Kvalita rozpoznávání testů vlastního modelu řeči
V sadě Speech Studio můžete zkontrolovat kvalitu rozpoznávání vlastního modelu řeči. Nahraný zvuk můžete přehrát a určit, jestli je zadaný výsledek rozpoznávání správný. Po úspěšném vytvoření testu se můžete podívat, jak model přepsal zvukovou datovou sadu, nebo porovnat výsledky ze dvou modelů vedle sebe.
Testování modelu vedle sebe je užitečné k ověření toho, který model rozpoznávání řeči je pro aplikaci nejvhodnější. Cílová míra přesnosti, která vyžaduje vstup datových sad přepisu, najdete v tématu Kvantitativní testování modelu.
Důležité
Při testování systém provede přepis. Je důležité mít na paměti, protože ceny se liší podle nabídky služeb a úrovně předplatného. Nejnovější podrobnosti najdete vždy na oficiálních cenách služeb Azure AI.
Vytvoření testu
Podle těchto pokynů vytvořte test:
Přihlaste se k sadě Speech Studio.
Přejděte do služby Speech Studio>Custom Speech a ze seznamu vyberte název projektu.
Vyberte Testovací modely>Vytvořit nový test.
Vyberte Zkontrolovat kvalitu (pouze zvuková data)>Další.
Zvolte datovou sadu zvuku, kterou chcete použít k testování, a pak vyberte Další. Pokud nejsou dostupné žádné datové sady, zrušte nastavení a pak přejděte do nabídky datových sad služby Speech a nahrajte datové sady.
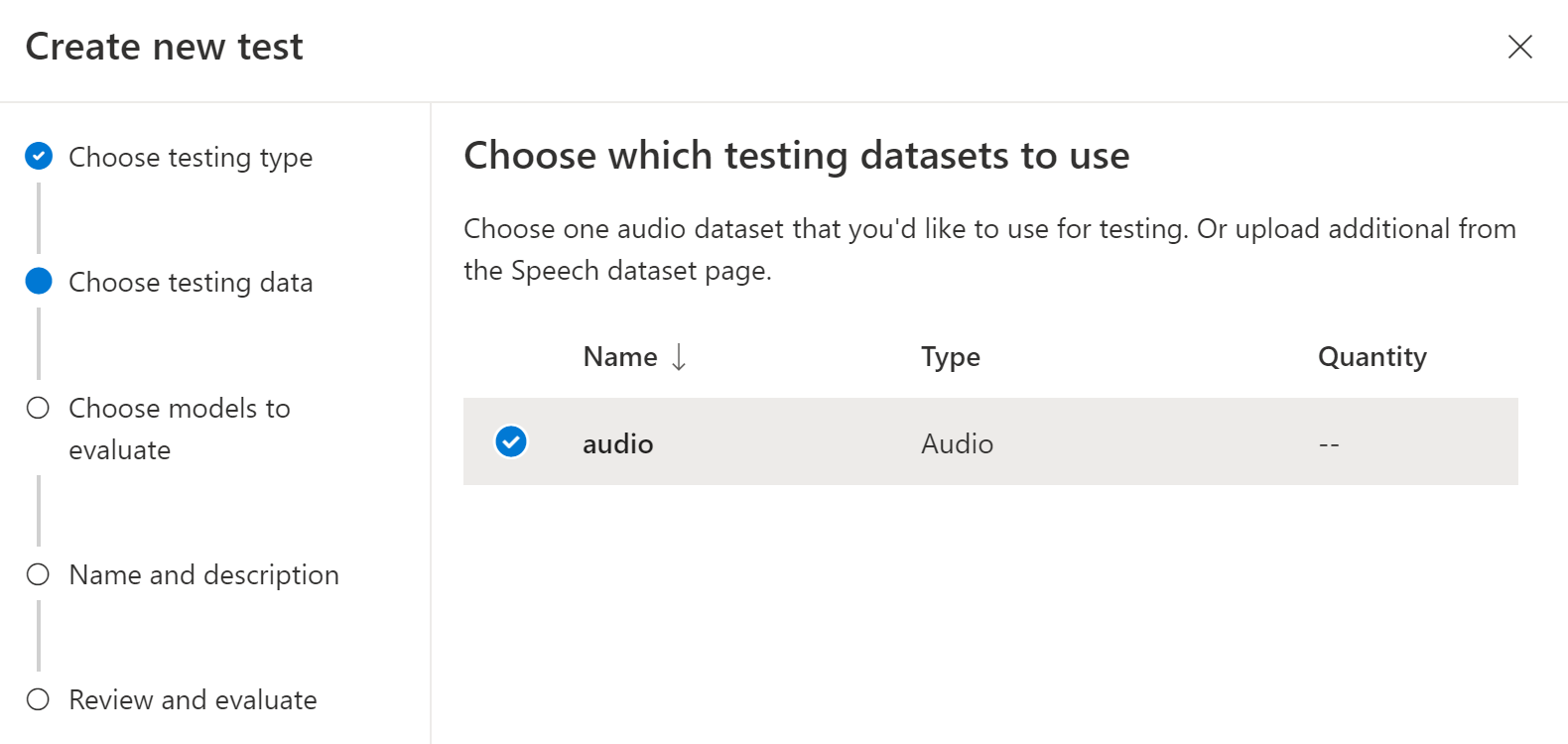
Vyberte jeden nebo dva modely, abyste mohli vyhodnotit a porovnat přesnost.
Zadejte název a popis testu a pak vyberte Další.
Zkontrolujte nastavení a pak vyberte Uložit a zavřít.
K vytvoření testu použijte spx csr evaluation create příkaz. Parametry požadavku se sestaví podle následujících pokynů:
projectNastavte parametr na ID existujícího projektu. Tento parametr se doporučuje, abyste mohli test zobrazit také v sadě Speech Studio. Spuštěnímspx csr project listpříkazu můžete získat dostupné projekty.- Nastavte požadovaný
model1parametr na ID modelu, který chcete testovat. - Nastavte požadovaný
