Poznámka
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Tento obsah se vztahuje na:![]() v4.0 (GA) | Předchozí verze:
v4.0 (GA) | Předchozí verze:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)![]() v2.1 (GA)
v2.1 (GA)
::: moniker-end
Tento obsah se vztahuje na:![]() v2.1 | Nejnovější verze:
v2.1 | Nejnovější verze:![]() v4.0 (GA)
v4.0 (GA)
Model faktury document intelligence používá výkonné funkce optického rozpoznávání znaků (OCR) k analýze a extrakci klíčových polí a řádkových položek z prodejních faktur, faktur za utility a nákupních objednávek. Faktury můžou mít různé formáty a kvalitu, včetně obrázků zachycených telefonem, naskenovaných dokumentů a digitálních souborů PDF. Rozhraní API analyzuje text faktury; extrahuje klíčové informace, jako je jméno zákazníka, fakturační adresa, termín splatnosti a splatnost částky; a vrátí strukturovanou reprezentaci dat JSON. Model aktuálně podporuje faktury ve 27 jazycích.
Podporované typy dokumentů:
- Faktury
- Faktury za utility
- Prodejní objednávky
- Nákupní objednávky
Automatizované zpracování faktur
Automatizované zpracování faktur je proces extrakce klíčových accounts payable polí z dokumentů fakturačního účtu. Extrahovaná data zahrnují řádkové položky z faktur integrovaných s pracovními postupy pro platby a recenze účtů (AP). V minulosti se proces splatných účtů provádí ručně, a proto je velmi časově náročný. Přesná extrakce klíčových dat z faktur je obvykle první a jeden z nejdůležitějších kroků v procesu automatizace faktury.
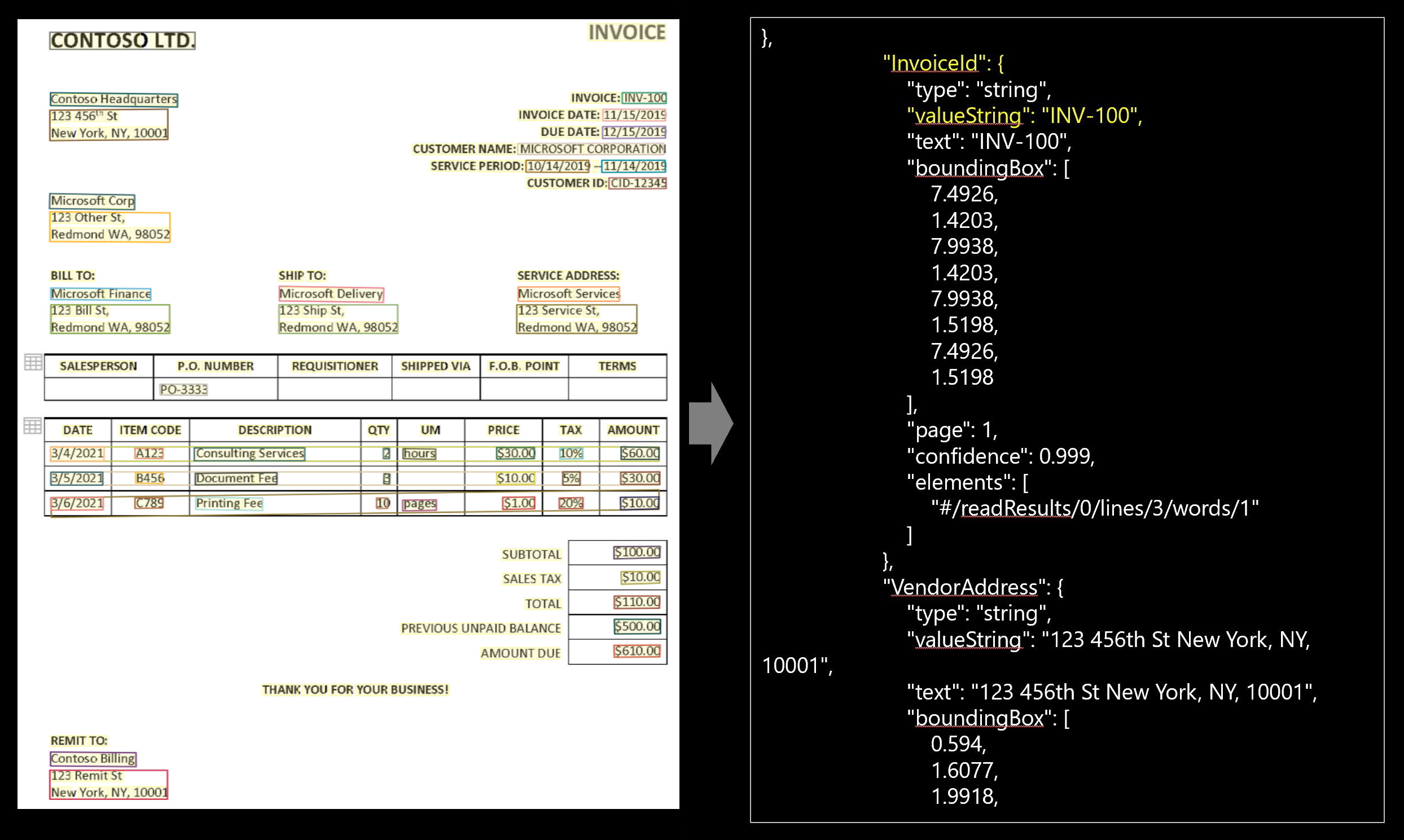
Ukázková faktura zpracovaná pomocí nástroje Document Intelligence Studio:

Ukázková faktura zpracovaná pomocí nástroje Popisování ukázek funkce Document Intelligence:
Možnosti vývoje
Document Intelligence v4.0: 2024-11-30 (GA) podporuje následující nástroje, aplikace a knihovny:
| Funkce | Zdroje informací | ID modelu |
|---|---|---|
| Model faktury | • Document Intelligence Studio • REST API • C# SDK • Python SDK• Java SDK • JavaScript SDK• JavaScript SDK |
předem připravená faktura |
Document Intelligence v3.1 podporuje následující nástroje, aplikace a knihovny:
| Funkce | Zdroje informací | ID modelu |
|---|---|---|
| Model faktury | • Document Intelligence Studio • REST API • C# SDK • Python SDK• Java SDK • JavaScript SDK• JavaScript SDK |
předem připravená faktura |
Document Intelligence v3.0 podporuje následující nástroje, aplikace a knihovny:
| Funkce | Zdroje informací | ID modelu |
|---|---|---|
| Model faktury | • Document Intelligence Studio • REST API • C# SDK • Python SDK• Java SDK • JavaScript SDK• JavaScript SDK |
předem připravená faktura |
Document Intelligence v2.1 podporuje následující nástroje, aplikace a knihovny:
| Funkce | Zdroje informací |
|---|---|
| Model faktury | • Nástroj pro popisování document intelligence• REST API • sada SDK klientské knihovny• Kontejner Document Intelligence Dockeru |
Požadavky na vstup
Podporované formáty souborů:
| Model | Obrázek: JPEG/JPG, PNG, BMP, TIFF, HEIF |
systém Microsoft Office: Word ( DOCX), Excel (XLSX), PowerPoint (PPTX), HTML |
|
|---|---|---|---|
| Čteno | ✔ | ✔ | ✔ |
| Rozložení | ✔ | ✔ | ✔ |
| Obecný dokument | ✔ | ✔ | |
| Předpřipravený | ✔ | ✔ | |
| Vlastní extrakce | ✔ | ✔ | |
| Vlastní klasifikace | ✔ | ✔ | ✔ |
Nejlepšíchvýsledkůch
U SOUBORŮ PDF a TIFF je možné zpracovat až 2 000 stránek (s předplatným úrovně Free se zpracuje pouze první dvě stránky).
Velikost souboru pro analýzu dokumentů je 500 MB pro placenou úroveň (S0) a
4MB pro bezplatnou úroveň (F0).Rozměry obrázku musí být mezi 50 pixely x 50 pixelů a 10 000 pixelů x 10 000 pixelů.
Pokud jsou soubory PDF uzamčené heslem, musíte před odesláním toto uzamčení odebrat.
Minimální výška extrahovaného textu je 12 pixelů pro obrázek o velikosti 1024 x 768 pixelů. Tato dimenze odpovídá
8bodě textu na 150 bodů na palec (DPI).Pro trénování vlastního modelu je maximální počet stránek pro trénovací data 500 pro vlastní model šablony a 50 000 pro vlastní neurální model.
Pro trénování vlastního modelu extrakce je celková velikost trénovacích dat 50 MB pro model šablony a
1GB pro neurální model.Pro trénování modelu vlastní klasifikace je
1celková velikost trénovacích dat GB s maximálně 10 000 stránkami. Pro 30.11.2024 (GA) je2celková velikost trénovacích dat GB s maximálně 10 000 stránkami.
- Podporované formáty souborů: JPEG, PNG, PDF a TIFF.
- Podporované soubory PDF a TIFF, zpracovávají se až 2 000 stránek. Pro předplatitele úrovně Free se zpracovávají pouze první dvě stránky.
- Podporovaná velikost souboru musí být menší než 50 MB a rozměry nejméně 50 × 50 pixelů a maximálně 10 000 × 10 000 pixelů.
Extrakce dat modelu faktury
Podívejte se, jak se data, včetně informací o zákaznících, podrobností o dodavateli a řádkových položek, extrahují z faktur. Potřebujete následující zdroje informací:
Předplatné Azure – můžete si ho zdarma vytvořit.
Instance Document Intelligence na webu Azure Portal K vyzkoušení služby můžete použít cenovou úroveň Free (
F0). Po nasazení prostředku vyberte Přejít k prostředku a získejte klíč a koncový bod.
Na domovské stránce nástroje Document Intelligence Studio vyberte Faktury.
Ukázkovou fakturu můžete analyzovat nebo nahrát vlastní soubory.
Vyberte tlačítko Spustit analýzu a v případě potřeby nakonfigurujte možnosti Analyzovat:

Nástroj Document Intelligence Sample Labeling
Přejděte k nástroji Ukázka funkce Document Intelligence.
Na domovské stránce ukázkového nástroje vyberte k získání dlaždice s daty předem vytvořený model.
V rozevírací nabídce vyberte typ formuláře, který chcete analyzovat.
Vyberte adresu URL souboru, který chcete analyzovat, z následujících možností:
- Ukázkový dokument faktury
- Ukázkový dokument s ID
- Ukázkový obrázek potvrzení
- Ukázkový obrázek vizitky
V poli Zdroj vyberte adresu URL z rozevírací nabídky, vložte vybranou adresu URL a vyberte tlačítko Načíst.
Do pole koncový bod služby Document Intelligence vložte koncový bod, který jste získali s předplatným Document Intelligence.
Do pole s klíčem vložte klíč, který jste získali z prostředku Document Intelligence.
Vyberte Spustit analýzu. Nástroj Popisování ukázek funkce Document Intelligence volá předem připravené rozhraní API pro analýzu a analyzuje dokument.
Prohlédněte si výsledky – prohlédněte si páry klíč-hodnota extrahované, řádkové položky, zvýrazněný text extrahovaný a zjištěné tabulky.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Poznámka:
Nástroj Sample Labeling nepodporuje formát souboru BMP. Jedná se o omezení nástroje, nikoli služby Document Intelligence.
Podporované jazyky a národní prostředí
Úplný seznam podporovaných jazyků najdete na naší stránce podpory předem připravených jazyků modelu.
Extrakce polí
Podporovaná pole pro extrakci dokumentů najdete na stránce schématu modelu faktury v našem ukázkovém úložišti GitHubu.
Páry klíč-hodnota faktury a extrahované řádkové položky jsou v
documentResultsčásti výstupu JSON.
Páry klíč-hodnota
Předem připravený model faktury podporuje volitelný návrat párů klíč-hodnota. Ve výchozím nastavení je návrat párů klíč-hodnota zakázán. Páry klíč-hodnota jsou specifické rozsahy v rámci faktury, které identifikují popisek nebo klíč a jeho přidruženou odpověď nebo hodnotu. Na faktuře můžou být tyto páry popiskem a hodnotou, kterou uživatel zadal pro dané pole nebo telefonní číslo. Model AI se vytrénuje tak, aby extrahovala identifikovatelné klíče a hodnoty na základě široké škály typů dokumentů, formátů a struktur.
Klíče mohou existovat také izolovaně, když model zjistí, že klíč existuje, bez přidružené hodnoty nebo při zpracování volitelných polí. Například pole s prostředním názvem může být v některých případech prázdné ve formuláři. Páry klíč-hodnota jsou vždy rozloženy do textu obsaženého v dokumentu. U dokumentů, ve kterých je stejná hodnota popsaná různými způsoby, například zákazník/uživatel, je přidruženým klíčem zákazník nebo uživatel (na základě kontextu).
Výstup JSON
Výstup JSON má tři části:
-
"readResults"uzel obsahuje veškerý rozpoznaný text a značky výběru. Text je uspořádaný přes stránku, pak po řádku a potom podle jednotlivých slov. -
"pageResults"Uzel obsahuje tabulky a buňky extrahované s ohraničujícími poli, jistotou a odkazem na řádky a slova v readResults. -
"documentResults"uzel obsahuje hodnoty specifické pro fakturu a řádkové položky, které model zjistil. Tady najdete všechna pole z faktury, jako je ID faktury, odeslání, faktura, zákazník, celkový součet, řádkové položky a spousta dalších položek.
Průvodce migrací
- Postupujte podle našeho průvodce migrací Document Intelligence v3.1 a zjistěte, jak používat verzi v3.0 ve vašich aplikacích a pracovních postupech.
::: moniker-end
Další kroky
Zkuste pomocí nástroje Document Intelligence Studio zpracovat vlastní formuláře a dokumenty.
Dokončete rychlý start s funkcí Document Intelligence a začněte vytvářet aplikaci pro zpracování dokumentů ve zvoleném vývojovém jazyce.
Zkuste zpracovat vlastní formuláře a dokumenty pomocí nástroje Document Intelligence Sample Labeling.
Dokončete rychlý start s funkcí Document Intelligence a začněte vytvářet aplikaci pro zpracování dokumentů ve zvoleném vývojovém jazyce.