Poznámka
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Moderní obchodní systémy spravují stále větší objemy heterogenních dat. Tato heterogenita znamená, že jedno úložiště dat obvykle není nejlepší přístup. Místo toho je často lepší ukládat různé typy dat v různých úložištích dat, přičemž každý se zaměřuje na konkrétní úlohu nebo vzor použití. Termín polyglotní trvalost se používá k popisu řešení, která používají kombinaci technologií úložiště dat. Proto je důležité pochopit hlavní modely úložiště a jejich kompromisy.
Výběr správného úložiště dat pro vaše požadavky je klíčovým rozhodnutím o návrhu. Existují doslova stovky implementací, které si můžete vybrat z databází SQL a NoSQL. Úložiště dat se často kategorizují podle toho, jak strukturují data a typy operací, které podporují. Tento článek popisuje několik nejběžnějších modelů úložiště. Upozorňujeme, že konkrétní technologie úložiště dat může podporovat více modelů úložiště. Například systémy pro správu relačních databází (RDBMS) můžou podporovat také úložiště klíčů/hodnot nebo grafů. Ve skutečnosti existuje obecný trend pro tzv. podporu více modelů , kdy jeden databázový systém podporuje několik modelů. Je ale stále užitečné porozumět různým modelům na vysoké úrovni.
Ne všechna úložiště dat v dané kategorii poskytují stejnou sadu funkcí. Většina úložišť dat poskytuje funkce na straně serveru pro dotazování a zpracování dat. Někdy je tato funkce integrovaná do modulu úložiště dat. V jiných případech jsou možnosti ukládání a zpracování dat oddělené a mohou existovat několik možností zpracování a analýzy. Úložiště dat také podporují různá programová rozhraní a rozhraní pro správu.
Obecně byste měli začít zvážením modelu úložiště, který je pro vaše požadavky nejvhodnější. Pak zvažte konkrétní úložiště dat v rámci této kategorie na základě faktorů, jako je sada funkcí, náklady a snadná správa.
Poznámka
Další informace o identifikaci a kontrole požadavků na datové služby pro přechod na cloud najdete v rozhraní Microsoft Cloud Adoption Framework pro Azure. Podobně se také můžete dozvědět o výběru nástrojů a služeb úložiště.
Systémy pro správu relačních databází
Relační databáze uspořádají data jako řadu dvojrozměrných tabulek s řádky a sloupci. Většina dodavatelů poskytuje dialekt jazyka SQL (Structured Query Language) pro načítání a správu dat. RdBMS obvykle implementuje transakční konzistentní mechanismus, který odpovídá modelu ACID (Atomic, Consistent, Isolated, Durable) pro aktualizaci informací.
RdBMS obvykle podporuje model schématu při zápisu, kde je datová struktura definovaná předem a všechny operace čtení nebo zápisu musí schéma používat.
Tento model je velmi užitečný, pokud jsou důležité záruky silné konzistence – kde všechny změny jsou atomické a transakce vždy opouštějí data v konzistentním stavu. Relační databázový systém (RDBMS) ale obecně nedokáže horizontálně škálovat bez nějaké formy rozdělení dat. Data v rdBMS musí být také normalizována, což není vhodné pro každou sadu dat.
Služby Azure
- Azure SQL Database | (Standardní hodnoty zabezpečení)
- Azure Database for MySQL | (Standardní hodnoty zabezpečení)
- Azure Database for PostgreSQL | (Standardní hodnoty zabezpečení)
Pracovní zátěž
- Záznamy se často vytvářejí a aktualizují.
- V jedné transakci musí být dokončeno více operací.
- Relace se vynucují pomocí omezení databáze.
- Indexy se používají k optimalizaci výkonu dotazů.
Datový typ
- Data jsou vysoce normalizovaná.
- Databázová schémata se vyžadují a vynucují.
- Relace mnoho-na-mnoho mezi datovými entitami v databázi.
- Omezení jsou definována ve schématu a ukládají se na všechna data v databázi.
- Data vyžadují vysokou integritu. Indexy a relace je potřeba udržovat přesně.
- Data vyžadují silnou konzistenci. Transakce fungují způsobem, který zajišťuje, že všechna data jsou 100% konzistentní pro všechny uživatele a procesy.
- Velikost jednotlivých datových položek je malá až střední.
