Kurz: Použití personalizace v Azure Notebooku
Důležité
Od 20. září 2023 nebudete moct vytvářet nové prostředky personalizace. Služba Personalizace se vyřadí z provozu 1. října 2026.
V tomto kurzu se spustí smyčka Personalizace v poznámkovém bloku Azure, která demonstruje koncový až koncový životní cyklus smyčky Personalizace.
Smyčka naznačuje, jaký typ kávy by si zákazník měl objednat. Uživatelé a jejich předvolby jsou uloženy v datové sadě uživatelů. Informace o kávě jsou uloženy v datové sadě kávy.
Uživatelé a káva
Poznámkový blok, který simuluje interakci uživatele s webem, vybere náhodného uživatele, čas dne a typ počasí z datové sady. Souhrn informací o uživateli:
| Zákazníci – kontextové funkce | Denní časy | Typy počasí |
|---|---|---|
| Alice Robert Cathy Dave |
Ráno Odpoledne Večer |
Slunné Deštivé Zasněžené |
Aby se personalizace v průběhu času naučila, systém také ví podrobnosti o výběru kávy pro každou osobu.
| Káva – akční funkce | Typy teploty | Místa původu | Typy pražení | Organické |
|---|---|---|---|---|
| Cappacino | Značný zájem | Keňa | Tmavý | Organické |
| Studené vaření | Bez zájmu | Brazílie | Světlý | Organické |
| Iced mocha | Bez zájmu | Etiopie | Světlý | Ne organické |
| Latte | Značný zájem | Brazílie | Tmavý | Ne organické |
Účelem smyčky Personalizace je najít nejlepší shodu mezi uživateli a kávou co nejvíce času.
Kód pro tento kurz je k dispozici v úložišti Personalizace ukázek Na GitHubu.
Jak simulace funguje
Na začátku spuštěného systému jsou návrhy z personalizace úspěšné pouze mezi 20 % až 30 %. Tento úspěch označuje odměna odeslaná zpět do rozhraní API personalizace odměny se skóre 1. Po několika voláních Rank a Rewards se systém zlepší.
Po počátečních požadavcích spusťte offline vyhodnocení. To umožňuje personalizaci kontrolovat data a navrhovat lepší zásady učení. Použijte nové zásady výuky a spusťte poznámkový blok znovu s 20 % z předchozího počtu požadavků. Smyčka bude s novou zásadou výuky fungovat lépe.
Rank and rewards calls
Pro každou z několika tisíc volání do služby Personalizace odešle Azure Notebook požadavek na pořadí do rozhraní REST API:
- Jedinečné ID události Rank/Request
- Kontextové funkce – náhodný výběr uživatele, počasí a denní čas – simulace uživatele na webu nebo mobilním zařízení
- Akce s funkcemi – Všechna data kávy – ze kterých personalizace navrhuje návrh
Systém obdrží požadavek a pak porovná předpověď se známou volbou uživatele pro stejnou denní dobu a počasí. Pokud je známá volba stejná jako předpovězená volba, pošle se odměna 1 zpět do personalizace. Jinak je odměna odeslaná zpět 0.
Poznámka:
Jedná se o simulaci, takže algoritmus odměny je jednoduchý. V reálném scénáři by měl algoritmus použít obchodní logiku, případně s váhami pro různé aspekty zkušeností zákazníka, aby určil skóre odměny.
Předpoklady
- Účet Azure Notebook.
- Prostředek Personalizace Azure AI
- Pokud jste už použili prostředek Personalizace, nezapomeňte vymazat data na webu Azure Portal pro daný prostředek.
- Nahrajte všechny soubory pro tuto ukázku do projektu Azure Notebook.
Popisy souborů:
- Personalizace.ipynb je poznámkový blok Jupyter pro účely tohoto kurzu.
- Uživatelská datová sada je uložená v objektu JSON.
- Datová sada kávy je uložená v objektu JSON.
