Analýza odpovědi rozhraní API dokumentu
Tento obsah se vztahuje na:![]() v4.0 (Preview)
v4.0 (Preview)![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)
V tomto článku se podíváme na různé objekty vrácené jako součást AnalyzeDocument odpovědi a na to, jak ve vašich aplikacích použít odpověď rozhraní API pro analýzu dokumentů.
Analýza žádosti o dokument
Rozhraní API funkce Document Intelligence analyzují obrázky, soubory PDF a další soubory dokumentů, aby extrahovali a rozpoznali různé obsahy, rozložení, styl a sémantické prvky. Operace analýzy je asynchronní rozhraní API. Odeslání dokumentu vrátí hlavičku Umístění operace, která obsahuje adresu URL pro dotazování na dokončení. Po úspěšném dokončení žádosti o analýzu obsahuje odpověď prvky popsané v extrakci dat modelu.
Prvky odpovědi
Prvky obsahu jsou základní textové prvky extrahované z dokumentu.
Prvky rozložení seskupí prvky obsahu do strukturálních jednotek.
Prvky stylu popisují písmo a jazyk prvků obsahu.
Sémantické prvky přiřazují význam zadaným prvkům obsahu.
Všechny prvky obsahu jsou seskupeny podle stránek určených číslem stránky (1indexováno). Jsou také seřazené podle pořadí čtení, které uspořádá sémanticky souvislé prvky dohromady, i když překříží hranice čar nebo sloupců. Když je pořadí čtení mezi odstavci a dalšími prvky rozložení nejednoznačné, služba obecně vrací obsah v pořadí zleva doprava a shora dolů.
Poznámka:
Funkce Document Intelligence v současné době nepodporuje pořadí čtení napříč hranicemi stránek. Značky výběru nejsou umístěny v okolních slovech.
Vlastnost obsahu nejvyšší úrovně obsahuje zřetězení všech prvků obsahu v pořadí čtení. Všechny prvky určují jejich pozici v pořadí čtenáře prostřednictvím rozsahů v rámci tohoto řetězce obsahu. Obsah některých prvků není vždy souvislý.
Analýza odpovědi
Odpověď analyzované pro každé rozhraní API vrací různé objekty. Odpovědi rozhraní API obsahují prvky z modelů komponent, pokud je to možné.
| Obsah odpovědi | Popis | rozhraní API |
|---|---|---|
| Stránky | Slova, řádky a rozsahy rozpoznané z každé stránky vstupního dokumentu. | Čtení, rozložení, obecný dokument, předem připravené a vlastní modely |
| Odstavce | Obsah rozpoznaný jako odstavce | Čtení, rozložení, obecný dokument, předem připravené a vlastní modely |
| Styly | Identifikované vlastnosti textového elementu. | Čtení, rozložení, obecný dokument, předem připravené a vlastní modely |
| Jazyky | Identifikovaný jazyk přidružený ke každému rozsahu extrahovaného textu | Čteno |
| Tabulky | Tabulkový obsah identifikovaný a extrahovaný z dokumentu Tabulky se vztahují k tabulkám identifikovaným předem natrénovaným modelem rozložení. Obsah označený jako tabulky se extrahuje jako strukturovaná pole v objektu dokumentů. | Rozložení, obecný dokument, faktura a vlastní modely |
| Čísla | Obrázky (grafy, obrázky) identifikované a extrahované z dokumentu a poskytují vizuální reprezentace, které pomáhají porozumět složitým informacím. | Model rozložení |
| Oddíly | Hierarchická struktura dokumentů byla identifikována a extrahována z dokumentu. Oddíl nebo pododdíl s odpovídajícími prvky (odstavec, tabulka, obrázek) připojenými k němu. | Model rozložení |
| keyValuePairs | Páry klíč-hodnota rozpoznané předem natrénovaným modelem Klíč je rozsah textu z dokumentu s přidruženou hodnotou. | Obecné modely dokumentů a faktur |
| Dokumenty | Rozpoznaná pole se vrátí ve slovníku fields v seznamu dokumentů. |
Předem připravené modely, vlastní modely. |
Další informace o objektech vrácených jednotlivými rozhraními API najdete v tématu extrakce dat modelu.
Vlastnosti elementu
Rozsahy
Spans určuje logickou pozici každého prvku v celkovém pořadí čtení, přičemž každé rozpětí určuje posun a délku znaku do vlastnosti řetězce obsahu nejvyšší úrovně. Ve výchozím nastavení se posuny a délky znaků vrací v jednotkách uživatelem vnímaných znaků (označovaných také jako grapheme clusters textové prvky). Aby uživatel vyhovoval různým vývojovým prostředím, které používají různé jednotky znaků, může zadat stringIndexIndex parametr dotazu, který vrátí posuny rozsahu a délky v bodech kódu Unicode (Python 3) nebo UTF16 (JavaScript, .NET). Další informace najdete v tématupodpora vícejazyčných a emoji.
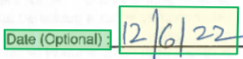
Ohraničující oblast
Ohraničující oblasti popisují vizuální umístění jednotlivých prvků v souboru. Pokud prvky nejsou vizuálně souvislé nebo křížové stránky (tabulky), pozice většiny prvků jsou popsány prostřednictvím pole ohraničující oblasti. Každá oblast určuje číslo stránky (1indexované) a ohraničující mnohoúhelník. Ohraničující mnohoúhelník je popsán jako posloupnost bodů ve směru hodinových ručiček zleva vzhledem k přirozené orientaci prvku. Pro čtyřúhelníky jsou body grafu vlevo nahoře, vpravo nahoře, vpravo dole a v levém dolním rohu. Každý bod představuje souřadnici x, y v jednotce stránky určené vlastností jednotky. Obecně platí, že měrná jednotka obrázků je pixely, zatímco soubory PDF používají palce.
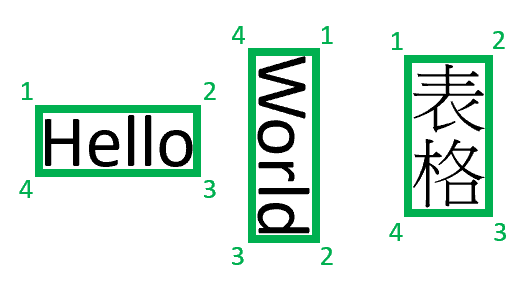
Poznámka:
Funkce Document Intelligence v současné době vrací pouze 4-vrcholové čtyřúhelníky jako ohraničující mnohoúhelníky. Budoucí verze můžou vrátit různé počty bodů pro popis složitějších obrazců, jako jsou zakřivené čáry nebo neúhledné obrázky. Ohraničující oblasti použité pouze u vykreslovaných souborů, pokud se soubor nevykreslí, nevracejí se ohraničující oblasti. Soubory formátu docx/xlsx/pptx/html se momentálně nevykreslí.
Prvky obsahu
Word
Slovo je prvek obsahu složený z posloupnosti znaků. Pomocí funkce Document Intelligence je slovo definováno jako posloupnost sousedních znaků s prázdnými znaky oddělujícími slova od sebe navzájem. Pro jazyky, které nepoužívají oddělovače mezer mezi slovy, se každý znak vrátí jako samostatné slovo, i když nepředstavuje sémantickou jednotku slova.

Značky výběru
Značka výběru je prvek obsahu, který představuje vizuální glyf označující stav výběru. Zaškrtávací políčko je běžnou formou značek výběru. Jsou ale také reprezentovány přepínači nebo krabicovou buňkou ve vizuálním formuláři. Stav značky výběru lze vybrat nebo zrušit výběr s jiným vizuálním znázorněným znázorněným stavem.

Prvky rozložení
Line
Řádek je uspořádaná posloupnost po sobě jdoucích prvků obsahu oddělených vizuálním prostorem nebo řádky, které bezprostředně sousedí pro jazyky bez oddělovačů mezer mezi slovy. Prvky obsahu ve stejné vodorovné rovině (řádku), ale oddělené více než jedním vizuálním prostorem jsou nejčastěji rozděleny na více řádků. I když tato funkce někdy rozděluje sémanticky souvislý obsah na samostatné řádky, umožňuje rozdělení textového obsahu do více sloupců nebo buněk. Čáry ve svislém zápisu jsou zjištěny ve svislém směru.

Odstavec
Odstavec je seřazená posloupnost řádků, které tvoří logickou jednotku. Čáry obvykle sdílejí společné zarovnání a mezery mezi čarami. Odstavce se často oddělují odsazením, přidají mezery nebo odrážkami nebo číslováním. Obsah lze přiřadit pouze jednomu odstavci. Vybrané odstavce je možné přidružit také k funkční roli v dokumentu. Mezi aktuálně podporované role patří záhlaví stránky, zápatí stránky, číslo stránky, název, nadpis oddílu a poznámka pod čarou.

Page
Stránka je seskupení obsahu, které obvykle odpovídá jedné straně listu papíru. Vykreslená stránka je charakterizována šířkou a výškou v zadané jednotce. Obecně platí, že obrázky používají pixel, zatímco pdf soubory používají paleci. Vlastnost úhel popisuje celkový úhel textu ve stupních pro stránky, které lze otočit.
Poznámka:
U tabulek, jako je Excel, se každý list mapuje na stránku. U prezentací, jako je PowerPoint, se každý snímek mapuje na stránku. U formátů souborů bez nativního konceptu stránek bez vykreslování, jako jsou dokumenty HTML nebo Word, se hlavní obsah souboru považuje za jednu stránku.
Table
Tabulka uspořádá obsah do skupiny buněk v rozložení mřížky. Řádky a sloupce můžou být vizuálně oddělené čarami mřížky, barevným pruhováním nebo většími mezerami. Pozice buňky tabulky se zadává prostřednictvím indexů řádků a sloupců. Buňka může být rozložená mezi více řádky a sloupci.
Na základě jejího umístění a stylu lze buňku klasifikovat jako obecný obsah, záhlaví řádku, záhlaví sloupce, hlava zástupných procedur nebo popis:
Buňka záhlaví řádku je obvykle první buňkou v řádku, která popisuje ostatní buňky v řádku.
Buňka záhlaví sloupce je obvykle první buňkou ve sloupci, která popisuje ostatní buňky ve sloupci.
Řádek nebo sloupec může obsahovat více buněk záhlaví, které popisují hierarchický obsah.
Buňka hlavy stub je obvykle buňka v prvním řádku a na pozici prvního sloupce. Může být prázdný nebo popsat hodnoty v buňkách záhlaví ve stejném řádku nebo sloupci.
Buňka popisu se obvykle zobrazí v horní nebo dolní oblasti tabulky s popisem celkového obsahu tabulky. Někdy se ale může zobrazit uprostřed tabulky, aby se tabulka rozdělila do oddílů. Popis buněk se obvykle rozprostírá mezi více buňkami v jednom řádku.
Tabulka popis určuje obsah, který tabulku vysvětluje. Tabulka může mít dále přidruženou popis a sadu poznámek pod čarou. Na rozdíl od buňky popisu popis obvykle leží mimo rozložení mřížky. Poznámka pod čarou tabulky označuje obsah uvnitř tabulky, často označený symbolem poznámky pod čarou, který se často nachází pod mřížkou tabulky.
Tabulky rozložení se liší od polí dokumentu extrahovaných z tabulkových dat. Tabulky rozložení se extrahují z tabulkového vizuálního obsahu v dokumentu bez ohledu na sémantiku obsahu. Některé tabulky rozložení jsou ve skutečnosti navrženy čistě pro vizuální rozložení a neobsahují vždy strukturovaná data. Metoda extrakce strukturovaných dat z dokumentů s různorodým vizuálním rozložením, jako jsou položky podrobností o účtenku, obecně vyžaduje významné následné zpracování. Je nezbytné namapovat záhlaví řádků nebo sloupců na strukturovaná pole s normalizovanými názvy polí. V závislosti na typu dokumentu použijte předem vytvořené modely nebo vytrénujte vlastní model k extrakci takového strukturovaného obsahu. Výsledné informace se zveřejňují jako pole dokumentu. Tyto vytrénované modely mohou také zpracovávat tabulková data bez záhlaví a strukturovaných dat v netabularových formulářích, například část pracovní zkušenosti životopisu.

Čísla
Obrázky (grafy, obrázky) v dokumentech hrají zásadní roli při doplňování a vylepšování textového obsahu a poskytují vizuální reprezentace, které pomáhají porozumět složitým informacím. Objekt obrázků zjištěný modelem rozložení má klíčové vlastnosti, jako boundingRegions jsou (prostorová umístění obrázku na stránkách dokumentu, včetně čísla stránky a mnohoúhelníku, které znázorňují hranici obrázku), spans (podrobnosti o rozsahu textu souvisejícího s obrázkem, určení jejich posunů a délek v textu dokumentu. Toto připojení pomáhá při přidružování obrázku k příslušnému textovému kontextu) elements (identifikátory textových prvků nebo odstavců v dokumentu, které souvisejí s obrázkem nebo popisují) a caption pokud nějaké existují.