Příklady
- Správa inventáře
- Správa objednávek
- Databáze pro sestavování zpráv
- Účetnictví
Úložiště klíčů a hodnot
Úložiště klíč/hodnota přidruží každou datovou hodnotu k jedinečnému klíči. Většina úložišť klíč/hodnota podporuje pouze jednoduché operace dotazování, vkládání a odstraňování. Pokud chcete upravit hodnotu (částečně nebo úplně), musí aplikace přepsat stávající data pro celou hodnotu. Ve většině implementací je čtení nebo zápis jedné hodnoty atomické operace.
Aplikace může ukládat libovolná data jako sadu hodnot. Aplikace musí poskytnout všechny informace o schématu. Úložiště pro klíče a hodnoty jednoduše načte nebo uloží hodnotu na základě klíče.
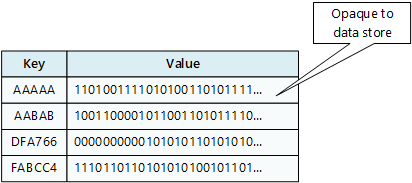
Úložiště klíč/hodnota jsou vysoce optimalizovaná pro aplikace, které provádějí jednoduché vyhledávání, ale jsou méně vhodné, pokud potřebujete dotazovat data napříč různými úložišti klíč/hodnota. Úložiště klíč/hodnota nejsou také optimalizovaná pro dotazování podle hodnoty.
Jedno úložiště klíč/hodnota může být extrémně škálovatelné, protože úložiště dat může snadno distribuovat data mezi více uzlů na samostatných počítačích.
Služby Azure
- Azure Cosmos DB for Table a Azure Cosmos DB for NoSQL | (standardní hodnoty zabezpečení služby Azure Cosmos DB)
- Azure Cache for Redis | (Standardní hodnoty zabezpečení)
- Azure Table Storage | (Standardní hodnoty zabezpečení)
Pracovní zátěž
- K datům se přistupuje pomocí jednoho klíče, jako je slovník.
- Nepotřebujete žádná spojení, zámky ani sjednocení.
- Nepoužívají se žádné mechanismy agregace.
- Sekundární indexy se obecně nepoužívají.
Datový typ
- Každý klíč je přidružený k jedné hodnotě.
- Neexistuje žádné uplatnění schématu.
- Mezi entitami nejsou žádné vztahy.
Příklady
- Ukládání dat do mezipaměti
- Správa relací
- Předvolby uživatelů a správa profilů
- Doporučení k produktům a zobrazování reklam
Databáze dokumentů
Databáze dokumentů ukládá kolekci dokumentů, kde se každý dokument skládá z pojmenovaných polí a dat. Data mohou být jednoduché hodnoty nebo složité prvky, jako jsou seznamy a podřízené kolekce. Dokumenty se načítají jedinečnými klíči.
Dokument obvykle obsahuje data pro jednu entitu, například zákazníka nebo objednávku. Dokument může obsahovat informace, které by byly rozloženy do několika relačních tabulek v RDBMS. Dokumenty nemusí mít stejnou strukturu. Aplikace můžou ukládat různá data do dokumentů, protože se mění obchodní požadavky.
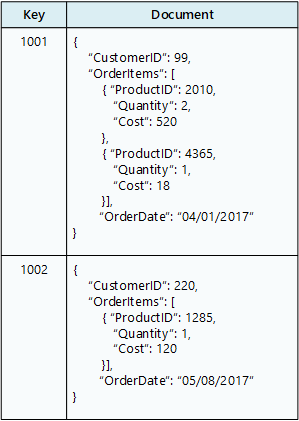
Služba Azure
Azure Cosmos DB for NoSQL (základní úroveň zabezpečení služby Azure Cosmos DB)
Pracovní zátěž
- Operace vložení a aktualizace jsou běžné.
- Žádná neshoda impedance mezi objekty a relačními databázemi. Dokumenty můžou lépe odpovídat strukturám objektů používaným v kódu aplikace.
- Jednotlivé dokumenty se načítají a zapisují jako jeden blok.
- Data vyžadují index u více polí.
Datový typ
- Data je možné spravovat denormalizovaným způsobem.
- Velikost jednotlivých dat dokumentu je poměrně malá.
- Každý typ dokumentu může používat vlastní schéma.
- Dokumenty můžou obsahovat volitelná pole.
- Data dokumentu jsou částečně strukturovaná, což znamená, že datové typy jednotlivých polí nejsou striktně definovány.
Příklady
- Katalog produktů
- Správa obsahu
- Správa inventáře
Grafové databáze
Grafová databáze ukládá dva typy informací, uzlů a hran. Hrany určují vztahy mezi uzly. Uzly a hrany můžou mít vlastnosti, které poskytují informace o daném uzlu nebo okraji, podobně jako sloupce v tabulce. Hrany můžou mít také směr označující povahu relace.
Grafové databáze můžou efektivně provádět dotazy v síti uzlů a hran a analyzovat vztahy mezi entitami. Následující diagram znázorňuje databázi pracovníků organizace strukturovanou jako graf. Entity jsou zaměstnanci a oddělení a hrany označují podřízené vztahy a oddělení, ve kterých zaměstnanci pracují.
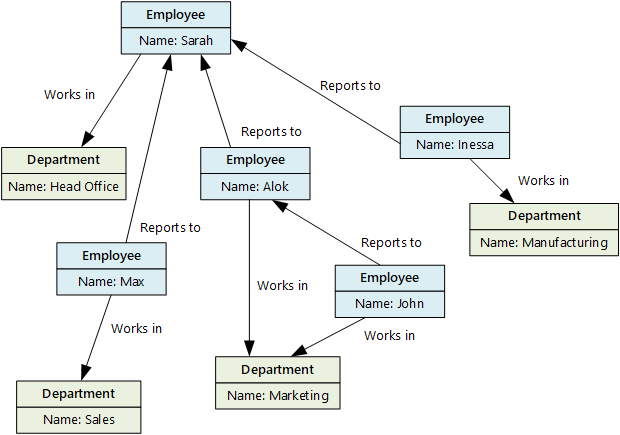
Tato struktura usnadňuje provádění dotazů, jako je například "Najít všechny zaměstnance, kteří přímo nebo nepřímo hlásí Sarah" nebo "Kdo pracuje ve stejném oddělení jako John?". U rozsáhlých grafů s mnoha entitami a relacemi můžete velmi rychle provádět velmi složité analýzy. Mnoho grafových databází poskytuje dotazovací jazyk, který můžete použít k efektivnímu procházení sítě relací.
Služby Azure
Azure Cosmos DB pro Apache Gremlin (standardní hodnoty zabezpečení) - SQL Server | (Standardní hodnoty zabezpečení)
Pracovní zátěž
- Složité vztahy mezi datovými položkami zahrnující mnoho kroků mezi souvisejícími datovými položkami.
- Vztah mezi datovými položkami je dynamický a v průběhu času se mění.
- Vztahy mezi objekty jsou prvotřídní entitou, bez nutnosti cizích klíčů a spojení pro procházení.
Datový typ
- Uzly a vztahy.
- Uzly jsou podobné řádkům tabulky nebo dokumentům JSON.
- Relace jsou stejně důležité jako uzly a zobrazují se přímo v dotazovacím jazyce.
- Složené objekty, jako je osoba s více telefonními čísly, jsou obvykle rozdělené do samostatných menších uzlů v kombinaci s relacemi umožňujícími procházení.
Příklady
- Organizační diagramy
- Sociální grafy
- Detekce podvodů
- Moduly doporučení
Analýza dat
Úložiště analýzy dat poskytují masivně paralelní řešení pro ingestování, ukládání a analýzu dat. Data se distribuují mezi více serverů, aby se maximalizovala škálovatelnost. Velké formáty datových souborů, jako jsou soubory s oddělovačem (CSV), parquet a ORC , se běžně používají při analýze dat. Historická data se obvykle ukládají v úložištích dat, jako je úložiště objektů blob nebo Azure Data Lake Storage Gen2 . Tato úložiště pak Azure Synapse, Databricks nebo HDInsight používají jako externí tabulky. Typický scénář použití dat uložených jako soubory parquet kvůli zlepšení výkonu je popsán v článku Použití externích tabulek se Synapse SQL.
Služby Azure
- Azure Synapse Analytics | (Standardní hodnoty zabezpečení)
-
Azure Data Lake (standardní hodnoty zabezpečení) - Azure Data Explorer | (Standardní hodnoty zabezpečení)
- Azure Analysis Services
- HDInsight | (Standardní hodnoty zabezpečení)
- Azure Databricks | (Standardní hodnoty zabezpečení)
Pracovní zátěž
- Analýza dat
- Podniková BI
Datový typ
- Historická data z více zdrojů
- Obvykle se denormalizuje podle schématu typu „hvězda“ nebo „sněhová vločka“, které se skládá z tabulek faktů a tabulek dimenzí.
