Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Proces označování je důležitou součástí přípravy datové sady. Vzhledem k tomu, že tento proces vyžaduje čas i úsilí, můžete pomocí funkce automatického označování automaticky označovat entity. Úlohy automatického označování můžete spustit na základě modelu, který jste dříve natrénovali, nebo za použití modelů GPT. Pomocí automatického popisování založeného na modelu, který jste dříve natrénovali, můžete začít popisovat několik dokumentů, vytrénovat model a pak vytvořit úlohu automatického označení, která vytvoří popisky entit pro jiné dokumenty založené na daném modelu. S automatickým GPT popisováním můžete okamžitě spustit úlohu automatického označování bez předchozího trénování modelu. Tato funkce vám může ušetřit čas a úsilí při ručním označování entit.
Požadavky
Než budete moct používat automatické označování na základě modelu, který jste natrénovali, potřebujete:
- Úspěšně vytvořený projekt s nakonfigurovaným účtem úložiště objektů blob v Azure.
- Textová data nahraná do vašeho úložiště.
- Označená data
- Úspěšně natrénovaný model
Spustit úlohu automatického označování
Když aktivujete úlohu automatického označování na základě modelu, který jste vytrénovali, platí měsíční limit 5 000 textových záznamů na prostředek. Stejný limit platí pro všechny projekty ve stejném zdroji.
Návod
Textový záznam se vypočítá jako strop (počet znaků v dokumentu / 1 000). Pokud má například dokument 8 921 znaků, je počet textových záznamů:
ceil(8921/1000) = ceil(8.921), což je devět textových záznamů.
V levém podokně vyberte Označování dat.
Vyberte tlačítko Autolabel v podokně Aktivita napravo od stránky.
Zvolte automatické označení na základě modelu, který jste natrénovali, a vyberte Další.

Zvolte natrénovaný model. Před použitím automatického označování doporučujeme zkontrolovat výkon modelu.
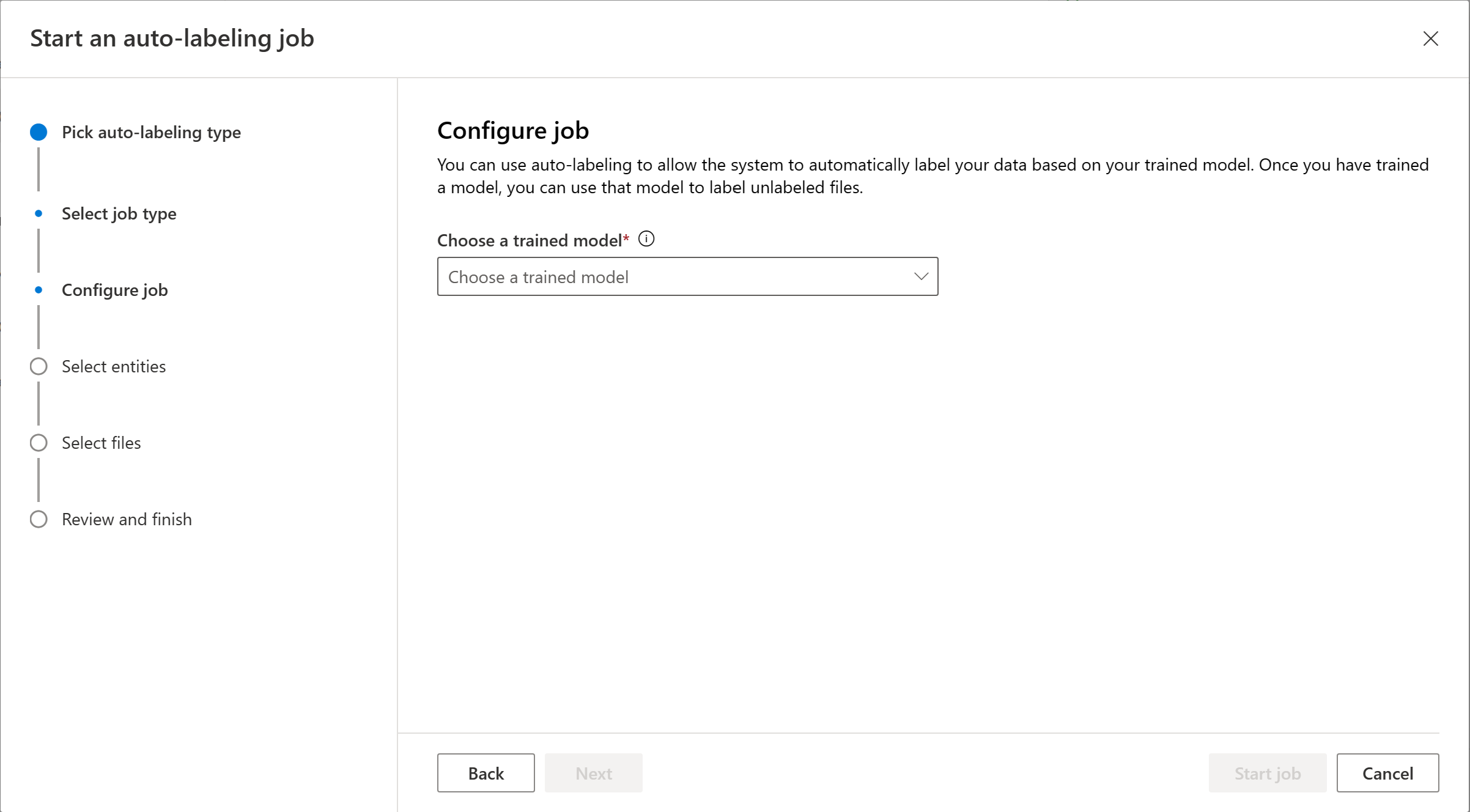
Zvolte entity, které chcete zahrnout do úlohy automatického označování. Ve výchozím nastavení jsou vybrány všechny entity. Můžete zobrazit celkový počet označení, přesnost a citlivost jednotlivých entit. Doporučujeme zahrnout entity, které dobře fungují, aby se zajistila kvalita automaticky označených entit.
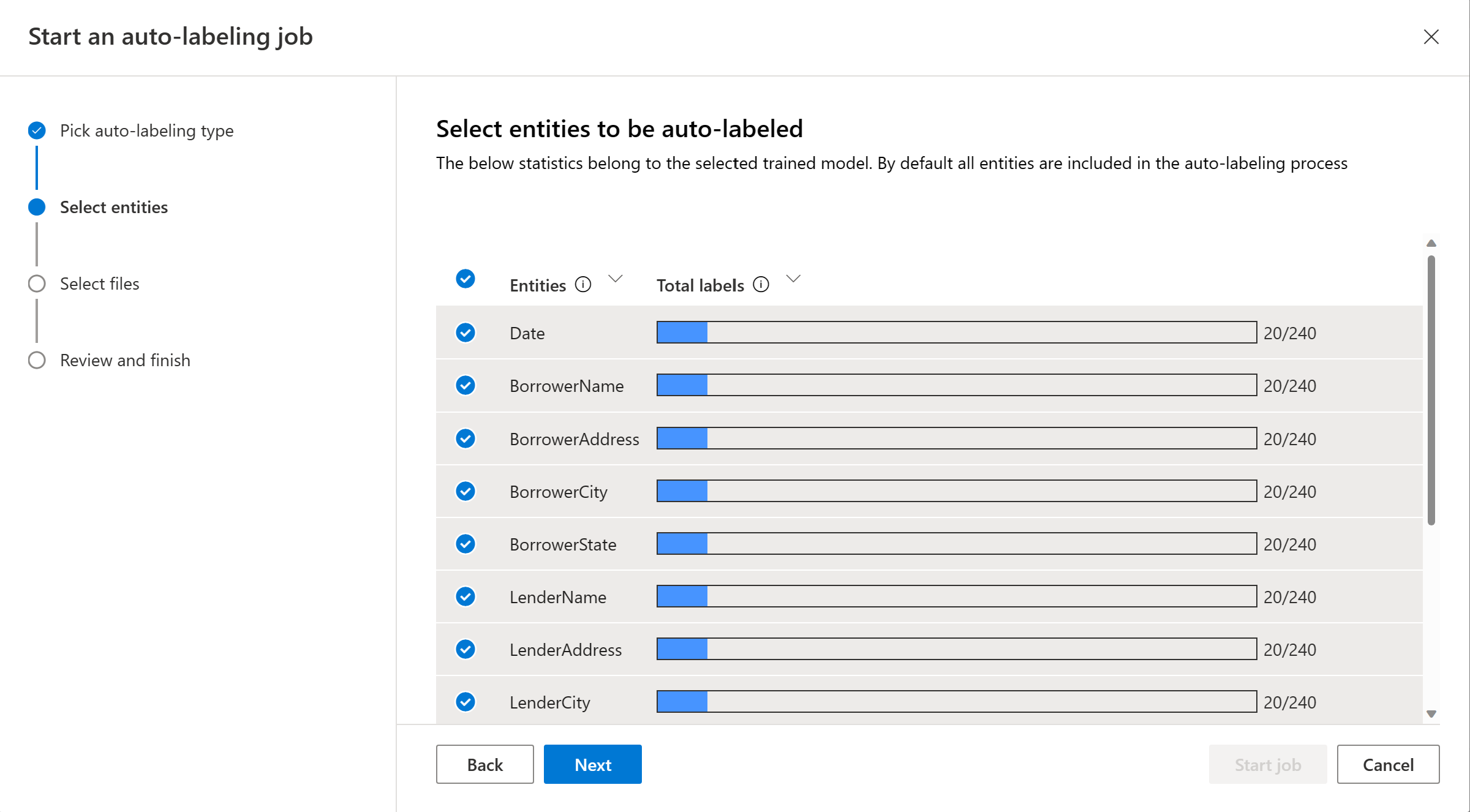
Vyberte dokumenty, které chcete automaticky označovat. Zobrazí se počet textových záznamů každého dokumentu. Když vyberete jeden nebo více dokumentů, měl by se zobrazit počet vybraných textových záznamů. Doporučujeme zvolit z filtru neoznačené dokumenty.
Poznámka:
- Pokud byla entita automaticky označena, ale má popisek definovaný uživatelem, použije se a zobrazí pouze popisek definovaný uživatelem.
- Dokumenty můžete zobrazit tak, že vyberete název dokumentu.
Výběrem Autolabel aktivujte úlohu automatického popisování. Měli byste vidět použitý model, počet dokumentů zahrnutých v úloze automatického označení, počet textových záznamů a entit, které se mají automaticky označovat. Úlohy automatického označování můžou trvat od několika sekund do několika minut v závislosti na počtu zahrnutých dokumentů.








Kontrola automaticky označených dokumentů
Po dokončení úlohy automatického označení se výstupní dokumenty zobrazí na stránce Popisování dat v sadě Language Studio. Výběrem možnosti Zkontrolovat dokumenty s automatickými štítky zobrazíte dokumenty s filtrem pro automatické štítkování.

Entity, které jsou automaticky označené tečkovanou čárou Tyto entity mají dva selektory (značku zaškrtnutí a symbol X), které umožňují přijmout nebo odmítnout automatický popisek.
Po přijetí entity se tečkovaná čára změní na plnou a značka se zahrne do jakéhokoli dalšího školení modelu, čímž se stane vámi definovanou značkou.
Případně můžete přijmout nebo odmítnout všechny automaticky označené entity v dokumentu pomocí možnosti Přijmout vše nebo Odmítnout vše v pravém horním rohu obrazovky.
Po přijetí nebo odmítnutí označených prvků vyberte Uložit popisky, aby se změny uložily.
Poznámka:
- Doporučujeme před přijetím ověřit automaticky označené entity.
- Všechny popisky, které nejsou akceptovány, se při trénování modelu odstraní.

Další kroky
- Přečtěte si další informace o označování dat.