Sestavení a trénování vlastního klasifikačního modelu
Tento obsah se vztahuje na:![]() v4.0 (Preview) | Předchozí verze:
v4.0 (Preview) | Předchozí verze:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)
Důležité
Vlastní klasifikační model je aktuálně ve verzi Public Preview. Funkce, přístupy a procesy se můžou před obecnou dostupností (GA) změnit na základě zpětné vazby uživatelů.
Vlastní klasifikační modely mohou klasifikovat každou stránku ve vstupním souboru a identifikovat tak dokumenty v rámci. Klasifikátorové modely mohou také identifikovat více dokumentů nebo více instancí jednoho dokumentu ve vstupním souboru. Vlastní modely Document Intelligence vyžadují pro zahájení práce maximálně pět trénovacích dokumentů na třídu dokumentů. Abyste mohli začít trénovat vlastní klasifikační model, potřebujete alespoň pět dokumentů pro každou třídu a dvě třídy dokumentů.
Požadavky na vstup modelu vlastní klasifikace
Ujistěte se, že vaše trénovací datová sada splňuje vstupní požadavky pro funkci Document Intelligence.
Nejlepšíchvýsledkůch
Podporované formáty souborů:
Model PDF Obrázek:
JPEG/JPG, PNG, BMP, TIFF, HEIFsystém Microsoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX) a HTMLČteno ✔ ✔ ✔ Rozložení ✔ ✔ ✔ (2024-02-29-preview, 2023-10-31-preview) Obecný dokument ✔ ✔ Předpřipravený ✔ ✔ Vlastní extrakce ✔ ✔ Vlastní klasifikace ✔ ✔ ✔ (29. 2024. 2024) U SOUBORŮ PDF a TIFF je možné zpracovat až 2000 stránek (s předplatným úrovně Free se zpracovávají pouze první dvě stránky).
Velikost souboru pro analýzu dokumentů je 500 MB pro placenou úroveň (S0) a 4 MB pro bezplatnou úroveň (F0).
Rozměry obrázku musí být mezi 50 x 50 pixelů a 10 000 px x 10 000 pixelů.
Pokud jsou soubory PDF uzamčené heslem, musíte před odesláním toto uzamčení odebrat.
Minimální výška extrahovaného textu je 12 pixelů pro obrázek o velikosti 1024 x 768 pixelů. Tato dimenze odpovídá
8150 bodům na palec (DPI).Pro trénování vlastního modelu je maximální počet stránek pro trénovací data 500 pro vlastní model šablony a 50 000 pro vlastní neurální model.
Pro trénování vlastního modelu extrakce je celková velikost trénovacích dat 50 MB pro model šablony a 1G MB pro neurální model.
Pro trénování modelu vlastní klasifikace je
1GBcelková velikost trénovacích dat s maximálně 10 000 stránkami.
Tipy pro trénování dat
Projděte si tyto tipy k další optimalizaci datové sady pro trénování:
Pokud je to možné, místo obrázkových dokumentů používejte textové dokumenty PDF. Naskenované dokumenty PDF se zpracovávají jako obrázky.
Pokud jsou obrázky formuláře méně kvalitní, použijte větší datovou sadu (např. 10 až 15 obrázků).
Nahrání trénovacích dat
Jakmile sestavíte sadu formulářů nebo dokumentů pro trénování, musíte ji nahrát do kontejneru úložiště objektů blob v Azure. Pokud nevíte, jak vytvořit účet úložiště Azure s kontejnerem, postupujte podle rychlého startu azure Storage pro Azure Portal. Službu můžete vyzkoušet pomocí cenové úrovně Free (F0) a později upgradovat na placenou úroveň pro produkční prostředí. Pokud je vaše datová sada uspořádaná jako složky, zachovejte tuto strukturu, protože Studio může pro popisky zjednodušit proces označování pomocí názvů složek.
Vytvoření projektu klasifikace v nástroji Document Intelligence Studio
Sada Document Intelligence Studio poskytuje a orchestruje všechna volání rozhraní API potřebná k dokončení datové sady a trénování modelu.
Začněte tím, že přejdete do sady Document Intelligence Studio. Při prvním použití sady Studio je potřeba inicializovat předplatné, skupinu prostředků a prostředek. Potom podle požadavků pro vlastní projekty nakonfigurujte Studio pro přístup k trénovací datové sadě.
V sadě Studio vyberte dlaždici Vlastní klasifikační model , v části Vlastní modely na stránce a vyberte tlačítko Vytvořit projekt .
V dialogovém okně vytvořit projekt zadejte název projektu, volitelně popis a vyberte pokračovat.
Než vyberete pokračovat, zvolte nebo vytvořte prostředek funkce Document Intelligence.
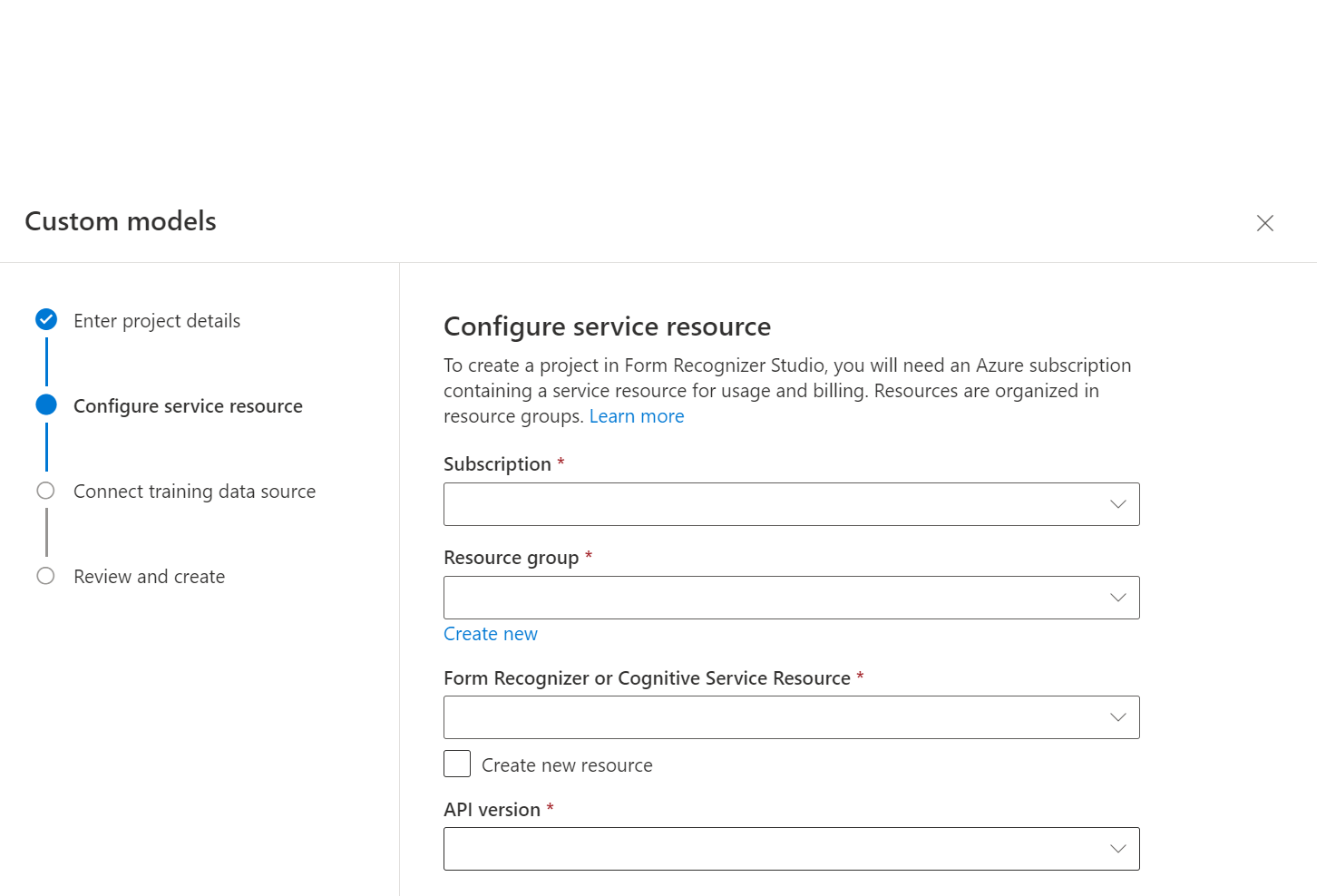
Pak vyberte účet úložiště, který jste použili k nahrání vlastní trénovací datové sady modelu. Cesta ke složce by měla být prázdná, pokud jsou vaše trénovací dokumenty v kořenovém adresáři kontejneru. Pokud jsou vaše dokumenty v podsložce, zadejte relativní cestu z kořenového adresáře kontejneru do pole Cesta ke složce. Po nakonfigurování účtu úložiště vyberte pokračovat.
Důležité
Trénovací datovou sadu můžete uspořádat podle složek, kde je název složky popisek nebo třída dokumentů, nebo můžete vytvořit plochý seznam dokumentů, ke kterým můžete přiřadit popisek v sadě Studio.
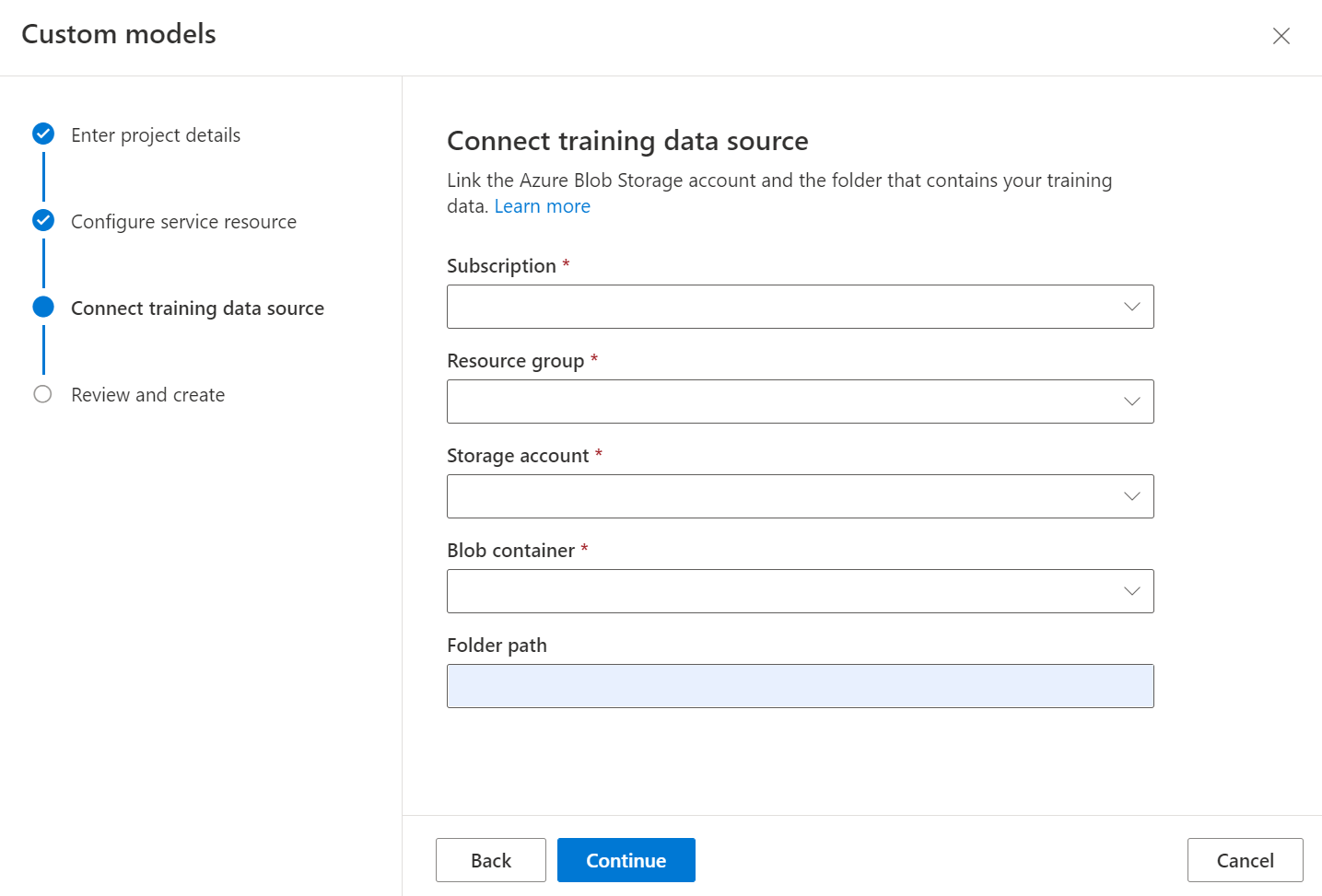
Trénování vlastního klasifikátoru vyžaduje výstup modelu rozložení pro každý dokument v datové sadě. Před procesem trénování modelu spusťte rozložení pro všechny dokumenty.
Nakonec zkontrolujte nastavení projektu a vyberte Vytvořit projekt a vytvořte nový projekt. Teď byste měli být v okně popisků a vidět soubory v datové sadě.
Označení dat
V projektu stačí označit každý dokument pouze popiskem příslušné třídy.
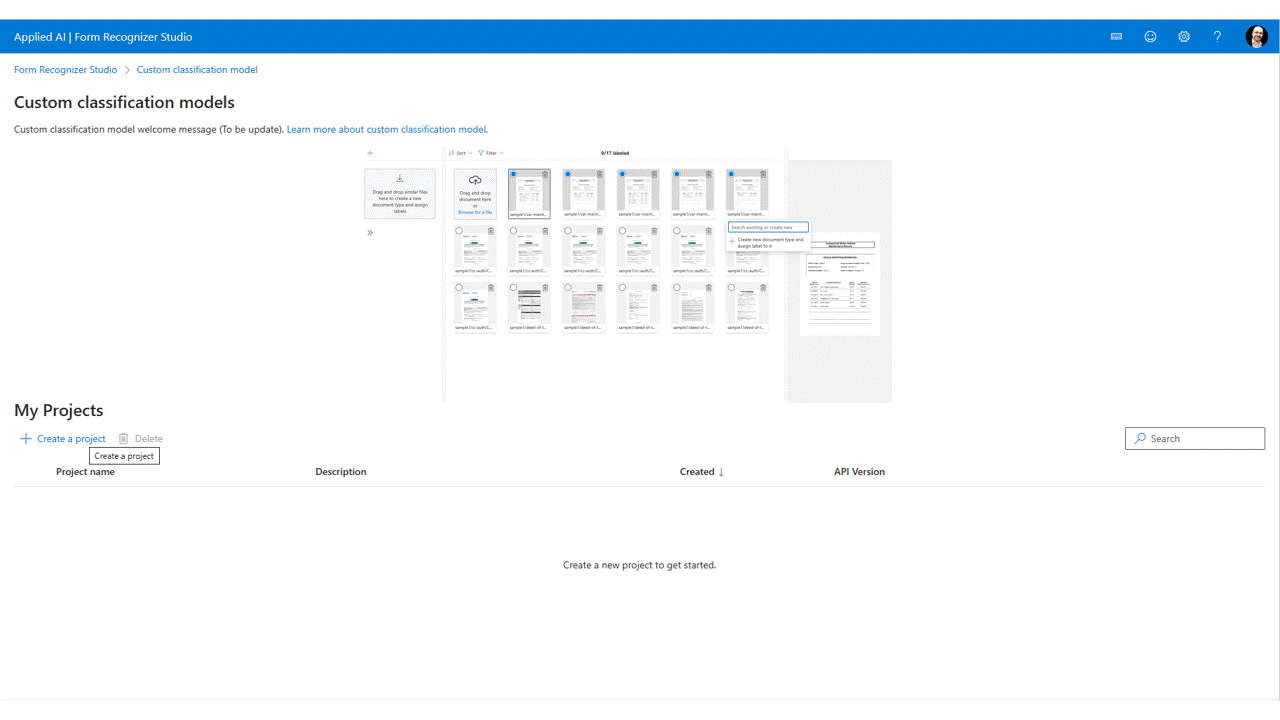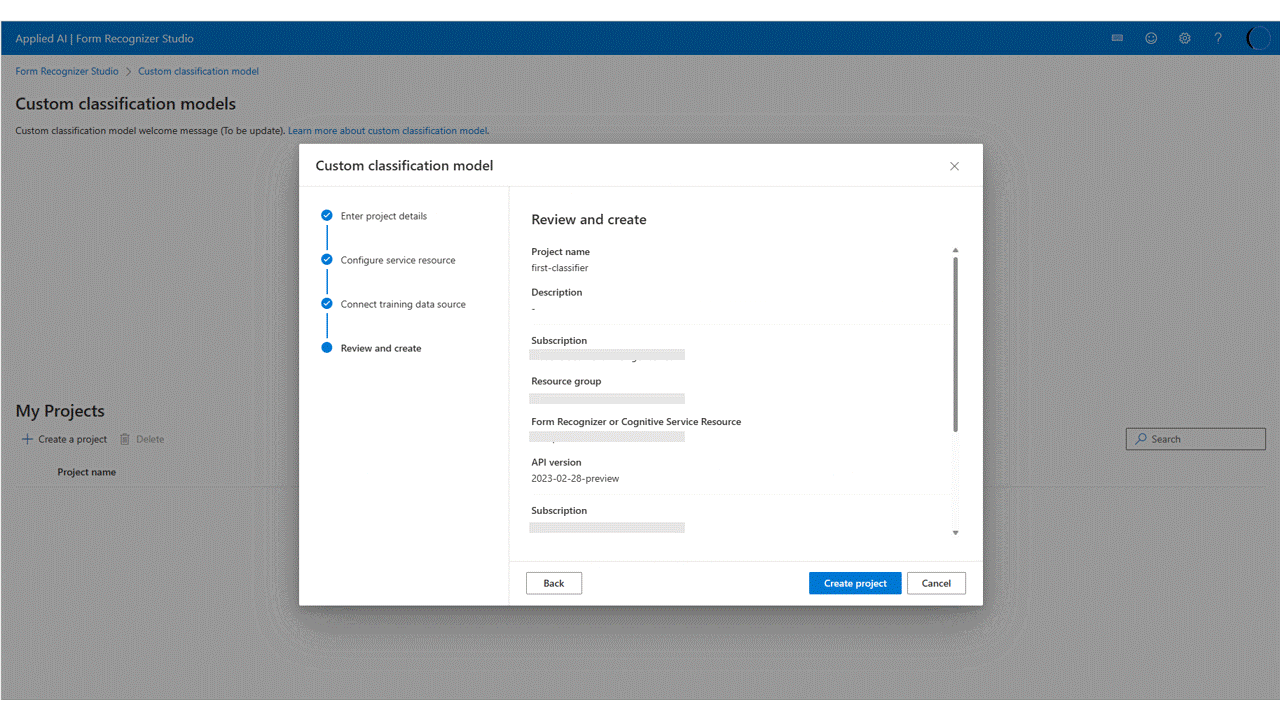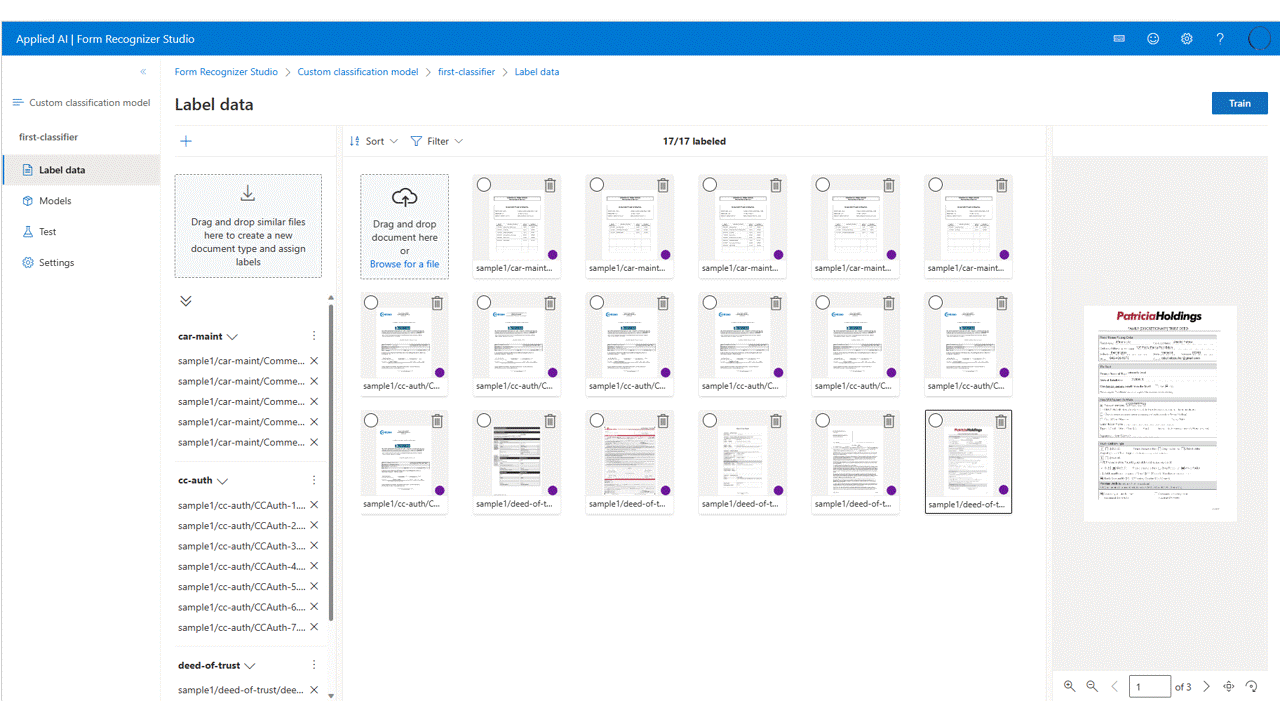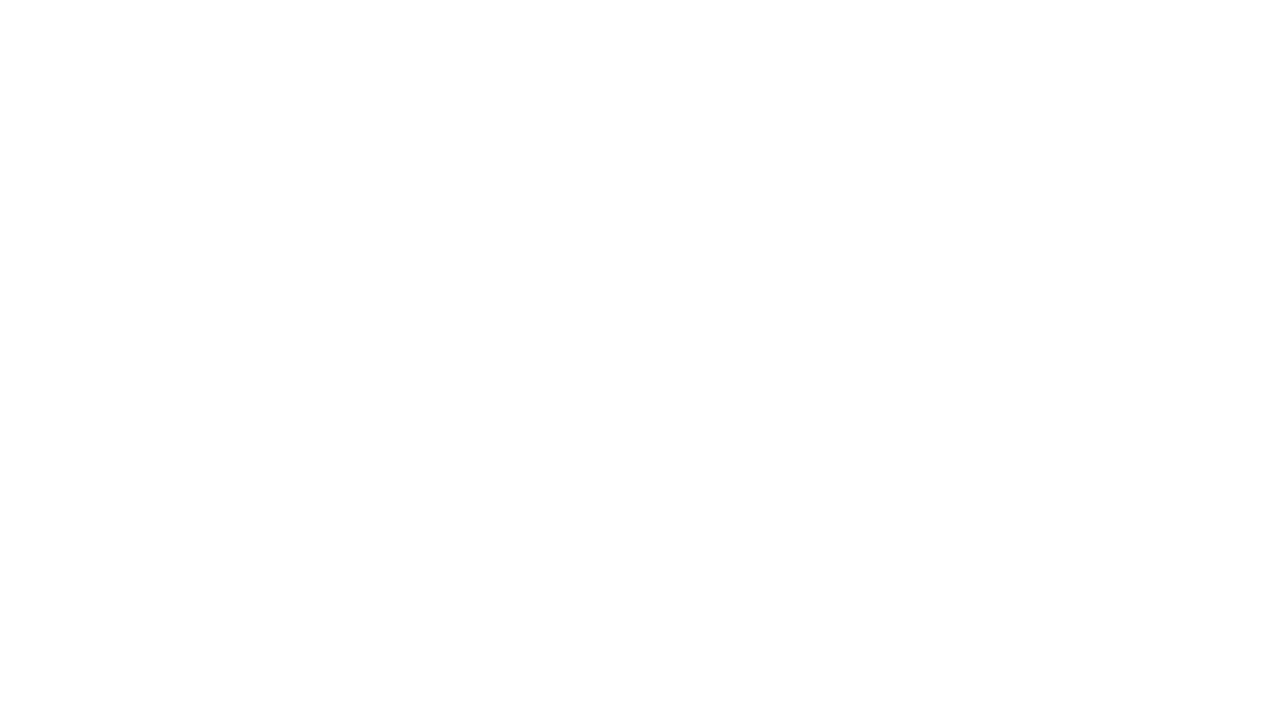
V seznamu souborů uvidíte soubory, které jste nahráli do úložiště, připravené k označení. Datovou sadu můžete označovat několika způsoby.
Pokud jsou dokumenty uspořádané do složek, studio vás vyzve, abyste jako popisky použili názvy složek. Tento krok zjednodušuje popisky až na jeden výběr.
Pokud chcete přiřadit popisek k dokumentu, vyberte u značky pro přidání výběru popisku popisek a přiřaďte popisek.
Výběr ovládacího prvku pro vícenásobný výběr dokumentů pro přiřazení popisku
Teď byste měli mít všechny dokumenty v datové sadě označené popiskem. Pokud se podíváte na účet úložiště, najdete .ocr.json soubory, které odpovídají jednotlivým dokumentům v trénovací datové sadě a novému souboru class-name.jsonl pro každou třídu označenou. Tato trénovací datová sada se odešle pro trénování modelu.
Trénování vašeho modelu
S označenou datovou sadou teď můžete model vytrénovat. V pravém horním rohu vyberte tlačítko vlaku.
V dialogovém okně modelu trénování zadejte jedinečné ID klasifikátoru a volitelně i popis. ID klasifikátoru přijímá datový typ řetězce.
Výběrem možnosti Trénování zahájíte proces trénování.
Klasifikátor modely se trénuje za několik minut.
Přejděte do nabídky Modely a zobrazte stav operace trénování.
Test modelu
Po dokončení trénování modelu můžete model otestovat výběrem modelu na stránce seznamu modelů.
Vyberte model a vyberte na tlačítku Test .
Přidejte nový soubor tak, že přejdete na soubor nebo ho přehodíte do selektoru dokumentu.
Pokud je vybraný soubor, zvolte tlačítko Analyzovat a otestujte model.
Výsledky modelu se zobrazí se seznamem identifikovaných dokumentů, skóre spolehlivosti pro každý identifikovaný dokument a rozsah stránek pro každý z identifikovaných dokumentů.
Ověřte model vyhodnocením výsledků pro každý identifikovaný dokument.
Trénování vlastního klasifikátoru pomocí sady SDK nebo rozhraní API
Studio orchestruje volání rozhraní API k trénování vlastního klasifikátoru. Trénovací datová sada klasifikátoru vyžaduje výstup z rozhraní API rozložení, které odpovídá verzi rozhraní API pro trénovací model. Použití výsledků rozložení ze starší verze rozhraní API může vést k vytvoření modelu s nižší přesností.
Studio vygeneruje výsledky rozložení pro trénovací datovou sadu, pokud datová sada neobsahuje výsledky rozložení. Při použití rozhraní API nebo sady SDK k trénování klasifikátoru je potřeba přidat výsledky rozložení do složek obsahujících jednotlivé dokumenty. Výsledky rozložení by měly být ve formátu odpovědi rozhraní API při přímém volání rozložení. Objektový model sady SDK se liší, ujistěte se, že layout results se jedná o výsledky rozhraní API, nikoli o SDK response.
Odstraňování potíží
Klasifikační model vyžaduje výsledky z modelu rozložení pro každý trénovací dokument. Pokud výsledky rozložení nezadáte, studio se pokusí spustit model rozložení pro každý dokument před trénováním klasifikátoru. Tento proces je omezený a může vést k odpovědi 429.
Před trénováním s klasifikačním modelem spusťte v každém dokumentu model rozložení a nahrajte ho do stejného umístění jako původní dokument. Po přidání výsledků rozložení můžete model klasifikátoru vytrénovat pomocí dokumentů.
Další kroky
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro