Nasazení velkých jazykových modelů pomocí nástroje Azure AI Studio
Důležité
Některé funkce popsané v tomto článku můžou být dostupné jenom ve verzi Preview. Tato verze Preview je poskytována bez smlouvy o úrovni služeb a nedoporučujeme ji pro produkční úlohy. Některé funkce se nemusí podporovat nebo mohou mít omezené možnosti. Další informace najdete v dodatečných podmínkách použití pro verze Preview v Microsoft Azure.
Nasazení velkého jazykového modelu (LLM) zpřístupňuje použití na webu, aplikaci nebo jiném produkčním prostředí. Nasazení obvykle zahrnuje hostování modelu na serveru nebo v cloudu a vytvoření rozhraní API nebo jiného rozhraní, aby uživatelé mohli s modelem pracovat. Nasazení můžete vyvolat pro odvozování aplikací umělé inteligence v reálném čase, jako je chat a copilot.
V tomto článku se dozvíte, jak nasadit velké jazykové modely v Azure AI Studiu. Modely můžete nasadit z katalogu modelů nebo z projektu. Modely můžete také nasadit pomocí sady Azure Machine Učení SDK. Tento článek také popisuje, jak provést odvozování nasazeného modelu.
Nasazení a odvozování modelu bezserverového rozhraní API pomocí kódu
Nasazení modelu
Modely bezserverového rozhraní API jsou modely, které můžete nasadit s průběžnými platbami. Mezi příklady patří Phi-3, Llama-2, Command R, Mistral Large a další. U modelů bezserverového rozhraní API se vám účtují pouze odvozování, pokud se nerozhodnete model vyladit.
Získání ID modelu
Modely bezserverového rozhraní API můžete nasadit pomocí sady Azure Machine Učení SDK, ale nejprve si projdeme katalog modelů a získáte ID modelu, které potřebujete k nasazení.
Přihlaste se k AI Studiu a přejděte na domovskou stránku.
Na levém bočním panelu vyberte Katalog modelů.
Ve filtru Možností nasazení vyberte bezserverové rozhraní API.
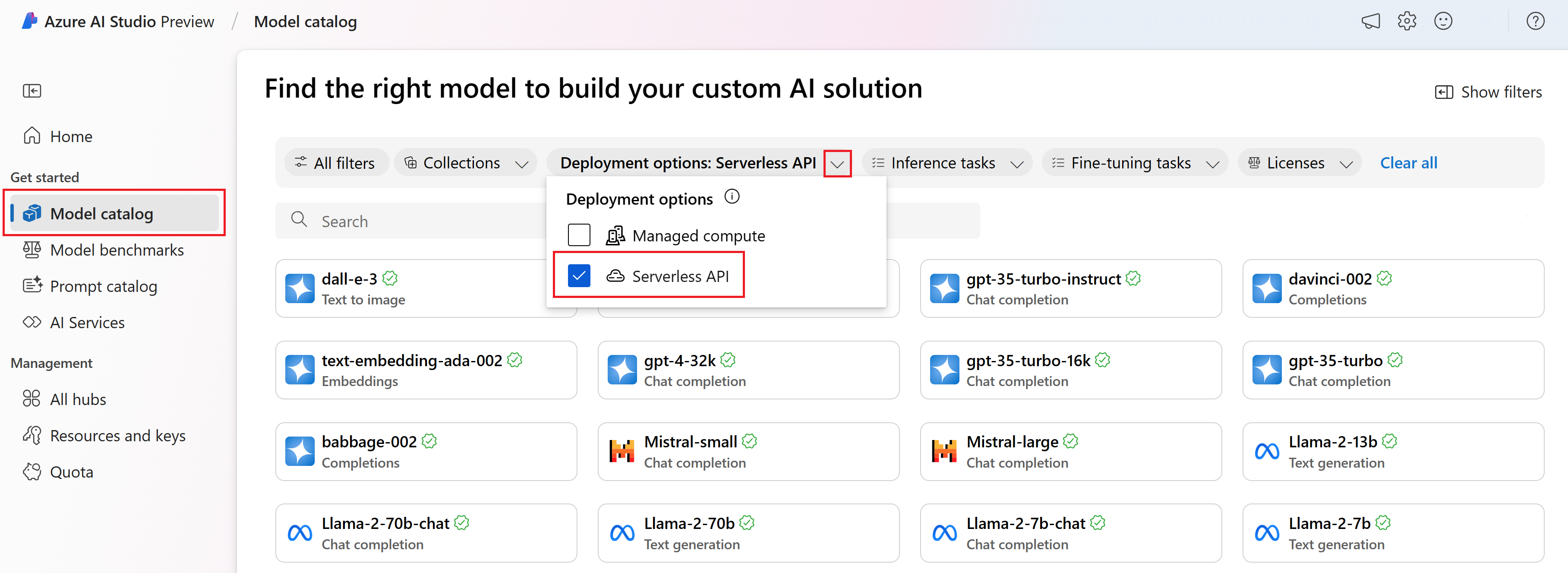
Vyberte model.
Zkopírujte ID modelu ze stránky podrobností vybraného modelu. Vypadá nějak takto:
azureml://registries/azureml-cohere/models/Cohere-command-r-plus/versions/3

Instalace sady Azure Machine Učení SDK
Dále je potřeba nainstalovat sadu Azure Machine Učení SDK. V terminálu spusťte následující příkazy:
pip install azure-ai-ml
pip install azure-identity
Nasazení modelu bezserverového rozhraní API
Nejprve se musíte ověřit v Azure AI.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
from azure.ai.ml.entities import MarketplaceSubscription, ServerlessEndpoint
# You can find your credential information in project settings.
client = MLClient(
credential=DefaultAzureCredential(),
subscription_id="your subscription name goes here",
resource_group_name="your resource group name goes here",
workspace_name="your project name goes here",
)
Za druhé, pojďme odkazovat na ID modelu, které jste našli dříve.
# You can find the model ID on the model catalog.
model_id="azureml://registries/azureml-meta/models/Llama-2-70b-chat/versions/18"
Modely bezserverového rozhraní API od poskytovatelů modelů třetích stran vyžadují k použití modelu předplatné Azure Marketplace. Pojďme vytvořit předplatné marketplace.
Poznámka:
Část můžete přeskočit, pokud nasazujete model bezserverového rozhraní API od Microsoftu, například Phi-3.
# You can customize the subscription name.
subscription_name="Meta-Llama-2-70b-chat"
marketplace_subscription = MarketplaceSubscription(
model_id=model_id,
name=subscription_name,
)
marketplace_subscription = client.marketplace_subscriptions.begin_create_or_update(
marketplace_subscription
).result()
Nakonec vytvoříme bezserverový koncový bod.
endpoint_name="Meta-Llama-2-70b-chat-qwerty" # Your endpoint name must be unique
serverless_endpoint = ServerlessEndpoint(
name=endpoint_name,
model_id=model_id
)
created_endpoint = client.serverless_endpoints.begin_create_or_update(
serverless_endpoint
).result()
Získání koncového bodu a klíčů bezserverového rozhraní API
endpoint_keys = client.serverless_endpoints.get_keys(endpoint_name)
print(endpoint_keys.primary_key)
print(endpoint_keys.secondary_key)
Odvození nasazení
Chcete-li odvodit, chcete použít kód speciálně pro různé typy modelů a sadu SDK, které používáte. Ukázky kódu najdete v ukázkovém úložišti Azure/azureml-examples.
Nasazení a odvození spravovaného výpočetního nasazení pomocí kódu
Nasazení modelu
Katalog modelů AI Studio nabízí více než 1 600 modelů a nejběžnějším způsobem nasazení těchto modelů je použít možnost spravovaného nasazení výpočetních prostředků, která se také někdy označuje jako spravované online nasazení.
Získání ID modelu
Spravované výpočetní modely můžete nasadit pomocí sady Azure Machine Učení SDK, ale nejprve si projdeme katalog modelů a získáte ID modelu, které potřebujete k nasazení.
Přihlaste se k AI Studiu a přejděte na domovskou stránku.