{
"figures": [
{
"boundingRegions": [],
"spans": [],
"elements": [
"/paragraphs/15",
...
],
"caption": {
"content": "Here is a figure with some text",
"boundingRegions": [],
"spans": [],
"elements": [
"/paragraphs/15"
]
}
}
]
}
Oddíly
Hierarchická analýza struktury dokumentů je klíčová při uspořádání, pochopení a zpracování rozsáhlých dokumentů. Tento přístup je nezbytný pro séanticky segmentace dlouhých dokumentů, aby se zvýšila porozumění, usnadnila navigace a zlepšila načítání informací. Nástup načítání rozšířené generace (RAG) v dokumentu generující AI podtržítka význam hierarchické analýzy struktury dokumentů. Model rozložení podporuje oddíly a pododdíly ve výstupu, které identifikují vztah oddílů a objektů v jednotlivých oddílech. Hierarchická struktura se udržuje v elements každé části.
{
"sections": [
{
"spans": [],
"elements": [
"/paragraphs/0",
"/sections/1",
"/sections/2",
"/sections/5"
]
},
...
}
Pole formuláře (pár klíč-hodnota)
Pole formuláře se skládá z popisku pole (klíče) a hodnoty. Popisek pole je obecně popisný textový řetězec popisující význam pole. Často se zobrazuje nalevo od hodnoty, i když se může zobrazit také nad nebo pod hodnotou. Hodnota pole obsahuje hodnotu obsahu konkrétní instance pole. Hodnota se může skládat ze slov, značek výběru a dalších prvků obsahu. Může být také prázdný pro nevyplněná pole formuláře. Speciální typ pole formuláře má hodnotu značky výběru s popiskem pole napravo. Pole dokumentu je podobné, ale odlišné koncepty od obecných polí formuláře. Popisek pole (klíč) v obecném poli formuláře se musí zobrazit v dokumentu. Proto nemůže obecně zaznamenávat informace, jako je název obchodníka v účtenku. Pole dokumentu jsou označená a neextrahují klíč. Pole dokumentu mapují pouze extrahovaná hodnota na označený klíč. Další informace najdete vpolích dokumentu.

Prvky stylu
Styl
Prvek stylu popisuje styl písma, který se má použít u textového obsahu. Obsah se zadává prostřednictvím rozsahů do globální vlastnosti obsahu. V současné době je jediným zjištěným stylem písma to, jestli je text ručně psaný. Při přidání jiných stylů je možné text popsat prostřednictvím více objektů stylu, které nejsouconflicting. Pro kompaktnost jsou všechny texty sdílející konkrétní styl písma (se stejnou jistotou) popsány prostřednictvím jednoho objektu stylu.
{
"confidence": 1,
"spans": [
{
"offset": 2402,
"length": 7
}
],
"isHandwritten": true
}
Jazyk
Element jazyka popisuje rozpoznaný jazyk pro obsah zadaný prostřednictvím rozsahů do vlastnosti globálního obsahu. Zjištěný jazyk se zadává prostřednictvím značky jazyka BCP-47, která označuje primární jazyk a volitelné informace o skriptu a oblasti. Například angličtina a tradiční čínština jsou rozpoznány jako "en" a zh-Hant, v uvedeném pořadí. Regionální rozdíly v pravopisu pro angličtinu ve Velké Británii můžou vést k rozpoznání textu jako en-GB. Prvky jazyka nepokrývají text bez dominantního jazyka (např. čísel).
Sémantické prvky
Poznámka:
Sémantické prvky popsané zde platí pro předem připravené modely funkce Document Intelligence. Vaše vlastní modely můžou vracet různé reprezentace dat. Například datum a čas vrácený vlastním modelem může být reprezentován vzorem, který se liší od standardního formátování ISO 8601.
Dokument
Dokument je séanticky úplná jednotka. Soubor může obsahovat více dokumentů, například více daňových formulářů v souboru PDF nebo více účtenek na jedné stránce. Řazení dokumentů v souboru však nemá zásadní vliv na informace, které předává.
Poznámka:
Funkce Document Intelligence v současné době nepodporuje více dokumentů na jedné stránce.
