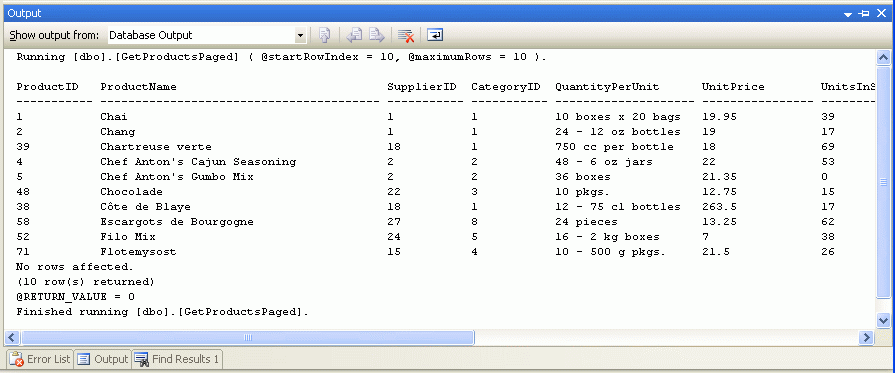{kind=link}
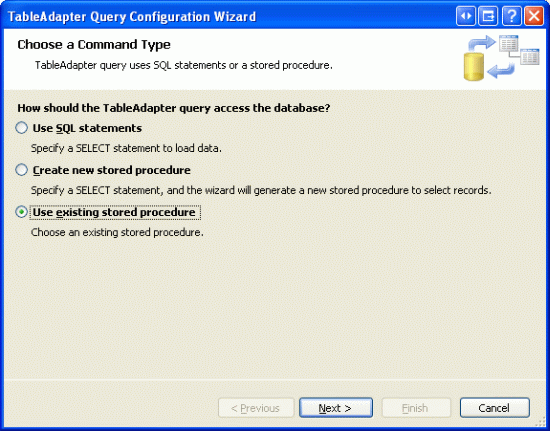
S touto vytvořenou uloženou procedurou jsme připraveni vytvořit metodu ProductsTableAdapter .
Northwind.xsd Otevřete typovou datovou sadu, klikněte pravým tlačítkem myši na položku ProductsTableAdaptera zvolte možnost Přidat dotaz. Místo vytvoření dotazu pomocí ad hoc příkazu SQL ho vytvořte pomocí existující uložené procedury.
Obrázek 9: Vytvoření metody DAL pomocí existující uložené procedury
Dále se zobrazí výzva k výběru uložené procedury, která se má vyvolat. V rozevíracím seznamu vyberte uloženou GetProductsPaged proceduru.
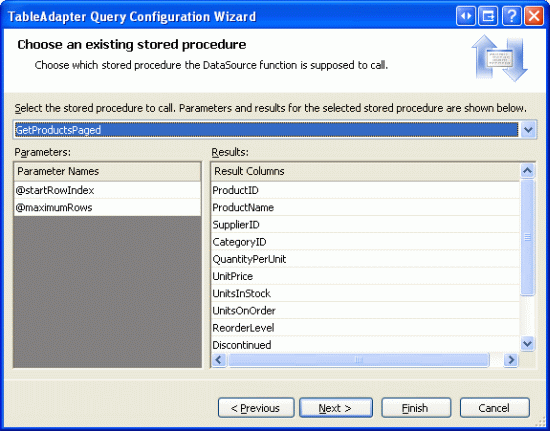
Obrázek 10: Volba uložené procedury GetProductsPaged z rozevíracího seznamu
Na další obrazovce se pak zobrazí dotaz, jaký druh dat vrátí uložená procedura: tabulková data, jedna hodnota nebo žádná hodnota. Vzhledem k tomu, že uložená procedura GetProductsPaged může vrátit více záznamů, indikuje, že vrací tabulková data.
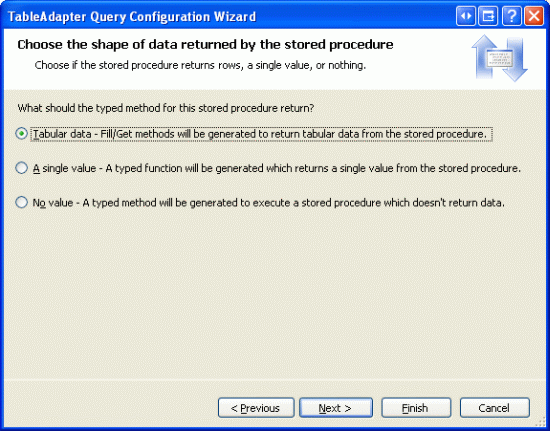
Obrázek 11: Indikuje, že uložená procedura vrací tabulková data
Nakonec uveďte názvy metod, které chcete vytvořit. Stejně jako v předchozích kurzech pokračujte a vytvářejte metody pomocí tabulky Fill a DataTable i Return a DataTable. Pojmenujte první metodu FillPaged a druhou GetProductsPaged.
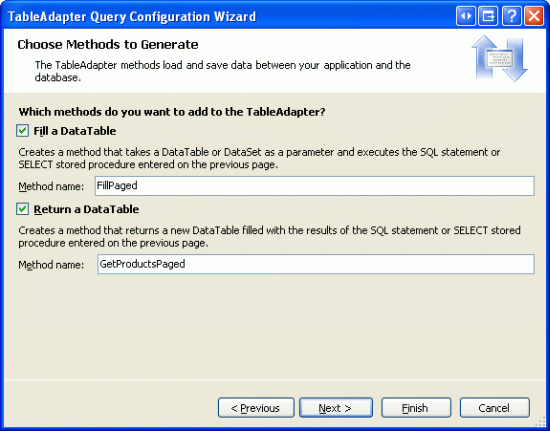
Obrázek 12: Pojmenování metod FillPaged a GetProductsPaged
Kromě vytvoření metody DAL pro vrácení konkrétní stránky produktů musíme také poskytovat takové funkce v BLL. Podobně jako metoda DAL musí metoda BLL s GetProductsPaged přijmout dva celočíselné vstupy pro zadání indexu počátečního řádku a maximální řádky a musí vrátit pouze ty záznamy, které spadají do zadaného rozsahu. Vytvořte takovou metodu BLL ve třídě ProductsBLL, která pouze volá do metody DAL s GetProductsPaged, například takto:
<System.ComponentModel.DataObjectMethodAttribute( _
System.ComponentModel.DataObjectMethodType.Select, False)> _
Public Function GetProductsPaged(startRowIndex As Integer, maximumRows As Integer) _
As Northwind.ProductsDataTable
Return Adapter.GetProductsPaged(startRowIndex, maximumRows)
End Function
Můžete použít libovolný název vstupních parametrů metody BLL, ale jak uvidíme krátce, rozhodnete se použít startRowIndex a maximumRows uložit nás z další části práce při konfiguraci ObjectDataSource pro použití této metody.
Krok 4: Konfigurace ObjectDataSource pro použití vlastního stránkování
S metodami BLL a DAL pro přístup k určité podmnožině záznamů jsou hotové, jsme připraveni vytvořit ovládací prvek GridView, který stránky prochází jeho podkladovými záznamy pomocí vlastního stránkování. Začněte tím, že otevřete EfficientPaging.aspx stránku ve PagingAndSorting složce, přidáte na stránku GridView a nakonfigurujete ji tak, aby používala nový ovládací prvek ObjectDataSource. V našich minulých kurzech jsme často měli ObjektDataSource nakonfigurovaný tak, aby používal metodu ProductsBLL třídy.GetProducts Tentokrát ale chceme použít metoduGetProductsPaged, protože GetProducts metoda vrátí všechnypouze konkrétní podmnožinu záznamů.
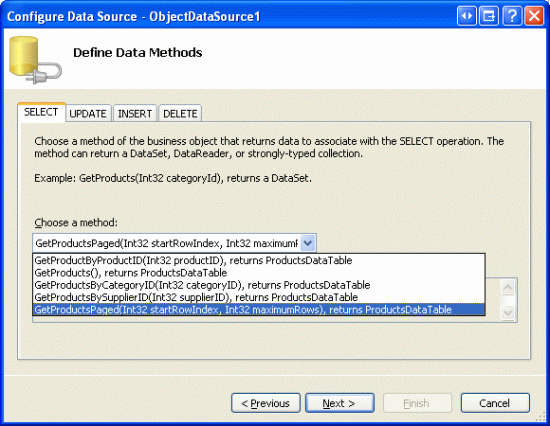
Obrázek 13: Konfigurace ObjectDataSource pro použití třídy ProductsBLL s GetProductsPaged – metoda
Vzhledem k tomu, že vytváříme GridView jen pro čtení, chvíli nastavte rozevírací seznam metody na kartách INSERT, UPDATE a DELETE na (None).
Dále průvodce ObjectDataSource vyzve nás k zadání zdrojů GetProductsPaged hodnot metod s startRowIndex a maximumRows vstupních parametrů. Tyto vstupní parametry budou ve skutečnosti nastaveny objektem GridView automaticky, takže jednoduše ponechte zdroj nastavený na None (Žádný) a klikněte na Dokončit.
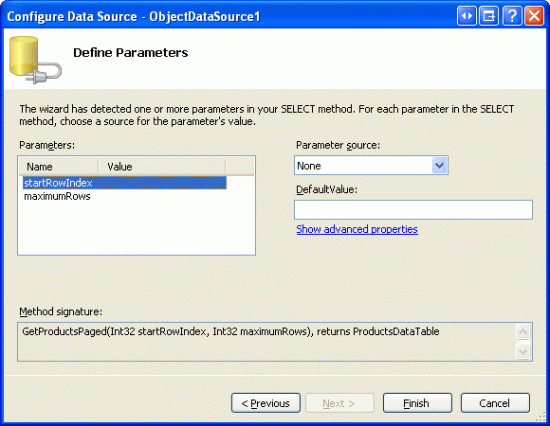
Obrázek 14: Ponechte zdroje vstupních parametrů jako žádné
Po dokončení průvodce ObjectDataSource bude GridView obsahovat BoundField nebo CheckBoxField pro každé pole dat produktu. Přizpůsobte si vzhled GridView podle potřeby. Rozhodl jsem se zobrazit pouze ProductName, , CategoryNameSupplierName, QuantityPerUnita UnitPrice BoundFields. Také nakonfigurujte GridView tak, aby podporoval stránkování zaškrtnutím políčka Povolit stránkování ve své inteligentní značce. Po těchto změnách by deklarativní kód GridView a ObjectDataSource měly vypadat podobně jako následující:
<asp:GridView ID="GridView1" runat="server" AutoGenerateColumns="False"
DataKeyNames="ProductID" DataSourceID="ObjectDataSource1" AllowPaging="True">
<Columns>
<asp:BoundField DataField="ProductName" HeaderText="Product"
SortExpression="ProductName" />
<asp:BoundField DataField="CategoryName" HeaderText="Category"
ReadOnly="True" SortExpression="CategoryName" />
<asp:BoundField DataField="SupplierName" HeaderText="Supplier"
SortExpression="SupplierName" />
<asp:BoundField DataField="QuantityPerUnit" HeaderText="Qty/Unit"
SortExpression="QuantityPerUnit" />
<asp:BoundField DataField="UnitPrice" DataFormatString="{0:c}"
HeaderText="Price" HtmlEncode="False" SortExpression="UnitPrice" />
</Columns>
</asp:GridView>
<asp:ObjectDataSource ID="ObjectDataSource1" runat="server"
OldValuesParameterFormatString="original_{0}" SelectMethod="GetProductsPaged"
TypeName="ProductsBLL">
<SelectParameters>
<asp:Parameter Name="startRowIndex" Type="Int32" />
<asp:Parameter Name="maximumRows" Type="Int32" />
</SelectParameters>
</asp:ObjectDataSource>
Pokud ale stránku navštívíte v prohlížeči, GridView není místem, kde se má najít.
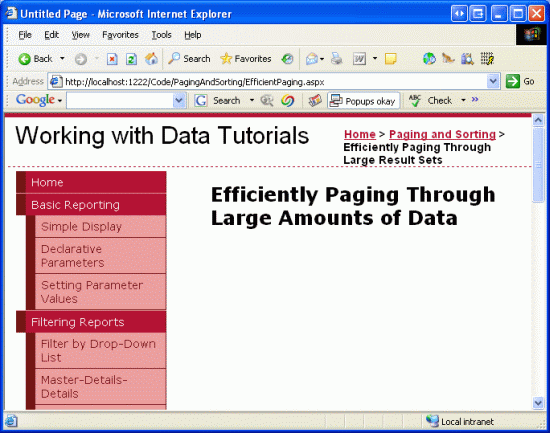
Obrázek 15: Objekt GridView se nezobrazuje
Objekt GridView chybí, protože ObjectDataSource aktuálně používá hodnotu 0 jako hodnoty pro oba GetProductsPagedstartRowIndex i maximumRows vstupní parametry. Výsledný dotaz SQL proto nevrací žádné záznamy, a proto není zobrazen Objekt GridView.
Abychom to mohli napravit, musíme nakonfigurovat ObjectDataSource tak, aby používal vlastní stránkování. To lze provést v následujících krocích:
-
Nastavte Vlastnost ObjectDataSource
EnablePagingnatruetuto hodnotu označuje ObjectDataSource, že musí předatSelectMethoddva další parametry: jeden pro zadání indexu počátečního řádku (StartRowIndexParameterName) a jeden pro zadání maximálního počtu řádků (MaximumRowsParameterName). -
Nastavte ObjectDataSource s
StartRowIndexParameterNameaMaximumRowsParameterNameVlastnosti Odpovídajícím způsobemStartRowIndexParameterNameaMaximumRowsParameterNamevlastnosti označují názvy vstupních parametrů předané doSelectMethodvlastní stránkovací účely. Ve výchozím nastavení jsoustartIndexRowtyto názvy parametrů amaximumRows, což je důvod, proč při vytvářeníGetProductsPagedmetody v BLL, použil jsem tyto hodnoty pro vstupní parametry. Pokud jste se rozhodli použít různé názvy parametrů pro metodu BLL,GetProductsPagednapříkladstartIndexmaxRows, například byste museli nastavit ObjectDataSource sStartRowIndexParameterNameaMaximumRowsParameterNamevlastnosti odpovídajícím způsobem (například startIndex proStartRowIndexParameterNamea maxRows proMaximumRowsParameterName). -
Nastavte ObjectDataSource vlastnost
SelectCountMethodna Název metody, která vrátí celkový počet záznamů, které jsou stránkovány prostřednictvím (TotalNumberOfProducts), vzpomeňte, žeProductsBLLmetoda třídy sTotalNumberOfProductsvrací celkový počet záznamů, které jsou stránkovány pomocí metody DAL, která spouštíSELECT COUNT(*) FROM Productsdotaz. Tyto informace potřebuje ObjectDataSource, aby bylo možné správně vykreslit stránkovací rozhraní. -
Odeberte a
startRowIndexmaximumRowselementy<asp:Parameter>z ObjectDataSource deklarativní revize při konfiguraci ObjectDataSource prostřednictvím průvodce, Visual Studio automaticky přidal dva<asp:Parameter>elementy proGetProductsPagedvstupní parametry metody. Nastavením naEnablePaging, tyto parametry budou předány automaticky; pokud se zobrazí také v deklarativní syntaxi, ObjectDataSource se pokusí předattrueparametry a dva parametry metoděGetProductsPaged.TotalNumberOfProductsPokud zapomenete tyto<asp:Parameter>prvky odebrat, při návštěvě stránky v prohlížeči se zobrazí chybová zpráva jako: ObjectDataSource ObjectDataSource nebylo možné najít ne generickou metodu TotalNumberOfProducts, která má parametry: startRowIndex, maximumRows.
Po provedení těchto změn by deklarativní syntaxe ObjectDataSource měla vypadat takto:
<asp:ObjectDataSource ID="ObjectDataSource1" runat="server"
OldValuesParameterFormatString="original_{0}" SelectMethod="GetProductsPaged"
TypeName="ProductsBLL" EnablePaging="True" SelectCountMethod="
TotalNumberOfProducts">
</asp:ObjectDataSource>
Všimněte si, že vlastnosti EnablePaging byly SelectCountMethod nastaveny a <asp:Parameter> prvky byly odebrány. Obrázek 16 ukazuje snímek obrazovky okno Vlastnosti po provedení těchto změn.

Obrázek 16: Použití vlastního stránkování konfigurace ovládacího prvku ObjectDataSource
Po provedení těchto změn navštivte tuto stránku v prohlížeči. Mělo by se zobrazit 10 produktů seřazených abecedně. Chvíli si projděte data o jedné stránce. I když neexistuje žádný vizuální rozdíl od perspektivy koncového uživatele mezi výchozím stránkováním a vlastním stránkováním, vlastní stránkování efektivněji stránkuje velké objemy dat, protože načítá jenom ty záznamy, které je potřeba zobrazit pro danou stránku.
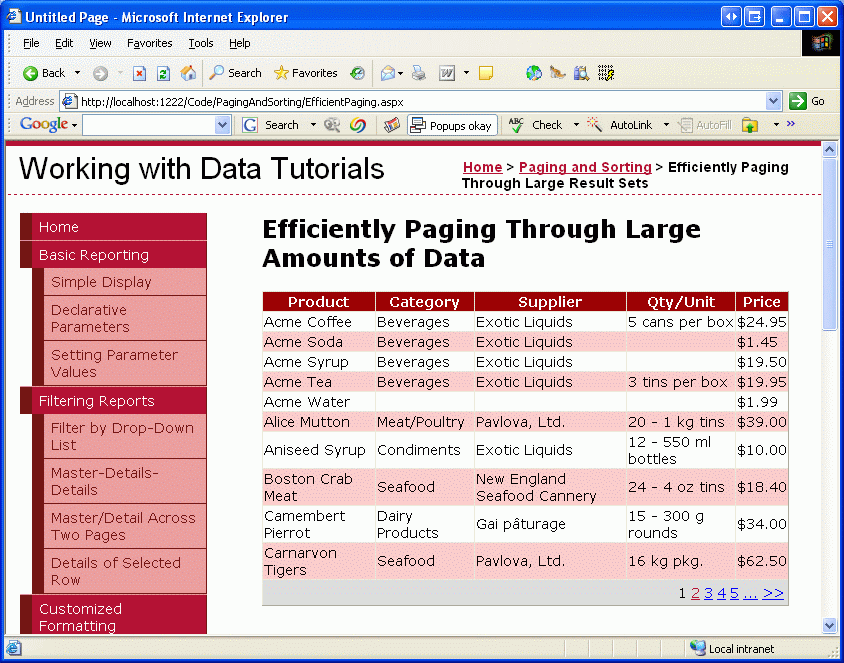
Obrázek 17: Data seřazená podle názvu produktu jsou stránkována pomocí vlastního stránkování (kliknutím zobrazíte obrázek v plné velikosti).
{kind=link}
Poznámka:
Při vlastním stránkování je hodnota počtu stránek vrácená objektem ObjectDataSource SelectCountMethod uložena ve stavu zobrazení GridView. Jiné GridView proměnné PageIndex, , EditIndex, SelectedIndexDataKeyskolekce a tak dále jsou uloženy ve stavu ovládacího prvku, který je trvalý bez ohledu na hodnotu GridView EnableViewState vlastnost.
PageCount Vzhledem k tomu, že hodnota je trvalá napříč postbacky pomocí stavu zobrazení, při použití stránkovacího rozhraní, které obsahuje odkaz, který vás přesměruje na poslední stránku, je nezbytné, aby byl stav zobrazení GridView povolený. (Pokud vaše stránkovací rozhraní neobsahuje přímý odkaz na poslední stránku, můžete zakázat stav zobrazení.)
Kliknutí na poslední odkaz stránky způsobí postback a dává GridView pokyn k aktualizaci jeho PageIndex vlastnosti. Pokud je odkaz na poslední stránku kliknut, GridView přiřadí jeho PageIndex vlastnost hodnotě menší než jeho PageCount vlastnost. Pokud je stav zobrazení zakázaný, PageCount hodnota se ztratí napříč postbacky a PageIndex místo toho se přiřadí maximální celočíselná hodnota. Dále se GridView pokusí určit počáteční index řádku vynásobením PageSize a PageCount vlastností. Výsledkem je OverflowException , že produkt překračuje maximální povolenou celočíselnou velikost.
Implementace vlastního stránkování a řazení
Naše aktuální vlastní implementace stránkování vyžaduje, aby pořadí, podle kterého jsou data stránkována prostřednictvím staticky při vytváření GetProductsPaged uložené procedury. Možná jste si však poznamenali, že inteligentní značka GridView s obsahuje kromě možnosti Povolit stránkování zaškrtávací políčko Povolit řazení. Přidání podpory řazení do GridView s naší aktuální vlastní implementací stránkování bohužel seřadí jenom záznamy na aktuálně zobrazené stránce dat. Pokud například nakonfigurujete GridView tak, aby podporoval stránkování, a pak při prohlížení první stránky dat seřadí podle názvu produktu v sestupném pořadí, obrátí pořadí produktů na stránce 1. Jak ukazuje obrázek 18, například Carnarvon Tigers jako první produkt při řazení v obráceném abecedním pořadí, který ignoruje 71 dalších produktů, které přicházejí po Carnarvon Tigers, abecedně; Řazení se považuje pouze za záznamy na první stránce.
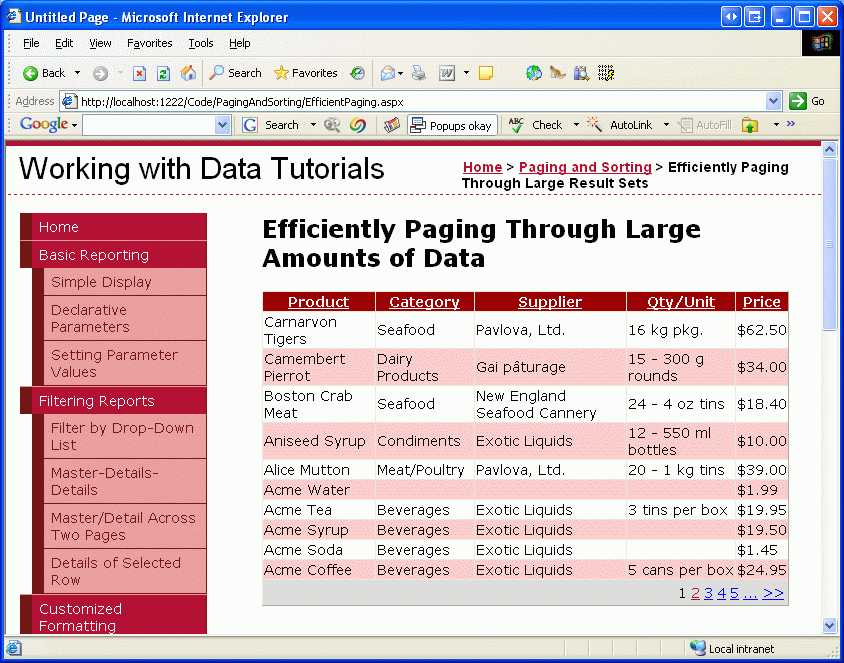
Obrázek 18: Seřadí se pouze data zobrazená na aktuální stránce (kliknutím zobrazíte obrázek v plné velikosti).
{kind=link}
Řazení se vztahuje pouze na aktuální stránku dat, protože řazení probíhá po načtení dat z metody BLL GetProductsPaged a tato metoda vrátí pouze tyto záznamy pro konkrétní stránku. Abychom mohli správně implementovat řazení, musíme předat výraz GetProductsPaged řazení metodě, aby data byla před vrácením konkrétní stránky dat správně seřazena. V dalším kurzu se dozvíme, jak toho dosáhnout.
Implementace vlastního stránkování a odstraňování
Pokud povolíte odstranění funkcí v Objektu GridView, jehož data jsou stránkována pomocí vlastních technik stránkování, zjistíte, že při odstranění posledního záznamu z poslední stránky GridView zmizí místo vhodného dekrementace GridView s PageIndex. Pokud chcete tuto chybu reprodukovat, povolte odstranění pro kurz, který jsme právě vytvořili. Přejděte na poslední stránku (strana 9), kde byste měli vidět jeden produkt, protože stránkujeme až 81 produktů, 10 produktů najednou. Odstraňte tento produkt.
Po odstranění posledního produktu by funkce GridView měla automaticky přejít na osmou stránku a tato funkce se zobrazí s výchozím stránkováním. Při vlastním stránkování však po odstranění posledního produktu na poslední stránce GridView úplně zmizí z obrazovky. Přesný důvod , proč k tomu dojde, je trochu nad rámec tohoto kurzu. Informace o zdroji tohoto problému najdete v tématu Odstranění posledního záznamu na poslední stránce z objektu GridView s vlastním stránkováním podrobností nízké úrovně. Stručně řečeno, důvodem je následující posloupnost kroků, které provádí GridView po kliknutí na tlačítko Odstranit:
- Odstranění záznamu
- Získejte odpovídající záznamy, které se mají zobrazit pro zadané
PageIndexaPageSize - Zkontrolujte, jestli
PageIndexnepřekračuje počet stránek dat ve zdroji dat. Pokud ano, automaticky dekrementujte vlastnost GridView sPageIndex. - Vytvoření vazby příslušné stránky dat k objektu GridView pomocí záznamů získaných v kroku 2
Problém vychází ze skutečnosti, že v kroku 2 použitý PageIndex při výběru záznamů k zobrazení je stále PageIndex na poslední stránce, jejíž jediný záznam byl právě odstraněn. V kroku 2 se proto nevrácejí žádné záznamy od poslední stránky dat, které již neobsahují žádné záznamy. Poté v kroku 3 GridView zjistí, že jeho PageIndex vlastnost je větší než celkový počet stránek ve zdroji dat (protože jsme odstranili poslední záznam na poslední stránce) a tím se zmenší jeho PageIndex vlastnost. V kroku 4 se GridView pokusí vytvořit vazbu k datům načteným v kroku 2; v kroku 2 však nebyly vráceny žádné záznamy, a proto výsledkem je prázdný Objekt GridView. U výchozího stránkování se tento problém neprovádí, protože v kroku 2 se všechny záznamy načítají ze zdroje dat.
Abychom to vyřešili, máme dvě možnosti. Prvním je vytvoření obslužné rutiny události pro obslužnou rutinu události GridView RowDeleted , která určuje, kolik záznamů se zobrazilo na stránce, která byla právě odstraněna. Pokud byl pouze jeden záznam, pak právě odstraněný záznam musel být poslední a musíme dekrementovat GridView s PageIndex. Samozřejmě chceme aktualizovat PageIndex pouze v případě, že operace odstranění byla skutečně úspěšná, což lze určit zajištěním, e.Exception že vlastnost je null.
Tento přístup funguje, protože aktualizuje PageIndex krok 1, ale před krokem 2. Proto se v kroku 2 vrátí příslušná sada záznamů. K tomuto účelu použijte kód podobný následujícímu:
Protected Sub GridView1_RowDeleted(sender As Object, e As GridViewDeletedEventArgs) _
Handles GridView1.RowDeleted
' If we just deleted the last row in the GridView, decrement the PageIndex
If e.Exception Is Nothing AndAlso GridView1.Rows.Count = 1 Then
' we just deleted the last row
GridView1.PageIndex = Math.Max(0, GridView1.PageIndex - 1)
End If
End Sub
Alternativním alternativním řešením je vytvořit obslužnou rutinu události pro událost ObjectDataSource RowDeleted a nastavit AffectedRows vlastnost na hodnotu 1. Po odstranění záznamu v kroku 1 (ale před opětovným načtením dat v kroku 2) GridView aktualizuje jeho PageIndex vlastnost, pokud operace ovlivnila jeden nebo více řádků.
AffectedRows Vlastnost však není nastavena ObjectDataSource, a proto je tento krok vynechán. Jedním ze způsobů, jak tento krok provést, je ruční nastavení AffectedRows vlastnosti, pokud se operace odstranění úspěšně dokončí. Toho lze dosáhnout pomocí kódu, jako je následující:
Protected Sub ObjectDataSource1_Deleted( _
sender As Object, e As ObjectDataSourceStatusEventArgs) _
Handles ObjectDataSource1.Deleted
' If we get back a Boolean value from the DeleteProduct method and it's true, then
' we successfully deleted the product. Set AffectedRows to 1
If TypeOf e.ReturnValue Is Boolean AndAlso CType(e.ReturnValue, Boolean) = True Then
e.AffectedRows = 1
End If
End Sub
Kód pro oba tyto obslužné rutiny událostí lze najít v kódu za třídou příkladu EfficientPaging.aspx .
Porovnání výkonu výchozího a vlastního stránkování
Vzhledem k tomu, že vlastní stránkování načte jenom potřebné záznamy, zatímco výchozí stránkování vrátí všechny záznamy pro každou zobrazenou stránku, je jasné, že vlastní stránkování je efektivnější než výchozí stránkování. Ale jak mnohem efektivnější je vlastní stránkování? Jaký druh zvýšení výkonu lze vidět přechodem z výchozího stránkování na vlastní stránkování?