- Ukázkový formát JSON požadavku je očekávaný formát požadavku POST na rozhraní Rank API.
Konfigurace prostředku Personalizace
Na webu Azure Portal nakonfigurujte prostředek Personalizace s frekvencí aktualizačního modelu nastaveným na 15 sekund a dobu čekání na odměnu 10 minut. Tyto hodnoty najdete na stránce Konfigurace.
| Nastavení | Hodnota |
|---|---|
| frekvence aktualizace modelu | 15 sekund |
| doba čekání na odměnu | 10 minut |
Tyto hodnoty mají velmi krátkou dobu trvání, aby bylo možné zobrazit změny v tomto kurzu. Tyto hodnoty by se neměly používat v produkčním scénáři, aniž by bylo možné je ověřovat pomocí smyčky Personalizace.
Nastavení poznámkového bloku Azure
- Změňte jádro na
Python 3.6. - Otevřete soubor
Personalizer.ipynb.
Spuštění buněk poznámkového bloku
Spusťte každou spustitelné buňku a počkejte, až se vrátí. Víte, že je hotovo, když hranaté závorky vedle buňky zobrazí číslo místo *. Následující části popisují, co každá buňka dělá programově a co očekávat pro výstup.
Zahrnutí modulů Pythonu
Zahrňte požadované moduly Pythonu. Buňka nemá žádný výstup.
import json
import matplotlib.pyplot as plt
import random
import requests
import time
import uuid
Nastavení klíče a názvu prostředku Personalizace
Na webu Azure Portal najděte svůj klíč a koncový bod na stránce Rychlý start prostředku Personalizace. Změňte hodnotu <your-resource-name> na název prostředku Personalizace. Změňte hodnotu <your-resource-key> na klíč Personalizace.
# Replace 'personalization_base_url' and 'resource_key' with your valid endpoint values.
personalization_base_url = "https://<your-resource-name>.cognitiveservices.azure.com/"
resource_key = "<your-resource-key>"
Tisk aktuálního data a času
Tato funkce slouží k zaznamenávání počátečních a koncových časů iterativní funkce a iterací.
Tyto buňky nemají žádný výstup. Funkce vypíše aktuální datum a čas při zavolání.
# Print out current datetime
def currentDateTime():
currentDT = datetime.datetime.now()
print (str(currentDT))
Získání času poslední aktualizace modelu
Při zavolání funkce get_last_updatedvypíše datum a čas poslední změny, které model aktualizoval.
Tyto buňky nemají žádný výstup. Funkce vypíše datum posledního trénování modelu při zavolání.
Funkce k získání vlastností modelu používá rozhraní GET REST API.
# ititialize variable for model's last modified date
modelLastModified = ""
def get_last_updated(currentModifiedDate):
print('-----checking model')
# get model properties
response = requests.get(personalization_model_properties_url, headers = headers, params = None)
print(response)
print(response.json())
# get lastModifiedTime
lastModifiedTime = json.dumps(response.json()["lastModifiedTime"])
if (currentModifiedDate != lastModifiedTime):
currentModifiedDate = lastModifiedTime
print(f'-----model updated: {lastModifiedTime}')
Získání konfigurace zásad a služeb
Pomocí těchto dvou volání REST ověřte stav služby.
Tyto buňky nemají žádný výstup. Funkce při zavolání vypíše hodnoty služby.
def get_service_settings():
print('-----checking service settings')
# get learning policy
response = requests.get(personalization_model_policy_url, headers = headers, params = None)
print(response)
print(response.json())
# get service settings
response = requests.get(personalization_service_configuration_url, headers = headers, params = None)
print(response)
print(response.json())
Vytváření adres URL a čtení datových souborů JSON
Tato buňka
- sestaví adresy URL použité ve voláníCH REST.
- Nastaví hlavičku zabezpečení pomocí klíče prostředku Personalizace.
- nastaví náhodné počáteční hodnoty pro ID události pořadí.
- přečte v datových souborech JSON.
- metoda volání
get_last_updated– v příkladu výstupu se odebraly zásady učení. - metoda volání
get_service_settings
Buňka obsahuje výstup z volání get_last_updated a get_service_settings funkcí.
# build URLs
personalization_rank_url = personalization_base_url + "personalizer/v1.0/rank"
personalization_reward_url = personalization_base_url + "personalizer/v1.0/events/" #add "{eventId}/reward"
personalization_model_properties_url = personalization_base_url + "personalizer/v1.0/model/properties"
personalization_model_policy_url = personalization_base_url + "personalizer/v1.0/configurations/policy"
personalization_service_configuration_url = personalization_base_url + "personalizer/v1.0/configurations/service"
headers = {'Ocp-Apim-Subscription-Key' : resource_key, 'Content-Type': 'application/json'}
# context
users = "users.json"
# action features
coffee = "coffee.json"
# empty JSON for Rank request
requestpath = "example-rankrequest.json"
# initialize random
random.seed(time.time())
userpref = None
rankactionsjsonobj = None
actionfeaturesobj = None
with open(users) as handle:
userpref = json.loads(handle.read())
with open(coffee) as handle:
actionfeaturesobj = json.loads(handle.read())
with open(requestpath) as handle:
rankactionsjsonobj = json.loads(handle.read())
get_last_updated(modelLastModified)
get_service_settings()
print(f'User count {len(userpref)}')
print(f'Coffee count {len(actionfeaturesobj)}')
Ověřte, že je výstup rewardWaitTime nastavený na 10 minut a modelExportFrequency je nastavený na 15 sekund.
-----checking model
<Response [200]>
{'creationTime': '0001-01-01T00:00:00+00:00', 'lastModifiedTime': '0001-01-01T00:00:00+00:00'}
-----model updated: "0001-01-01T00:00:00+00:00"
-----checking service settings
<Response [200]>
{...learning policy...}
<Response [200]>
{'rewardWaitTime': '00:10:00', 'defaultReward': 0.0, 'rewardAggregation': 'earliest', 'explorationPercentage': 0.2, 'modelExportFrequency': '00:00:15', 'logRetentionDays': -1}
User count 4
Coffee count 4
Řešení potíží s prvním voláním REST
Tato předchozí buňka je první buňka, která volá personalizaci. Ujistěte se, že je ve výstupu <Response [200]>stavový kód REST . Pokud se zobrazí chyba, například 404, ale jste si jistí, že máte správný klíč prostředku a název, znovu načtěte poznámkový blok.
Ujistěte se, že počet kávy a uživatelů je 4. Pokud se zobrazí chyba, zkontrolujte, že jste nahráli všechny 3 soubory JSON.
Nastavení grafu metrik na webu Azure Portal
V pozdější části tohoto kurzu je dlouhotrvající proces 10 000 požadavků viditelný z prohlížeče s aktualizací textového pole. V grafu nebo jako celkový součet může být přehlednější, když dlouho běžící proces skončí. K zobrazení těchto informací použijte metriky poskytnuté s prostředkem. Graf teď můžete vytvořit, když jste dokončili požadavek na službu, a pak graf pravidelně aktualizovat během dlouhotrvajícího procesu.
Na webu Azure Portal vyberte prostředek Personalizace.
V navigaci prostředků vyberte metriky pod monitorováním.
V grafu vyberte Přidat metriku.
Obor názvů prostředků a metrik je již nastavený. Stačí vybrat metriku úspěšných volání a agregaci součtu.
Změňte filtr času na posledních 4 hodin.
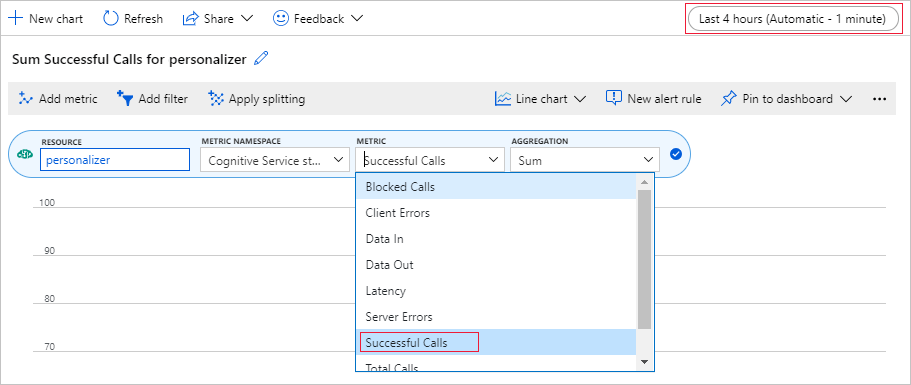
V grafu by se měla zobrazit tři úspěšná volání.
Vygenerování jedinečného ID události
Tato funkce vygeneruje jedinečné ID pro každé volání pořadí. ID slouží k identifikaci informací o pořadí a odměně. Tato hodnota může pocházet z obchodního procesu, jako je ID webového zobrazení nebo ID transakce.
Buňka nemá žádný výstup. Funkce vypíše jedinečné ID při zavolání.
def add_event_id(rankjsonobj):
eventid = uuid.uuid4().hex
rankjsonobj["eventId"] = eventid
return eventid
Získání náhodného uživatele, počasí a času dne
Tato funkce vybere jedinečného uživatele, počasí a denní dobu a pak tyto položky přidá do objektu JSON, který se odešle do požadavku pořadí.
Buňka nemá žádný výstup. Při zavolání funkce vrátí jméno náhodného uživatele, náhodné počasí a náhodný čas dne.
Seznam 4uživatelůch
{
"Alice": {
"Sunny": {
"Morning": "Cold brew",
"Afternoon": "Iced mocha",
"Evening": "Cold brew"
}...
},
"Bob": {
"Sunny": {
"Morning": "Cappucino",
"Afternoon": "Iced mocha",
"Evening": "Cold brew"
}...
},
"Cathy": {
"Sunny": {
"Morning": "Latte",
"Afternoon": "Cold brew",
"Evening": "Cappucino"
}...
},
"Dave": {
"Sunny": {
"Morning": "Iced mocha",
"Afternoon": "Iced mocha",
"Evening": "Iced mocha"
}...
}
}
def add_random_user_and_contextfeatures(namesoption, weatheropt, timeofdayopt, rankjsonobj):
name = namesoption[random.randint(0,3)]
weather = weatheropt[random.randint(0,2)]
timeofday = timeofdayopt[random.randint(0,2)]
rankjsonobj['contextFeatures'] = [{'timeofday': timeofday, 'weather': weather, 'name': name}]
return [name, weather, timeofday]
Přidání všech dat kávy
Tato funkce přidá do objektu JSON celý seznam kávy, který se má odeslat do požadavku pořadí.
Buňka nemá žádný výstup. Funkce změní rankjsonobj při zavolání.
Příkladem funkcí jedné kávy je:
{
"id": "Cappucino",
"features": [
{
"type": "hot",
"origin": "kenya",
"organic": "yes",
"roast": "dark"
}
}
def add_action_features(rankjsonobj):
rankjsonobj["actions"] = actionfeaturesobj
Porovnání predikce se známými předvolbami uživatele
Tato funkce se volá po volání rozhraní Rank API pro každou iteraci.
Tato funkce porovnává předvolby uživatele pro kávu na základě počasí a času dne s návrhem personalizace pro uživatele pro tyto filtry. Pokud se návrh shoduje, vrátí se skóre 1, jinak je skóre 0. Buňka nemá žádný výstup. Funkce vypíše skóre při zavolání.
def get_reward_from_simulated_data(name, weather, timeofday, prediction):
if(userpref[name][weather][timeofday] == str(prediction)):
return 1
return 0
Promyčkáme volání do pořadí a odměny.
Další buňka je hlavní prací poznámkového bloku, získání náhodného uživatele, získání seznamu kávy a odesílání obou do rozhraní Rank API. Porovnávání předpovědi se známými předvolbami uživatele a následné odeslání odměny zpět do služby Personalizace.
Smyčka se spustí pro num_requests časy. Personalizace potřebuje k vytvoření modelu několik tisíc volání do pořadí a odměny.
Následuje příklad kódu JSON odeslaného do rozhraní Rank API. Seznam kávy není úplný, aby byl stručný. Celý kód JSON pro kávu si můžete prohlédnout v coffee.jsonsouboru .
JSON odeslaný do rozhraní Rank API:
{
'contextFeatures':[
{
'timeofday':'Evening',
'weather':'Snowy',
'name':'Alice'
}
],
'actions':[
{
'id':'Cappucino',
'features':[
{
'type':'hot',
'origin':'kenya',
'organic':'yes',
'roast':'dark'
}
]
}
...rest of coffee list
],
'excludedActions':[
],
'eventId':'b5c4ef3e8c434f358382b04be8963f62',
'deferActivation':False
}
Odpověď JSON z rozhraní Rank API:
{
'ranking': [
{'id': 'Latte', 'probability': 0.85 },
{'id': 'Iced mocha', 'probability': 0.05 },
{'id': 'Cappucino', 'probability': 0.05 },
{'id': 'Cold brew', 'probability': 0.05 }
],
'eventId': '5001bcfe3bb542a1a238e6d18d57f2d2',
'rewardActionId': 'Latte'
}
Nakonec každá smyčka zobrazuje náhodný výběr uživatele, počasí, denní čas a určenou odměnu. Odměna 1 označuje zdroj personalizace vybraný správný typ kávy pro daného uživatele, počasí a denní dobu.
1 Alice Rainy Morning Latte 1
Funkce používá:
- Pořadí: POST REST API pro získání pořadí.
- Odměna: rozhraní POST REST API k hlášení odměny.
def iterations(n, modelCheck, jsonFormat):
i = 1
# default reward value - assumes failed prediction
reward = 0
# Print out dateTime
currentDateTime()
# collect results to aggregate in graph
total = 0
rewards = []
count = []
# default list of user, weather, time of day
namesopt = ['Alice', 'Bob', 'Cathy', 'Dave']
weatheropt = ['Sunny', 'Rainy', 'Snowy']
timeofdayopt = ['Morning', 'Afternoon', 'Evening']
while(i <= n):
# create unique id to associate with an event
eventid = add_event_id(jsonFormat)
# generate a random sample
[name, weather, timeofday] = add_random_user_and_contextfeatures(namesopt, weatheropt, timeofdayopt, jsonFormat)
# add action features to rank
add_action_features(jsonFormat)
# show JSON to send to Rank
print('To: ', jsonFormat)
# choose an action - get prediction from Personalizer
response = requests.post(personalization_rank_url, headers = headers, params = None, json = jsonFormat)
# show Rank prediction
print ('From: ',response.json())
# compare personalization service recommendation with the simulated data to generate a reward value
prediction = json.dumps(response.json()["rewardActionId"]).replace('"','')
reward = get_reward_from_simulated_data(name, weather, timeofday, prediction)
# show result for iteration
print(f' {i} {currentDateTime()} {name} {weather} {timeofday} {prediction} {reward}')
# send the reward to the service
response = requests.post(personalization_reward_url + eventid + "/reward", headers = headers, params= None, json = { "value" : reward })
# for every N rank requests, compute total correct total
total = total + reward
# every N iteration, get last updated model date and time
if(i % modelCheck == 0):
print("**** 10% of loop found")
get_last_updated(modelLastModified)
# aggregate so chart is easier to read
if(i % 10 == 0):
rewards.append( total)
count.append(i)
total = 0
i = i + 1
# Print out dateTime
currentDateTime()
return [count, rewards]
Spuštění pro 10 000 iterací
Spusťte smyčku Personalizace pro 10 000 iterací. Jedná se o dlouho běžící událost. Nezavírejte prohlížeč, na kterém je poznámkový blok spuštěný. Aktualizujte graf metrik na webu Azure Portal pravidelně, abyste viděli celkový počet volání služby. Když máte přibližně 20 000 volání, provede se iterace pořadí a odměna pro každou iteraci smyčky.
# max iterations
num_requests = 200
# check last mod date N% of time - currently 10%
lastModCheck = int(num_requests * .10)
jsonTemplate = rankactionsjsonobj
# main iterations
[count, rewards] = iterations(num_requests, lastModCheck, jsonTemplate)
Výsledky grafu pro zobrazení vylepšení
Vytvoření grafu z a countrewards.
def createChart(x, y):
plt.plot(x, y)
plt.xlabel("Batch of rank events")
plt.ylabel("Correct recommendations per batch")
plt.show()
Spuštění grafu pro 10 000 žádostí o pořadí
createChart Spusťte funkci.
createChart(count,rewards)
Čtení grafu
Tento graf ukazuje úspěch modelu pro aktuální výchozí zásady výuky.
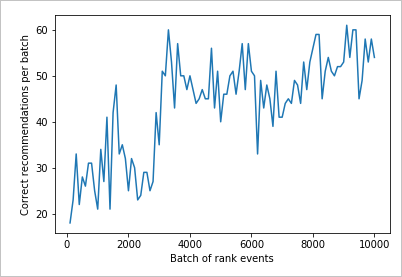
Ideální cíl, který je na konci testu, je smyčka průměrem úspěšnosti, která je téměř 100 % minus průzkum. Výchozí hodnota průzkumu je 20 %.
100-20=80
Tato hodnota zkoumání se nachází na webu Azure Portal pro prostředek Personalizace na stránce Konfigurace .
Pokud chcete najít lepší zásady učení na základě vašich dat do rozhraní Rank API, spusťte na portálu offline vyhodnocení smyčky Personalizace.
Spuštění offline vyhodnocení
Na webu Azure Portal otevřete stránku Vyhodnocení prostředku Personalizace.
Vyberte Vytvořit vyhodnocení.
Zadejte požadovaná data názvu vyhodnocení a rozsah dat pro vyhodnocení smyčky. Rozsah kalendářních dat by měl obsahovat jenom dny, na které se zaměřujete na vyhodnocení.
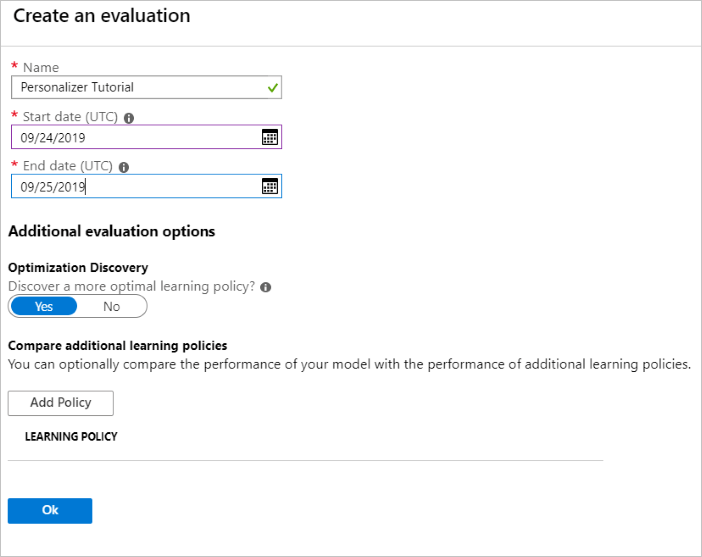
Účelem spuštění tohoto offline vyhodnocení je určit, jestli existují lepší zásady výuky pro funkce a akce použité v této smyčce. Pokud chcete najít lepší zásady výuky, ujistěte se, že je zapnuté zjišťování optimalizace.
Pokud chcete zahájit vyhodnocení, vyberte OK .
Tato stránka Vyhodnocení uvádí nové vyhodnocení a aktuální stav. V závislosti na tom, kolik dat máte, může toto vyhodnocení nějakou dobu trvat. Po několika minutách se můžete vrátit na tuto stránku a podívat se na výsledky.
Po dokončení vyhodnocení vyberte vyhodnocení a pak vyberte Porovnání různých zásad výuky. Zobrazí se dostupné zásady výuky a jejich chování s daty.
Vyberte nejdůležitější zásady výuky v tabulce a vyberte Použít. Tím se uplatní nejlepší zásady výuky pro váš model a přetrénování.
Změna frekvence aktualizace modelu na 5 minut
- Na webu Azure Portal stále na prostředku Personalizace vyberte stránku Konfigurace .
- Změňte frekvenci aktualizace modelu a dobu čekání na odměnu na 5 minut a vyberte Uložit.
Přečtěte si další informace o době čekání na odměnu a frekvenci aktualizace modelu.
#Verify new learning policy and times
get_service_settings()
Ověřte, že výstup rewardWaitTime je nastavený na modelExportFrequency 5 minut.
-----checking model
<Response [200]>
{'creationTime': '0001-01-01T00:00:00+00:00', 'lastModifiedTime': '0001-01-01T00:00:00+00:00'}
-----model updated: "0001-01-01T00:00:00+00:00"
-----checking service settings
<Response [200]>
{...learning policy...}
<Response [200]>
{'rewardWaitTime': '00:05:00', 'defaultReward': 0.0, 'rewardAggregation': 'earliest', 'explorationPercentage': 0.2, 'modelExportFrequency': '00:05:00', 'logRetentionDays': -1}
User count 4
Coffee count 4
Ověření nových zásad výuky
Vraťte se do souboru Azure Notebooks a pokračujte spuštěním stejné smyčky, ale pouze pro 2 000 iterací. Aktualizujte graf metrik na webu Azure Portal pravidelně, abyste viděli celkový počet volání služby. Pokud máte přibližně 4 000 volání, pořadí a odměna volání pro každou iteraci smyčky, iterace se provádějí.
# max iterations
num_requests = 2000
# check last mod date N% of time - currently 10%
lastModCheck2 = int(num_requests * .10)
jsonTemplate2 = rankactionsjsonobj
# main iterations
[count2, rewards2] = iterations(num_requests, lastModCheck2, jsonTemplate)
Spuštění grafu pro 2 000 žádostí o pořadí
createChart Spusťte funkci.
createChart(count2,rewards2)
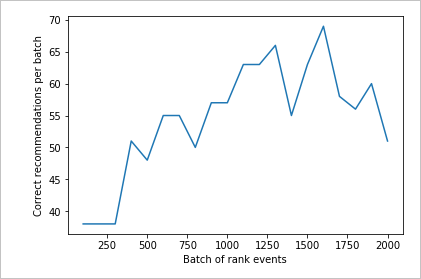
Kontrola druhého grafu
Druhý graf by měl zobrazit viditelný nárůst předpovědí pořadí, které odpovídají uživatelským předvolbám.
Vyčištění prostředků
Pokud nemáte v úmyslu pokračovat v sérii kurzů, vyčistěte následující zdroje informací:
- Odstraňte projekt Azure Notebook.
- Odstraňte prostředek Personalizace.
Další kroky
Poznámkový blok Jupyter a datové soubory použité v této ukázce jsou k dispozici v úložišti GitHubu pro personalizaci.