Typ dokumentu popisuje dokumenty sdílející společnou sadu sémantických polí reprezentovaných strukturovaným schématem nezávisle na své vizuální šabloně nebo rozložení. Například všechny dokumenty typu "účtenka" mohou obsahovat název obchodníka, datum transakce a celkový součet transakcí, i když restaurace a hotel účtenky se často liší vzhledem.
Prvek dokumentu obsahuje seznam rozpoznaných polí z polí určených sémantickým schématem zjištěného typu dokumentu:
Pole dokumentu lze extrahovat nebo odvodit. Extrahovaná pole jsou reprezentována extrahovaným obsahem a volitelně jeho normalizovanou hodnotou, pokud je interpretovatelná.
Odvozené pole nemá vlastnost obsahu a je reprezentována pouze prostřednictvím její hodnoty.
Pole neobsahuje vlastnost obsahu. Obsah může být zřetězen z obsahu prvků pole.
Pole objektu obsahuje vlastnost obsahu, která určuje celý obsah představující objekt, který může být nadmnožinou extrahovaných dílčích polí.
Sémantické schéma typu dokumentu je popsáno prostřednictvím polí, která obsahuje. Každé schéma pole je určeno pomocí kanonického názvu a typu hodnoty. Mezi typy hodnot polí patří základní (např. řetězec), složená (např. adresa) a strukturované typy (např. pole, objekt). Typ hodnoty pole také určuje sémantickou normalizaci provedenou za účelem převodu zjištěného obsahu na reprezentaci normalizace. Normalizace může být závislá na národním prostředí.
Základní typy
| Typ hodnoty pole | Popis | Normalizovaná reprezentace | Příklad (obsah pole –> hodnota) |
|---|---|---|---|
| string | Prostý text | Stejné jako obsah | MerchantName: "Contoso" → "Contoso" |
| datum | Datum | ISO 8601 - YYYY-MM-DD | InvoiceDate: "5/7/2022" → "2022-05-07" |
| čas | Čas | ISO 8601 - hh:mm:ss | TransactionTime: "9:45 PM" → "21:45:00" |
| phoneNumber | Telefonní číslo | E.164 - +{CountryCode}{SubscriberNumber} | Práce Telefon: "(800) 555-7676" → "+18005557676" |
| Země | Země/oblast | ISO 3166-1 alfa-3 | Země: "USA" → "USA" |
| selectionMark | Je vybráno. | "podepsáno" nebo "bez znaménka" | AcceptEula: ☑ → "selected" |
| Podpis | Je podepsáno | Stejné jako obsah | LendeeSignature: {signature} → "signed" |
| Číslo | Číslo s plovoucí desetinnou čárkou | Číslo s plovoucí desetinnou čárkou | Množství: "1,20" → 1,2 |
| integer | Celé číslo | 64bitové podepsané číslo | Počet: "123" → 123 |
| boolean | Logická hodnota | true/false | IsStatutoryEmployee: ☑ → true |
Složené typy
Měna: Částka měny s volitelnou měnou jednotky. Hodnota, například:
InvoiceTotal: $123.45{ "amount": 123.45, "currencySymbol": "$" }Adresa: Parsovaná adresa. Příklad:
ShipToAddress: 123 Main St., Redmond, WA 98052{ "poBox": "PO Box 12", "houseNumber": "123", "streetName": "Main St.", "city": "Redmond", "state": "WA", "postalCode": "98052", "countryRegion": "USA", "streetAddress": "123 Main St." }
Strukturované typy
Pole: Seznam polí stejného typu
"Items": { "type": "array", "valueArray": [ ] }Objekt: Pojmenovaný seznam dílčích polí potenciálně různých typů
"InvoiceTotal": { "type": "currency", "valueCurrency": { "currencySymbol": "$", "amount": 110 }, "content": "$110.00", "boundingRegions": [ { "pageNumber": 1, "polygon": [ 7.3842, 7.465, 7.9181, 7.465, 7.9181, 7.6089, 7.3842, 7.6089 ] } ], "confidence": 0.945, "spans": [ { "offset": 806, "length": 7 } ] }
Další kroky
Zkuste pomocí nástroje Document Intelligence Studio zpracovat vlastní formuláře a dokumenty.
Dokončete rychlý start s funkcí Document Intelligence a začněte vytvářet aplikaci pro zpracování dokumentů ve zvoleném vývojovém jazyce.