Rychlý start: vlastní shrnutí (Preview)
V tomto článku můžete začít vytvářet vlastní projekt souhrnu, ve kterém můžete trénovat vlastní modely nad souhrnem. Model je software umělé inteligence, který je natrénovaný k určitému úkolu. V tomto systému modely shrnují text a trénují se učením z importovaných dat.
V tomto článku používáme Language Studio k předvedení klíčových konceptů vlastního souhrnu. Jako příklad vytvoříme vlastní sumarizační model pro extrahování zařízení nebo místa ošetření z krátkých poznámek k uvolnění.
Požadavky
- Předplatné Azure: Můžete si ho vytvořit zdarma.
Vytvoření nového prostředku Azure AI Language a účtu úložiště Azure
Než budete moct použít vlastní sumarizaci, budete muset vytvořit prostředek jazyka Azure AI, který vám poskytne přihlašovací údaje, které potřebujete k vytvoření projektu a zahájení trénování modelu. Budete také potřebovat účet úložiště Azure, kde můžete nahrát datovou sadu, která se použije k sestavení modelu.
Důležité
Pokud chcete rychle začít, doporučujeme vytvořit nový prostředek jazyka Azure AI pomocí kroků uvedených v tomto článku. Pomocí kroků v tomto článku můžete vytvořit prostředek jazyka a účet úložiště současně, což je jednodušší než později.
Vytvoření nového prostředku z webu Azure Portal
Přejděte na web Azure Portal a vytvořte nový prostředek jazyka Azure AI.
V zobrazeném okně vyberte tuto službu z vlastních funkcí. Vyberte Pokračovat a vytvořte prostředek v dolní části obrazovky.

Vytvořte prostředek jazyka s následujícími podrobnostmi.
Název Popis Předplatné Vaše předplatné Azure. Skupina prostředků Skupina prostředků, která bude obsahovat váš prostředek. Můžete použít existující nebo vytvořit nový. Oblast Oblast vašeho prostředku Jazyk. Například "USA – západ 2". Název Název vašeho prostředku Cenová úroveň Cenová úroveň vašeho prostředku Jazyk. Službu můžete vyzkoušet pomocí úrovně Free (F0). Poznámka:
Pokud se zobrazí zpráva"Váš přihlašovací účet není vlastníkem skupiny prostředků vybraného účtu úložiště", musí mít váš účet přiřazenou roli vlastníka pro skupinu prostředků, abyste mohli vytvořit prostředek jazyka. Požádejte o pomoc vlastníka předplatného Azure.
V části této služby vyberte existující účet úložiště nebo vyberte Nový účet úložiště. Tyto hodnoty vám pomůžou začít, a ne nutně hodnoty účtu úložiště, které budete chtít použít v produkčních prostředích. Abyste se vyhnuli latenci při sestavování projektu, připojte se k účtům úložiště ve stejné oblasti jako prostředek jazyka.
Hodnota účtu úložiště Doporučená hodnota Název účtu úložiště Libovolný název Storage account type Standardní LRS Ujistěte se, že je zaškrtnuté příslušné oznámení O umělé inteligenci. V dolní části stránky vyberte Zkontrolovat a vytvořit a pak vyberte Vytvořit.