model2parametr na ID jiného modelu, který chcete testovat. Pokud nechcete porovnat dva modely, použijte stejný model pro obojímodel1imodel2. - Nastavte požadovaný
datasetparametr na ID datové sady, kterou chcete použít pro test. languageNastavte parametr, jinak rozhraní příkazového řádku služby Speech nastaví ve výchozím nastavení "en-US". Tento parametr by měl být národním prostředím obsahu datové sady. Národní prostředí nelze později změnit. Parametr Rozhraní příkazovéholocaleřádkulanguageslužby Speech odpovídá vlastnosti v požadavku JSON a odpovědi.- Nastavte požadovaný
nameparametr. Tento parametr je název zobrazený v sadě Speech Studio. Parametr Rozhraní příkazovéhodisplayNameřádkunameslužby Speech odpovídá vlastnosti v požadavku JSON a odpovědi.
Tady je příklad příkazu Rozhraní příkazového řádku služby Speech, který vytvoří test:
spx csr evaluation create --api-version v3.2 --project 0198f569-cc11-4099-a0e8-9d55bc3d0c52 --dataset 23b6554d-21f9-4df1-89cb-f84510ac8d23 --model1 13fb305e-09ad-4bce-b3a1-938c9124dda3 --model2 13fb305e-09ad-4bce-b3a1-938c9124dda3 --name "My Inspection" --description "My Inspection Description"
Měl by se zobrazit text odpovědi v následujícím formátu:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": -1.0,
"sentenceErrorRate1": -1.0,
"sentenceCount1": -1,
"wordCount1": -1,
"correctWordCount1": -1,
"wordSubstitutionCount1": -1,
"wordDeletionCount1": -1,
"wordInsertionCount1": -1,
"wordErrorRate2": -1.0,
"sentenceErrorRate2": -1.0,
"sentenceCount2": -1,
"wordCount2": -1,
"correctWordCount2": -1,
"wordSubstitutionCount2": -1,
"wordDeletionCount2": -1,
"wordInsertionCount2": -1
},
"lastActionDateTime": "2024-07-14T21:21:39Z",
"status": "NotStarted",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
Vlastnost nejvyšší úrovně self v textu odpovědi je identifikátor URI vyhodnocení. Pomocí tohoto identifikátoru URI získáte podrobnosti o výsledcích projektu a testu. Tento identifikátor URI také použijete k aktualizaci nebo odstranění vyhodnocení.
V případě nápovědy k rozhraní příkazového řádku služby Speech s vyhodnoceními spusťte následující příkaz:
spx help csr evaluation
K vytvoření testu použijte operaci Evaluations_Create rozhraní REST API pro převod řeči na text. Sestavte tělo požadavku podle následujících pokynů:
projectNastavte vlastnost na identifikátor URI existujícího projektu. Tato vlastnost se doporučuje, abyste si také mohli test prohlédnout v sadě Speech Studio. Můžete vytvořit Projects_List žádost o získání dostupných projektů.- Nastavte požadovanou
model1vlastnost na identifikátor URI modelu, který chcete testovat. - Nastavte požadovanou
model2vlastnost na identifikátor URI jiného modelu, který chcete testovat. Pokud nechcete porovnat dva modely, použijte stejný model pro obojímodel1imodel2. - Nastavte požadovanou
datasetvlastnost na identifikátor URI datové sady, kterou chcete použít pro test. - Nastavte požadovanou
localevlastnost. Tato vlastnost by měla být národním prostředím obsahu datové sady. Národní prostředí nelze později změnit. - Nastavte požadovanou
displayNamevlastnost. Tato vlastnost je název zobrazený v sadě Speech Studio.
Vytvořte požadavek HTTP POST pomocí identifikátoru URI, jak je znázorněno v následujícím příkladu. Nahraďte YourSubscriptionKey klíčem prostředku služby Speech, nahraďte YourServiceRegion oblastí prostředků služby Speech a nastavte vlastnosti textu požadavku, jak jsme popsali dříve.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey" -H "Content-Type: application/json" -d '{
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"displayName": "My Inspection",
"description": "My Inspection Description",
"locale": "en-US"
}' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations"
Měl by se zobrazit text odpovědi v následujícím formátu:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": -1.0,
"sentenceErrorRate1": -1.0,
"sentenceCount1": -1,
"wordCount1": -1,
"correctWordCount1": -1,
"wordSubstitutionCount1": -1,
"wordDeletionCount1": -1,
"wordInsertionCount1": -1,
"wordErrorRate2": -1.0,
"sentenceErrorRate2": -1.0,
"sentenceCount2": -1,
"wordCount2": -1,
"correctWordCount2": -1,
"wordSubstitutionCount2": -1,
"wordDeletionCount2": -1,
"wordInsertionCount2": -1
},
"lastActionDateTime": "2024-07-14T21:21:39Z",
"status": "NotStarted",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
Vlastnost nejvyšší úrovně self v textu odpovědi je identifikátor URI vyhodnocení. Pomocí tohoto identifikátoru URI získáte podrobnosti o výsledcích projektu a testu vyhodnocení. Tento identifikátor URI také použijete k aktualizaci nebo odstranění vyhodnocení.
Získání výsledků testu
Měli byste získat výsledky testu a zkontrolovat zvukové datové sady v porovnání s výsledky přepisu pro každý model.
Pokud chcete získat výsledky testu, postupujte takto:
- Přihlaste se k sadě Speech Studio.
- Vyberte Custom speech> Your project name >Test models.
- Vyberte odkaz podle názvu testu.
- Po dokončení testu by se měly zobrazit výsledky, které obsahují číslo WER pro každý testovaný model.
Tato stránka obsahuje seznam všech promluv v datové sadě a výsledky rozpoznávání spolu s přepisem odeslané datové sady. Můžete přepínat různé typy chyb, včetně vložení, odstranění a nahrazení. Poslechem zvuku a porovnáním výsledků rozpoznávání v jednotlivých sloupcích se můžete rozhodnout, který model vyhovuje vašim potřebám, a určit, kde se vyžaduje další trénování a vylepšení.
Pokud chcete získat výsledky testu, použijte spx csr evaluation status příkaz. Parametry požadavku se sestaví podle následujících pokynů:
- Nastavte požadovaný
evaluationparametr na ID vyhodnocení, které chcete získat výsledky testu.
Tady je příklad příkazu Rozhraní příkazového řádku služby Speech, který získá výsledky testu:
spx csr evaluation status --api-version v3.2 --evaluation 9c06d5b1-213f-4a16-9069-bc86efacdaac
Modely, zvuková datová sada, přepisy a další podrobnosti se vrátí v textu odpovědi.
Měl by se zobrazit text odpovědi v následujícím formátu:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": 0.028900000000000002,
"sentenceErrorRate1": 0.667,
"tokenErrorRate1": 0.12119999999999999,
"sentenceCount1": 3,
"wordCount1": 173,
"correctWordCount1": 170,
"wordSubstitutionCount1": 2,
"wordDeletionCount1": 1,
"wordInsertionCount1": 2,
"tokenCount1": 165,
"correctTokenCount1": 145,
"tokenSubstitutionCount1": 10,
"tokenDeletionCount1": 1,
"tokenInsertionCount1": 9,
"tokenErrors1": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
},
"wordErrorRate2": 0.028900000000000002,
"sentenceErrorRate2": 0.667,
"tokenErrorRate2": 0.12119999999999999,
"sentenceCount2": 3,
"wordCount2": 173,
"correctWordCount2": 170,
"wordSubstitutionCount2": 2,
"wordDeletionCount2": 1,
"wordInsertionCount2": 2,
"tokenCount2": 165,
"correctTokenCount2": 145,
"tokenSubstitutionCount2": 10,
"tokenDeletionCount2": 1,
"tokenInsertionCount2": 9,
"tokenErrors2": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
}
},
"lastActionDateTime": "2024-07-14T21:22:45Z",
"status": "Succeeded",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
V případě nápovědy k rozhraní příkazového řádku služby Speech s vyhodnoceními spusťte následující příkaz:
spx help csr evaluation
Pokud chcete získat výsledky testu, začněte pomocí operace Evaluations_Get rozhraní REST API pro převod řeči na text.
Vytvořte požadavek HTTP GET pomocí identifikátoru URI, jak je znázorněno v následujícím příkladu. Nahraďte YourEvaluationId id vyhodnocení, nahraďte YourSubscriptionKey klíčem prostředku služby Speech a nahraďte YourServiceRegion oblastí prostředků služby Speech.
curl -v -X GET "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/YourEvaluationId" -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey"
Modely, zvuková datová sada, přepisy a další podrobnosti se vrátí v textu odpovědi.
Měl by se zobrazit text odpovědi v následujícím formátu:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": 0.028900000000000002,
"sentenceErrorRate1": 0.667,
"tokenErrorRate1": 0.12119999999999999,
"sentenceCount1": 3,
"wordCount1": 173,
"correctWordCount1": 170,
"wordSubstitutionCount1": 2,
"wordDeletionCount1": 1,
"wordInsertionCount1": 2,
"tokenCount1": 165,
"correctTokenCount1": 145,
"tokenSubstitutionCount1": 10,
"tokenDeletionCount1": 1,
"tokenInsertionCount1": 9,
"tokenErrors1": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
},
"wordErrorRate2": 0.028900000000000002,
"sentenceErrorRate2": 0.667,
"tokenErrorRate2": 0.12119999999999999,
"sentenceCount2": 3,
"wordCount2": 173,
"correctWordCount2": 170,
"wordSubstitutionCount2": 2,
"wordDeletionCount2": 1,
"wordInsertionCount2": 2,
"tokenCount2": 165,
"correctTokenCount2": 145,
"tokenSubstitutionCount2": 10,
"tokenDeletionCount2": 1,
"tokenInsertionCount2": 9,
"tokenErrors2": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
}
},
"lastActionDateTime": "2024-07-14T21:22:45Z",
"status": "Succeeded",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
Porovnání přepisu se zvukem
Výstup přepisu můžete zkontrolovat podle každého testovaného modelu na základě datové sady vstupu zvuku. Pokud jste do testu zahrnuli dva modely, můžete porovnat jejich kvalitu přepisu vedle sebe.
