Kontrola stavu uzlu a podu
Tento článek je součástí série článků. Začněte přehledem.
Pokud cluster zkontroluje, že jste provedli v předchozím kroku, zkontrolujte stav pracovních uzlů Azure Kubernetes Service (AKS). Podle šesti kroků v tomto článku zkontrolujte stav uzlů, zjistěte důvod uzlu, který není v pořádku, a problém vyřešte.
Krok 1: Kontrola stavu pracovních uzlů
Různé faktory můžou přispět k uzlům, které nejsou v pořádku v clusteru AKS. Jedním z běžných důvodů je rozdělení komunikace mezi řídicí rovinou a uzly. Tato nesprávná komunikaci je často způsobena chybnou konfigurací pravidel směrování a brány firewall.
Když nakonfigurujete cluster AKS pro uživatelem definované směrování, musíte nakonfigurovat výchozí cesty prostřednictvím síťového virtuálního zařízení nebo brány firewall, jako je brána firewall Azure. Pokud chcete vyřešit problém s chybnou konfigurací, doporučujeme nakonfigurovat bránu firewall tak, aby umožňovala nezbytné porty a plně kvalifikované názvy domén (FQDN) v souladu s pokyny pro výchozí přenos dat AKS.
Dalším důvodem nezdravých uzlů může být nedostatečný výpočetní výkon, paměť nebo prostředky úložiště, které vytvářejí tlaky kubeletu. V takových případech může vertikální navýšení kapacity prostředků účinně vyřešit problém.
V privátním clusteru AKS můžou problémy s překladem DNS (Domain Name System) způsobit problémy s komunikací mezi řídicí rovinou a uzly. Musíte ověřit, že se název DNS serveru rozhraní Kubernetes API překládá na privátní IP adresu serveru rozhraní API. Nesprávná konfigurace vlastního serveru DNS je běžnou příčinou selhání překladu DNS. Pokud používáte vlastní servery DNS, ujistěte se, že je správně zadáte jako servery DNS ve virtuální síti, kde jsou uzly zřízeny. Ověřte také, že privátní server rozhraní API AKS je možné přeložit přes vlastní server DNS.
Po vyřešení těchto potenciálních problémů souvisejících s komunikací řídicí roviny a překladem DNS můžete efektivně řešit a řešit problémy se stavem uzlů v rámci clusteru AKS.
Stav uzlů můžete vyhodnotit pomocí jedné z následujících metod.
Zobrazení stavu kontejnerů služby Azure Monitor
Pokud chcete zobrazit stav uzlů, podů uživatelů a systémových podů v clusteru AKS, postupujte takto:
- Na webu Azure Portal přejděte do služby Azure Monitor.
- V části Přehledy navigačního podokna vyberte Kontejnery.
- Vyberte Monitorované clustery pro seznam monitorovaných clusterů AKS.
- Výběrem clusteru AKS ze seznamu zobrazíte stav uzlů, uživatelských podů a systémových podů.

Zobrazení uzlů AKS
Pokud chcete zajistit, aby všechny uzly v clusteru AKS byly ve stavu připraveno, postupujte takto:
- Na webu Azure Portal přejděte do clusteru AKS.
- V části Nastavení navigačního podokna vyberte Fondy uzlů.
- Vyberte Uzly.
- Ověřte, že jsou všechny uzly v připraveném stavu.

Monitorování v clusteru pomocí nástroje Prometheus a Grafana
Pokud jste nasadili Prometheus a Grafana v clusteru AKS, můžete získat přehledy pomocí řídicího panelu podrobností clusteru K8. Tento řídicí panel zobrazuje metriky clusteru Prometheus a zobrazuje důležité informace, jako je využití procesoru, využití paměti, síťová aktivita a využití systému souborů. Zobrazuje také podrobné statistiky pro jednotlivé pody, kontejnery a systémové služby.
Na řídicím panelu vyberte Podmínky uzlu a zobrazte metriky o stavu a výkonu clusteru. Můžete sledovat uzly, které můžou mít problémy, jako jsou problémy s jejich plánem, síť, tlak na disk, tlak na paměť, proporcionální integrální derivátový tlak (PID) nebo místo na disku. Monitorujte tyto metriky, abyste mohli proaktivně identifikovat a řešit případné problémy, které mají vliv na dostupnost a výkon clusteru AKS.

Monitorování spravované služby pro Prometheus a Azure Managed Grafana
Pomocí předem připravených řídicích panelů můžete vizualizovat a analyzovat metriky Prometheus. K tomu musíte nastavit cluster AKS tak, aby shromažďuje metriky Prometheus ve spravované službě Monitor pro Prometheus a připojili pracovní prostor Monitoru k pracovnímu prostoru Azure Managed Grafana . Tyto řídicí panely poskytují komplexní přehled o výkonu a stavu clusteru Kubernetes.
Řídicí panely se zřídí v zadané instanci Azure Managed Grafana ve složce Managed Prometheus . Mezi řídicí panely patří:
- Kubernetes / Výpočetní prostředky / Cluster
- Kubernetes / Výpočetní prostředky / Obor názvů (pody)
- Kubernetes / Výpočetní prostředky / Uzel (pody)
- Kubernetes / Výpočetní prostředky / Pod
- Kubernetes / Výpočetní prostředky / Obor názvů (úlohy)
- Kubernetes / Výpočetní prostředky / Úlohy
- Kubernetes / Kubelet
- Exportér uzlu / METODA USE / Uzel
- Export uzlů / Uzly
- Kubernetes / Výpočetní prostředky / Cluster (Windows)
- Kubernetes / Výpočetní prostředky / Obor názvů (Windows)
- Kubernetes / Výpočetní prostředky / Pod (Windows)
- Kubernetes / METODA USE / Cluster (Windows)
- Kubernetes / METODA USE / Node (Windows)
Tyto integrované řídicí panely se široce používají v opensourcové komunitě pro monitorování clusterů Kubernetes pomocí Prometheus a Grafany. Pomocí těchto řídicích panelů můžete zobrazit metriky, jako jsou využití prostředků, stav podu a síťová aktivita. Můžete také vytvořit vlastní řídicí panely, které jsou přizpůsobené vašim potřebám monitorování. Řídicí panely pomáhají efektivně monitorovat a analyzovat metriky Prometheus v clusteru AKS, které umožňují optimalizovat výkon, řešit problémy a zajistit hladký provoz úloh Kubernetes.
Pomocí řídicího panelu Kubernetes / Výpočetní prostředky / Uzly (pody) můžete zobrazit metriky pro uzly agenta Linuxu. Pro každý pod můžete vizualizovat využití procesoru, kvótu procesoru, využití paměti a kvótu paměti.

Pokud váš cluster obsahuje uzly agenta Windows, můžete pomocí řídicího panelu Kubernetes / USE Method / Node (Windows) vizualizovat metriky Prometheus shromážděné z těchto uzlů. Tento řídicí panel poskytuje komplexní přehled o spotřebě prostředků a výkonu uzlů Windows v rámci clusteru.
Využijte tyto vyhrazené řídicí panely, abyste mohli snadno monitorovat a analyzovat důležité metriky související s procesorem, pamětí a dalšími prostředky v uzlech agenta Linuxu a Windows. Tato viditelnost umožňuje identifikovat potenciální kritické body, optimalizovat přidělení prostředků a zajistit efektivní provoz v clusteru AKS.
Krok 2: Ověření připojení řídicí roviny a pracovního uzlu
Pokud jsou pracovní uzly v pořádku, měli byste prozkoumat připojení mezi spravovanou řídicí rovinou AKS a pracovními uzly clusteru. AKS umožňuje komunikaci mezi serverem rozhraní API Kubernetes a jednotlivými uzly kubelets prostřednictvím zabezpečené metody komunikace tunelu. Tyto komponenty můžou komunikovat i v případě, že jsou v různých virtuálních sítích. Tunel je chráněn šifrováním mTLS (Mutual Transport Layer Security). Primární tunel, který AKS používá, se nazývá Konnectivity (dříve označovaný jako apiserver-network-proxy). Ujistěte se, že všechna pravidla sítě a plně kvalifikované názvy domén splňují požadovaná pravidla sítě Azure.
K ověření připojení mezi spravovanou řídicí rovinou AKS a pracovními uzly clusteru clusteru AKS můžete použít nástroj příkazového řádku kubectl .
Pokud chcete zajistit, aby pody agenta Konnectivity fungovaly správně, spusťte následující příkaz:
kubectl get deploy konnectivity-agent -n kube-system
Ujistěte se, že jsou pody v připraveném stavu.
Pokud dojde k problému s připojením mezi řídicí rovinou a pracovními uzly, nastavte připojení poté, co zajistíte, že jsou povolená požadovaná pravidla odchozího provozu AKS.
Spuštěním následujícího příkazu restartujte konnectivity-agent pody:
kubectl rollout restart deploy konnectivity-agent -n kube-system
Pokud restartování podů neopraví připojení, zkontrolujte protokoly anomálií. Spuštěním následujícího příkazu zobrazte protokoly podů konnectivity-agent :
kubectl logs -l app=konnectivity-agent -n kube-system --tail=50
Protokoly by měly zobrazit následující výstup:
I1012 12:27:43.521795 1 options.go:102] AgentCert set to "/certs/client.crt".
I1012 12:27:43.521831 1 options.go:103] AgentKey set to "/certs/client.key".
I1012 12:27:43.521834 1 options.go:104] CACert set to "/certs/ca.crt".
I1012 12:27:43.521837 1 options.go:105] ProxyServerHost set to "sethaks-47983508.hcp.switzerlandnorth.azmk8s.io".
I1012 12:27:43.521841 1 options.go:106] ProxyServerPort set to 443.
I1012 12:27:43.521844 1 options.go:107] ALPNProtos set to [konnectivity].
I1012 12:27:43.521851 1 options.go:108] HealthServerHost set to
I1012 12:27:43.521948 1 options.go:109] HealthServerPort set to 8082.
I1012 12:27:43.521956 1 options.go:110] AdminServerPort set to 8094.
I1012 12:27:43.521959 1 options.go:111] EnableProfiling set to false.
I1012 12:27:43.521962 1 options.go:112] EnableContentionProfiling set to false.
I1012 12:27:43.521965 1 options.go:113] AgentID set to b7f3182c-995e-4364-aa0a-d569084244e4.
I1012 12:27:43.521967 1 options.go:114] SyncInterval set to 1s.
I1012 12:27:43.521972 1 options.go:115] ProbeInterval set to 1s.
I1012 12:27:43.521980 1 options.go:116] SyncIntervalCap set to 10s.
I1012 12:27:43.522020 1 options.go:117] Keepalive time set to 30s.
I1012 12:27:43.522042 1 options.go:118] ServiceAccountTokenPath set to "".
I1012 12:27:43.522059 1 options.go:119] AgentIdentifiers set to .
I1012 12:27:43.522083 1 options.go:120] WarnOnChannelLimit set to false.
I1012 12:27:43.522104 1 options.go:121] SyncForever set to false.
I1012 12:27:43.567902 1 client.go:255] "Connect to" server="e9df3653-9bd4-4b09-b1a7-261f6104f5d0"
Poznámka:
Když je cluster AKS nastavený s integrací virtuální sítě serveru API a buď rozhraním CNI (Azure Container Networking Interface) nebo Azure CNI s dynamickým přiřazením IP adres podů, nemusíte nasazovat agenty Konnectivity. Integrované pody serveru rozhraní API můžou navázat přímou komunikaci s pracovními uzly clusteru prostřednictvím privátních sítí.
Pokud ale používáte integraci virtuální sítě serveru API s azure CNI Overlay nebo přineste si vlastní CNI (BYOCNI), konnectivity se nasadí pro usnadnění komunikace mezi servery API a IP adresami podů. Komunikace mezi servery rozhraní API a pracovními uzly zůstává přímá.
Můžete také prohledat protokoly kontejneru ve službě protokolování a monitorování a načíst protokoly. Příklad, který hledá chyby připojení aks-link , najdete v tématu Protokoly dotazů z přehledů kontejneru.
Spuštěním následujícího dotazu načtěte protokoly:
ContainerLogV2
| where _ResourceId =~ "/subscriptions/<subscription-ID>/resourceGroups/<resource-group-name>/providers/Microsoft.ContainerService/managedClusters/<cluster-ID>" // Use the IDs and names of your resources for these values.
| where ContainerName has "aks-link"
| project LogSource,LogMessage, TimeGenerated, Computer, PodName, ContainerName, ContainerId
| order by TimeGenerated desc
| limit 200
Spuštěním následujícího dotazu vyhledejte protokoly kontejneru pro všechny neúspěšné pody v konkrétním oboru názvů:
let KubePodInv = KubePodInventory
| where TimeGenerated >= startTime and TimeGenerated < endTime
| where _ResourceId =~ "<cluster-resource-ID>" // Use your resource ID for this value.
| where Namespace == "<pod-namespace>" // Use your target namespace for this value.
| where PodStatus == "Failed"
| extend ContainerId = ContainerID
| summarize arg_max(TimeGenerated, *) by ContainerId, PodStatus, ContainerStatus
| project ContainerId, PodStatus, ContainerStatus;
KubePodInv
| join
(
ContainerLogV2
| where TimeGenerated >= startTime and TimeGenerated < endTime
| where PodNamespace == "<pod-namespace>" //update with target namespace
) on ContainerId
| project TimeGenerated, PodName, PodStatus, ContainerName, ContainerId, ContainerStatus, LogMessage, LogSource
Pokud nemůžete protokoly získat pomocí dotazů nebo nástroje kubectl, použijte ověřování Secure Shell (SSH). V tomto příkladu se po připojení k uzlu přes SSH najde pod tunelové skříně .
kubectl pods -n kube-system -o wide | grep tunnelfront
ssh azureuser@<agent node pod is on, output from step above>
docker ps | grep tunnelfront
docker logs …
nslookup <ssh-server_fqdn>
ssh -vv azureuser@<ssh-server_fqdn> -p 9000
docker exec -it <tunnelfront_container_id> /bin/bash -c "ping bing.com"
kubectl get pods -n kube-system -o wide | grep <agent_node_where_tunnelfront_is_running>
kubectl delete po <kube_proxy_pod> -n kube-system
Krok 3: Ověření překladu DNS při omezení výchozího přenosu dat
Překlad DNS je zásadním aspektem clusteru AKS. Pokud překlad DNS nefunguje správně, může to způsobit chyby řídicí roviny nebo selhání načítání imagí kontejneru. Pokud chcete zajistit správné fungování překladu DNS na server rozhraní API Kubernetes, postupujte takto:
Spuštěním příkazu kubectl exec otevřete příkazové prostředí v kontejneru, který běží v podu.
kubectl exec --stdin --tty your-pod --namespace <namespace-name> -- /bin/bashZkontrolujte, jestli jsou v kontejneru nainstalované nástroje nslookup nebo dig .
