Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Tento kurz vysvětluje, jak vytvořit řešení pro načítání rozšířené generace (RAG) pomocí nástroje Azure Content Understanding v nástrojích Foundry. Popisuje klíčové kroky k vytvoření silného systému RAG, nabízí tipy ke zlepšení relevance a přesnosti a ukazuje, jak se spojit s dalšími službami Azure. Na konci můžete pomocí Funkce Content Understanding zpracovávat multimodální data, zlepšit načítání a pomáhat modelům AI poskytovat přesné a smysluplné odpovědi.
Cvičení zahrnutá v tomto kurzu
- Vytváření analyzátorů Naučte se vytvářet opakovaně použitelné analyzátory pro extrakci strukturovaného obsahu z multimodálních dat pomocí extrakce obsahu.
- Generování cílových metadat s extrakcí polí Zjistěte, jak pomocí umělé inteligence generovat další metadata, jako jsou souhrny nebo klíčová témata, k obohacení extrahovaného obsahu.
- Předběžné zpracování extrahovaného obsahu Prozkoumejte způsoby, jak transformovat extrahovaný obsah na vektorové vkládání pro sémantické vyhledávání a načítání.
- Navrhněte jednotný index. Vytvořte jednotný index Azure AI Vyhledávač, který integruje a uspořádá multimodální data pro efektivní načítání.
- Sémantické načítání bloků dat. Extrahujte kontextově relevantní informace, které poskytují přesnější a smysluplnější odpovědi na dotazy uživatelů.
- Interact s daty pomocí chatovacích modelů Použití chatových modelů Azure OpenAI k zapojení indexovaných dat, povolení konverzačního vyhledávání, dotazování a odpovídání.
Požadavky
Abyste mohli začít, potřebujete Aktivní Azure předplatné. Pokud účet Azure nemáte, můžete vytvořit bezplatné předplatné.
Jakmile máte předplatné Azure, vytvořte na portálu Azure prostředek Microsoft Foundry.
Tento prostředek je uvedený v části Foundry>Foundry na portálu.
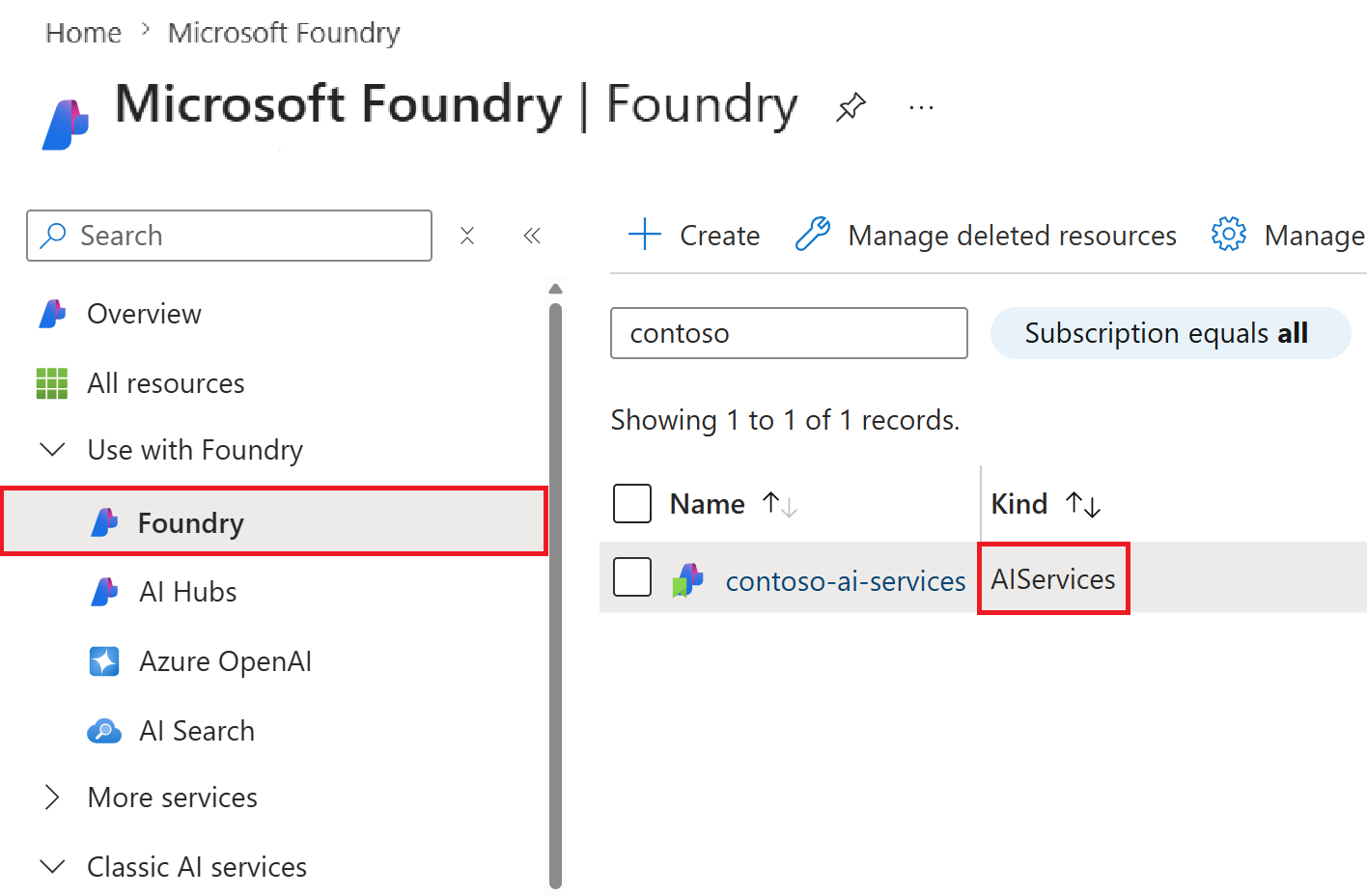
Azure AI Vyhledávač Resource: Nastavte prostředek Azure AI Vyhledávač pro povolení indexování a načítání multimodálních dat.
Nasazení modelu chatu Azure OpenAI: Nasaďte model Azure OpenAI pro chat, který umožňuje konverzační interakce.
Nasazení modelu vkládání: Ujistěte se, že máte nasazený model vkládání pro generování vektorových reprezentací pro sémantické vyhledávání.
Verze rozhraní API: V tomto kurzu se používá nejnovější verze rozhraní GA API.
Python Environment: Nainstalujte Python 3.11 a spusťte poskytnuté ukázky kódu a skripty.
Tento kurz se řídí tímto ukázkovým kódem, který najdete v našem poznámkovém bloku Python. Podle README vytvořte základní prostředky, udělte prostředkům správné role řízení přístupu (IAM) a nainstalujte všechny balíčky potřebné pro účely tohoto kurzu.
Multimodální data použitá v tomto kurzu se skládají z dokumentů, obrázků, zvuku a videa. Jsou navržené tak, aby vás provedly procesem vytváření robustního řešení RAG s Azure Porozumění obsahu v nástrojích Foundry.
Extrahovat data
Generace s načítáním z externích zdrojů (RAG) je metoda, která vylepšuje funkce velkých jazykových modelů (LLM) začleněním dat z externích znalostních zdrojů. Vytvoření robustního multimodálního řešení RAG začíná extrakcí a strukturováním dat z různých typů obsahu. Azure Content Understanding poskytuje tři klíčové komponenty pro usnadnění tohoto procesu: extrakce obsahu, extrakce polí a analyzátory. Společně tyto komponenty tvoří základ pro vytvoření sjednoceného, opakovaně použitelného a rozšířeného datového kanálu pro pracovní postupy RAG.
