Nápady na řešení
Tento článek popisuje myšlenku řešení. Váš cloudový architekt může pomocí těchto pokynů vizualizovat hlavní komponenty pro typickou implementaci této architektury. Tento článek slouží jako výchozí bod k návrhu dobře navrženého řešení, které odpovídá konkrétním požadavkům vaší úlohy.
Implementace vlastního řešení pro zpracování přirozeného jazyka (NLP) v Azure Pro úlohy, jako je detekce a analýza mínění, použijte Spark NLP.
Apache®, Apache Spark a logo plamene jsou registrované ochranné známky nebo ochranné známky nadace Apache Software Foundation v USA a/nebo v jiných zemích. Použití těchto značek nevyžaduje žádné doporučení Apache Software Foundation.
Architektura

Stáhněte si soubor aplikace Visio s touto architekturou.
Workflow
- Služby Azure Event Hubs, Azure Data Factory nebo obě služby přijímají dokumenty nebo nestrukturovaná textová data.
- Služba Event Hubs a Data Factory ukládají data ve formátu souboru ve službě Azure Data Lake Storage. Doporučujeme nastavit adresářovou strukturu, která vyhovuje obchodním požadavkům.
- Rozhraní AZURE Počítačové zpracování obrazu API využívá k využívání dat funkci optického rozpoznávání znaků (OCR). Rozhraní API pak zapíše data do bronzové vrstvy. Tato platforma Consumption používá architekturu jezerahouse.
- V bronzové vrstvě předzpracuje text různé funkce Spark NLP. Mezi příklady patří rozdělení, oprava pravopisu, čištění a pochopení gramatiky. Doporučujeme spustit klasifikaci dokumentů v bronzové vrstvě a pak zapsat výsledky do stříbrné vrstvy.
- Pokročilé funkce NLP sparku ve stříbrné vrstvě provádějí úlohy analýzy dokumentů, jako je rozpoznávání pojmenovaných entit, shrnutí a načítání informací. V některých architekturách se výsledek zapíše do zlaté vrstvy.
- Ve zlaté vrstvě spouští Spark NLP různé lingvistické vizuální analýzy textových dat. Tyto analýzy poskytují přehled o závislostech jazyka a pomáhají s vizualizací popisků NER.
- Uživatelé se dotazovat na textová data zlaté vrstvy jako datový rámec a zobrazit výsledky v Power BI nebo webových aplikacích.
Během kroků zpracování se azure Databricks, Azure Synapse Analytics a Azure HDInsight používají se Spark NLP k poskytování funkcí NLP.
Komponenty
- Data Lake Storage je systém souborů kompatibilní se systémem Hadoop, který má integrovaný hierarchický obor názvů a masivní škálování a ekonomiku služby Azure Blob Storage.
- Azure Synapse Analytics je analytická služba pro datové sklady a systémy pro velké objemy dat.
- Azure Databricks je analytická služba pro velké objemy dat, která se snadno používají, usnadňují spolupráci a jsou založená na Apache Sparku. Azure Databricks je navržený pro datové vědy a datové inženýrství.
- Event Hubs ingestuje datové proudy, které klientské aplikace generují. Služba Event Hubs ukládá streamovaná data a zachovává posloupnost přijatých událostí. Příjemci se můžou připojit ke koncovým bodům centra, aby mohli načítat zprávy ke zpracování. Služba Event Hubs se integruje se službou Data Lake Storage, jak ukazuje toto řešení.
- Azure HDInsight je spravovaná opensourcová analytická služba v cloudu pro podniky. S Azure HDInsight můžete používat opensourcové architektury, jako je Hadoop, Apache Spark, Apache Hive, LLAP, Apache Kafka, Apache Storm a R.
- Data Factory automaticky přesouvá data mezi účty úložiště různých úrovní zabezpečení, aby se zajistilo oddělení povinností.
- Počítačové zpracování obrazu používá rozhraní API pro rozpoznávání textu k rozpoznávání textu v obrázcích a extrahování informací. Rozhraní API pro čtení používá nejnovější modely rozpoznávání a je optimalizované pro velké dokumenty náročné na text a hlučné obrázky. Rozhraní OCR API není optimalizované pro velké dokumenty, ale podporuje více jazyků než rozhraní API pro čtení. Toto řešení používá OCR k vytváření dat ve formátu hOCR .
