Filtrování obsahu v Azure AI Studiu
Důležité
Některé funkce popsané v tomto článku můžou být dostupné jenom ve verzi Preview. Tato verze Preview je poskytována bez smlouvy o úrovni služeb a nedoporučujeme ji pro produkční úlohy. Některé funkce se nemusí podporovat nebo mohou mít omezené možnosti. Další informace najdete v dodatečných podmínkách použití pro verze Preview v Microsoft Azure.
Azure AI Studio obsahuje systém filtrování obsahu, který funguje společně s základními modely a modely generování imagí DALL-E.
Důležité
Systém filtrování obsahu se nepoužije na prompty a dokončená zadání zpracovávané modelem Whisper ve službě Azure OpenAI. Přečtěte si další informace o modelu Whisper v Azure OpenAI.
Jak to funguje
Tento systém filtrování obsahu využívá Azure AI Content Safety a funguje spuštěním výstupu příkazového vstupu i dokončení prostřednictvím souboru klasifikačních modelů určených k detekci a zabránění výstupu škodlivého obsahu. Varianty konfigurací rozhraní API a návrhu aplikací můžou mít vliv na dokončená zadání a filtrování chování.
S nasazeními modelů Azure OpenAI můžete použít výchozí filtr obsahu nebo vytvořit vlastní filtr obsahu (popsaný dále). Výchozí filtr obsahu je také k dispozici pro další textové modely kurátorované službou Azure AI v katalogu modelů, ale vlastní filtry obsahu zatím nejsou pro tyto modely dostupné. Modely dostupné prostřednictvím modelů jako služba mají ve výchozím nastavení povolené filtrování obsahu a není možné je nakonfigurovat.
Podpora jazyků
Modely filtrování obsahu byly natrénovány a testovány v následujících jazycích: angličtina, němčina, japonština, španělština, francouzština, italština, portugalština a čínština. Služba ale může fungovat v mnoha dalších jazycích, ale kvalita se může lišit. Ve všech případech byste měli provést vlastní testování, abyste se ujistili, že to pro vaši aplikaci funguje.
Vytvoření filtru obsahu
Pro jakékoli nasazení modelu v Azure AI Studiu můžete přímo použít výchozí filtr obsahu, ale možná budete chtít mít větší kontrolu. Můžete například nastavit přísnější nebo lenientnější filtr nebo povolit pokročilejší funkce, jako jsou stínění výzvy a detekce chráněných materiálů.
Pokud chcete vytvořit filtr obsahu, postupujte takto:
Přejděte do AI Studia a přejděte do centra. Pak v levém navigačním panelu vyberte kartu Filtry obsahu a vyberte tlačítko Vytvořit filtr obsahu.

Na stránce Základní informace zadejte název filtru obsahu. Vyberte připojení, které chcete přidružit k filtru obsahu. Pak vyberte Další.

Na stránce Vstupní filtry můžete nastavit filtr pro vstupní výzvu. Nastavte prahovou hodnotu úrovně akce a závažnosti pro každý typ filtru. Na této stránce nakonfigurujete jak výchozí filtry, tak i další filtry (například Prompt Shields for jailbreak attacks). Pak vyberte Další.

Obsah se označí podle kategorie a zablokuje se podle nastavené prahové hodnoty. U kategorií násilí, nenávisti, sexuálního a sebepoškozování upravte posuvník tak, aby blokoval obsah vysoké, střední nebo nízké závažnosti.
Na stránce Výstupní filtry můžete nakonfigurovat výstupní filtr, který se použije pro veškerý výstupní obsah vygenerovaný vaším modelem. Nakonfigurujte jednotlivé filtry jako předtím. Tato stránka také poskytuje možnost režimu streamování, která umožňuje filtrovat obsah téměř v reálném čase, protože je generován modelem, což snižuje latenci. Až budete hotovi, vyberte Další.
Obsah bude anotován jednotlivými kategoriemi a zablokován podle prahové hodnoty. U násilného obsahu, obsahu nenávisti, sexuálního obsahu a kategorie obsahu sebepoškozování upravte prahovou hodnotu pro blokování škodlivého obsahu se stejnou nebo vyšší úrovní závažnosti.
Volitelně můžete na stránce Nasazení přidružit filtr obsahu k nasazení. Pokud už vybrané nasazení obsahuje připojený filtr, musíte potvrdit, že ho chcete nahradit. Filtr obsahu můžete také přidružit k nasazení později. Vyberte Vytvořit.

Konfigurace filtrování obsahu se vytvářejí na úrovni centra v AI Studiu. Další informace o konfigurovatelnosti najdete v dokumentaci k Azure OpenAI.
Na stránce Revize zkontrolujte nastavení a pak vyberte Vytvořit filtr.




Použití seznamu blokovaných položek jako filtru
Seznam blokovaných položek můžete použít buď jako vstupní nebo výstupní filtr, nebo obojí. Povolte možnost Blocklist na stránce vstupního filtru nebo výstupního filtru. V rozevíracím seznamu vyberte jeden nebo více seznamů blokovaných položek nebo použijte integrovaný seznam blokovaných vulgárních výrazů. Do stejného filtru můžete zkombinovat více seznamů blokovaných položek.
Použití filtru obsahu
Proces vytváření filtru umožňuje použít filtr na požadovaná nasazení. Filtry obsahu můžete také kdykoli změnit nebo odebrat z nasazení.
Pokud chcete použít filtr obsahu pro nasazení, postupujte takto:
Přejděte do AI Studia a vyberte projekt.
Vyberte Nasazení a zvolte jedno z vašich nasazení a pak vyberte Upravit.
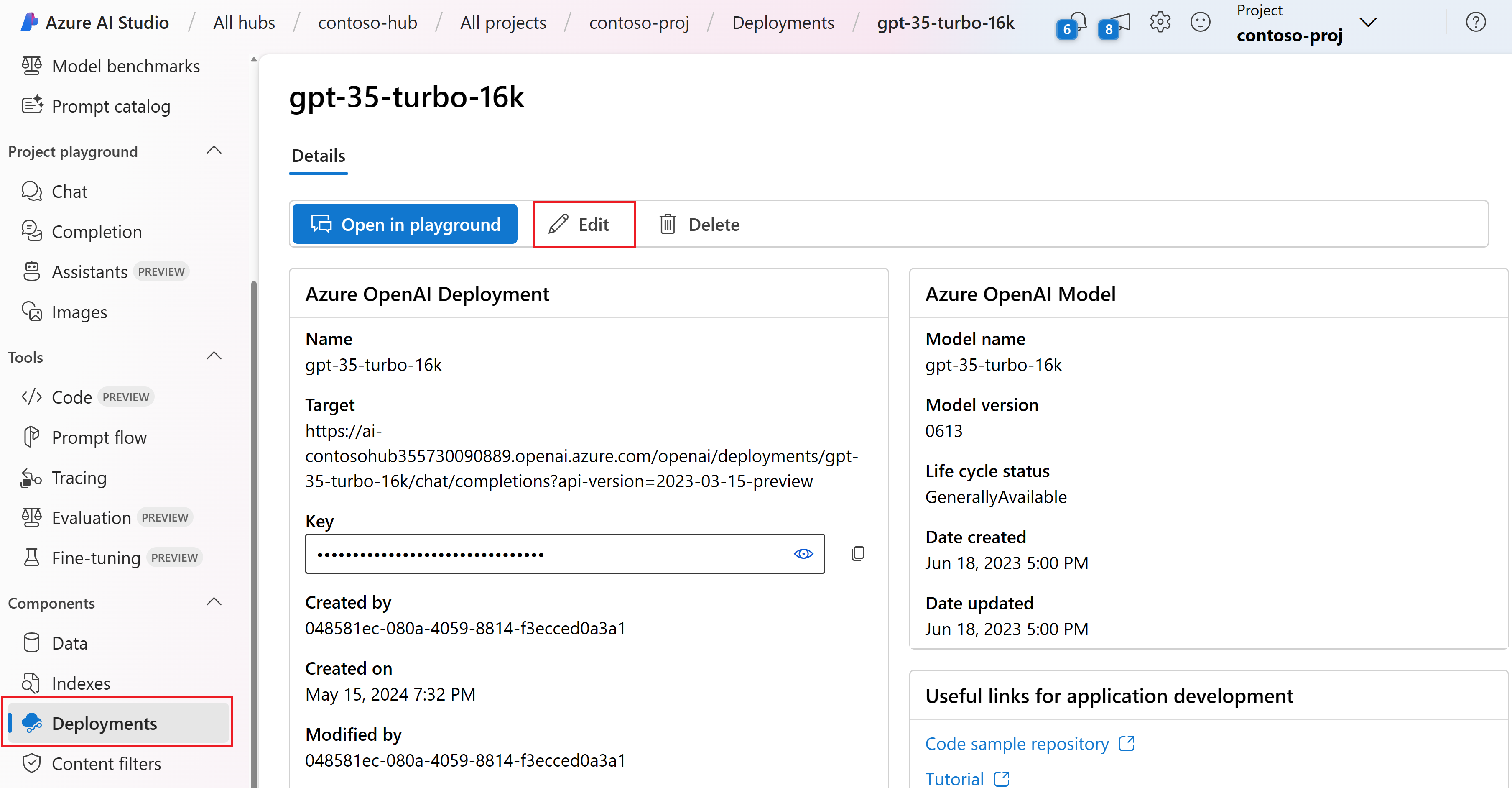
V okně nasazení aktualizace vyberte filtr obsahu, který chcete použít pro nasazení.



Teď můžete přejít na dětské hřiště a otestovat, jestli filtr obsahu funguje podle očekávání.
Kategorie
| Kategorie | Popis |
|---|---|
| Nenávist | Kategorie nenávisti popisuje jazykové útoky nebo použití, které zahrnují pejorativní nebo nediskriminační jazyk s odkazem na osobu nebo skupinu identit na základě určitých různých atributů těchto skupin, včetně rasy, etnického původu, státní příslušnosti, genderové identity a výrazu, sexuální orientace, náboženství, přistěhovalectví, stavu schopnosti, osobního vzhledu a velikosti těla. |
| Sexuální | Sexuální kategorie popisuje jazyk související s anatomickými orgány a pohlavními orgány, romantickými vztahy, působí v erotických nebo laskavých termínech, fyzické sexuální činy, včetně těch, které jsou znázorněny jako útok nebo vynucený sexuální násilí proti willu, prostituci, pornografii a zneužívání. |
| Násilí | Kategorie násilí popisuje jazyk související s fyzickými činy, které mají ublížit, poškodit, poškodit nebo zabít někoho nebo něco; popisuje zbraně atd. |
| Sebepoškozování | Kategorie sebepoškozování popisuje jazyk související s fyzickými akcemi, jejichž účelem je úmyslně ublížit, poškodit nebo poškodit tělo nebo zabít sebe. |
Úrovně závažnosti
| Kategorie | Popis |
|---|---|
| Safe | Obsah může souviset s násilím, sebepoškozováním, sexuálním nebo nenávistným kategoriím, ale termíny se používají obecně, novináři, vědecké, lékařské a podobné profesionální kontexty, které jsou vhodné pro většinu cílových skupin. |
| Nízká | Obsah, který vyjadřuje dotčená, úsudek nebo názorná stanoviska, zahrnuje urážlivé použití jazyka, stereotypu, případy použití zkoumání fiktivního světa (například hry, literatury) a znázornění s nízkou intenzitou. |
| Střední | Obsah, který používá urážlivé, urážlivé, posměšné, zastrašující nebo demeaning jazyka na konkrétní skupiny identit, zahrnuje znázornění hledání a provádění škodlivých instrukcí, fantazí, glorifikace, propagaci škod ve střední intenzitě. |
| Vysoká | Obsah, který zobrazuje explicitní a závažné škodlivé instrukce, akce, poškození nebo zneužití; zahrnuje doporučení, glorifikace nebo propagaci závažných škodlivých činů, extrémních nebo nelegálních forem škod, radikalizace nebo nekonsensuální výměny moci nebo zneužití. |
Konfigurovatelnost (Preview)
Výchozí konfigurace filtrování obsahu pro řadu modelů GPT je nastavená na filtrování na střední prahové hodnotě závažnosti pro všechny čtyři kategorie škod obsahu (nenávist, násilí, sexuální a sebepoškozování) a vztahuje se na výzvy (text, vícemodální text/obrázek) a dokončení (text). To znamená, že obsah, který je zjištěn na střední nebo vysoké úrovni závažnosti, je filtrovaný, zatímco obsah zjištěný na úrovni závažnosti není filtrován filtry obsahu. U DALL-E je výchozí prahová hodnota závažnosti nastavená na nízkou pro výzvy (text) i dokončení (obrázky), takže obsah zjištěný na úrovních závažnosti nízký, střední nebo vysoký je filtrovaný. Funkce konfigurovatelnosti je dostupná ve verzi Preview a umožňuje zákazníkům upravit nastavení samostatně pro výzvy a dokončení a filtrovat obsah pro každou kategorii obsahu na různých úrovních závažnosti, jak je popsáno v následující tabulce:
| Filtrovaná závažnost | Konfigurovatelné pro výzvy | Konfigurovatelné pro dokončení | Popisy |
|---|---|---|---|
| Nízká, střední, vysoká | Ano | Yes | Nejtěsnější konfigurace filtrování. Obsah zjištěný na úrovních závažnosti je nízký, střední a vysoký filtrovaný. |
| Střední, vysoká | Ano | Yes | Obsah zjištěný na úrovni závažnosti není filtrovaný, obsah na střední a vysoké úrovni se filtruje. |
| Vysoká | Ano | Yes | Obsah zjištěný na úrovních závažnosti nízký a střední není filtrovaný. Filtruje se pouze obsah na úrovni závažnosti. Vyžaduje schválení1. |
| Žádné filtry | Pokud schváleno1 | Pokud schváleno1 | Žádný obsah se nefiltruje bez ohledu na zjištěnou úroveň závažnosti. Vyžaduje schválení1. |
1 Pro modely Azure OpenAI mají plnou kontrolu nad filtrováním obsahu jenom zákazníci, kteří byli schváleni pro filtrování upraveného obsahu, včetně konfigurace filtrů obsahu na úrovni závažnosti s vysokou úrovní nebo vypnutí filtrů obsahu. Platí pro upravené filtry obsahu prostřednictvím tohoto formuláře: Kontrola omezeného přístupu Azure OpenAI: Upravené filtry obsahu a monitorování zneužití (microsoft.com)
Zákazníci zodpovídají za zajištění toho, aby aplikace integrující Azure OpenAI dodržovaly pravidla chování.
Další vstupní filtry
Můžete také povolit speciální filtry pro scénáře generování umělé inteligence:
- Útoky s jailbreakem: Útoky s jailbreakem jsou uživatelské výzvy navržené tak, aby vyvolaly model generativní umělé inteligence na projevující se chování, které bylo natrénováno, aby se zabránilo nebo přerušilo pravidla nastavená v systémové zprávě.
- Nepřímé útoky: Nepřímé útoky, označované také jako útoky nepřímých výzev nebo útoky prostřednictvím injektáže mezi doménou, představují potenciální ohrožení zabezpečení, kdy třetí strany umístí do dokumentů škodlivé instrukce, ke kterým může systém Generative AI přistupovat a zpracovávat.
Další výstupní filtry
Můžete také povolit následující speciální výstupní filtry:
- Chráněný materiál pro text: Chráněný text popisuje známý textový obsah (například text skladby, články, recepty a vybraný webový obsah), který lze vypisovat velkými jazykovými modely.
- Chráněný materiál pro kód: Chráněný kód materiálu popisuje zdrojový kód, který odpovídá sadě zdrojového kódu z veřejných úložišť, které lze vypisovat velkými jazykovými modely bez správné citace zdrojových úložišť.
- Uzemnění: Filtr detekce uzemnění zjišťuje, jestli jsou textové odpovědi velkých jazykových modelů (LLM) uzemněny ve zdrojových materiálech poskytovaných uživateli.
Další kroky
- Přečtěte si další informace o základních modelech, které power Azure OpenAI.
- Filtrování obsahu Azure AI Studio využívá zabezpečení obsahu Azure AI.
- Přečtěte si další informace o porozumění a zmírnění rizik spojených s vaší aplikací: Přehled zodpovědných postupů AI pro modely Azure OpenAI.
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro