Vytvoření vlastního modelu analýzy obrázků
Důležité
Tato funkce je teď zastaralá. 31. března 2025 se vyřadí vlastní klasifikace obrázků Azure AI 4.0, rozpoznávání vlastních objektů a rozhraní API verze Preview pro rozpoznávání produktů. Po tomto datu se volání rozhraní API do těchto služeb nezdaří.
Pokud chcete zachovat hladký provoz modelů, přejděte na Azure AI Custom Vision, který je teď obecně dostupný. Custom Vision nabízí podobné funkce jako tyto vyřazené funkce.
Image Analysis 4.0 umožňuje trénovat vlastní model pomocí vlastních trénovacích imagí. Ručním popiskem obrázků můžete model vytrénovat tak, aby na obrázky použily vlastní značky (klasifikace obrázků) nebo detekují vlastní objekty (rozpoznávání objektů). Modely analýzy obrázků 4.0 jsou zvláště efektivní při učení s několika snímky , takže můžete získat přesné modely s méně trénovacími daty.
V této příručce se dozvíte, jak vytvořit a vytrénovat vlastní model klasifikace obrázků. Uvádíme několik rozdílů mezi trénováním modelu klasifikace obrázků a modelem detekce objektů.
Poznámka:
Přizpůsobení modelu je k dispozici prostřednictvím rozhraní REST API a sady Vision Studio, ale ne prostřednictvím sad SDK klientského jazyka.
Požadavky
- Předplatné Azure. Můžete si ho zdarma vytvořit.
- Jakmile budete mít předplatné Azure, vytvořte na webu Azure Portal prostředek Vision, abyste získali klíč a koncový bod. Pokud používáte Vision Studio, musíte prostředek vytvořit v oblasti USA – východ. Po nasazení vyberte Přejít k prostředku. Zkopírujte klíč a koncový bod do dočasného umístění pro pozdější použití.
- Prostředek služby Azure Storage. Vytvořte prostředek úložiště.
- Sada obrázků, pomocí kterých se má trénovat klasifikační model. Sadu ukázkových obrázků můžete použít na GitHubu. Nebo můžete použít vlastní image. Potřebujete jenom 3 až 5 obrázků na každou třídu.
Poznámka:
Nedoporučujeme používat vlastní modely pro důležitá obchodní prostředí kvůli potenciální vysoké latenci. Když zákazníci trénují vlastní modely v nástroji Vision Studio, patří tyto vlastní modely do prostředku Zpracování obrazu, pod kterým byli trénováni, a zákazník může k těmto modelům volat pomocí rozhraní API pro analýzu obrázků . Při těchto voláních se vlastní model načte do paměti a inicializuje se infrastruktura předpovědi. I když k tomu dojde, zákazníci můžou zaznamenat delší, než očekávanou latenci, aby mohli přijímat výsledky předpovědi.
Vytvoření nového vlastního modelu
Začněte tím, že přejdete do nástroje Vision Studio a vyberete kartu Analýza obrázků. Pak vyberte dlaždici Přizpůsobit modely .
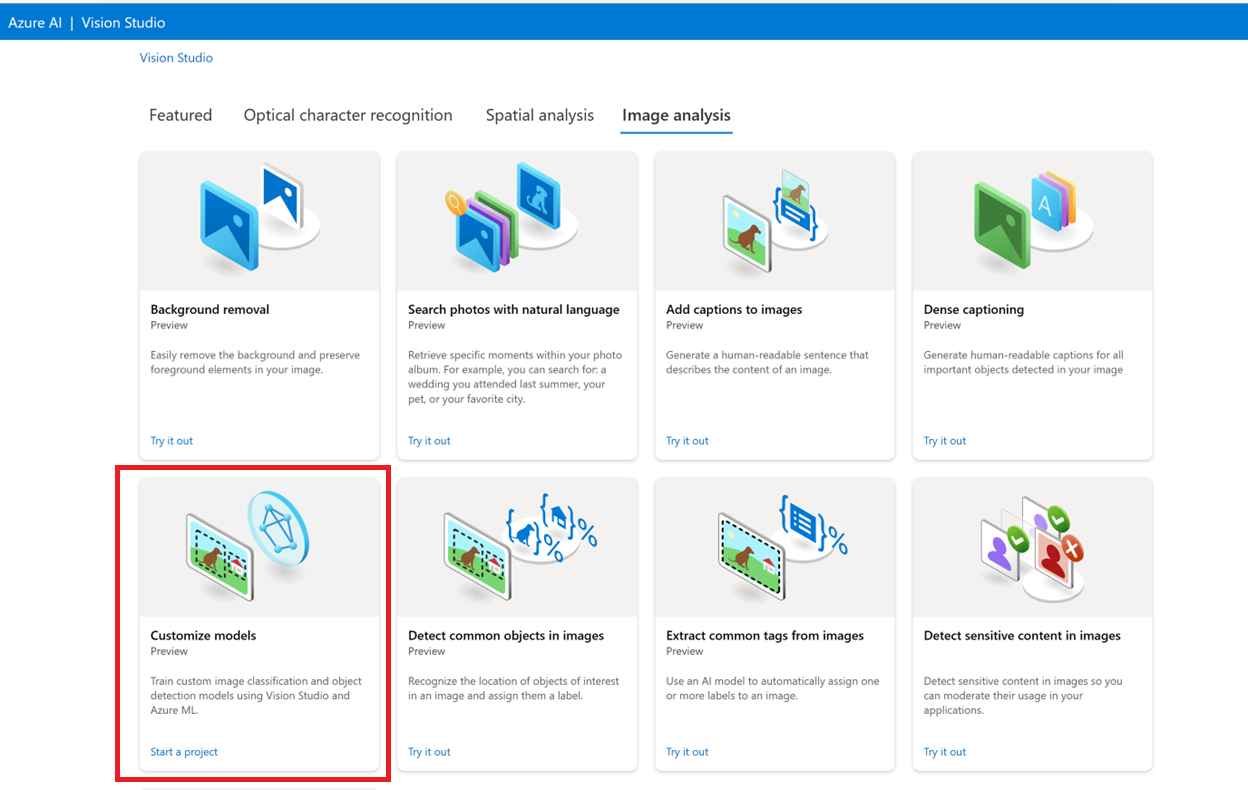
Pak se přihlaste pomocí svého účtu Azure a vyberte prostředek Vision. Pokud ho nemáte, můžete si ho vytvořit z této obrazovky.
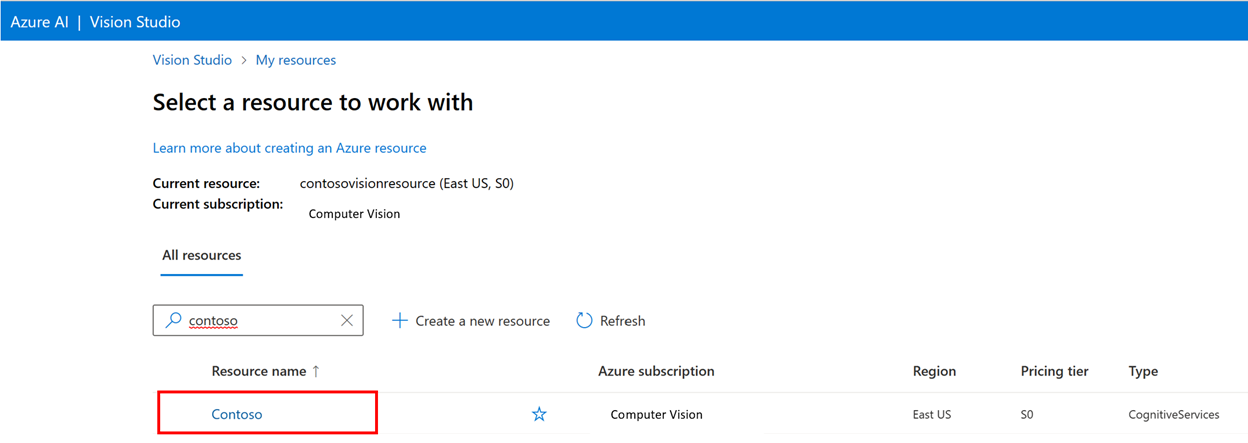
Příprava trénovacích obrázků
Musíte nahrát trénovací obrázky do kontejneru Azure Blob Storage. Na webu Azure Portal přejděte k prostředku úložiště a přejděte na kartu Prohlížeče úložiště. Tady můžete vytvořit kontejner objektů blob a nahrát obrázky. Všechny je umístěte do kořenového adresáře kontejneru.
Přidání datové sady
Pokud chcete vytrénovat vlastní model, musíte ho přidružit k datové sadě , kde jako trénovací data zadáte obrázky a jejich popisky. V nástroji Vision Studio vyberte kartu Datové sady a zobrazte datové sady.
Pokud chcete vytvořit novou datovou sadu, vyberte přidat novou datovou sadu. V místním okně zadejte název a vyberte typ datové sady pro váš případ použití. Modely klasifikace obrázků používají popisky obsahu na celý obrázek, zatímco modely rozpoznávání objektů používají popisky objektů na konkrétní umístění na obrázku. Modely rozpoznávání produktů jsou podkategorie modelů rozpoznávání objektů, které jsou optimalizované pro detekci maloobchodních produktů.
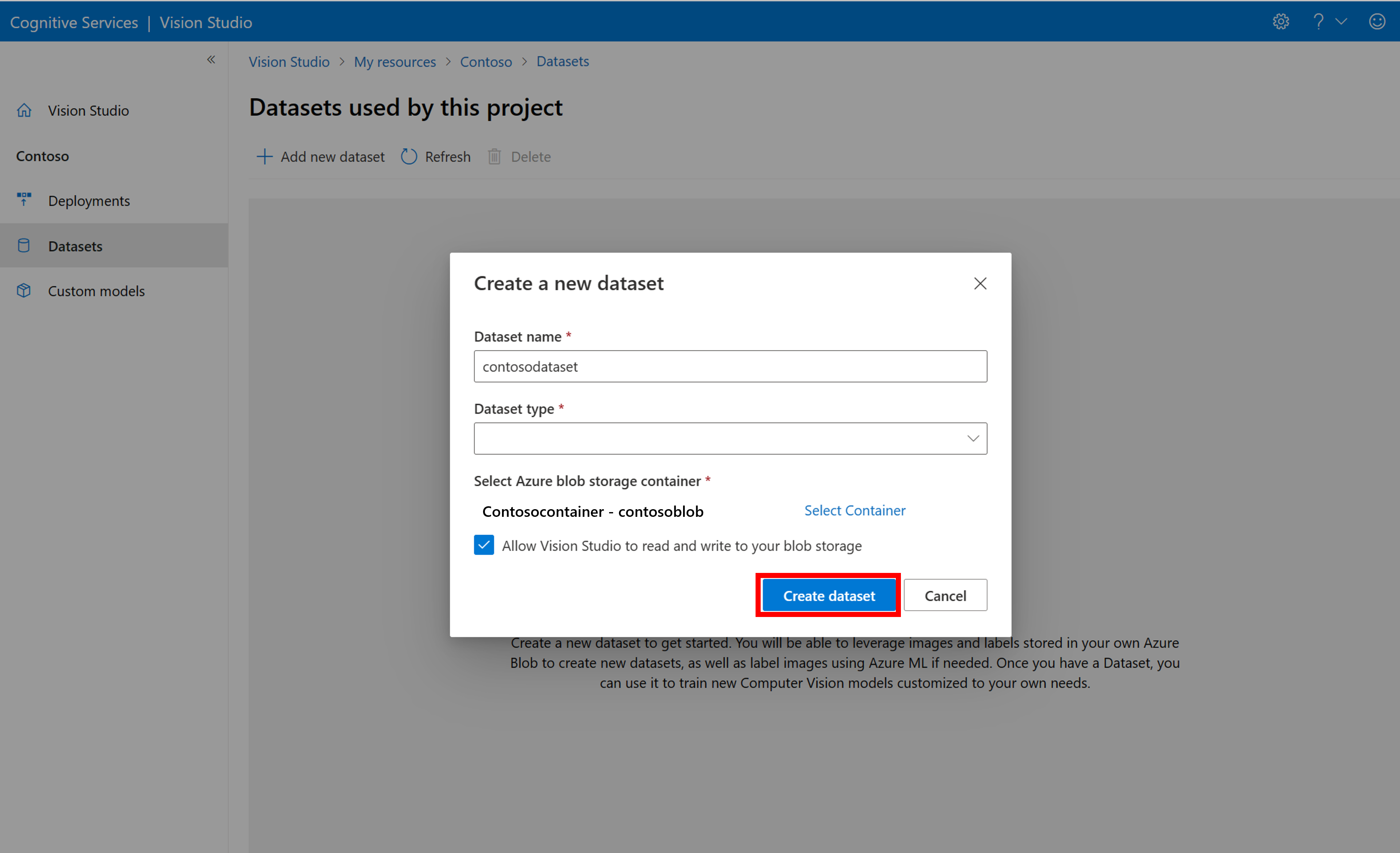
Pak vyberte kontejner z účtu služby Azure Blob Storage, do kterého jste uložili trénovací image. Zaškrtnutím políčka povolíte nástroji Vision Studio číst a zapisovat do kontejneru úložiště objektů blob. Tento krok je nezbytný k importu označených dat. Vytvořte datovou sadu.
Vytvoření projektu popisků ve službě Azure Machine Learning
K vyjádření informací o označování potřebujete soubor COCO. Snadný způsob, jak vygenerovat soubor COCO, je vytvořit projekt Azure Machine Learning, který se dodává s pracovním postupem označování dat.
Na stránce s podrobnostmi datové sady vyberte Přidat nový projekt popisků dat. Pojmenujte ho a vyberte Vytvořit nový pracovní prostor. Otevře se nová karta webu Azure Portal, kde můžete vytvořit projekt Azure Machine Learning.
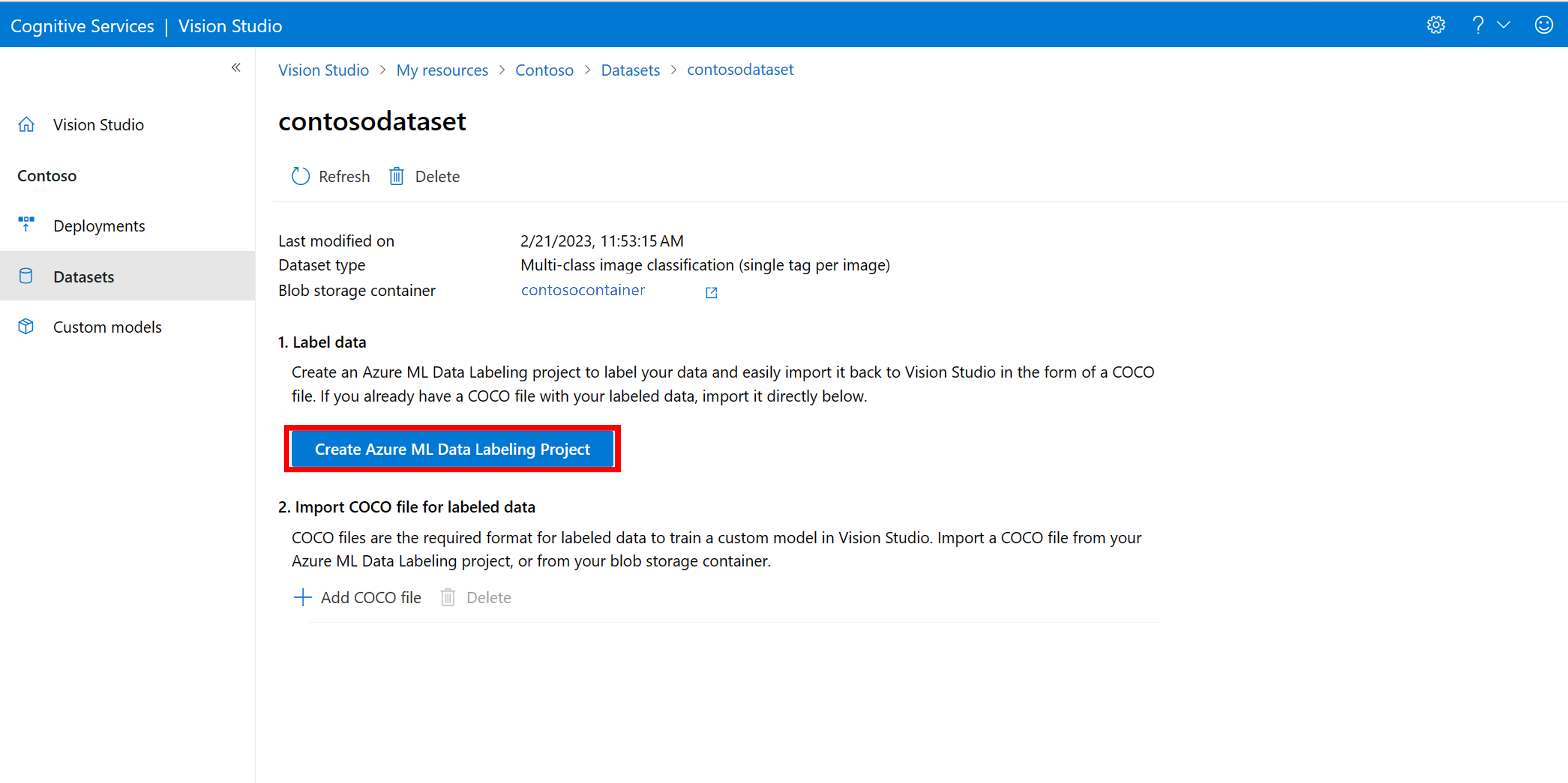
Po vytvoření projektu Azure Machine Learning se vraťte na kartu Vision Studio a vyberte ho v části Pracovní prostor. Portál Azure Machine Learning se pak otevře na nové kartě prohlížeče.
Vytvoření popisků
Pokud chcete začít popisovat, postupujte podle výzvy přidat třídy popisků a přidejte třídy popisků.
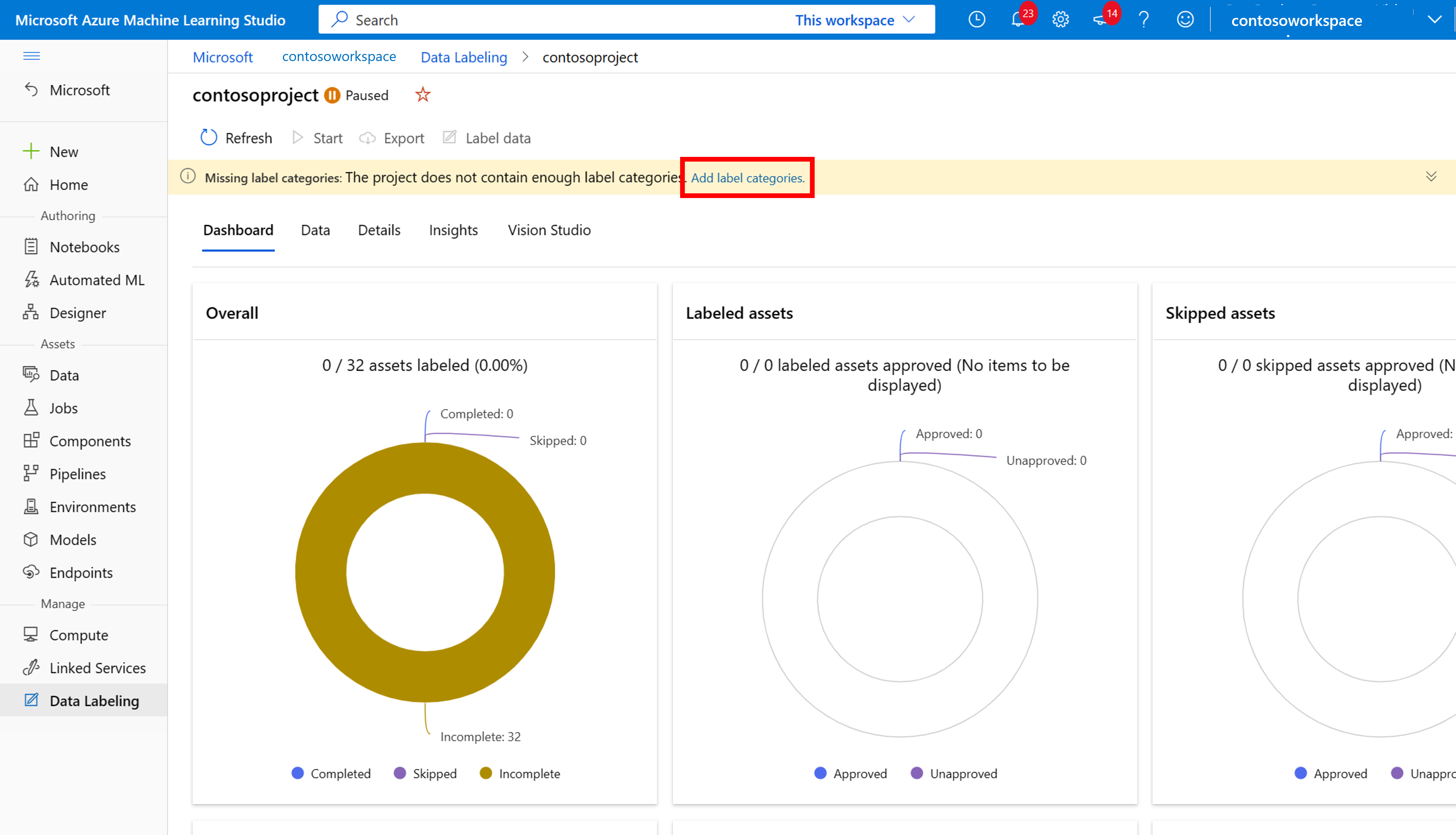
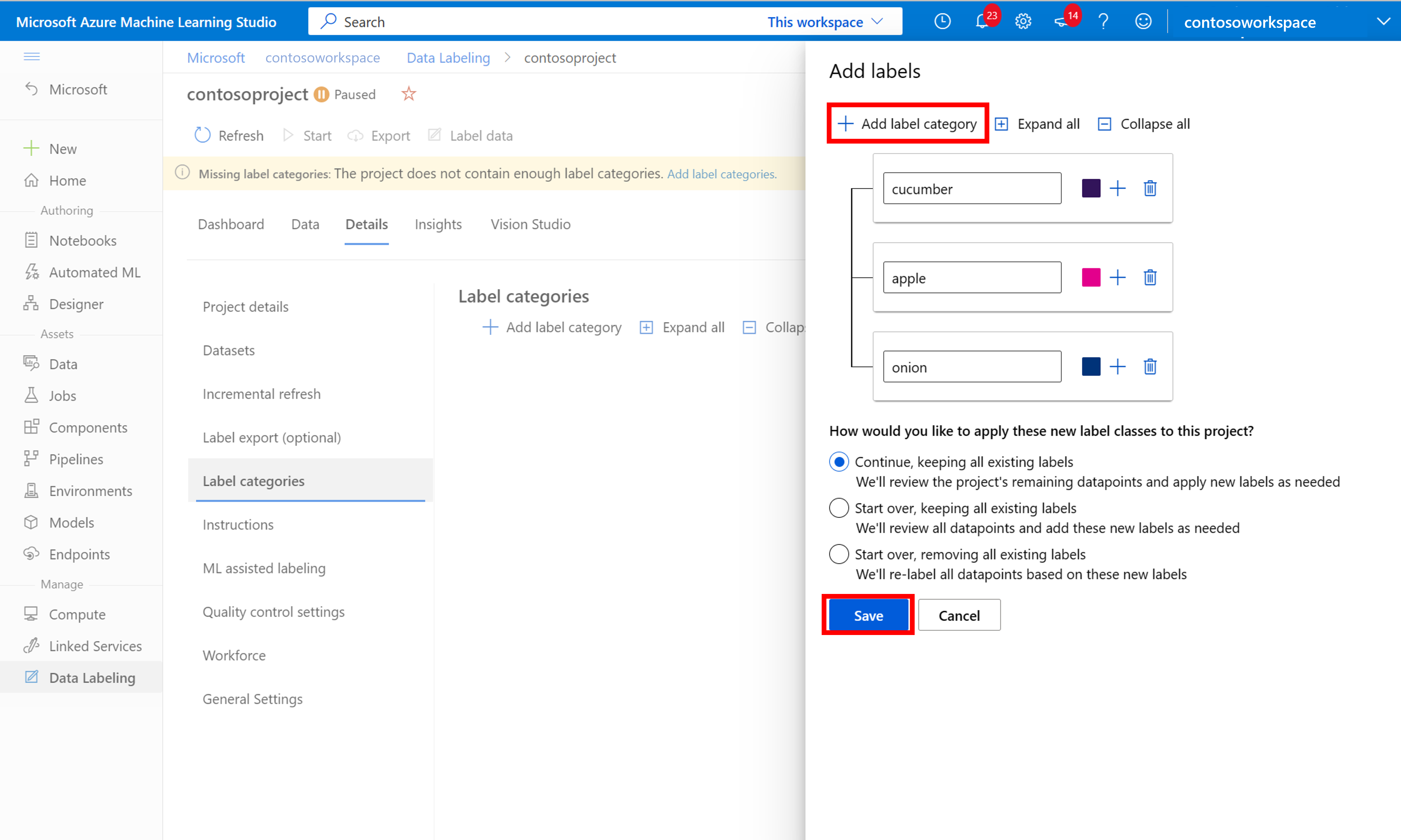
Po přidání všech popisků tříd je uložte, vyberte Spustit v projektu a pak v horní části vyberte Popisek dat .
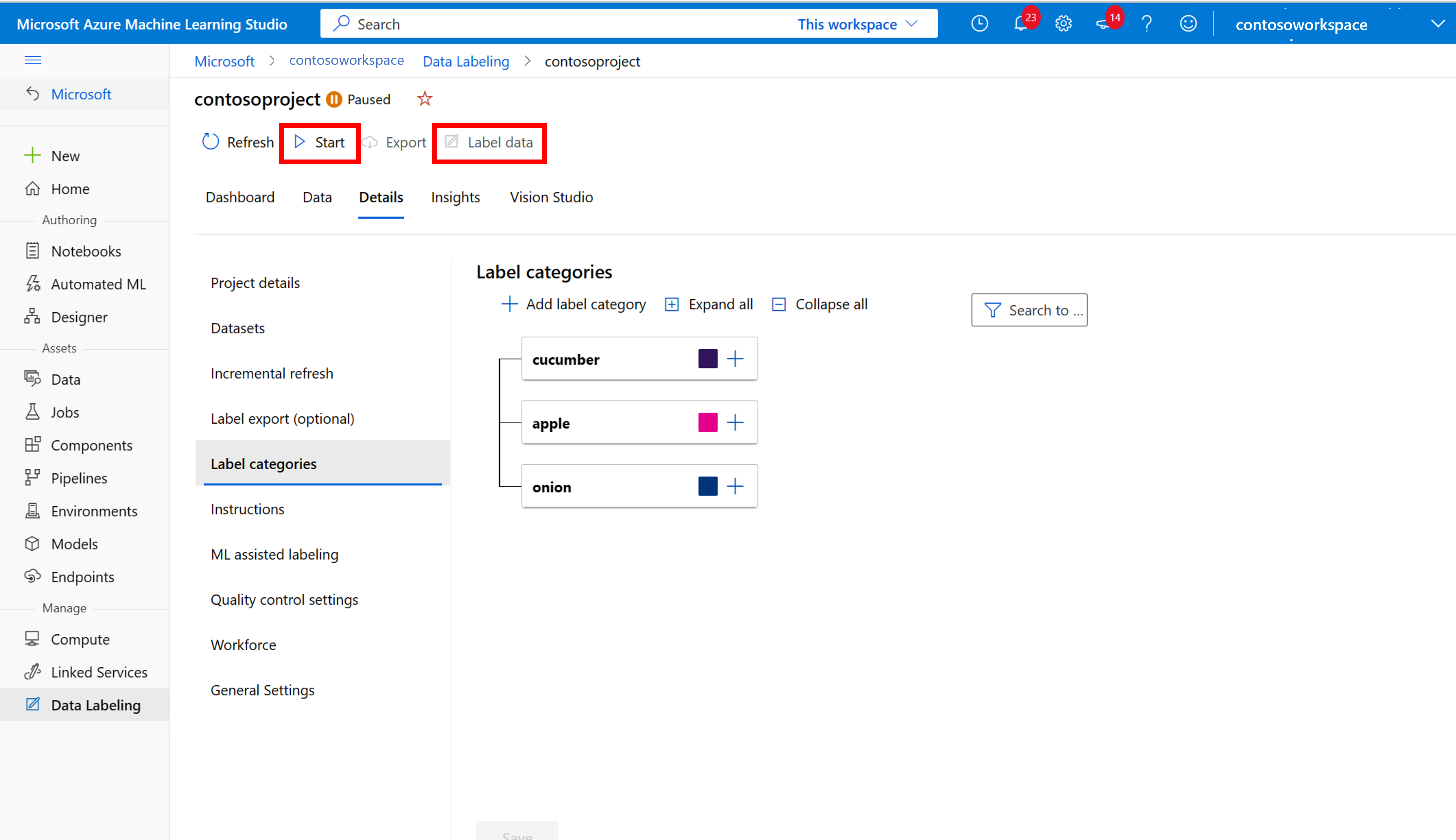
Ruční označení trénovacích dat
Zvolte Začít popisování a postupujte podle pokynů k označení všech obrázků. Až budete hotovi, vraťte se v prohlížeči na kartu Vision Studio.
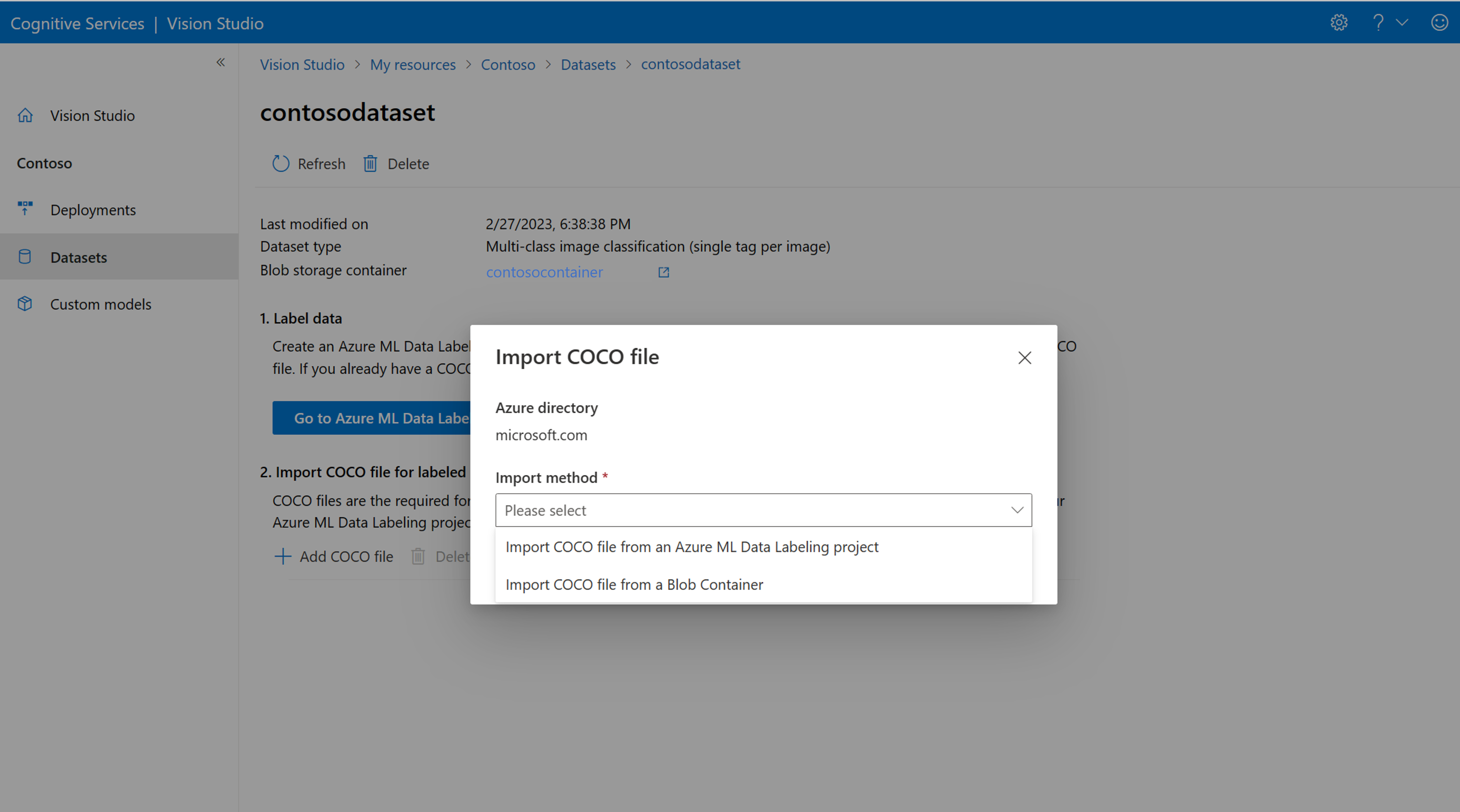
Teď vyberte Přidat soubor COCO a pak vyberte Importovat soubor COCO z projektu Popisování dat Azure ML. Tím se naimportují označená data ze služby Azure Machine Learning.
Vytvořený soubor COCO je teď uložený v kontejneru Azure Storage, který jste propojili s tímto projektem. Teď ho můžete importovat do pracovního postupu přizpůsobení modelu. Vyberte ho z rozevíracího seznamu. Po importu souboru COCO do datové sady je možné datovou sadu použít k trénování modelu.
Poznámka:
Pokud máte připravený soubor COCO, který chcete importovat, přejděte na kartu Datové sady a vyberte Přidat soubory COCO do této datové sady. Můžete přidat konkrétní soubor COCO z účtu úložiště objektů blob nebo importovat z projektu popisků služby Azure Machine Learning.
Microsoft v současné době řeší problém, který způsobuje selhání importu souboru COCO s velkými datovými sadami při zahájení v nástroji Vision Studio. Pokud chcete trénovat pomocí velké datové sady, doporučujeme místo toho použít rozhraní REST API.
Informace o souborech COCO
Soubory COCO jsou soubory JSON s konkrétními požadovanými poli: "images", "annotations"a "categories". Ukázkový soubor COCO bude vypadat takto:
{
"images": [
{
"id": 1,
"width": 500,
"height": 828,
"file_name": "0.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/0.jpg"
},
{
"id": 2,
"width": 754,
"height": 832,
"file_name": "1.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/1.jpg"
},
...
],
"annotations": [
{
"id": 1,
"category_id": 7,
"image_id": 1,
"area": 0.407,
"bbox": [
0.02663142641129032,
0.40691584277841153,
0.9524163571731749,
0.42766634515266866
]
},
{
"id": 2,
"category_id": 9,
"image_id": 2,
"area": 0.27,
"bbox": [
0.11803319477782331,
0.41586723392402375,
0.7765206955096307,
0.3483334397217212
]
},
...
],
"categories": [
{
"id": 1,
"name": "vegall original mixed vegetables"
},
{
"id": 2,
"name": "Amy's organic soups lentil vegetable"
},
{
"id": 3,
"name": "Arrowhead 8oz"
},
...
]
}
Referenční dokumentace k poli souboru COCO
Pokud generujete vlastní soubor COCO úplně od začátku, ujistěte se, že jsou všechna požadovaná pole vyplněná správnými podrobnostmi. Následující tabulky popisují každé pole v souboru COCO:
"images"
| Klíč | Typ | Popis | Povinné? |
|---|---|---|---|
id |
integer | Jedinečné ID obrázku od 1 | Ano |
width |
integer | Šířka obrázku v pixelech | Ano |
height |
integer | Výška obrázku v pixelech | Ano |
file_name |
string | Jedinečný název obrázku | Ano |
absolute_url nebo coco_url |
string | Cesta k obrázku jako absolutní identifikátor URI objektu blob v kontejneru objektů blob. Prostředek Vision musí mít oprávnění ke čtení souborů poznámek a všech odkazovaných souborů obrázků. | Ano |
Hodnotu pro absolute_url najdete ve vlastnostech kontejneru objektů blob:
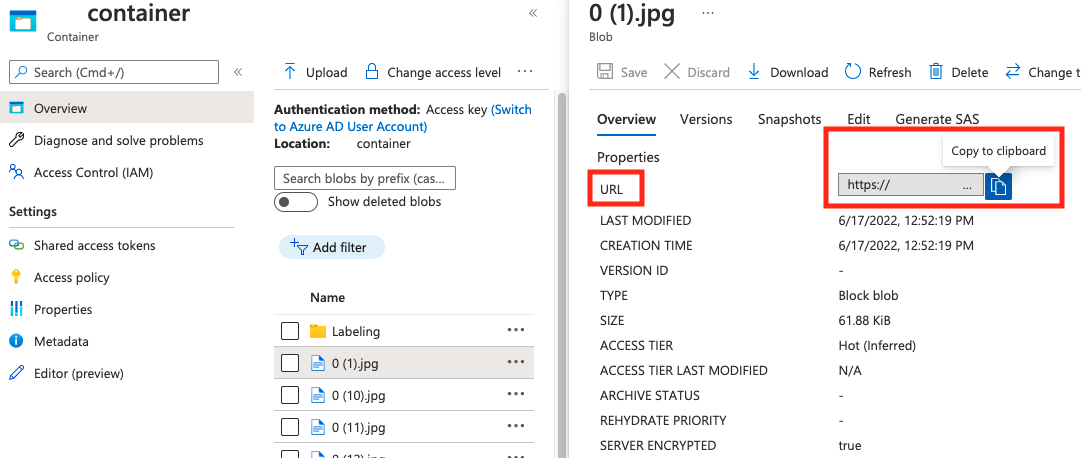
"poznámky"
| Klíč | Typ | Popis | Povinné? |
|---|---|---|---|
id |
integer | ID poznámky | Ano |
category_id |
integer | ID kategorie definované v oddílu categories |
Ano |
image_id |
integer | ID obrázku | Ano |
area |
integer | Hodnota "Width" x 'Height' (třetí a čtvrtá hodnota bbox) |
No |
bbox |
list[float] | Relativní souřadnice ohraničujícího rámečku (0 až 1) v pořadí 'Vlevo', 'Horní', 'Šířka', 'Výška' | Ano |
"categories" (kategorie)
| Klíč | Typ | Popis | Povinné? |
|---|---|---|---|
id |
integer | Jedinečné ID pro každou kategorii (třída popisku). Ty by se měly vyskytovat v annotations části. |
Ano |
name |
string | Název kategorie (třída popisku) | Ano |
Ověření souboru COCO
Ukázkový kód Pythonu můžete použít ke kontrole formátu souboru COCO.
Trénování vlastního modelu
Pokud chcete začít trénovat model pomocí souboru COCO, přejděte na kartu Vlastní modely a vyberte Přidat nový model. Zadejte název modelu a vyberte Image classification nebo Object detection jako typ modelu.
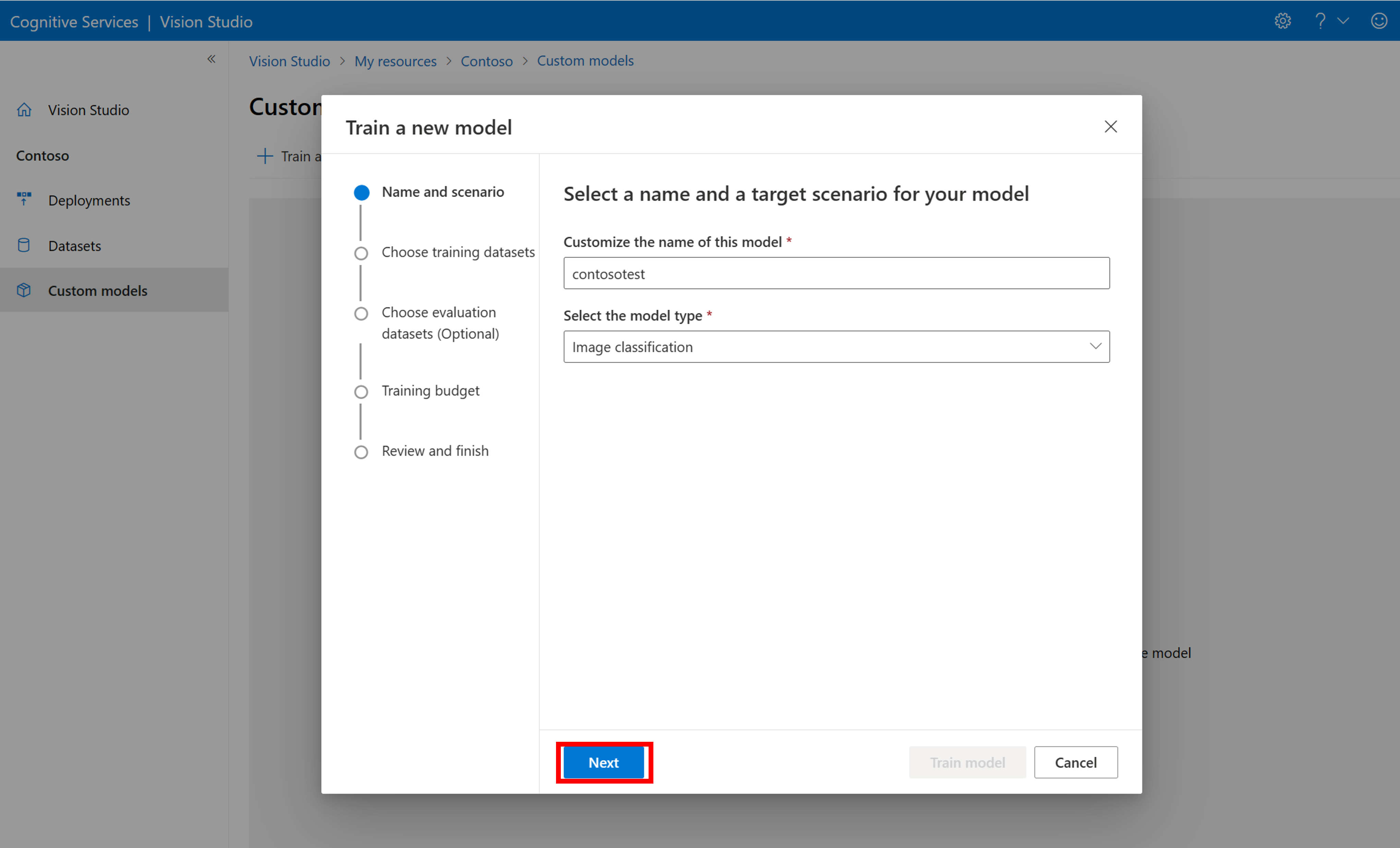
Vyberte datovou sadu, která je teď přidružená k souboru COCO obsahujícímu informace o označování.
Pak vyberte časový rozpočet a vytrénujte model. U malých příkladů můžete použít 1 hour rozpočet.