Stažení ukázkových dat
Pokud potřebujete ukázková data, poskytli jsme pro účely tohoto rychlého startu některé scénáře sumarizace textu a shrnutí konverzací.
Nahrání ukázkových dat do kontejneru objektů blob
Vyhledejte soubory, které chcete nahrát do účtu úložiště.
Na webu Azure Portal přejděte k účtu úložiště, který jste vytvořili, a vyberte ho.
V účtu úložiště vyberte v nabídce vlevo kontejnery umístěné pod úložištěm dat. Na obrazovce, která se zobrazí, vyberte + Kontejner. Pojmenujte kontejner ukázková data a ponechte výchozí úroveň veřejného přístupu.
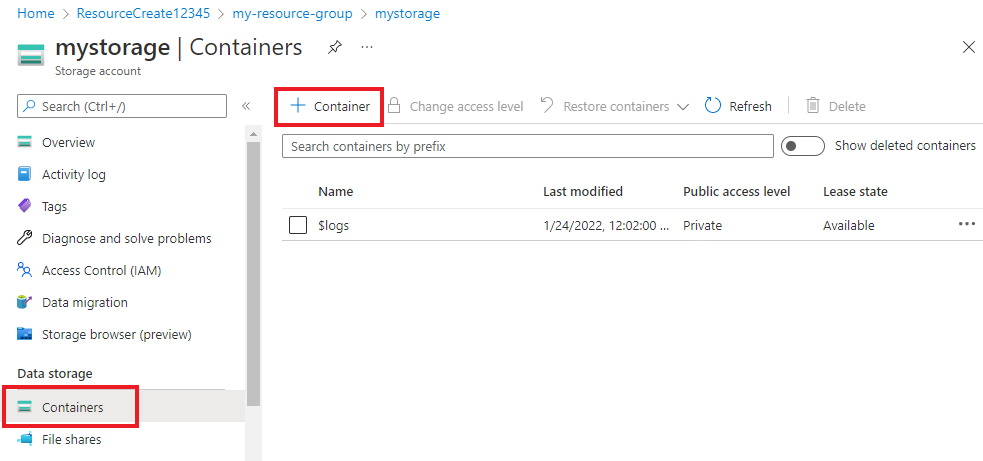
Po vytvoření kontejneru ho vyberte. Pak vyberte tlačítko Nahrát a
.jsonvyberte soubory.txt, které jste stáhli dříve.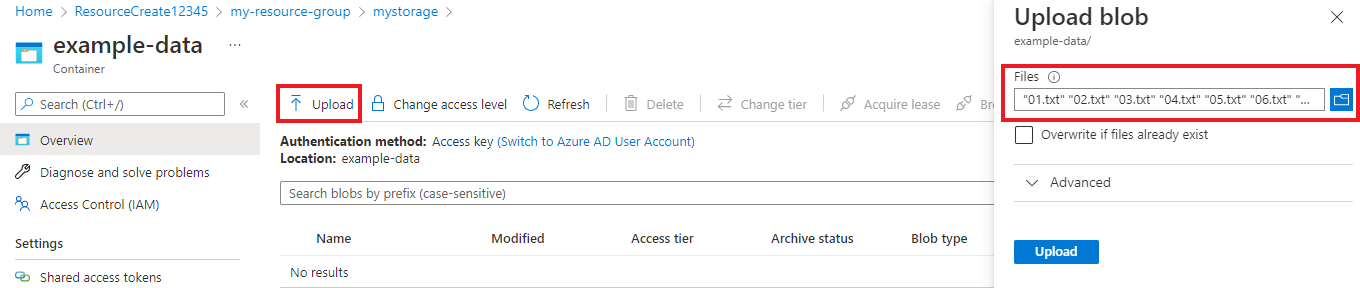


Vytvoření vlastního projektu souhrnu
Jakmile nakonfigurujete svůj prostředek a účet úložiště, vytvořte nový vlastní projekt souhrnu. Projekt je pracovní oblast pro vytváření vlastních modelů ML na základě vašich dat. K vašemu projektu má přístup jenom vy a ostatní, kteří mají přístup k používanému prostředku jazyka.
Přihlaste se k sadě Language Studio. Zobrazí se okno, ve které můžete vybrat předplatné a prostředek jazyka. Vyberte prostředek jazyka, který jste vytvořili v předchozím kroku.
Vyberte funkci, kterou chcete použít v sadě Language Studio.
V horní nabídce na stránce projektů vyberte Vytvořit nový projekt . Vytvoření projektu umožňuje označit data, trénovat, vyhodnocovat, vylepšovat a nasazovat modely.

Zadejte informace o projektu, včetně názvu, popisu a jazyka souborů v projektu. Pokud používáte ukázkovou datovou sadu, vyberte angličtinu. Později nemůžete změnit název projektu. Vyberte Další.
Tip
Vaše datová sada nemusí být úplně ve stejném jazyce. Můžete mít více dokumentů, z nichž každý má různé podporované jazyky. Pokud vaše datová sada obsahuje dokumenty různých jazyků nebo pokud očekáváte text z různých jazyků během běhu, vyberte možnost povolit vícejazyčnou datovou sadu , když zadáte základní informace o projektu. Tuto možnost můžete povolit později na stránce Nastavení projektu.
Po výběru možnosti Vytvořit nový projekt se zobrazí okno, které vám umožní připojit účet úložiště. Pokud jste už připojili účet úložiště, zobrazí se účet úložiště připojený. Pokud ne, zvolte účet úložiště v rozevíracím seznamu, který se zobrazí, a vyberte Připojení účet úložiště. Tím se nastaví požadované role pro váš účet úložiště. Tento krok pravděpodobně vrátí chybu, pokud nejste v účtu úložiště přiřazeni jako vlastník .
Poznámka:
- Tento krok stačí provést jenom jednou pro každý nový prostředek, který používáte.
- Tento proces je nevratný, pokud k prostředku jazyka připojíte účet úložiště, nemůžete ho později odpojit.
- Prostředek jazyka můžete připojit pouze k jednomu účtu úložiště.
Vyberte kontejner, do kterého jste datovou sadu nahráli.
Pokud jste už označili data, ujistěte se, že se řídí podporovaným formátem, a vyberte Ano, soubory jsou už označené a mám formátovaný soubor popisků JSON a v rozevírací nabídce vyberte soubor štítků. Vyberte Další. Pokud datovou sadu používáte z rychlého startu, nemusíte si prohlédnout formátování souboru s popisky JSON.
Zkontrolujte zadaná data a vyberte Vytvořit projekt.