Bohužel neexistuje žádná velikost, která by tady odpovídala všem. Zvýšení výkonu závisí na řadě faktorů, nejvýraznější dva jsou počet stránkovaných záznamů a zatížení databázového serveru a komunikačních kanálů mezi webovým serverem a databázovým serverem. U malých tabulek s několika desítkami záznamů může být rozdíl v výkonu zanedbatelný. U velkých tabulek s tisíci až stovkami tisíc řádků je ale rozdíl v výkonu akutní.
Článek vlastního stránkování v ASP.NET 2.0 s SQL Serverem 2005 obsahuje některé testy výkonu, které jsem spustil, aby se projevily rozdíly v výkonu mezi těmito dvěma stránkovacími technikami při stránkování v tabulce databáze s 50 000 záznamy. V těchtotestch ASP.NET ASP.NET ch Mějte na paměti, že tyto testy byly spuštěny na mém vývojovém poli s jedním aktivním uživatelem, a proto nejsou efektivní a nenapodobují typické vzory zatížení webu. Bez ohledu na to, jaké výsledky znázorňují relativní rozdíly v době provádění výchozího a vlastního stránkování při práci s dostatečně velkým množstvím dat.
| Prům. Doba trvání (s) | Čte | |
|---|---|---|
| Výchozí stránkovací nástroj SQL Profiler | 1.411 | 383 |
| Vlastní stránkovací nástroj SQL Profiler | 0.002 | 29 |
| Výchozí trasování stránkování ASP.NET | 2.379 | – |
| Vlastní trasování stránkování ASP.NET | 0.029 | – |
Jak vidíte, načtení konkrétní stránky dat vyžadovalo průměrně 354 méně čtení a dokončilo se za zlomek času. Na stránce ASP.NET byla vlastní stránka schopna vykreslit téměř 1/100th času, který trvalo při použití výchozího stránkování.
Shrnutí
Výchozí stránkování je cinch, který implementuje, stačí zaškrtnout políčko Povolit stránkování v inteligentní značce ovládacího prvku web dat, ale taková jednoduchost se blíží nákladům na výkon. Při výchozím stránkování platí, že když uživatel požádá o libovolnou stránku dat , vrátí se všechny záznamy, i když se může zobrazit jenom malý zlomek. Pro boj s touto režií za výkon nabízí ObjectDataSource alternativní stránkovací možnost vlastní stránkování.
Vlastní stránkování se sice zlepšuje při výchozích problémech s výkonem stránkování načtením jenom těch záznamů, které je potřeba zobrazit, ale je více zapojené do implementace vlastního stránkování. Nejprve se musí zapsat dotaz, který správně (a efektivně) přistupuje ke konkrétní podmnožině požadovaných záznamů. Toho lze dosáhnout mnoha způsoby; ten, který jsme prozkoumali v tomto kurzu, je použít novou ROW_NUMBER() funkci SYSTÉMU SQL Server 2005 k řazení výsledků a pak vrátit pouze ty výsledky, jejichž pořadí spadá do zadaného rozsahu. Kromě toho musíme přidat způsob, jak určit celkový počet stránkovaných záznamů. Po vytvoření těchto metod DAL a BLL musíme také nakonfigurovat ObjectDataSource, aby bylo možné určit, kolik záznamů se stránkuje, a správně předat počáteční řádek index a maximální řádky hodnoty BLL.
I když implementace vlastního stránkování vyžaduje řadu kroků a není tak jednoduché jako výchozí stránkování, je vlastní stránkování při stránkování dostatečně velkým množstvím dat nezbytné. Jak se ukázaly výsledky, vlastní stránkování může vyřadit sekundy mimo dobu vykreslování ASP.NET stránky a může tížit databázový server o jeden nebo více řádů.
Šťastné programování!
O autorovi
Scott Mitchell, autor sedmi knih ASP/ASP.NET a zakladatel 4GuysFromRolla.com, pracuje s webovými technologiemi Microsoftu od roku 1998. Scott pracuje jako nezávislý konzultant, trenér a spisovatel. Jeho nejnovější kniha je Sams Teach Yourself ASP.NET 2.0 za 24 hodin. Může být dosažitelný na mitchell@4GuysFromRolla.comadrese .