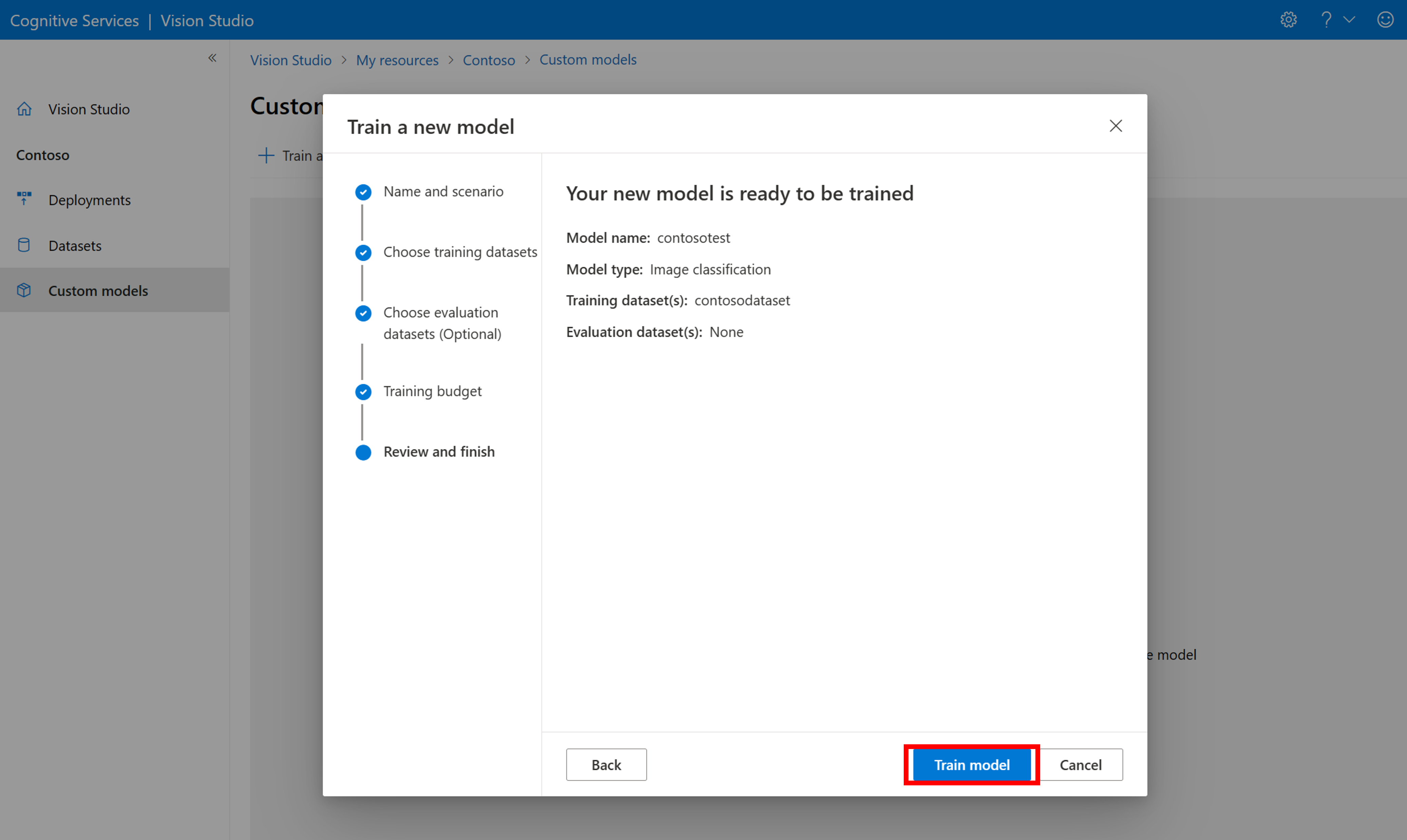
Dokončení trénování může nějakou dobu trvat. Modely analýzy obrázků 4.0 můžou být přesné pouze s malou sadou trénovacích dat, ale trénování trvá déle než předchozí modely.
Vyhodnocení natrénovaného modelu
Po dokončení trénování můžete zobrazit vyhodnocení výkonu modelu. Používají se následující metriky:
- Klasifikace obrázků: Průměrná přesnost, Přesnost top 1, Přesnost Top 5
- Rozpoznávání objektů: Průměrná přesnost @ 30, Průměrná přesnost @ 50, Průměrná průměrná přesnost @ 75
Pokud při trénování modelu není k dispozici testovací sada, bude hlášený výkon odhadován na základě části trénovací sady. Důrazně doporučujeme použít vyhodnocovací datovou sadu (pomocí stejného procesu jako výše), abyste měli spolehlivý odhad výkonu modelu.