Trénování vašeho modelu
Po vytvoření projektu začnete trénovat model.
Zahájení trénování modelu v sadě Language Studio:
V nabídce na levé straně vyberte Úlohy trénování .
V horní nabídce vyberte Spustit trénovací úlohu .
Vyberte Vytrénovat nový model a do textového pole zadejte název modelu. Existující model můžete také přepsat tak, že vyberete tuto možnost a zvolíte model, který chcete přepsat z rozevírací nabídky. Přepsání natrénovaného modelu je nevratné, ale nebude mít vliv na nasazené modely, dokud nový model nenasadíte.
Ve výchozím nastavení systém rozdělí označená data mezi trénovací a testovací sady podle zadaných procent. Pokud máte v testovací sadě dokumenty, můžete trénovací a testovací data rozdělit ručně.
Vyberte tlačítko Trénovat.
Pokud v seznamu vyberete ID trénovací úlohy, zobrazí se boční podokno, kde můžete zkontrolovat průběh trénování, stav úlohy a další podrobnosti o této úloze.
Poznámka:
- Pouze úspěšně dokončené trénovací úlohy vygenerují modely.
- Trénování může trvat několik minut až několik hodin na základě velikosti označených dat.
- Najednou můžete mít spuštěnou pouze jednu úlohu trénování. V rámci stejného projektu nemůžete spustit další úlohu trénování, dokud se nedokončí spuštěná úloha.