- Obvykle jsou načítány s novými daty podle plánu.
- Tabulky dimenzí často obsahují několik historických verzí entity, které se označují jako pomalu se měnící dimenze.
Příklady
- Podnikový datový sklad
Databáze skupin sloupců
Databáze rodiny sloupců uspořádá data do řádků a sloupců. V nejjednodušší podobě se databáze s rodinou sloupců může zdát velmi podobná relační databázi, alespoň koncepčně. Skutečná síla databáze sloupcové rodiny spočívá ve svém denormalizovaném přístupu k strukturování řídkých dat.
Databázi rodiny sloupců si můžete představit jako uchovávání tabulkových dat s řádky a sloupci, ale sloupce jsou rozdělené do skupin označovaných jako rodiny sloupců. Každá řada sloupců obsahuje sadu sloupců, které spolu logicky souvisejí a obvykle se načítají nebo manipulují jako jednotka. Další data, ke kterým se přistupuje samostatně, se dají uložit v samostatných rodinách sloupců. V rámci rodiny sloupců je možné přidávat nové sloupce dynamicky a řádky můžou být řídké (to znamená, že řádek nemusí mít hodnotu pro každý sloupec).
Následující diagram znázorňuje příklad se dvěma rodinami sloupců, Identity a Contact Info. Data pro jednu entitu mají v každé skupině sloupců stejný klíč řádku. Tato struktura, ve které se řádky pro každý daný objekt v rodině sloupců mohou dynamicky lišit, je důležitou výhodou přístupu rodiny sloupců, takže tato forma úložiště dat je vysoce vhodná pro ukládání strukturovaných a nestálých dat.

Na rozdíl od úložiště klíč/hodnota nebo databáze dokumentů ukládá většina databází řady sloupců data v pořadí klíčů, nikoli výpočtem hodnoty hash. Mnoho implementací umožňuje vytvářet indexy nad konkrétními sloupci v řadě sloupců. Indexy umožňují načíst data podle hodnoty sloupců, nikoli podle klíče řádku.
Operace čtení a zápisu pro řádek jsou obvykle atomické s jednou rodinou sloupců, ačkoliv některé implementace poskytují atomicitu přes celý řádek, pokrývající více rodin sloupců.
Služby Azure
Azure Cosmos DB pro Apache Cassandra (standardní hodnoty zabezpečení) - HBase v HDInsightu | (Standardní hodnoty zabezpečení)
Pracovní zátěž
- Většina databází řady sloupců provádí operace zápisu velmi rychle.
- Operace aktualizace a odstranění jsou vzácné.
- Navržená tak, aby poskytovala přístup s vysokou propustností a nízkou latencí.
- Podporuje snadný přístup k dotazu na určitou sadu polí v mnohem větším záznamu.
- Masivně škálovatelné.
Datový typ
- Data se ukládají v tabulkách, které se skládají z klíčového sloupce a jedné nebo více rodin sloupců.
- Konkrétní sloupce se můžou lišit podle jednotlivých řádků.
- Jednotlivé buňky jsou přístupné prostřednictvím příkazů get a put
- Pomocí příkazu scan se vrátí více řádků.
Příklady
- Doporučení
- Personalizace
- Data ze snímačů
- Telemetrie
- Odesílání zpráv
- Analýza sociálních médií
- Webová analýza
- Monitorování aktivit
- Data o počasí a dalších časových řadách
Databáze vyhledávacího stroje
Databáze vyhledávacího stroje umožňuje aplikacím vyhledávat informace uchovávané v externích úložištích dat. Databáze vyhledávacího webu může indexovat obrovské objemy dat a poskytovat přístup k těmto indexům téměř v reálném čase.
Indexy můžou být vícerozměrné a můžou podporovat vyhledávání volného textu ve velkých objemech textových dat. Indexování je možné provádět pomocí pull modelu, aktivovaného databází vyhledávacího enginu, nebo pomocí push modelu, iniciovaného kódem externí aplikace.
Hledání může být přesné nebo přibližné. Vyhledávání přibližných shod najde dokumenty, které odpovídají sadě termínů, a vypočítá, jak přesně odpovídají. Některé vyhledávače také podporují lingvistické analýzy, které mohou vracet shody na základě synonym, rozšíření žánrů (například přiřazení dogs k pets) a lemmatizaci (slova se stejným kořenem).
Služba Azure
Pracovní zátěž
- Indexy dat z více zdrojů a služeb
- Dotazy jsou ad hoc a můžou být složité.
- Vyžaduje se fulltextové vyhledávání.
- Vyžaduje se ad hoc samoobslužný dotaz.
Datový typ
- Částečně strukturovaný nebo nestrukturovaný text
- Text s odkazem na strukturovaná data
Příklady
- Katalogy produktů
- Vyhledávání na webu
- Protokolování
Databáze časových řad
Data časových řad jsou sada hodnot uspořádaných podle času. Databáze časových řad obvykle shromažďují velké objemy dat v reálném čase z velkého počtu zdrojů. Aktualizace jsou vzácné a odstranění se často provádí jako hromadné operace. I když jsou záznamy zapsané do databáze časových řad obecně malé, často existuje velký počet záznamů a celková velikost dat se může rychle zvětšit.
Služba Azure
Pracovní zátěž
- Záznamy se obvykle připojují postupně v časovém pořadí.
- Převážná většina operací (95–99 %%) tvoří zápisy.
- Aktualizace jsou vzácné.
- Odstranění probíhá hromadně a provádí se v souvislých blocích nebo záznamech.
- Data se čtou postupně ve vzestupném nebo sestupném časovém pořadí, často paralelně.
Datový typ
- Časové razítko se používá jako primární klíč a mechanismus řazení.
- Značky mohou definovat další informace o typu, původu a dalších informacích o položce.
Příklady
- Monitorování a telemetrie událostí
- Senzor nebo jiná data IoT
Úložiště objektů
Úložiště objektů je optimalizované pro ukládání a načítání velkých binárních objektů (obrázky, soubory, video a zvukové streamy, velké datové objekty aplikací a dokumenty, image disků virtuálního počítače). Velké datové soubory se také v tomto modelu často používají, například soubor s oddělovačem (CSV), parquet a ORC. Úložiště objektů můžou spravovat extrémně velké objemy nestrukturovaných dat.
Služba Azure
- Azure Blob Storage | (Standardní hodnoty zabezpečení)
- Azure Data Lake Storage Gen2 | (Standardní hodnoty zabezpečení)
Pracovní zátěž
- Identifikovaný podle klíče
- Obsah je obvykle prvek, jako je oddělovač, obrázek nebo videosoubor.
- Obsah musí být trvalý a externí pro libovolnou aplikační vrstvu.
Datový typ
- Velikost dat je velká.
- Hodnota je neprůhledná.
Příklady
- Obrázky, videa, dokumenty office, soubory PDF
- Statické HTML, JSON, CSS
- Soubory protokolu a auditu
- Zálohy databáze
Sdílené soubory
Někdy může být použití jednoduchých plochých souborů nejúčinnějším způsobem ukládání a načítání informací. Použití sdílených složek umožňuje přístup k souborům přes síť. Díky příslušným mechanismům zabezpečení a souběžnému řízení přístupu může sdílení dat tímto způsobem umožnit distribuovaným službám poskytovat vysoce škálovatelný přístup k datům pro provádění základních operací nízké úrovně, jako jsou jednoduché požadavky na čtení a zápis.
Služba Azure
-
Azure Files (základ zabezpečení)
Pracovní zátěž
- Migrace z existujících aplikací, které pracují se systémem souborů
- Vyžaduje rozhraní SMB.
Datový typ
- Soubory v hierarchické sadě složek
- Přístupné se standardními knihovnami pro vstup a výstup.
Příklady
- Starší verze souborů
- Sdílený obsah přístupný z řady virtuálních počítačů nebo instancí aplikací
S pochopením různých modelů úložiště dat vám pomůže následující krok vyhodnotit úlohy a aplikaci a rozhodnout se, které úložiště dat bude vyhovovat vašim konkrétním potřebám. K tomuto procesu vám pomůže rozhodovací strom úložiště dat .
Další kroky
- Řešení a služby cloudového úložiště Azure
- Kontrola možností úložiště
- Seznámení se službou Azure Storage
- Úvod do Azure Data Exploreru