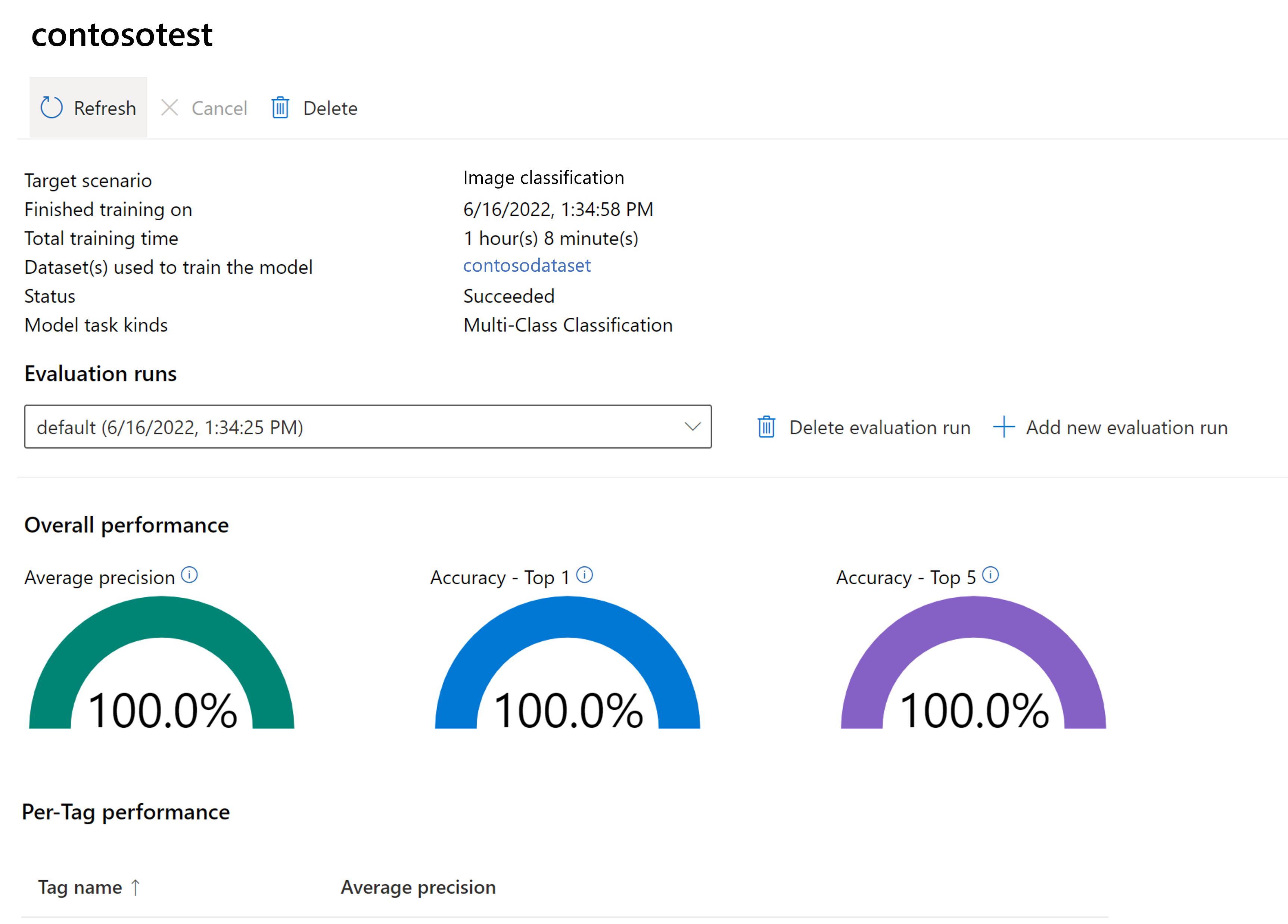
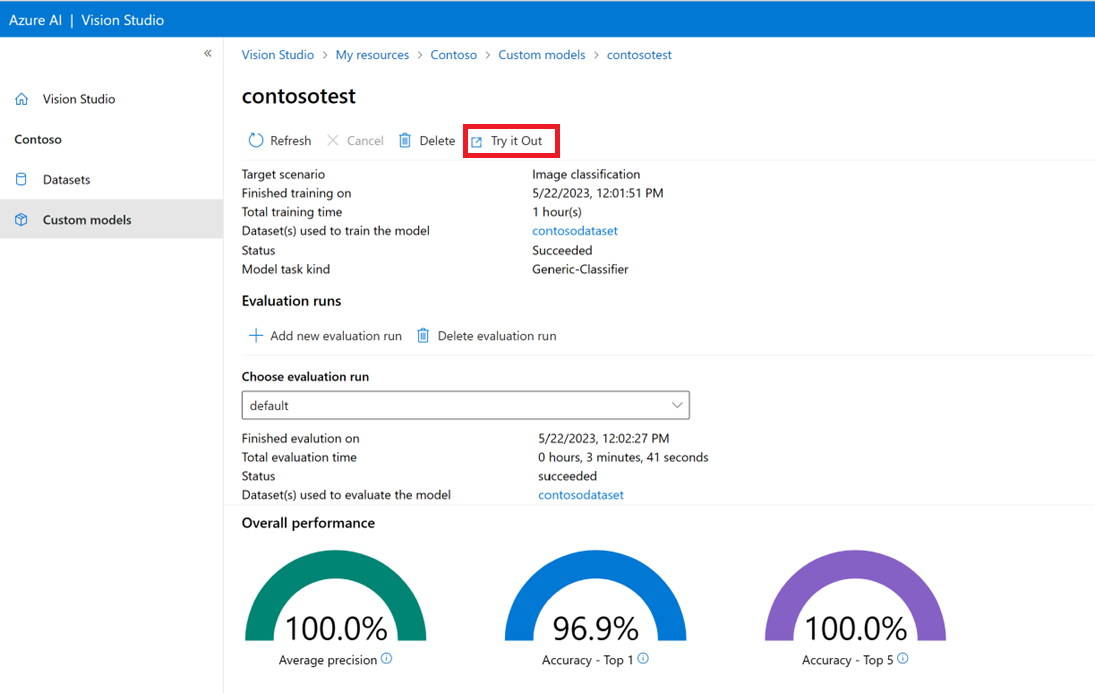
Testování vlastního modelu v nástroji Vision Studio
Jakmile vytvoříte vlastní model, můžete ho otestovat výběrem tlačítka Vyzkoušet na obrazovce pro vyhodnocení modelu.
Tím přejdete na stránku Extrahovat běžné značky ze stránky obrázků . V rozevírací nabídce zvolte vlastní model a nahrajte testovací obrázek.
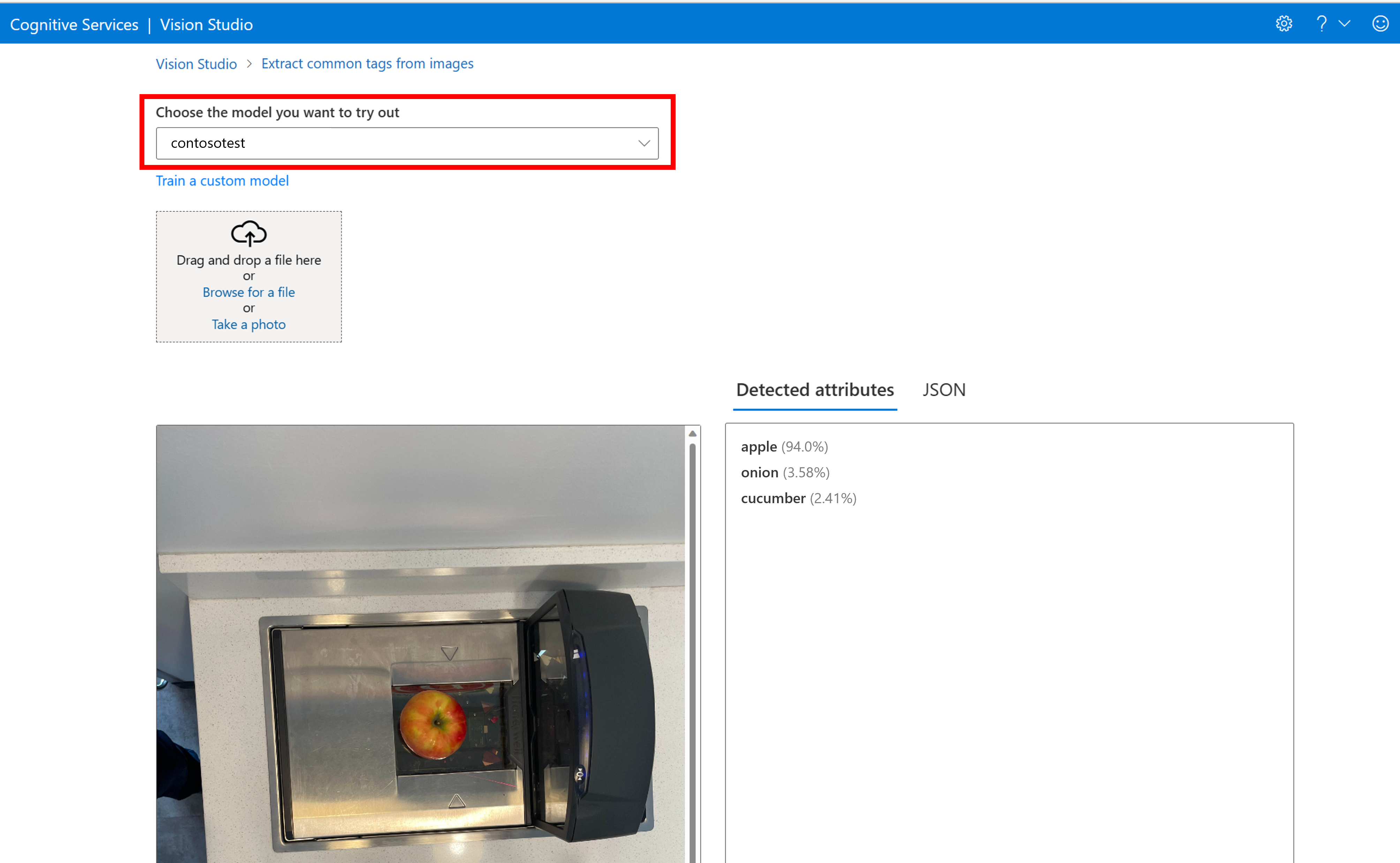
Výsledky předpovědi se zobrazí ve správném sloupci.
Související obsah
V této příručce jste vytvořili a vytrénovali vlastní model klasifikace obrázků pomocí analýzy obrázků. V dalším kroku se dozvíte více o rozhraní API Analyzovat obrázek 4.0, abyste mohli volat vlastní model z aplikace pomocí REST.
- Koncepty přizpůsobení modelu
- Volání rozhraní API pro analýzu obrázků