Podrobnosti scénáře
Zpracování přirozeného jazyka (NLP) má mnoho použití: analýzu mínění, rozpoznávání témat, rozpoznávání jazyka, extrakci klíčových frází a kategorizaci dokumentů.
Apache Spark je architektura paralelního zpracování, která podporuje zpracování v paměti, aby se zvýšil výkon analytických aplikací pro velké objemy dat, jako je NLP. Azure Synapse Analytics, Azure HDInsight a Azure Databricks nabízejí přístup ke Sparku a využívají jeho výpočetní výkon.
Pro přizpůsobené úlohy NLP slouží opensourcová knihovna Spark NLP jako efektivní architektura pro zpracování velkého množství textu. Tento článek představuje řešení pro rozsáhlé vlastní NLP v Azure. Řešení používá funkce NLP Sparku ke zpracování a analýze textu. Další informace o Spark NLP najdete v tématu Funkce a kanály Spark NLP dále v tomto článku.
Potenciální případy použití
Klasifikace dokumentů: Spark NLP nabízí několik možností klasifikace textu:
- Předběžné zpracování textu v algoritmech Spark NLP a strojového učení založené na Spark ML
- Předběžné zpracování textu a vkládání slov do algoritmů Spark NLP a strojového učení, jako jsou GloVe, BERT a ELMo
- Předběžné zpracování textu a vkládání vět ve SparkU NLP a algoritmech strojového učení, jako je univerzální kodér vět
- Předběžné zpracování a klasifikace textu ve SparkU NLP, která používá anotátor ClassifierDL a je založená na TensorFlow
Extrakce entit názvů (NER): V prostředí Spark NLP s několika řádky kódu můžete vytrénovat model NER, který používá BERT, a dosáhnout nejmodernější přesnosti. NER je dílčí úkol extrakce informací. Funkce NER vyhledá pojmenované entity v nestrukturovaném textu a klasifikuje je do předdefinovaných kategorií, jako jsou jména osob, organizace, místa, lékařské kódy, časové výrazy, množství, peněžní hodnoty a procenta. Spark NLP používá nejmodernější model NER s BERT. Model je inspirovaný bývalým modelem NER, obousměrným systémem LSTM-CNN. Tento bývalý model používá novou architekturu neurální sítě, která automaticky rozpozná funkce na úrovni slov a znakové úrovně. Pro tento účel model používá hybridní obousměrnou architekturu LSTM a CNN, takže eliminuje potřebu většiny technik funkcí.
Rozpoznávání mínění a emocí: Spark NLP dokáže automaticky detekovat pozitivní, negativní a neutrální aspekty jazyka.
Část řeči (POS): Tato funkce přiřadí každému tokenu ve vstupním textu gramatický popisek.
Detekce vět (SD): SD je založená na modelu neuronové sítě pro obecné účely pro detekci hranic vět, která identifikuje věty v textu. Mnoho úkolů NLP má větu jako vstupní jednotku. Mezi příklady těchto úloh patří označování POS, analýza závislostí, rozpoznávání pojmenovaných entit a strojový překlad.
Funkce a kanály Spark NLP
Spark NLP poskytuje knihovny Pythonu, Javy a Scala, které nabízejí plnou funkčnost tradičních knihoven NLP, jako jsou spaCy, NLTK, Stanford CoreNLP a Open NLP. Spark NLP také nabízí funkce, jako je kontrola pravopisu, analýza mínění a klasifikace dokumentů. Spark NLP zlepšuje předchozí úsilí tím, že poskytuje nejmodernější přesnost, rychlost a škálovatelnost.
Spark NLP je zdaleka nejrychlejší opensourcová knihovna NLP. Nedávné veřejné srovnávací testy ukazují Spark NLP jako 38 a 80krát rychlejší než spaCy s srovnatelnou přesností pro trénování vlastních modelů. Spark NLP je jediná opensourcová knihovna, která může používat distribuovaný cluster Spark. Spark NLP je nativní rozšíření Spark ML, které pracuje přímo na datových rámcích. Výsledkem je, že zrychlení v clusteru vede k dalšímu rozsahu zvýšení výkonu. Vzhledem k tomu, že každý kanál Spark NLP je kanál Spark ML, je NLP pro vytváření sjednocených kanálů NLP a strojového učení vhodných pro vytváření sjednocených kanálů NLP a strojového učení, jako je klasifikace dokumentů, predikce rizik a doporučovací kanály.
Kromě vynikajícího výkonu přináší Spark NLP také nejmodernější přesnost pro rostoucí počet úloh NLP. Tým Spark NLP pravidelně čte nejnovější relevantní akademické dokumenty a vytváří nejpřesnější modely.
Pro pořadí provádění kanálu NLP se Spark NLP řídí stejným konceptem vývoje jako tradiční modely strojového učení Sparku. Spark NLP ale používá techniky NLP. Následující diagram znázorňuje základní komponenty kanálu Spark NLP.
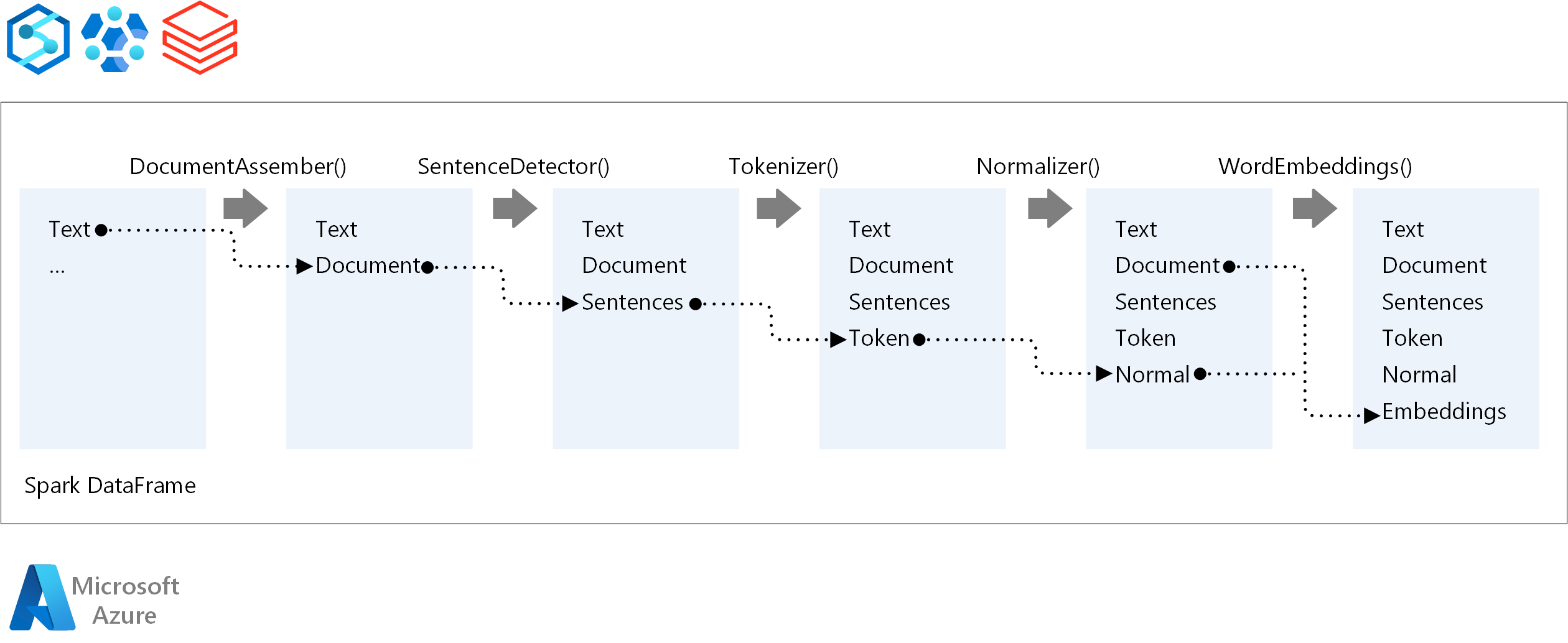
Přispěvatelé
Tento článek spravuje Microsoft. Původně byla napsána následujícími přispěvateli.
Hlavní autor:
- Moritz Steller | Vedoucí architekt cloudových řešení
Další kroky
Dokumentace ke SparkU NLP:
Komponenty Azure: