Koordinuje akce prováděné kolekcí spolupracujících instancí v distribuované aplikaci. Zvolí jednu instanci jako vedoucí a ta potom přijme zodpovědnost za správu ostatních instancí. To vám pomůže předejít tomu, aby docházelo ke vzájemným konfliktům instancí, kolizím ve využívání sdílených prostředků nebo situacím, kdy jedna instance nedopatřením zasahuje do činnosti jiné instance.
Kontext a problém
Typická cloudová aplikace provádí koordinovaně celou řadu úloh. Všechny tyto úlohy můžou být instance, které spouštějí stejný kód a vyžadují přístup ke stejným prostředkům, nebo můžou běžet paralelně a provádět dílčí úkoly nějakého složitějšího výpočtu.
Instance úloh se můžou po většinu času spouštět samostatně, ale může být také nutné koordinovat akce jednotlivých instancí, aby se zajistilo, že nejsou v konfliktu, způsobí kolize pro sdílené prostředky nebo omylem zasahují do práce, kterou provádějí jiné instance úloh.
Příklad:
- V cloudovém systému, který implementuje horizontální škálování, může běžet současně více instancí stejné úlohy, kdy každá instance obsluhuje jiného uživatele. Pokud tyto instance zapisují do sdíleného prostředku, je potřeba koordinovat jejich akce, aby nedocházelo k tomu, že jedna instance bude přepisovat změny provedené jinou instancí.
- Pokud úlohy běží paralelně a každá provádí určitou část jednoho komplexního výpočtu, je potřeba po dokončení činnosti všech instancí agregovat výsledky.
Všechny instance úlohy jsou rovnocenné a žádná z nich neplní roli vedoucí instance, která by činnost všech ostatních koordinovala nebo provedla agregaci výsledků.
Řešení
Je potřeba určit jednu instanci úlohy jako vedoucí instanci, která bude koordinovat akce ostatních podřízených instancí. Pokud všechny instance úlohy spouštějí stejný kód, může vedoucí roli plnit kterákoli z nich. Proto musí být proces voleb spravován pečlivě, aby se zabránilo tomu, že dvě nebo více instancí převezme pozici vedoucího procesu současně.
Mechanismus zvolení vedoucí instance musí být robustní. Musí počítat s událostmi, jako je výpadek sítě nebo selhání procesu. V mnoha řešeních monitorují podřízené instance vedoucí instanci prostřednictvím prezenčního signálu nebo cyklického dotazování. Pokud činnost vedoucí instance úlohy neočekávaně skončí nebo je kvůli selhání sítě pro podřízené instance nedostupná, je nutné, aby tyto instance zvolily novou vedoucí instanci.
Existuje několik strategií pro výběr vedoucí skupiny úkolů v distribuovaném prostředí, mezi které patří:
- Získání sdíleného, distribuovaného vzájemně vyloučeného přístupu. První instance úlohy, která získá vzájemně vyloučený přístup, se stává vedoucí instancí. Systém však musí zajistit, aby se v případě, že vedoucí instance skončí nebo se odpojí od zbytku systému, vytvořil nový vzájemně vyloučený přístup, který umožní, že se vedoucí instancí může stát nová instance úlohy. Tato strategie je ukázaná v následujícím příkladu.
- Implementace jednoho z běžných algoritmů volby vedoucího programu, jako je Bully Algorithm, Raft Consensus Algorithm nebo Ring Algorithm. Tyto algoritmy předpokládají, že všichni kandidáti účastnící se volby mají jedinečné ID a že můžou spolehlivě komunikovat s ostatními kandidáty.
Problémy a důležité informace
Když se budete rozhodovat, jak tento model implementovat, měli byste vzít v úvahu následující skutečnosti:
- Proces volby vedoucí instance by měl být odolný vůči přechodným i trvalým chybám.
- Je potřeba implementovat proces, který zjistí, že vedoucí instance přestala fungovat nebo je z jiného důvodu nedostupná (například kvůli selhání komunikace). Jak rychle je potřeba nefunkčnost vedoucí instance zjistit, závisí na systému. Některé systémy dokážou fungovat krátce i bez vedoucího procesu a když se objeví přechodná chyba, může být opravena dřív, než to fungování systému nějak naruší. V jiných případech může být potřeba, aby bylo selhání vedoucí instance zjištěno okamžitě a aby ihned proběhla nová volba.
- V systému, který implementuje automatické horizontální škálování, může být vedoucí proces ukončen ve chvíli, kdy se obnoví původní škálování a ukončí se některé výpočetní prostředky.
- Při použití sdíleného, distribuovaného vzájemně vyloučeného přístupu se v externí službě, která vzájemně vyloučený přístup poskytuje, vytvoří závislost. Služba představuje kritický prvek způsobující selhání. Když bude z nějakého důvodu nedostupná, systém nebude moct zvolit vedoucí instanci.
- Jednoduchým řešením by bylo použít jeden vyhrazený vedoucí proces. Pokud ale takový proces selže, může dojít k poměrně dlouhodobému výpadku, než se opět restartuje. Způsobená latence může ovlivnit výkon a dobu odezvy dalších procesů, které můžou čekat, až vedoucí proces zkoordinuje určitou operaci.
- Nejvyšší flexibilitu pro ladění a optimalizaci kódu poskytuje ruční implementace jednoho z algoritmů volby vedoucího procesu.
- Předejděte tomu, aby se vedoucí proces stal kritickým bodem v systému. Účelem vedoucího je koordinovat práci podřízených úkolů a nemusí se nutně účastnit samotné práce – i když by to mělo být možné, pokud není úkol zvolen jako vedoucí.
Kdy se má tento model použít
Tento model použijte, pokud úlohy v distribuované aplikaci, například v řešeních hostovaných v cloudu, vyžadují pečlivou koordinaci a žádný proces není přirozeně vedoucí.
Tento model nebude pravděpodobně vhodný v následujících případech:
- Existuje přirozený nebo určený vedoucí proces, který může roli vedoucího procesu plnit vždycky. Například je možné implementovat jediný proces, který bude koordinovat instance úlohy. Pokud tento proces selže nebo je poškozen, systém ho může vypnout a restartovat.
- Koordinace úloh lze dosáhnout jednodušším způsobem. Například pokud je pouze potřeba koordinovat přístup několika instancí úlohy ke sdíleným prostředkům, je lepším řešením řízení přístupu pomocí optimistického nebo pesimistického zamykání.
- Řešení třetí strany, jako je Apache Zookeper , může být efektivnějším řešením.
Návrh úloh
Architekt by měl vyhodnotit způsob použití modelu volby leadera v návrhu úlohy k řešení cílů a principů zahrnutých v pilířích architektury Azure Well-Architected Framework. Příklad:
| Pilíř | Jak tento model podporuje cíle pilíře |
|---|---|
| Rozhodnutí o návrhu spolehlivosti pomáhají vaší úloze stát se odolnou proti selhání a zajistit, aby se po selhání obnovila do plně funkčního stavu. | Tento model zmírní účinek chybných funkcí uzlu tím, že spolehlivě přesměruje práci. Implementuje také převzetí služeb při selhání prostřednictvím algoritmů pro konsensus, když vedoucí funkce nefunguje. - RE:05 Redundance - RE:07 Samoopravení |
Stejně jako u jakéhokoli rozhodnutí o návrhu zvažte jakékoli kompromisy proti cílům ostatních pilířů, které by mohly být s tímto vzorem zavedeny.
Příklad
Ukázka volby leadera na GitHubu ukazuje, jak pomocí zapůjčení objektu blob služby Azure Storage poskytnout mechanismus pro implementaci sdíleného distribuovaného mutexu. Tento mutex lze použít k volbě vedoucího procesu mezi skupinou dostupných instancí pracovních procesů. První instance, která získá zapůjčení, je zvolena vedoucí instancí a zůstane vedoucí instancí, dokud neuvolní zapůjčení nebo nepůjde obnovit zapůjčení. Ostatní instance pracovních procesů můžou dál monitorovat zapůjčení objektů blob v případě, že vedoucí instance už nebudou k dispozici.
Zapůjčení objektu blob funguje u objektu blob jako výhradní zámek proti zápisu. Jeden objekt blob může být zapůjčen vždy jen jedné instanci. Instance pracovního procesu může požádat o zapůjčení zadaného objektu blob a udělí se zapůjčení, pokud žádná jiná instance pracovního procesu nemá zapůjčení nad stejným objektem blob. Jinak požadavek vyvolá výjimku.
Chcete-li zabránit selhání instance vedoucí instance zachování zapůjčení neomezeně dlouhou dobu, zadejte životnost zapůjčení. Když tato platnost vyprší, bude zapůjčení opět k dispozici. Zatímco však instance uchovává zapůjčení, může požádat o prodloužení zapůjčení a bude mu uděleno zapůjčení na další časové období. Instance vedoucí instance může tento proces průběžně opakovat, pokud chce zachovat zapůjčení. Další informace o způsobech zapůjčení objektu blob najdete v tématu Zapůjčení objektu blob (REST API).
Třída BlobDistributedMutex v příkladu jazyka C# níže obsahuje metodu RunTaskWhenMutexAcquired , která umožňuje instanci pracovního procesu pokusit se získat zapůjčení pro zadaný objekt blob. Podrobnosti o objektu blob (název, kontejner a účet úložiště) se předávají konstruktoru v objektu BlobSettings při vytvoření objektu BlobDistributedMutex (tento objekt je jednoduchá struktura, která je součástí ukázkového kódu). Konstruktor také přijímá Task odkaz na kód, který má instance pracovního procesu spustit, pokud úspěšně získá zapůjčení objektu blob a je zvolen vedoucí. Všimněte si, že kód, který zpracovává podrobnosti získání zapůjčení na nižší úrovni, je implementovaný v samostatné pomocné třídě BlobLeaseManager.
public class BlobDistributedMutex
{
...
private readonly BlobSettings blobSettings;
private readonly Func<CancellationToken, Task> taskToRunWhenLeaseAcquired;
...
public BlobDistributedMutex(BlobSettings blobSettings,
Func<CancellationToken, Task> taskToRunWhenLeaseAcquired, ... )
{
this.blobSettings = blobSettings;
this.taskToRunWhenLeaseAcquired = taskToRunWhenLeaseAcquired;
...
}
public async Task RunTaskWhenMutexAcquired(CancellationToken token)
{
var leaseManager = new BlobLeaseManager(blobSettings);
await this.RunTaskWhenBlobLeaseAcquired(leaseManager, token);
}
...
Metoda RunTaskWhenMutexAcquired v ukázkovém kódu výše vyvolá metodu RunTaskWhenBlobLeaseAcquired použitou v následujícím ukázkovém kódu, která provede samotné získání zapůjčení. Metoda RunTaskWhenBlobLeaseAcquired běží asynchronně. Pokud se zapůjčení úspěšně získá, byla instance pracovního procesu zvolena vedoucí instancí. Účelem delegáta taskToRunWhenLeaseAcquired je provést práci, která koordinuje ostatní instance pracovního procesu. Pokud není zapůjčení získáno, byla jako vedoucí zvolena jiná instance pracovního procesu a aktuální instance pracovního procesu zůstává podřízená. TryAcquireLeaseOrWait je pomocná metoda, která prostřednictvím objektu BlobLeaseManager získává zapůjčení.
private async Task RunTaskWhenBlobLeaseAcquired(
BlobLeaseManager leaseManager, CancellationToken token)
{
while (!token.IsCancellationRequested)
{
// Try to acquire the blob lease.
// Otherwise wait for a short time before trying again.
string? leaseId = await this.TryAcquireLeaseOrWait(leaseManager, token);
if (!string.IsNullOrEmpty(leaseId))
{
// Create a new linked cancellation token source so that if either the
// original token is canceled or the lease can't be renewed, the
// leader task can be canceled.
using (var leaseCts =
CancellationTokenSource.CreateLinkedTokenSource(new[] { token }))
{
// Run the leader task.
var leaderTask = this.taskToRunWhenLeaseAcquired.Invoke(leaseCts.Token);
...
}
}
}
...
}
Také úloha spuštěná vedoucí instancí běží asynchronně. Zatímco tato úloha běží, metoda RunTaskWhenBlobLeaseAcquired použitá v následujícím ukázkovém kódu se pravidelně pokouší zapůjčení obnovit. To pomáhá zajistit, aby instance pracovního procesu zůstala vedoucí instancí. V ukázkovém řešení je prodleva mezi žádostmi o obnovení kratší než doba určená pro dobu trvání zapůjčení, aby se zabránilo zvolení jiné instance pracovního procesu vedoucí instancí. Pokud obnovení z nějakého důvodu selže, úloha specifická pro vedoucí úkol se zruší.
Pokud se zapůjčení nepodaří obnovit nebo se úloha zruší (pravděpodobně v důsledku vypnutí instance pracovního procesu), zapůjčení se uvolní. V tuto chvíli lze tuto nebo jinou instanci pracovního procesu zvolit jako vedoucí instanci. Úryvek kódu níže demonstruje tuto část procesu.
private async Task RunTaskWhenBlobLeaseAcquired(
BlobLeaseManager leaseManager, CancellationToken token)
{
while (...)
{
...
if (...)
{
...
using (var leaseCts = ...)
{
...
// Keep renewing the lease in regular intervals.
// If the lease can't be renewed, then the task completes.
var renewLeaseTask =
this.KeepRenewingLease(leaseManager, leaseId, leaseCts.Token);
// When any task completes (either the leader task itself or when it
// couldn't renew the lease) then cancel the other task.
await CancelAllWhenAnyCompletes(leaderTask, renewLeaseTask, leaseCts);
}
}
}
}
...
}
KeepRenewingLease je další pomocná metoda, která prostřednictvím objektu BlobLeaseManager obnovuje zapůjčení. Metoda CancelAllWhenAnyCompletes zruší úlohy určené prvními dvěma parametry. Následující diagram znázorňuje použití třídy BlobDistributedMutex ke zvolení vedoucí instance a spuštění úlohy, která koordinuje operace.
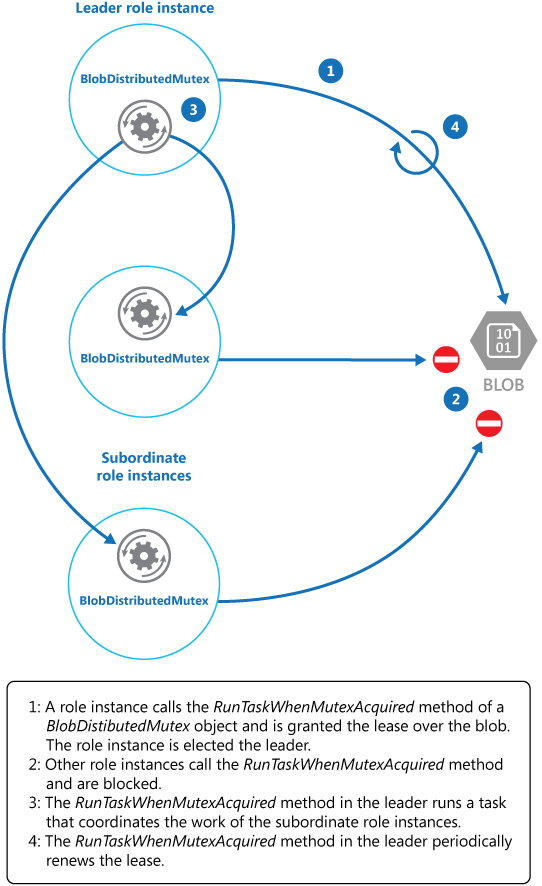
Následující příklad kódu ukazuje, jak používat BlobDistributedMutex třídu v rámci instance pracovního procesu. Tento kód získá zapůjčení objektu blob pojmenovaného MyLeaderCoordinatorTask v kontejneru zapůjčení Azure Blob Storage a určí, že kód definovaný v MyLeaderCoordinatorTask metodě by se měl spustit, pokud je instance pracovního procesu zvolena vedoucí instancí.
// Create a BlobSettings object with the connection string or managed identity and the name of the blob to use for the lease
BlobSettings blobSettings = new BlobSettings(storageConnStr, "leases", "MyLeaderCoordinatorTask");
// Create a new BlobDistributedMutex object with the BlobSettings object and a task to run when the lease is acquired
var distributedMutex = new BlobDistributedMutex(
blobSettings, MyLeaderCoordinatorTask);
// Wait for completion of the DistributedMutex and the UI task before exiting
await distributedMutex.RunTaskWhenMutexAcquired(cancellationToken);
...
// Method that runs if the worker instance is elected the leader
private static async Task MyLeaderCoordinatorTask(CancellationToken token)
{
...
}
Několik poznámek k ukázkovému řešení:
- Objekt blob je potenciální kritický prvek způsobující selhání. Pokud se služba Blob Service stane nedostupnou nebo je nedostupná, nebude vedoucí moct obnovit zapůjčení a nebude moct získat zapůjčení žádná jiná instance pracovního procesu. V tomto případě nebude moct žádná instance pracovního procesu fungovat jako vedoucí instance. Služba objektů blob je však navržená jako odolné řešení, takže její úplné selhání se považuje za extrémně nepravděpodobné.
- Pokud se úkol prováděný vedoucími zastavuje, vedoucí může pokračovat v obnovení zapůjčení, aby zabránil jakékoli jiné instanci pracovního procesu v získání zapůjčení a převzetí pozice vedoucího procesu za účelem koordinace úkolů. V ostrém provozu je potřeba stav vedoucí instance pravidelně kontrolovat.
- Proces volby je nedeterministický. Nemůžete provést žádné předpoklady o tom, která instance pracovního procesu získá zapůjčení objektu blob a stane se vedoucí instancí.
- Objekt blob používaný jako cíl zapůjčení objektu blob není vhodné používat k žádnému jinému účelu. Pokud se instance pracovního procesu pokusí uložit data v tomto objektu blob, nebudou tato data přístupná, pokud instance pracovního procesu není vedoucí instancí a uchovává zapůjčení objektu blob.
Další kroky
Při implementaci tohoto modelu můžou být relevantní také následující pokyny:
- Součástí tohoto modelu je ukázková aplikace ke stažení.
- Pokyny k automatickému škálování: Je možné spouštět a ukončovat instance hostitelů úlohy v závislosti na tom, jak se mění zatížení aplikace. Automatické škálování může usnadnit udržování propustnosti a výkonu zpracování v obdobích špičky.
- Asynchronní vzor založený na úlohách.
- Příklad ilustrující bully algoritmus.
- Příklad ilustrující ring algoritmus.
- Apache Curator – klientská knihovna pro Apache ZooKeeper.
- Článek Zapůjčení objektu blob (REST API) na webu MSDN.