Implementační kroky
Pokud chcete implementovat extrakci dat v Nástroji Content Understanding, postupujte takto:
Vytvořte analyzátor: Definujte analyzátor pomocí rozhraní REST API nebo našich ukázek kódu Python.
Extrakce obsahu: Pomocí analyzátoru můžete zpracovávat soubory a extrahovat strukturovaný obsah.
(Volitelné) Vylepšení pomocí extrakce polí: Volitelně můžete zadat pole vygenerovaná pomocí AI, která mají rozšířit extrahovaný obsah o přidaná metadata.
Vytvořte analyzátory
Analyzátory jsou opakovaně použitelné komponenty v nástroji Content Understanding, které zjednodušují proces extrakce dat. Po vytvoření analyzátoru je možné ho opakovaně použít ke zpracování souborů a extrakci obsahu nebo polí na základě předdefinovaných schémat. Analyzátor funguje jako podrobný plán pro zpracování dat a zajišťuje konzistenci a efektivitu napříč více soubory a typy obsahu.
Následující ukázky kódu ukazují, jak vytvořit analyzátory pro jednotlivé způsoby a určit strukturovaná data, která se mají extrahovat, například klíčová pole, souhrny nebo klasifikace. Tyto analyzátory slouží jako základ pro extrakci a rozšiřování obsahu v řešení RAG.
Načtení všech proměnných prostředí a potřebných knihoven z jazyka Langchain
import os
from dotenv import load_dotenv
load_dotenv()
# Load and validate Foundry Tools configs
AZURE_AI_SERVICE_ENDPOINT = os.getenv("AZURE_AI_SERVICE_ENDPOINT")
AZURE_AI_SERVICE_API_VERSION = os.getenv("AZURE_AI_SERVICE_API_VERSION") or "2025-11-01"
AZURE_DOCUMENT_INTELLIGENCE_API_VERSION = os.getenv("AZURE_DOCUMENT_INTELLIGENCE_API_VERSION") or "2024-11-30"
# Load and validate Azure OpenAI configs
AZURE_OPENAI_ENDPOINT = os.getenv("AZURE_OPENAI_ENDPOINT")
AZURE_OPENAI_CHAT_DEPLOYMENT_NAME = os.getenv("AZURE_OPENAI_CHAT_DEPLOYMENT_NAME")
AZURE_OPENAI_CHAT_API_VERSION = os.getenv("AZURE_OPENAI_CHAT_API_VERSION") or "2024-08-01-preview"
AZURE_OPENAI_EMBEDDING_DEPLOYMENT_NAME = os.getenv("AZURE_OPENAI_EMBEDDING_DEPLOYMENT_NAME")
AZURE_OPENAI_EMBEDDING_API_VERSION = os.getenv("AZURE_OPENAI_EMBEDDING_API_VERSION") or "2023-05-15"
# Load and validate Azure Search Services configs
AZURE_SEARCH_ENDPOINT = os.getenv("AZURE_SEARCH_ENDPOINT")
AZURE_SEARCH_INDEX_NAME = os.getenv("AZURE_SEARCH_INDEX_NAME") or "sample-doc-index"
# Import libraries from Langchain
from langchain import hub
from langchain_openai import AzureChatOpenAI
from langchain_openai import AzureOpenAIEmbeddings
from langchain.schema import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough
from langchain.text_splitter import MarkdownHeaderTextSplitter
from langchain.vectorstores.azuresearch import AzureSearch
from langchain_core.prompts import ChatPromptTemplate
from langchain.schema import Document
import requests
import json
import sys
import uuid
from pathlib import Path
from dotenv import find_dotenv, load_dotenv
from azure.identity import DefaultAzureCredential, get_bearer_token_provider
# Add the parent directory to the path to use shared modules
parent_dir = Path(Path.cwd()).parent
sys.path.append(str(parent_dir))
Ukázka kódu: Vytvoření analyzátoru
from pathlib import Path
from python.content_understanding_client import AzureContentUnderstandingClient
credential = DefaultAzureCredential()
token_provider = get_bearer_token_provider(credential, "https://cognitiveservices.azure.com/.default")
#set analyzer configs
analyzer_configs = [
{
"id": "doc-analyzer" + str(uuid.uuid4()),
"template_path": "../analyzer_templates/content_document.json",
"location": Path("../data/sample_layout.pdf"),
},
{
"id": "image-analyzer" + str(uuid.uuid4()),
"template_path": "../analyzer_templates/image_chart_diagram_understanding.json",
"location": Path("../data/sample_report.pdf"),
},
{
"id": "audio-analyzer" + str(uuid.uuid4()),
"template_path": "../analyzer_templates/call_recording_analytics.json",
"location": Path("../data/callCenterRecording.mp3"),
},
{
"id": "video-analyzer" + str(uuid.uuid4()),
"template_path": "../analyzer_templates/video_content_understanding.json",
"location": Path("../data/FlightSimulator.mp4"),
},
]
# Create Content Understanding client
content_understanding_client = AzureContentUnderstandingClient(
endpoint=AZURE_AI_SERVICE_ENDPOINT,
api_version=AZURE_AI_SERVICE_API_VERSION,
token_provider=token_provider,
x_ms_useragent="azure-ai-content-understanding-python/content_extraction", # This header is used for sample usage telemetry, please comment out this line if you want to opt out.
)
# Iterate through each config and create an analyzer
for analyzer in analyzer_configs:
analyzer_id = analyzer["id"]
template_path = analyzer["template_path"]
try:
# Create the analyzer using the content understanding client
response = content_understanding_client.begin_create_analyzer(
analyzer_id=analyzer_id,
analyzer_template_path=template_path
)
result = content_understanding_client.poll_result(response)
print(f"Successfully created analyzer: {analyzer_id}")
except Exception as e:
print(f"Failed to create analyzer: {analyzer_id}")
print(f"Error: {e}")
Poznámka: Schémata extrakce polí jsou volitelná a nevyžadují se k extrakci obsahu. Pokud chcete spouštět extrakci obsahu a vytvářet analyzátory bez definování schémat polí, stačí zadat ID analyzátoru a soubor, který se má analyzovat.
Schémata byla použita v tomto kurzu. Tady je příklad definice schématu.
V následujícím příkladu definujeme schéma pro extrakci základních informací z dokumentu faktury.
{
"description": "Sample invoice analyzer",
"scenario": "document",
"config": {
"returnDetails": true
},
"fieldSchema": {
"fields": {
"VendorName": {
"type": "string",
"method": "extract",
"description": "Vendor issuing the invoice"
},
"Items": {
"type": "array",
"method": "extract",
"items": {
"type": "object",
"properties": {
"Description": {
"type": "string",
"method": "extract",
"description": "Description of the item"
},
"Amount": {
"type": "number",
"method": "extract",
"description": "Amount of the item"
}
}
}
}
}
}
}
Extrakce obsahu a polí
Extrakce obsahu je prvním krokem procesu implementace RAG. Transformuje nezpracovaná multimodální data na strukturované a prohledávatelné formáty. Tento základní krok zajistí, že je obsah uspořádaný a připravený k indexování a načítání. I když extrakce obsahu poskytuje směrný plán pro indexování a načítání, nemusí plně řešit potřeby specifické pro doménu nebo poskytovat hlubší kontextové přehledy. Přečtěte si další informace o možnostech extrakce obsahu pro jednotlivé způsoby.
Extrakce polí vychází z extrakce obsahu pomocí AI k vygenerování dalších metadat, která rozšiřují znalostní bázi. Tento krok umožňuje definovat vlastní pole přizpůsobená konkrétnímu případu použití, což umožňuje přesnější načítání a vylepšenou relevanci vyhledávání. Extrakce polí doplňuje extrakci obsahu přidáním hloubky a kontextu, což zpřístupňuje data pro scénáře RAG. Přečtěte si další informace o možnostech extrakce polí pro jednotlivé způsoby.
S analyzátory vytvořenými pro jednotlivé způsoby teď můžeme zpracovávat soubory pro extrakci strukturovaného obsahu a metadat generovaných AI na základě definovaných schémat. Tato část ukazuje, jak pomocí analyzátorů analyzovat multimodální data a poskytuje vzorek výsledků vrácených rozhraními API. Tyto výsledky ukazují transformaci nezpracovaných dat na užitečné přehledy, které tvoří základ pro pracovní postupy indexování, načítání a RAG.
Analýza souborů
#Iterate through each analyzer created and analyze content for each modality
analyzer_results =[]
extracted_markdown = []
analyzer_content = []
for analyzer in analyzer_configs:
analyzer_id = analyzer["id"]
template_path = analyzer["template_path"]
file_location = analyzer["location"]
try:
# Analyze content
response = content_understanding_client.begin_analyze(analyzer_id, file_location)
result = content_understanding_client.poll_result(response)
analyzer_results.append({"id":analyzer_id, "result": result["result"]})
analyzer_content.append({"id": analyzer_id, "content": result["result"]["contents"]})
except Exception as e:
print(e)
print("Error in creating analyzer. Please double-check your analysis settings.\nIf there is a conflict, you can delete the analyzer and then recreate it, or move to the next cell and use the existing analyzer.")
print("Analyzer Results:")
for analyzer_result in analyzer_results:
print(f"Analyzer ID: {analyzer_result['id']}")
print(json.dumps(analyzer_result["result"], indent=2))
# Delete the analyzer if it is no longer needed
#content_understanding_client.delete_analyzer(ANALYZER_ID)
Výsledky extrakce
Následující ukázky kódu ukazují výstup extrakce obsahu a polí pomocí Azure Content Understanding. Odpověď JSON obsahuje více polí, z nichž každá obsluhuje konkrétní účel představující extrahovaná data.
Pole Markdown: Pole
markdownposkytuje zjednodušenou, čitelnou reprezentaci extrahovaného obsahu. Je zvlášť užitečné pro rychlé náhledy nebo integraci extrahovaných dat do aplikací, které vyžadují strukturovaný text, jako jsou znalostní báze nebo vyhledávací rozhraní. Například v dokumentumarkdownmůže pole obsahovat záhlaví, odstavce a další strukturální prvky formátované pro snadnou čitelnost.Výstup JSON: Úplný výstup JSON poskytuje komplexní reprezentaci extrahovaných dat, včetně obsahu i metadat generovaných během procesu extrakce, včetně následujících vlastností:
- Pole: Metadata generovaná AI, jako jsou souhrny, klíčová témata nebo klasifikace, přizpůsobená konkrétnímu schématu definovanému v analyzátoru.
- Skóre spolehlivosti: Indikátory spolehlivosti extrahovaných dat
- Umístění: Informace o umístění výňatků ve zdrojovém souboru.
- Další metadata: Podrobnosti, jako jsou čísla stránek, rozměry a další kontextové informace.
Výsledek ukazuje extrakci záhlaví, odstavců, tabulek a dalších strukturálních prvků při zachování logické organizace obsahu. Kromě toho ukazuje schopnost extrahovat klíčová pole a poskytuje stručné výtahy z rozsáhlých materiálů.
{
"id": "bcf8c7c7-03ab-4204-b22c-2b34203ef5db",
"status": "Succeeded",
"result": {
"analyzerId": "training_document_analyzer",
"apiVersion": "2025-11-01",
"createdAt": "2024-11-13T07:15:46Z",
"warnings": [],
"contents": [
{
"markdown": "CONTOSO LTD.\n\n\n# Contoso Training Topics\n\nContoso Headquarters...",
"fields": {
"ChapterTitle": {
"type": "string",
"valueString": "Risks and Compliance regulations",
"spans": [ { "offset": 0, "length": 12 } ],
"confidence": 0.941,
"source": "D(1,0.5729,0.6582,2.3353,0.6582,2.3353,0.8957,0.5729,0.8957)"
},
"ChapterAuthor": {
"type": "string",
"valueString": "John Smith",
"spans": [ { "offset": 0, "length": 12 } ],
"confidence": 0.941,
"source": "D(1,0.5729,0.6582,2.3353,0.6582,2.3353,0.8957,0.5729,0.8957)"
},
"ChapterPublishDate": {
"type": "Date",
"valueString": "04-11-2017",
"spans": [ { "offset": 0, "length": 12 } ],
"confidence": 0.941,
"source": "D(1,0.5729,0.6582,2.3353,0.6582,2.3353,0.8957,0.5729,0.8957)"
},
},
"kind": "document",
"startPageNumber": 1,
"endPageNumber": 1,
"unit": "inch",
"pages": [
{
"pageNumber": 1,
"angle": -0.0039,
"width": 8.5,
"height": 11,
"spans": [ { "offset": 0, "length": 1650 } ],
"words": [
{
....
},
],
"lines": [
{
...
},
]
}
],
}
]
}
}
Předběžné zpracování výstupu ze služby Content Understanding
Jakmile se data extrahují pomocí Azure Content Understanding, dalším krokem je příprava výstupu analýzy pro vložení do vyhledávacího systému. Předběžné zpracování výstupu zajistí, že se extrahovaný obsah transformuje do formátu vhodného pro indexování a načítání. Tento krok zahrnuje převod výstupu JSON z analyzátorů na strukturované řetězce, přičemž zachová obsah i metadata pro bezproblémovou integraci do podřízených pracovních postupů.
Následující příklad ukazuje, jak předem zpracovat výstupní data z analyzátorů, včetně dokumentů, obrázků, zvuku a videa. Proces převodu každého výstupu JSON na strukturovaný řetězec představuje základ pro vkládání dat do systému vyhledávání založeného na vektorech, který umožňuje efektivní načítání a vylepšené pracovní postupy RAG.
def convert_values_to_strings(json_obj):
return [str(value) for value in json_obj]
#process all content and convert to string
def process_allJSON_content(all_content):
# Initialize empty list to store string of all content
output = []
document_splits = [
"This is a json string representing a document with text and metadata for the file located in "+str(analyzer_configs[0]["location"])+" "
+ v
+ "```"
for v in convert_values_to_strings(all_content[0]["content"])
]
docs = [Document(page_content=v) for v in document_splits]
output += docs
#convert image json object to string and append file metadata to the string
image_splits = [
"This is a json string representing an image verbalization and OCR extraction for the file located in "+str(analyzer_configs[1]["location"])+" "
+ v
+ "```"
for v in convert_values_to_strings(all_content[1]["content"])
]
image = [Document(page_content=v) for v in image_splits]
output+=image
#convert audio json object to string and append file metadata to the string
audio_splits = [
"This is a json string representing an audio segment with transcription for the file located in "+str(analyzer_configs[2]["location"])+" "
+ v
+ "```"
for v in convert_values_to_strings(all_content[2]["content"])
]
audio = [Document(page_content=v) for v in audio_splits]
output += audio
#convert video json object to string and append file metadata to the string
video_splits = [
"The following is a json string representing a video segment with scene description and transcript for the file located in "+str(analyzer_configs[3]["location"])+" "
+ v
+ "```"
for v in convert_values_to_strings(all_content[3]["content"])
]
video = [Document(page_content=v) for v in video_splits]
output+=video
return output
all_splits = process_allJSON_content(analyzer_content)
print("There are " + str(len(all_splits)) + " documents.")
# Print the content of all doc splits
for doc in all_splits:
print(f"doc content", doc.page_content)
Vložit a indexovat extrahovaný obsah
Po předběžném zpracování extrahovaných dat z Azure Content Understanding je dalším krokem vložení a indexování obsahu pro efektivní načítání. Tento krok zahrnuje transformaci strukturovaných řetězců na vektorové vkládání pomocí modelu vkládání a jejich uložení v rámci systému Azure AI Vyhledávač. Vložením obsahu povolíte sémantické vyhledávání a umožníte systému načíst nejrelevantní informace na základě významu, nikoli přesné shody klíčových slov. Tento krok je kritický pro vytvoření robustního řešení RAG, protože zajišťuje optimalizaci extrahovaného obsahu pro pokročilé pracovní postupy vyhledávání a načítání.
# Embed the splitted documents and insert into Azure Search vector store
def embed_and_index_chunks(docs):
aoai_embeddings = AzureOpenAIEmbeddings(
azure_deployment=AZURE_OPENAI_EMBEDDING_DEPLOYMENT_NAME,
openai_api_version=AZURE_OPENAI_EMBEDDING_API_VERSION, # e.g., "2023-12-01-preview"
azure_endpoint=AZURE_OPENAI_ENDPOINT,
azure_ad_token_provider=token_provider
)
vector_store: AzureSearch = AzureSearch(
azure_search_endpoint=AZURE_SEARCH_ENDPOINT,
azure_search_key=None,
index_name=AZURE_SEARCH_INDEX_NAME,
embedding_function=aoai_embeddings.embed_query
)
vector_store.add_documents(documents=docs)
return vector_store
# embed and index the docs:
vector_store = embed_and_index_chunks(all_splits)
Sémantické načítání bloků dat
S vloženým a indexovaným extrahovaným obsahem je dalším krokem použití síly podobnosti a vektorového vyhledávání k načtení nejrelevavantnějších bloků informací. Tato část ukazuje, jak provádět podobnostní i hybridní vyhledávání, což systému umožňuje vyhledávat obsah na základě sémantického významu, spíše než přesných shod klíčových slov. Získáním kontextově relevantních úseků můžete zlepšit přesnost vašich pracovních postupů RAG a poskytovat přesnější, smysluplnější odpovědi na dotazy uživatelů.
# Set your query
query = "japan"
# Perform a similarity search
docs = vector_store.similarity_search(
query=query,
k=3,
search_type="similarity",
)
for doc in docs:
print(doc.page_content)
# Perform a hybrid search using the search_type parameter
docs = vector_store.hybrid_search(query=query, k=3)
for doc in docs:
print(doc.page_content)
Použití OpenAI k interakci s daty
Když je extrahovaný obsah vložený a indexovaný, posledním krokem při vytváření robustního řešení RAG je povolení konverzačních interakcí pomocí chatovacích modelů OpenAI. V této části se dozvíte, jak se dotazovat na indexovaná data a jak použít chatovací modely OpenAI, které poskytují stručné a kontextově bohaté odpovědi. Integrací konverzační umělé inteligence můžete své řešení RAG transformovat do interaktivního systému, který poskytuje smysluplné přehledy a vylepšuje zapojení uživatelů. Následující příklady vás provedou nastavením konverzačního toku s rozšířeným načítáním, který zajišťuje bezproblémovou integraci mezi vašimi daty a modely chatu OpenAI.
# Setup rag chain
prompt_str = """You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:"""
def setup_rag_chain(vector_store):
retriever = vector_store.as_retriever(search_type="similarity", k=3)
prompt = ChatPromptTemplate.from_template(prompt_str)
llm = AzureChatOpenAI(
openai_api_version=AZURE_OPENAI_CHAT_API_VERSION,
azure_deployment=AZURE_OPENAI_CHAT_DEPLOYMENT_NAME,
azure_ad_token_provider=token_provider,
temperature=0.7,
)
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
return rag_chain
# Setup conversational search
def conversational_search(rag_chain, query):
print(rag_chain.invoke(query))
rag_chain = setup_rag_chain(vector_store)
while True:
query = input("Enter your query: ")
if query=="":
break
conversational_search(rag_chain, query)