Kontrola kvality přepisů:
- Přihlaste se k sadě Speech Studio.
- Vyberte Custom speech> Your project name >Test models.
- Vyberte odkaz podle názvu testu.
- Při čtení odpovídajícího přepisu modelem přehraje zvukový soubor.
Pokud testovací datová sada obsahovala více zvukových souborů, zobrazí se v tabulce několik řádků. Pokud jste do testu zahrnuli dva modely, zobrazí se přepisy ve sloupcích vedle sebe. Rozdíly v přepisu mezi modely se zobrazují v modrém písmu textu.
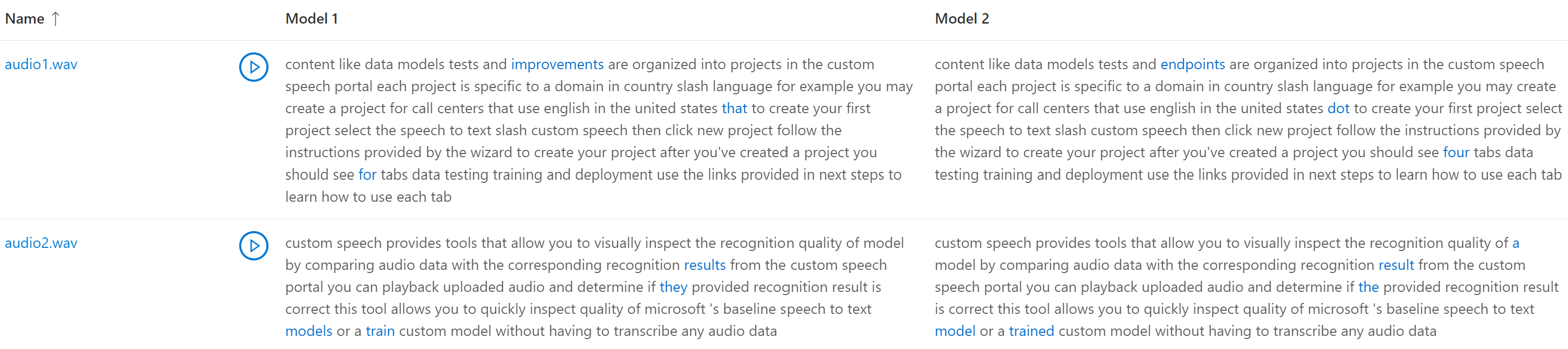
Testovací datová sada zvuku, přepisy a testované modely se vrátí ve výsledcích testu. Pokud byl testován pouze jeden model, model1 hodnota odpovídá model2a transcription1 hodnota odpovídá transcription2.
Kontrola kvality přepisů:
- Pokud ještě nemáte kopii, stáhněte si datovou sadu zvukového testu.
- Stáhněte si výstupní přepisy.
- Při čtení odpovídajícího přepisu modelem přehraje zvukový soubor.
Pokud porovnáváte kvalitu mezi dvěma modely, věnujte zvláštní pozornost rozdílům mezi přepisy jednotlivých modelů.
Testovací datová sada zvuku, přepisy a testované modely se vrátí ve výsledcích testu. Pokud byl testován pouze jeden model, model1 hodnota odpovídá model2a transcription1 hodnota odpovídá transcription2.
Kontrola kvality přepisů:
- Pokud ještě nemáte kopii, stáhněte si datovou sadu zvukového testu.
- Stáhněte si výstupní přepisy.
- Při čtení odpovídajícího přepisu modelem přehraje zvukový soubor.
Pokud porovnáváte kvalitu mezi dvěma modely, věnujte zvláštní pozornost rozdílům mezi přepisy jednotlivých modelů.