Pokud není v podu nainstalovaný žádný nástroj, spuštěním následujícího příkazu vytvořte pod nástroje ve stejném oboru názvů.
kubectl run -i --tty busybox --image=busybox --namespace <namespace-name> --rm=true -- shAdresu serveru ROZHRANÍ API můžete načíst ze stránky přehledu clusteru AKS na webu Azure Portal nebo můžete spustit následující příkaz.
az aks show --name <aks-name> --resource-group <resource-group-name> --query fqdn --output tsvSpuštěním následujícího příkazu se pokuste přeložit server rozhraní API AKS. Další informace najdete v tématu Řešení potíží se selháním překladu DNS z podu, ale ne z pracovního uzlu.
nslookup myaks-47983508.hcp.westeurope.azmk8s.ioZkontrolujte nadřazený server DNS z podu a zjistěte, jestli překlad DNS funguje správně. Například pro Azure DNS spusťte
nslookuppříkaz.nslookup microsoft.com 168.63.129.16Pokud předchozí kroky neposkytují přehledy, připojte se k jednomu z pracovních uzlů a zkuste z uzlu překlad DNS. Tento krok pomáhá identifikovat, jestli problém souvisí s AKS nebo konfigurací sítě.
Pokud je překlad DNS z uzlu úspěšný, ale ne z podu, může problém souviset s DNS Kubernetes. Postup ladění překladu DNS z podu najdete v tématu Řešení potíží se selháními překladu DNS.
Pokud překlad DNS z uzlu selže, zkontrolujte nastavení sítě a ujistěte se, že jsou otevřené odpovídající cesty směrování a porty pro usnadnění překladu DNS.
Krok 4: Kontrola chyb kubeletu
Ověřte podmínku procesu kubeletu, který běží na každém pracovním uzlu, a ujistěte se, že není pod tlakem. Potenciální tlak se může týkat procesoru, paměti nebo úložiště. Pokud chcete ověřit stav jednotlivých uzlů kubelet, můžete použít jednu z následujících metod.
Sešit kubeletu AKS
Pokud chcete zajistit, aby kubelety uzlů agenta fungovaly správně, postupujte takto:
Na webu Azure Portal přejděte do clusteru AKS.
V části Monitorování v navigačním podokně vyberte Sešity.
Vyberte sešit Kubelet.
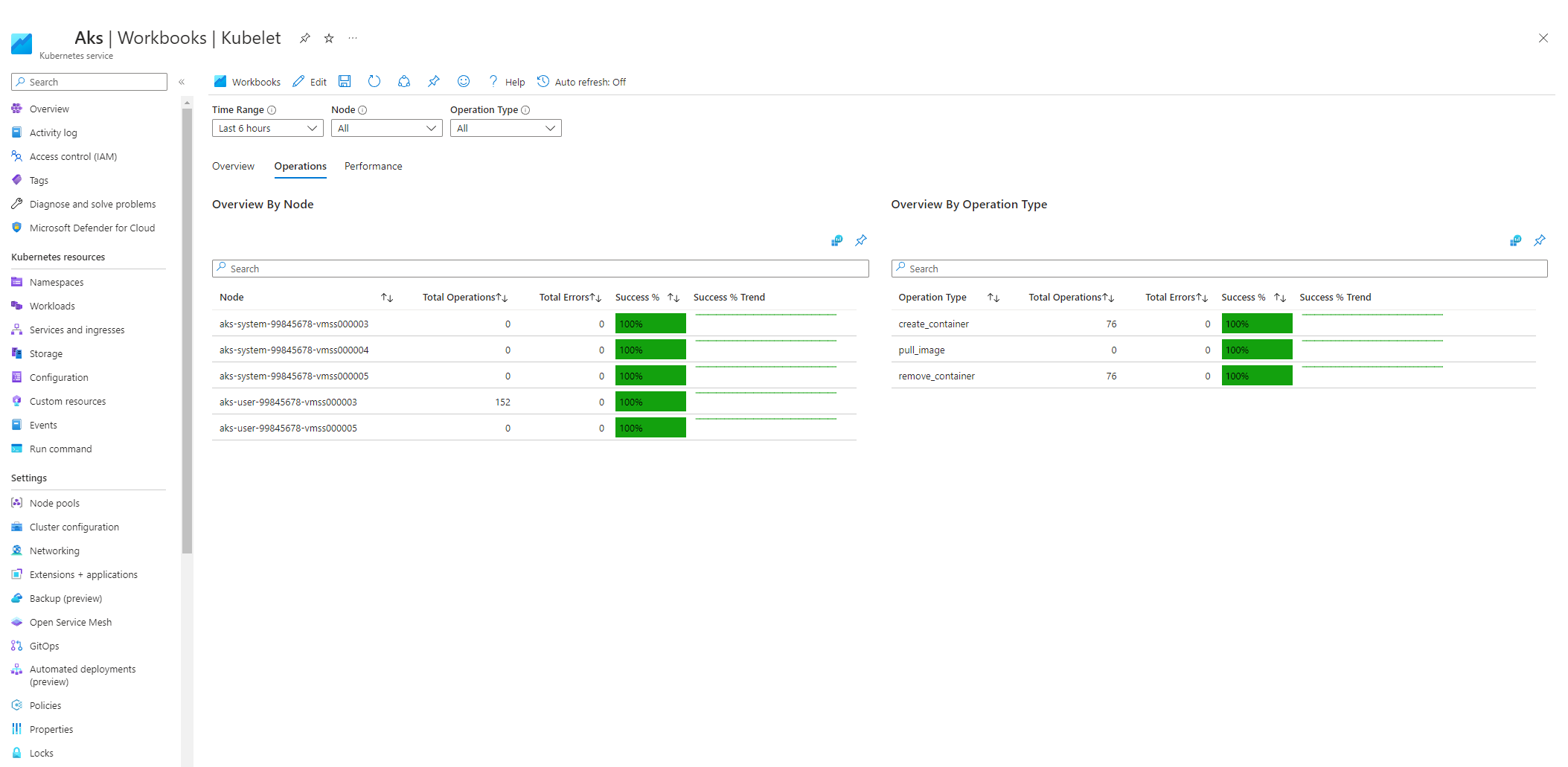
Vyberte Operace a ujistěte se, že jsou dokončené operace pro všechny pracovní uzly.


Monitorování v clusteru pomocí nástroje Prometheus a Grafana
Pokud jste nasadili Prometheus a Grafana v clusteru AKS, můžete pomocí řídicího panelu Kubernetes / Kubelet získat přehled o stavu a výkonu jednotlivých kubelet uzlů.

Monitorování spravované služby pro Prometheus a Azure Managed Grafana
Pomocí předem vytvořeného řídicího panelu Kubernetes / Kubelet můžete vizualizovat a analyzovat metriky Prometheus pro kubelety pracovních uzlů. K tomu musíte nastavit cluster AKS tak, aby shromažďuje metriky Prometheus ve spravované službě Monitor pro Prometheus a připojili pracovní prostor Monitoru k pracovnímu prostoru Azure Managed Grafana .

Tlak se zvyšuje, když se kubelet restartuje a způsobuje občasné, nepředvídatelné chování. Ujistěte se, že se počet chyb nepřerůstá nepřetržitě. Občasná chyba je přijatelná, ale konstantní růst značí základní problém, který je nutné prošetřit a vyřešit.
Krok 5: Pomocí nástroje NPD (Node Problem Detector) zkontrolujte stav uzlu
NPD je nástroj Kubernetes, který můžete použít k identifikaci a hlášení problémů souvisejících s uzly. Funguje jako systémová služba na každém uzlu v clusteru. Shromažďuje metriky a systémové informace, jako je využití procesoru, využití disku a stav připojení k síti. Když se zjistí problém, nástroj NPD vygeneruje sestavu událostí a podmínky uzlu. V AKS se nástroj NPD používá k monitorování a správě uzlů v clusteru Kubernetes hostovaném v cloudu Azure. Další informace najdete v tématu NPD v uzlech AKS.
Krok 6: Kontrola omezování vstupně-výstupních operací disku za sekundu (IOPS)
Pokud chcete zajistit, aby se počet IOPS omezoval a ovlivnil služby a úlohy v clusteru AKS, můžete použít jednu z následujících metod.
V/V sešit disku uzlu AKS
Pokud chcete monitorovat metriky související s vstupně-výstupními operacemi disku pracovních uzlů v clusteru AKS, můžete použít V/V sešit disku uzlu. Při přístupu k sešitu postupujte takto:
Na webu Azure Portal přejděte do clusteru AKS.
V části Monitorování v navigačním podokně vyberte Sešity.
Vyberte sešit IO disku uzlu.
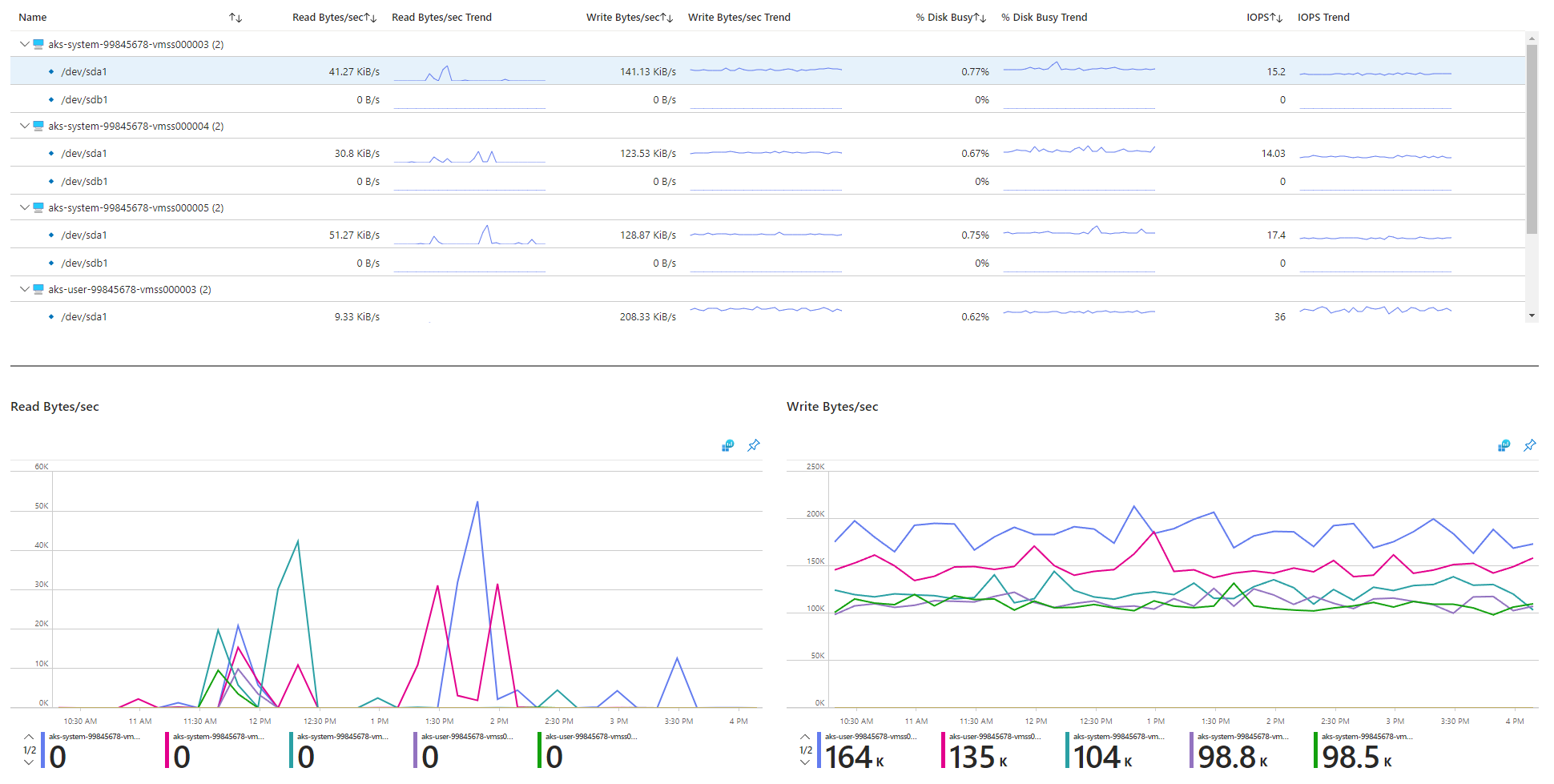
Projděte si metriky související s vstupně-výstupními operacemi.


Monitorování v clusteru pomocí nástroje Prometheus a Grafana
Pokud jste nasadili Nástroj Prometheus a Grafana v clusteru AKS, můžete pomocí řídicího panelu USE Method / Node získat přehled o vstupně-výstupních operacích disku pro pracovní uzly clusteru.

Monitorování spravované služby pro Prometheus a Azure Managed Grafana
Pomocí předem vytvořeného řídicího panelu exportéru uzlů nebo uzlů můžete vizualizovat a analyzovat metriky související s vstupně-výstupními operacemi disku z pracovních uzlů. K tomu musíte nastavit cluster AKS tak, aby shromažďuje metriky Prometheus ve spravované službě Monitor pro Prometheus a připojili pracovní prostor Monitoru k pracovnímu prostoru Azure Managed Grafana .

IOPS a disky Azure
Fyzická úložná zařízení mají svá omezení z hlediska šířky pásma a maximálního počtu operací se soubory, které dokážou zpracovat. Disky Azure slouží k ukládání operačního systému, který běží na uzlech AKS. Disky podléhají stejným omezením fyzického úložiště jako operační systém.
Představte si koncept propustnosti. Průměrnou velikost vstupně-výstupních operací můžete vynásobit IOPS a určit propustnost v megabajtech za sekundu (MB/s). Větší vstupně-výstupní operace se kvůli pevné propustnosti disku překládají na nižší počet vstupně-výstupních operací za sekundu.
Když úloha překročí maximální limity služby IOPS přiřazené k diskům Azure, může cluster přestat reagovat a zadat stav čekání na vstupně-výstupní operace. V linuxových systémech se mnoho komponent považuje za soubory, jako jsou síťové sokety, CNI, Docker a další služby, které jsou závislé na vstupně-výstupních operacích sítě. V důsledku toho, pokud disk nelze přečíst, selhání se rozšíří na všechny tyto soubory.
Několik událostíach
Velký počet kontejnerů, které běží na uzlech, protože vstupně-výstupní operace Dockeru sdílí disk s operačním systémem.
Vlastní nástroje nebo nástroje třetích stran používané pro zabezpečení, monitorování a protokolování, které můžou generovat další vstupně-výstupní operace na disku operačního systému.
Události převzetí služeb při selhání uzlů a pravidelné úlohy, které zvyšují zatížení nebo škálují počet podů. Tato zvýšená zátěž zvyšuje pravděpodobnost výskytů omezování, což může způsobit přechod všech uzlů do stavu, který není připravený , dokud neukončí vstupně-výstupní operace.
Přispěvatelé
Tento článek spravuje Microsoft. Původně byla napsána následujícími přispěvateli.
Hlavní autoři:
- Paul Salvatori | Hlavní zákaznický inženýr
- Francis Simy Nazareth | Vedoucí technický specialista
Pokud chcete zobrazit neveřejné profily LinkedIn, přihlaste se na LinkedIn.