Nasazení modelu
Obecně platí, že po trénování modelu byste zkontrolovali podrobnosti o jeho vyhodnocení a v případě potřeby provedli vylepšení. V tomto rychlém startu jednoduše nasadíte model a zpřístupníte ho pro vyzkoušení v sadě Language Studio.
Nasazení modelu v sadě Language Studio:
V nabídce na levé straně vyberte Nasazení modelu .
Vyberte Přidat nasazení a spusťte novou úlohu nasazení.
Výběrem možnosti Vytvořit nové nasazení vytvořte nové nasazení a v rozevíracím seznamu níže přiřaďte natrénovaný model. Existující nasazení můžete také přepsat tak, že vyberete tuto možnost a v rozevíracím seznamu níže vyberete natrénovaný model, který k němu chcete přiřadit.
Poznámka:
Přepsání existujícího nasazení nevyžaduje změny volání rozhraní API pro predikce, ale výsledky, které získáte, budou založené na nově přiřazeného modelu.
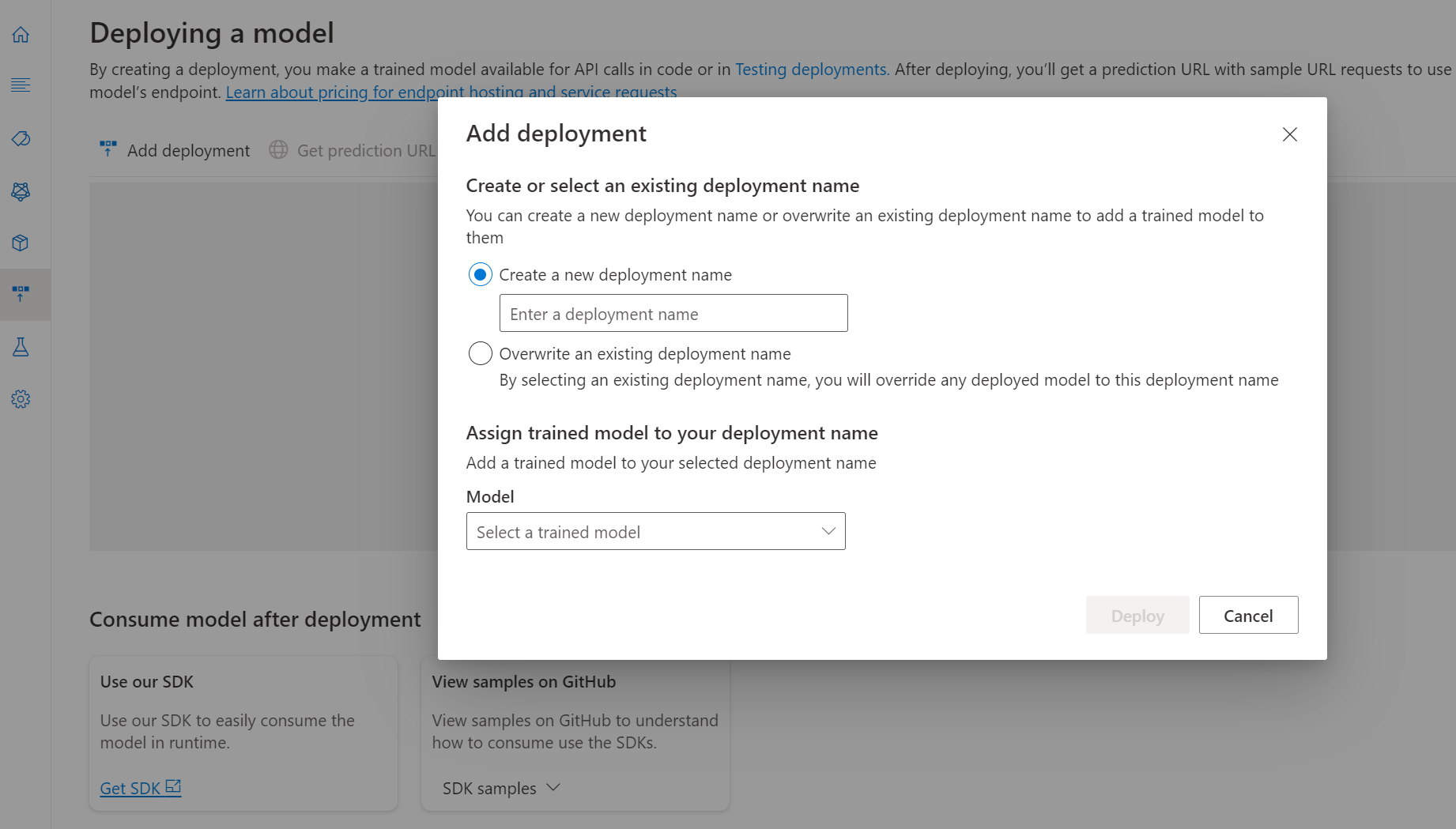
Výběrem možnosti Nasadit spustíte úlohu nasazení.
Po úspěšném nasazení se vedle něj zobrazí datum vypršení platnosti. Vypršení platnosti nasazení je v případě, že nasazený model nebude dostupný pro predikci, což obvykle nastane dvanáct měsíců po vypršení platnosti konfigurace trénování.


Testování modelu
V tomto rychlém startu použijete Language Studio k odeslání vlastní úlohy souhrnu a vizualizaci výsledků. V ukázkové datové sadě, kterou jste si stáhli dříve, najdete některé testovací dokumenty, které můžete použít v tomto kroku.
Testování nasazených modelů v sadě Language Studio:
V nabídce na levé straně vyberte Testovací nasazení .
Vyberte nasazení, které chcete otestovat. Můžete testovat jenom modely, které jsou přiřazené k nasazením.
V případě vícejazyčných projektů v rozevíracím seznamu jazyka vyberte jazyk textu, který testujete.
V rozevíracím seznamu vyberte nasazení, které chcete dotazovat nebo testovat.
Můžete zadat text, který chcete odeslat do žádosti, nebo nahrát
.txtsoubor, který chcete použít.V horní nabídce vyberte Spustit test .
Na kartě Výsledek můžete zobrazit extrahované entity z textu a jejich typů. Odpověď JSON můžete zobrazit také na kartě JSON .

Vyčištění prostředků
Pokud už projekt nepotřebujete, můžete projekt odstranit pomocí sady Language Studio. Vyberte funkci, kterou používáte v horní části, a pak vyberte projekt, který chcete odstranit. V horní nabídce vyberte Odstranit a projekt odstraňte.