Zobrazení vyhodnocení a podrobností modelu klasifikace textu
Po dokončení trénování modelu můžete zobrazit výkon modelu a zobrazit predikované třídy pro dokumenty v testovací sadě.
Poznámka
Použití možnosti Automaticky rozdělit testovací sadu od trénovacích dat může mít za následek jiný výsledek vyhodnocení modelu při každém trénování nového modelu, protože testovací sada se z dat vybírá náhodně. Abyste měli jistotu, že se vyhodnocení počítá na stejné testovací sadě při každém trénování modelu, nezapomeňte při spuštění trénovací úlohy použít možnost Použít ruční rozdělení trénovacích a testovacích dat a definovat testovací dokumenty při označování dat.
Požadavky
Před zobrazením vyhodnocení modelu potřebujete:
- Vlastní projekt klasifikace textu s nakonfigurovaným účtem úložiště objektů blob v Azure.
- Textová data, která se nahrála do vašeho účtu úložiště.
- Popsaná data
- Úspěšně natrénovaný model
Další informace najdete v tématu Životní cyklus vývoje projektu .
Podrobnosti o modelu
Přejděte na stránku projektu v nástroji Language Studio.
V nabídce na levé straně obrazovky vyberte Výkon modelu .
Na této stránce můžete zobrazit pouze úspěšně natrénované modely, skóre F1 pro každý model a datum vypršení platnosti modelu. Výběrem názvu modelu získáte další podrobnosti o jeho výkonu.
Poznámka
Třídy, které nejsou v testovací sadě označeny ani predikovány, nebudou součástí zobrazených výsledků.
Na této kartě můžete zobrazit podrobnosti modelu, jako jsou: skóre F1, přesnost, úplnost, datum a čas trénovací úlohy, celková doba trénování a počet trénovacích a testovacích dokumentů zahrnutých v této úloze trénování.
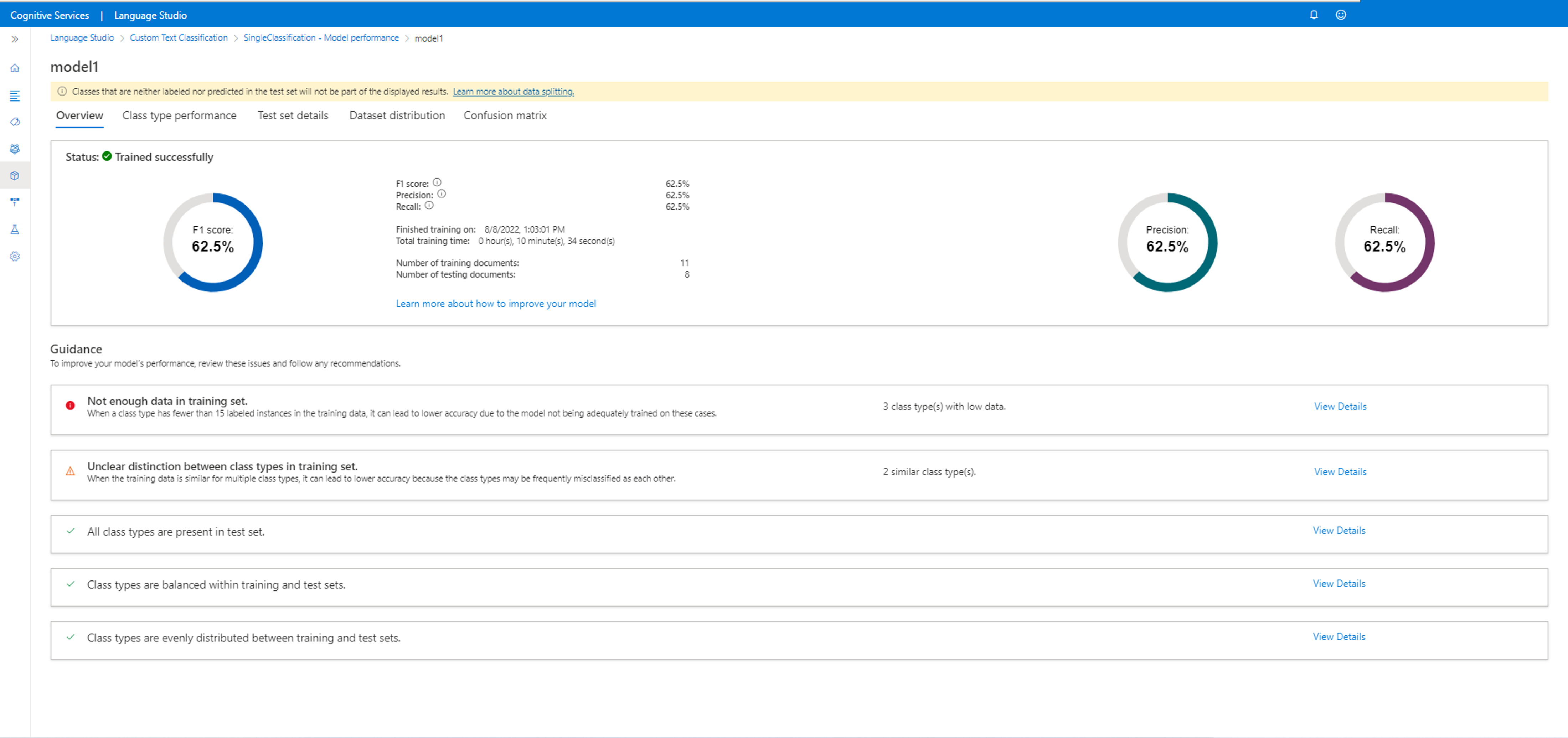
Zobrazí se také pokyny k vylepšení modelu. Po kliknutí na zobrazení podrobností se otevře boční panel s dalšími pokyny, jak model vylepšit. V tomto příkladu není v trénovací sadě pro tyto třídy dostatek dat. V trénovací sadě je také nejasný rozdíl mezi typy tříd, kde jsou dvě třídy vzájemně zaměňovány. Kliknutím na zmatené třídy budete přesměrováni na stránku popisků dat , kde můžete označit více dat správnou třídou.
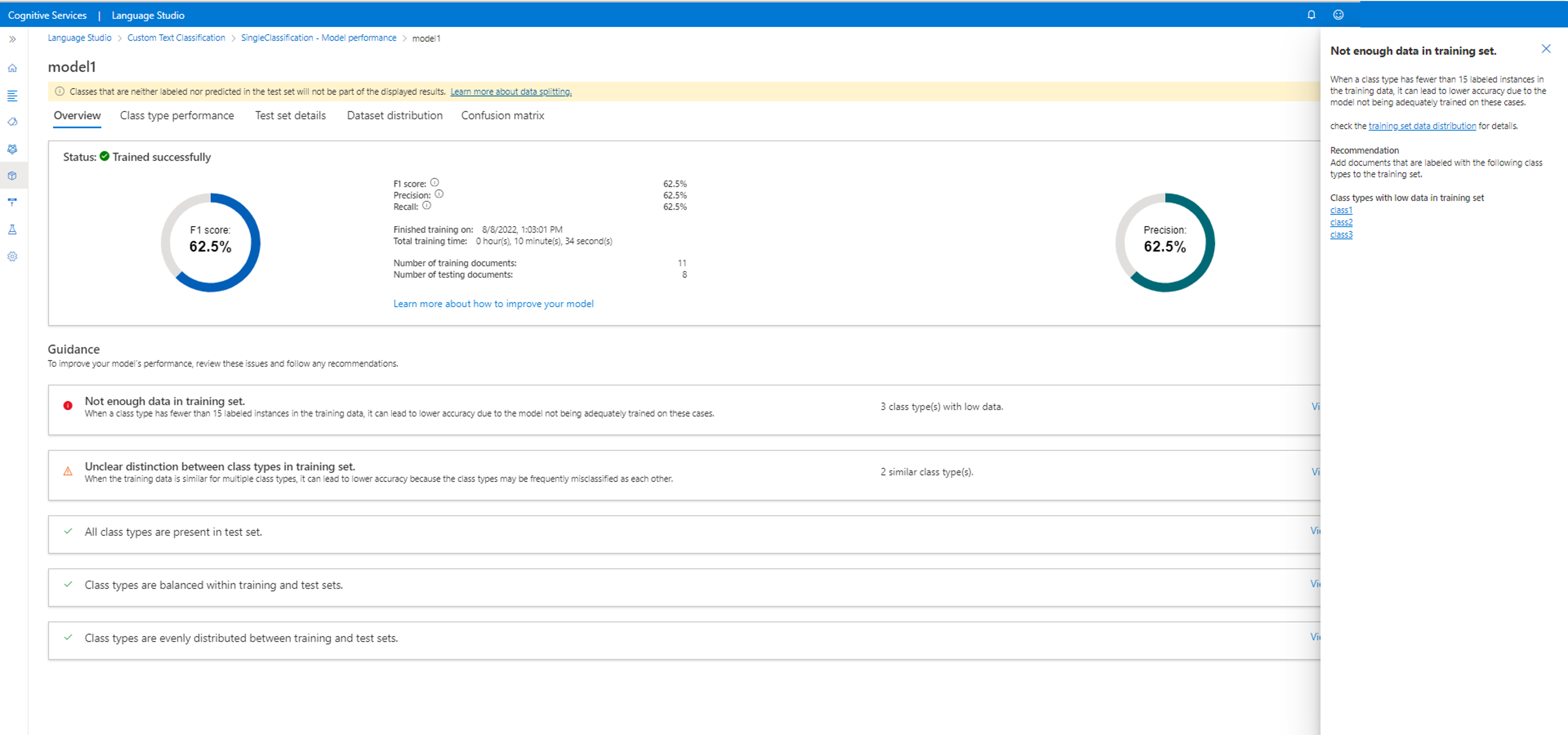
Přečtěte si další informace o pokynech k modelu a matici záměny v konceptech výkonu modelu .







Načtení nebo export dat modelu
Načtení dat modelu:
Na stránce vyhodnocení modelu vyberte libovolný model.
Vyberte tlačítko Načíst data modelu .
Ověřte, že nemáte žádné neuložené změny, které potřebujete zaznamenat v zobrazeném okně, a vyberte Načíst data.
Počkejte, až se data modelu načtou zpátky do projektu. Po dokončení budete přesměrováni zpět na stránku návrhu schématu .
Export dat modelu:
Na stránce vyhodnocení modelu vyberte libovolný model.
Vyberte tlačítko Exportovat data modelu . Počkejte, až se místně stáhne snímek JSON vašeho modelu.
Odstranit model
Odstranění modelu v nástroji Language Studio:
V nabídce vlevo vyberte Výkon modelu .
Vyberte název modelu , který chcete odstranit, a v horní nabídce vyberte Odstranit .
V zobrazeném okně vyberte OK a model odstraňte.
Další kroky
Při kontrole výkonu modelu se seznámíte s metrikami vyhodnocení , které se používají. Jakmile víte, jestli se výkon vašeho modelu musí zlepšit, můžete začít model vylepšovat.
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro