Trénování vlastního modelu
Model poskytuje překlady pro konkrétní jazykovou dvojici. Výsledkem úspěšného trénování je model. K trénování vlastního modelu se vyžadují tři vzájemně se vylučující typy dokumentů: trénování, ladění a testování. Pokud jsou při řazení trénování do fronty k dispozici pouze trénovací data, Custom Translator automaticky sestaví data pro ladění a testování. Použije náhodnou podmnožinu vět z trénovacích dokumentů a vyloučí tyto věty ze samotných trénovacích dat. K trénování úplného modelu se vyžaduje minimálně 10 000 paralelních trénovacích vět.
Vytvoření modelu
Vyberte okno Trénování modelu .
Zadejte název modelu.
Nechte vybranou výchozí možnost Úplné trénování nebo vyberte Trénování jen pro slovník.
Poznámka
Úplné trénování zobrazí všechny nahrané typy dokumentů. Pouze slovník zobrazuje pouze dokumenty slovníku.
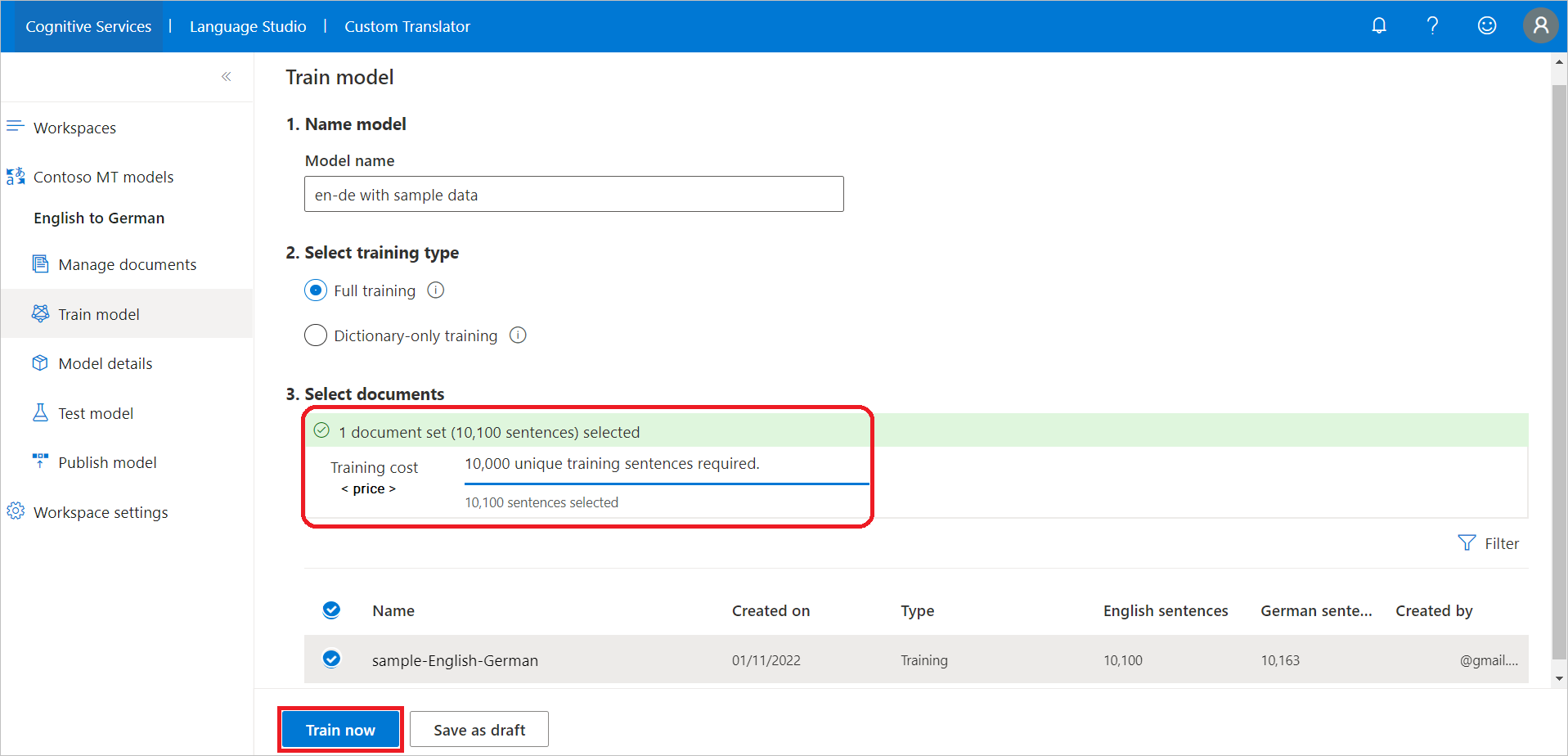
V části Vybrat dokumenty vyberte například dokumenty, které chcete použít k trénování modelu,
sample-English-Germana zkontrolujte náklady na trénování spojené s vybraným počtem vět.Vyberte Trénovat.
Potvrďte ho výběrem možnosti Train (Trénovat ).
Poznámka
Oznámení zobrazují probíhající trénování modelu, například odeslání stavu dat . Trénovací model trvá několik hodin a závisí na počtu vybraných vět.
Kdy vybrat trénování jen pro slovník
Pro dosažení lepších výsledků doporučujeme nechat systém učit se z tréninkových dat. Pokud však nemáte dostatek paralelních vět ke splnění minimálních požadavků 10 000 nebo věty a složená podstatná jména musí být vykreslena tak, jak jsou, použijte trénování pouze pro slovník. Model obvykle dokončí trénování mnohem rychleji než v případě úplného trénováním. Výsledné modely použijí základní modely pro překlad spolu se slovníky, které jste přidali. Nezobrazí se skóre BLEU ani nedostanete sestavu testu.
Poznámka
Custom Translator nepáruje slovníkové soubory po větách. Proto je důležité, aby ve slovníkových dokumentech byl stejný počet zdrojových a cílových frází/vět a aby si přesně odpovídaly. Pokud tomu tak není, nahrávání dokumentů se nezdaří.
Podrobnosti o modelu
Po úspěšném trénování modelu vyberte okno Podrobnosti modelu .
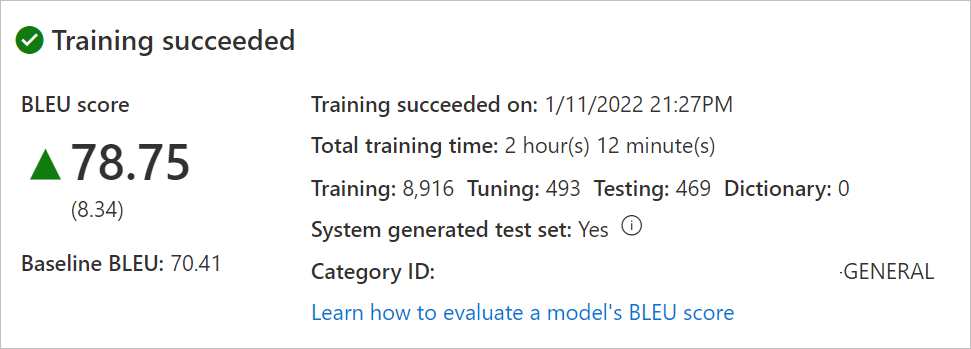
Vyberte Název modelu a zkontrolujte datum a čas trénování, celkovou dobu trénování, počet vět použitých pro trénování, ladění, testování, slovník a to, jestli systém vygeneroval testovací a ladicí sady. Použijete
Category IDk vytváření žádostí o překlad.Vyhodnoťte skóre BLEU modelu. Zkontrolujte testovací sadu: skóre BLEU je skóre vlastního modelu a BLEU směrného plánu je předem natrénovaný model směrného plánu, který se používá k přizpůsobení. Vyšší skóre BLEU znamená vyšší kvalitu překladu pomocí vlastního modelu.
Duplicitní model
Vyberte okno Podrobnosti modelu .
Najeďte myší na název modelu a zaškrtněte tlačítko pro výběr.
Vyberte Duplikovat.
Vyplňte Název nového modelu.
Pokud nebudou vybrána nebo nahrána žádná další data, ponechte možnost Train okamžitě zaškrtnutou. V opačném případě zaškrtněte políčko Uložit jako koncept.
Vyberte Uložit.
Poznámka
Pokud model uložíte jako
Draft, podrobnosti o modelu se aktualizují o název modelu veDraftstavu.Pokud chcete přidat další dokumenty, vyberte název modelu a postupujte podle výše uvedené
Create modelčásti.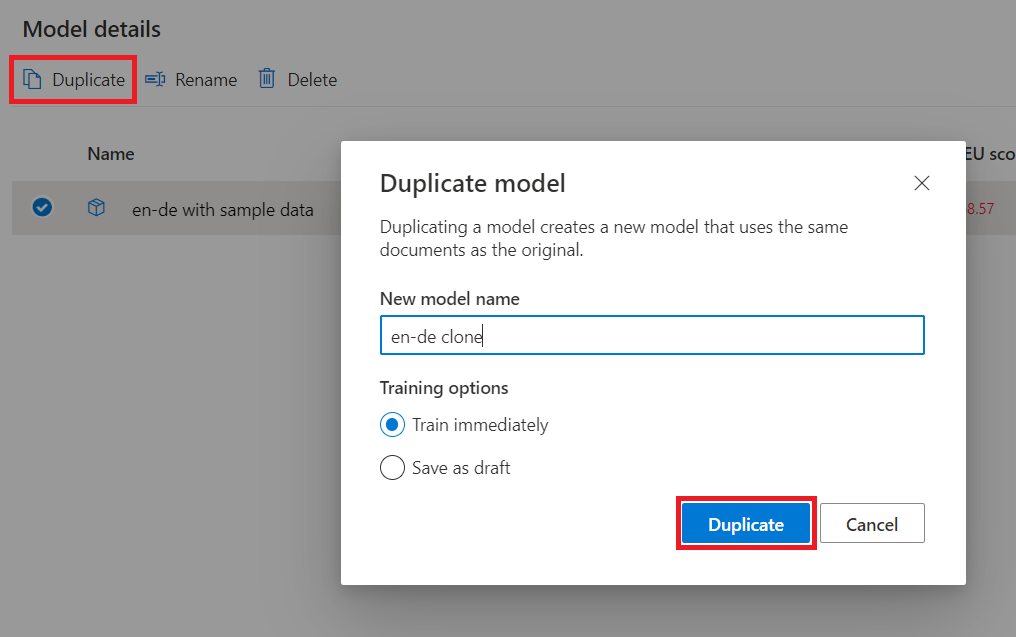
Další kroky
- Naučte se testovat a vyhodnocovat kvalitu modelu.
- Zjistěte , jak publikovat model.
- Naučte se překládat pomocí vlastních modelů.