Na levém bočním panelu vyberte Katalog modelů.
Ve filtru Možností nasazení vyberte Spravované výpočetní prostředky.
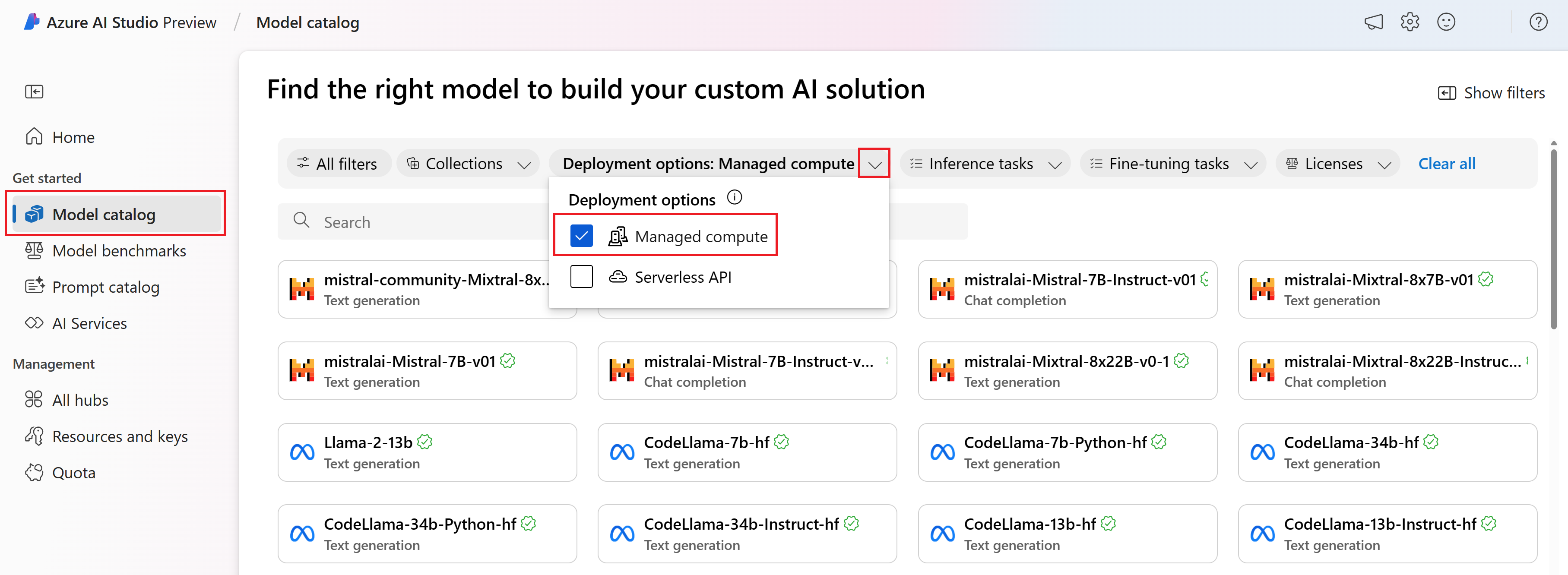
Vyberte model.
Zkopírujte ID modelu ze stránky podrobností vybraného modelu. Vypadá nějak takto:
azureml://registries/azureml/models/deepset-roberta-base-squad2/versions/16

Instalace sady Azure Machine Učení SDK
V tomto kroku je potřeba nainstalovat sadu Azure Machine Učení SDK.
pip install azure-ai-ml
pip install azure-identity
Nasazení modelu
Nejprve se musíte ověřit v Azure AI.
from azure.ai.ml import MLClient
from azure.identity import InteractiveBrowserCredential
client = MLClient(
credential=InteractiveBrowserCredential,
subscription_id="your subscription name goes here",
resource_group_name="your resource group name goes here",
workspace_name="your project name goes here",
)
Pojďme model nasadit.
U možnosti nasazení spravovaného výpočetního prostředí je potřeba vytvořit koncový bod před nasazením modelu. Koncový bod si můžete představit jako kontejner, který může obsahovat více nasazení modelu. Názvy koncových bodů musí být v určité oblasti jedinečné, takže v tomto příkladu používáme časové razítko k vytvoření jedinečného názvu koncového bodu.
import time, sys
from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
ProbeSettings,
)
# Make the endpoint name unique
timestamp = int(time.time())
online_endpoint_name = "customize your endpoint name here" + str(timestamp)
# Create an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
auth_mode="key",
)
workspace_ml_client.begin_create_or_update(endpoint).wait()
Vytvořte nasazení. ID modelu najdete v katalogu modelů.
model_name = "azureml://registries/azureml/models/deepset-roberta-base-squad2/versions/16"
demo_deployment = ManagedOnlineDeployment(
name="demo",
endpoint_name=online_endpoint_name,
model=model_name,
instance_type="Standard_DS3_v2",
instance_count=2,
liveness_probe=ProbeSettings(
failure_threshold=30,
success_threshold=1,
timeout=2,
period=10,
initial_delay=1000,
),
readiness_probe=ProbeSettings(
failure_threshold=10,
success_threshold=1,
timeout=10,
period=10,
initial_delay=1000,
),
)
workspace_ml_client.online_deployments.begin_create_or_update(demo_deployment).wait()
endpoint.traffic = {"demo": 100}
workspace_ml_client.begin_create_or_update(endpoint).result()
Odvození nasazení
K otestování odvozování potřebujete ukázková data JSON. Vytvořte sample_score.json pomocí následujícího příkladu.
{
"inputs": {
"question": [
"Where do I live?",
"Where do I live?",
"What's my name?",
"Which name is also used to describe the Amazon rainforest in English?"
],
"context": [
"My name is Wolfgang and I live in Berlin",
"My name is Sarah and I live in London",
"My name is Clara and I live in Berkeley.",
"The Amazon rainforest (Portuguese: Floresta Amaz\u00f4nica or Amaz\u00f4nia; Spanish: Selva Amaz\u00f3nica, Amazon\u00eda or usually Amazonia; French: For\u00eat amazonienne; Dutch: Amazoneregenwoud), also known in English as Amazonia or the Amazon Jungle, is a moist broadleaf forest that covers most of the Amazon basin of South America. This basin encompasses 7,000,000 square kilometres (2,700,000 sq mi), of which 5,500,000 square kilometres (2,100,000 sq mi) are covered by the rainforest. This region includes territory belonging to nine nations. The majority of the forest is contained within Brazil, with 60% of the rainforest, followed by Peru with 13%, Colombia with 10%, and with minor amounts in Venezuela, Ecuador, Bolivia, Guyana, Suriname and French Guiana. States or departments in four nations contain \"Amazonas\" in their names. The Amazon represents over half of the planet's remaining rainforests, and comprises the largest and most biodiverse tract of tropical rainforest in the world, with an estimated 390 billion individual trees divided into 16,000 species."
]
}
}
Pojďme odvodit sample_score.json. Změňte umístění podle umístění, kam jste uložili ukázkový soubor JSON.
scoring_file = "./sample_score.json"
response = workspace_ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
deployment_name="demo",
request_file=scoring_file,
)
response_json = json.loads(response)
print(json.dumps(response_json, indent=2))
Odstranění koncového bodu nasazení
Pokud chcete odstranit nasazení v AI Studiu, vyberte tlačítko Odstranit na horním panelu stránky s podrobnostmi o nasazení.
Důležité informace o kvótách
Pokud chcete nasadit a provést odvozování s koncovými body v reálném čase, spotřebujete kvótu jader virtuálního počítače, která je přiřazená k vašemu předplatnému na základě jednotlivých oblastí. Když se zaregistrujete do AI Studia, dostanete výchozí kvótu virtuálních počítačů pro několik rodin virtuálních počítačů dostupných v dané oblasti. Nasazení můžete dál vytvářet, dokud nedosáhnete limitu kvóty. Jakmile k tomu dojde, můžete požádat o navýšení kvóty.
Další kroky
- Další informace o tom, co můžete dělat v AI Studiu
- Získejte odpovědi na nejčastější dotazy v článku Nejčastější dotazy k Azure AI