Tento článek popisuje, jak vývojový tým použil metriky k nalezení kritických bodů a zlepšení výkonu distribuovaného systému. Článek je založený na skutečném zátěžovém testování, které jsme provedli pro ukázkovou aplikaci. Aplikace pochází ze standardního plánu Azure Kubernetes Service (AKS) pro mikroslužby.
Tento článek je součástí série článků. První část si můžete přečíst tady.
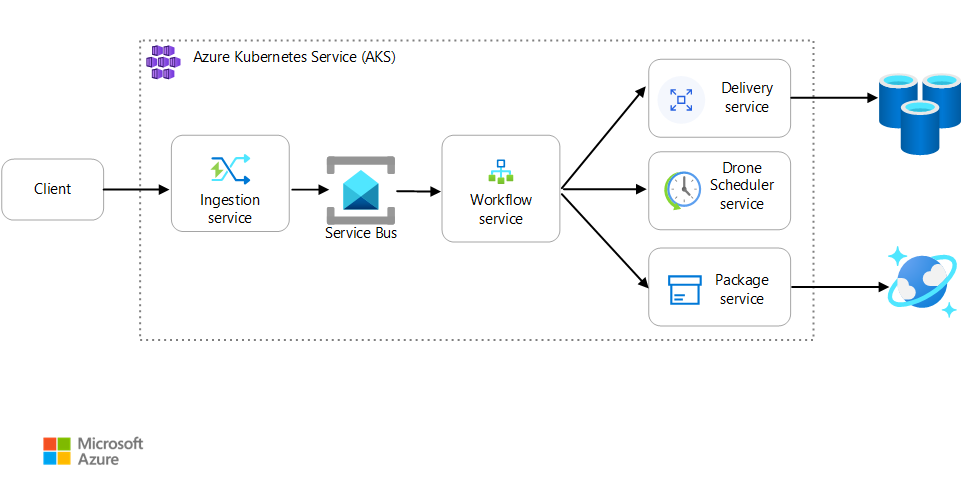
Scénář: Klientská aplikace zahájí obchodní transakci, která zahrnuje více kroků.
Tento scénář zahrnuje aplikaci pro doručování pomocí dronů, která běží v AKS. Zákazníci používají webovou aplikaci k plánování dodávek pomocí dronů. Každá transakce vyžaduje několik kroků, které provádí samostatné mikroslužby na back-endu:
- Doručení se stará o doručení.
- Služba Drone Scheduler plánuje vyzvednutí dronů.
- Balíčky spravuje služba Package Service.
Existují dvě další služby: Služba příjmu dat, která přijímá požadavky klientů a umístí je do fronty pro zpracování, a služba pracovního postupu, která koordinuje kroky v pracovním postupu.
Další informace o tomto scénáři najdete v tématu Návrh architektury mikroslužeb.
Test 1: Směrný plán
Pro první zátěžový test tým vytvořil cluster AKS se šesti uzly a nasadil tři repliky každé mikroslužby. Zátěžový test byl krokový zátěžový test, který začínal u dvou simulovaných uživatelů a postupně se zvýšil až na 40 simulovaných uživatelů.
| Nastavení | Hodnota |
|---|---|
| Uzly clusteru | 6 |
| Lusky | 3 na službu |
Následující graf ukazuje výsledky zátěžového testu, jak je znázorněno v sadě Visual Studio. Fialová čára vykreslí uživatelské zatížení a oranžová čára vykreslí celkový počet požadavků.
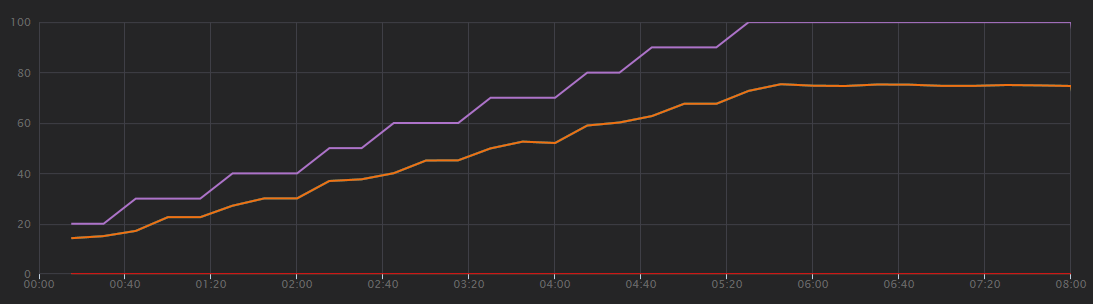
První věc, kterou je potřeba si uvědomit o tomto scénáři, je, že požadavky klientů za sekundu nejsou užitečnou metrikou výkonu. Je to proto, že aplikace zpracovává požadavky asynchronně, takže klient dostane odpověď okamžitě. Kód odpovědi je vždy HTTP 202 (Přijato), což znamená, že požadavek byl přijat, ale zpracování není dokončeno.
Ve skutečnosti chceme vědět, jestli back-end drží krok s frekvencí požadavků. Fronta služby Service Bus může absorbovat špičky, ale pokud back-end nedokáže zvládnout trvalé zatížení, zpracování bude dál a dál zaostává.
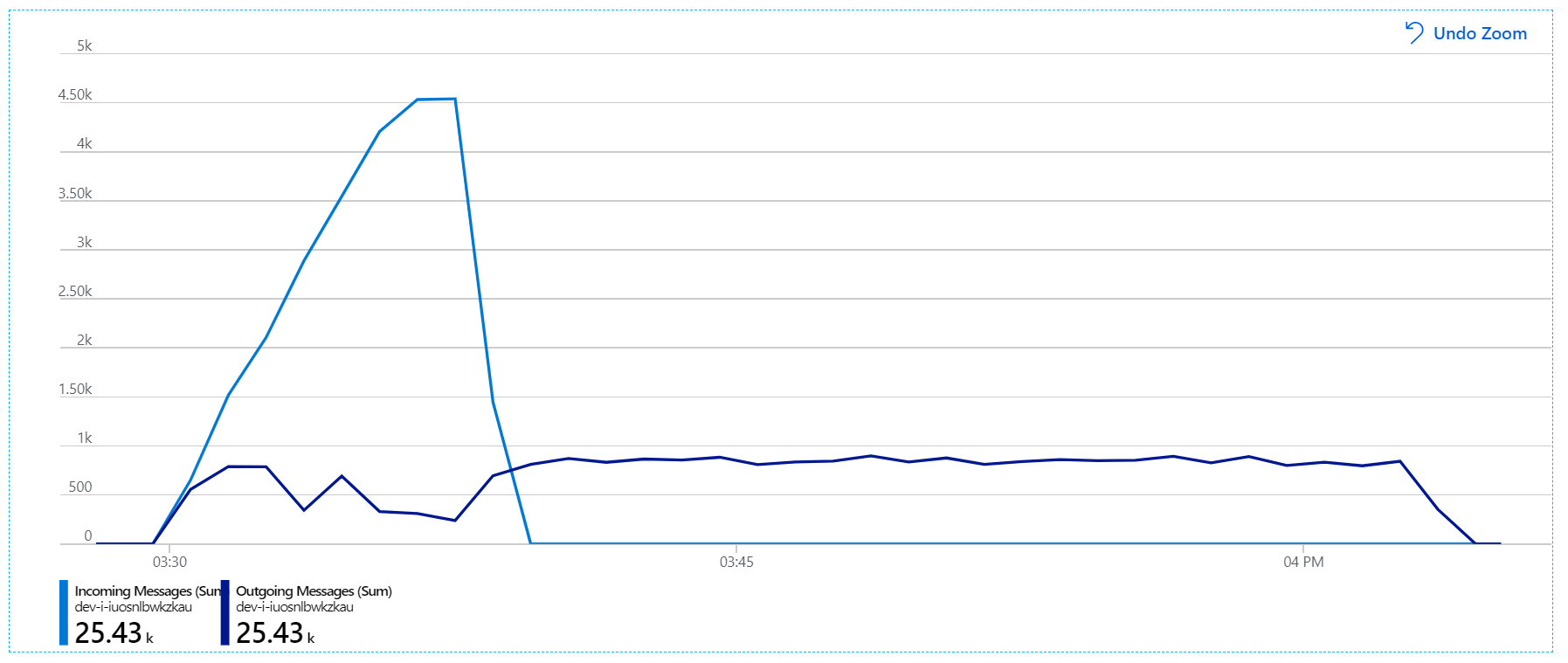
Tady je informativní graf. Vykreslí počet příchozích a odchozích zpráv ve frontě služby Service Bus. Příchozí zprávy se zobrazují světle modře a odchozí zprávy tmavě modré:
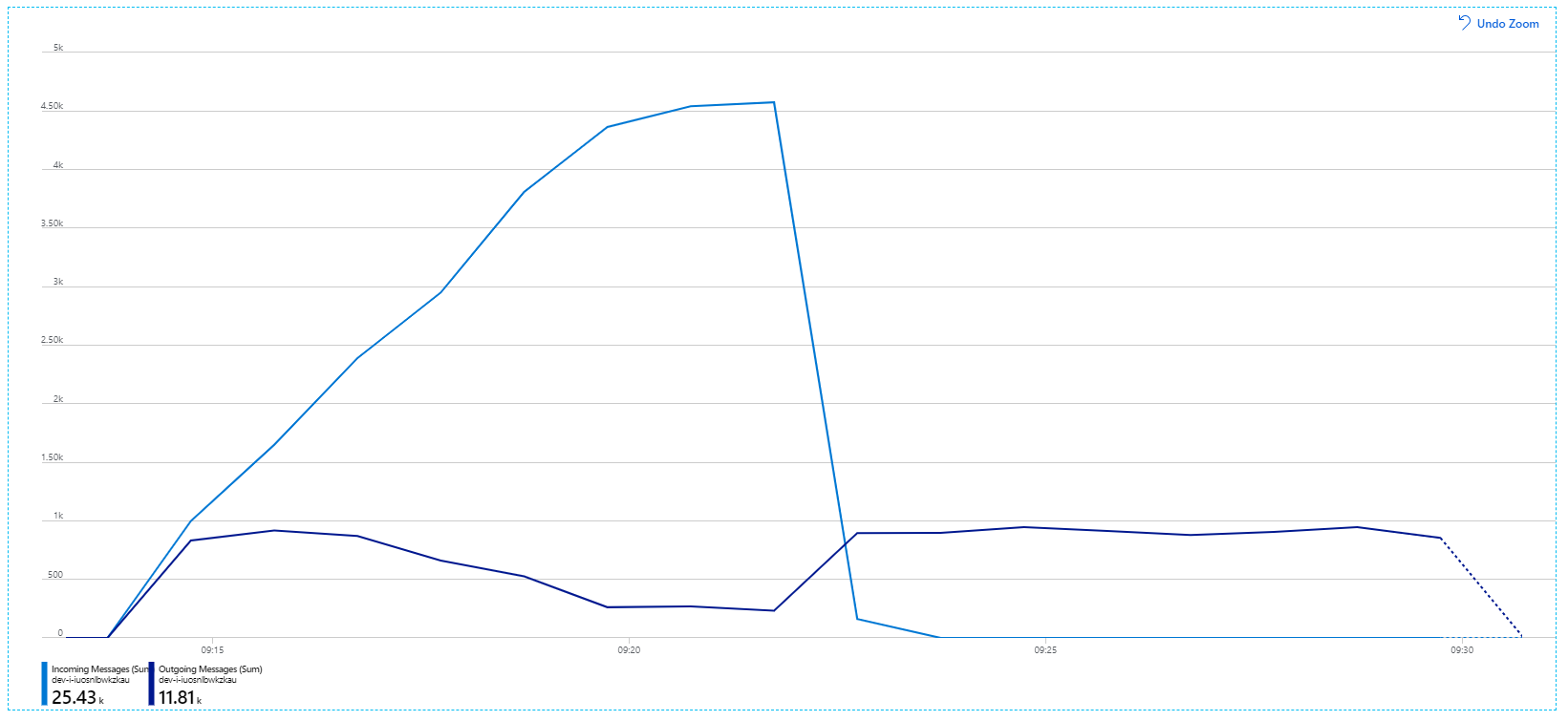
Tento graf ukazuje, že rychlost příchozích zpráv se zvyšuje, dosáhne vrcholu a na konci zátěžového testu klesne zpět na nulu. Počet odchozích zpráv ale v rané fázi testu vrcholí a pak ve skutečnosti klesá. To znamená, že služba pracovního postupu, která zpracovává požadavky, neudržuje krok. I po skončení zátěžového testu (přibližně 9:22 v grafu) se zprávy stále zpracovávají, protože služba pracovního postupu pokračuje vyprázdnění fronty.
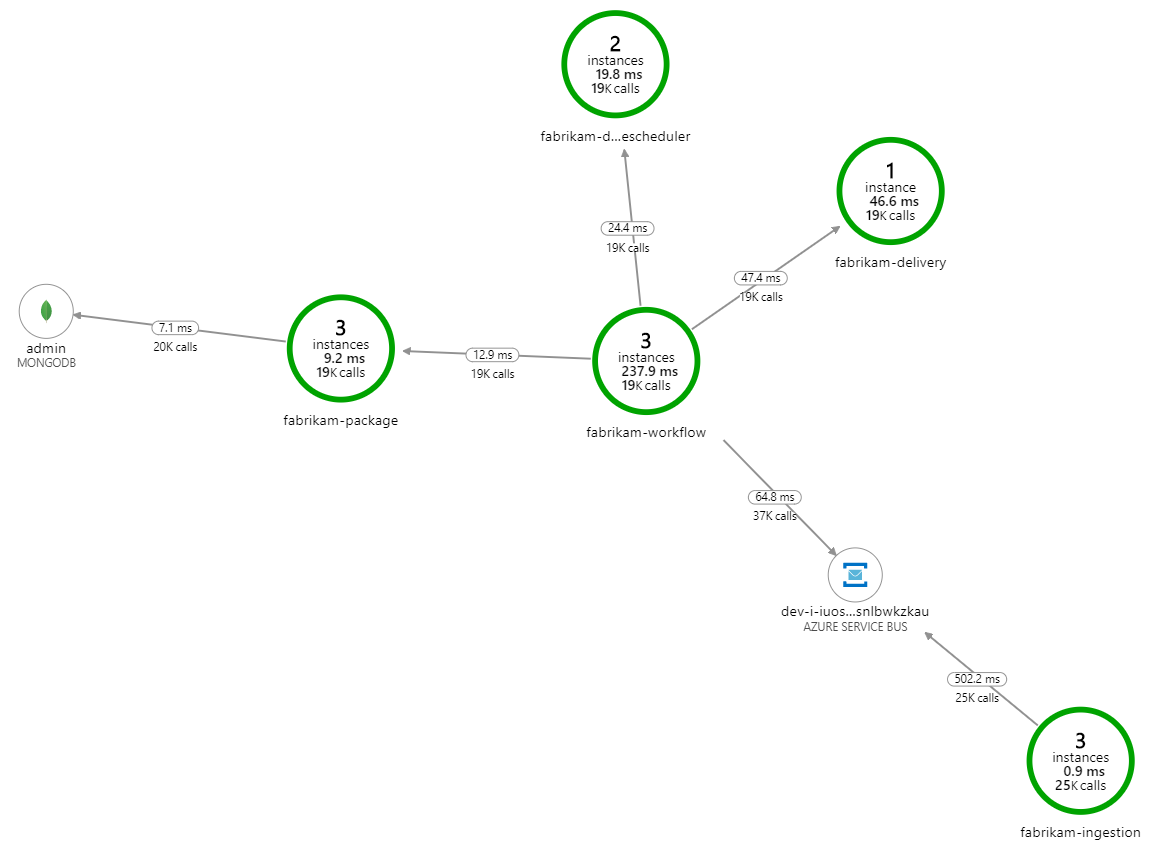
Co zpomaluje zpracování? První věc, kterou je potřeba hledat, jsou chyby nebo výjimky, které můžou značit systémový problém. Mapa aplikace ve službě Azure Monitor zobrazuje graf volání mezi komponentami a představuje rychlý způsob, jak odhalit problémy a pak kliknutím získat další podrobnosti.
Mapa aplikace jasně ukazuje, že služba pracovního postupu dostává chyby ze služby Delivery Service:
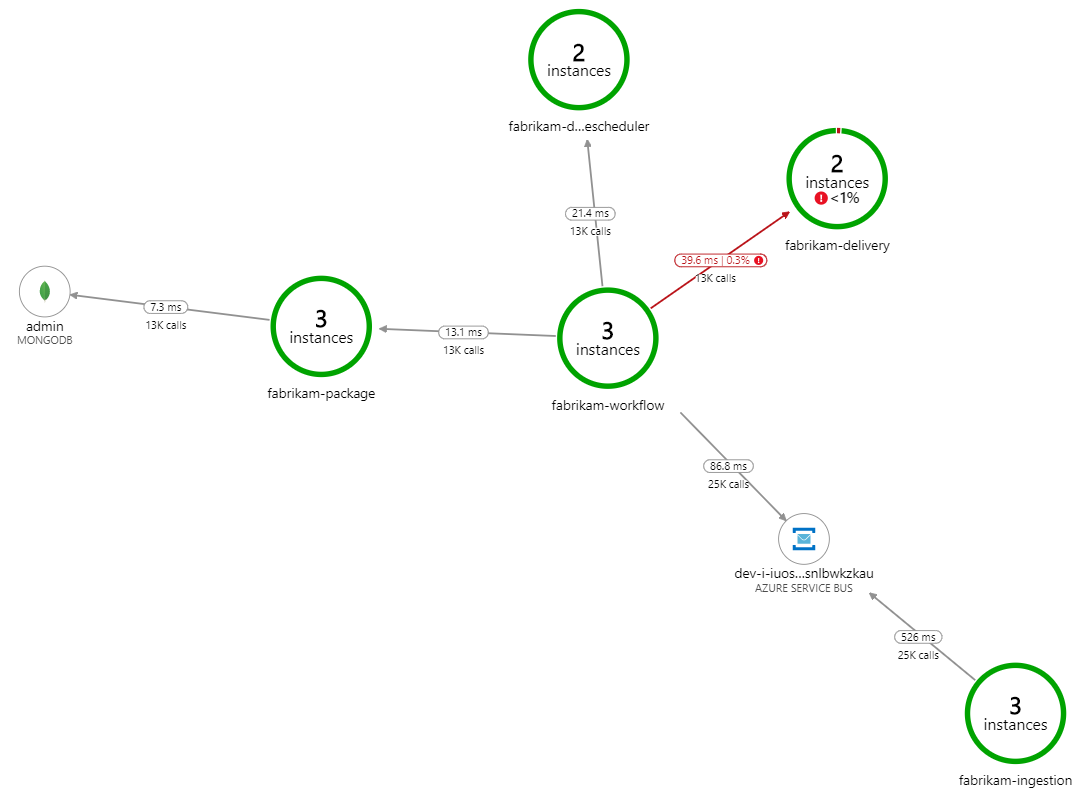
Pokud chcete zobrazit další podrobnosti, můžete vybrat uzel v grafu a kliknout do kompletního zobrazení transakcí. V tomto případě to ukazuje, že služba doručování vrací chyby HTTP 500. Chybové zprávy indikují, že dochází k výjimce kvůli omezením paměti v Azure Cache for Redis.
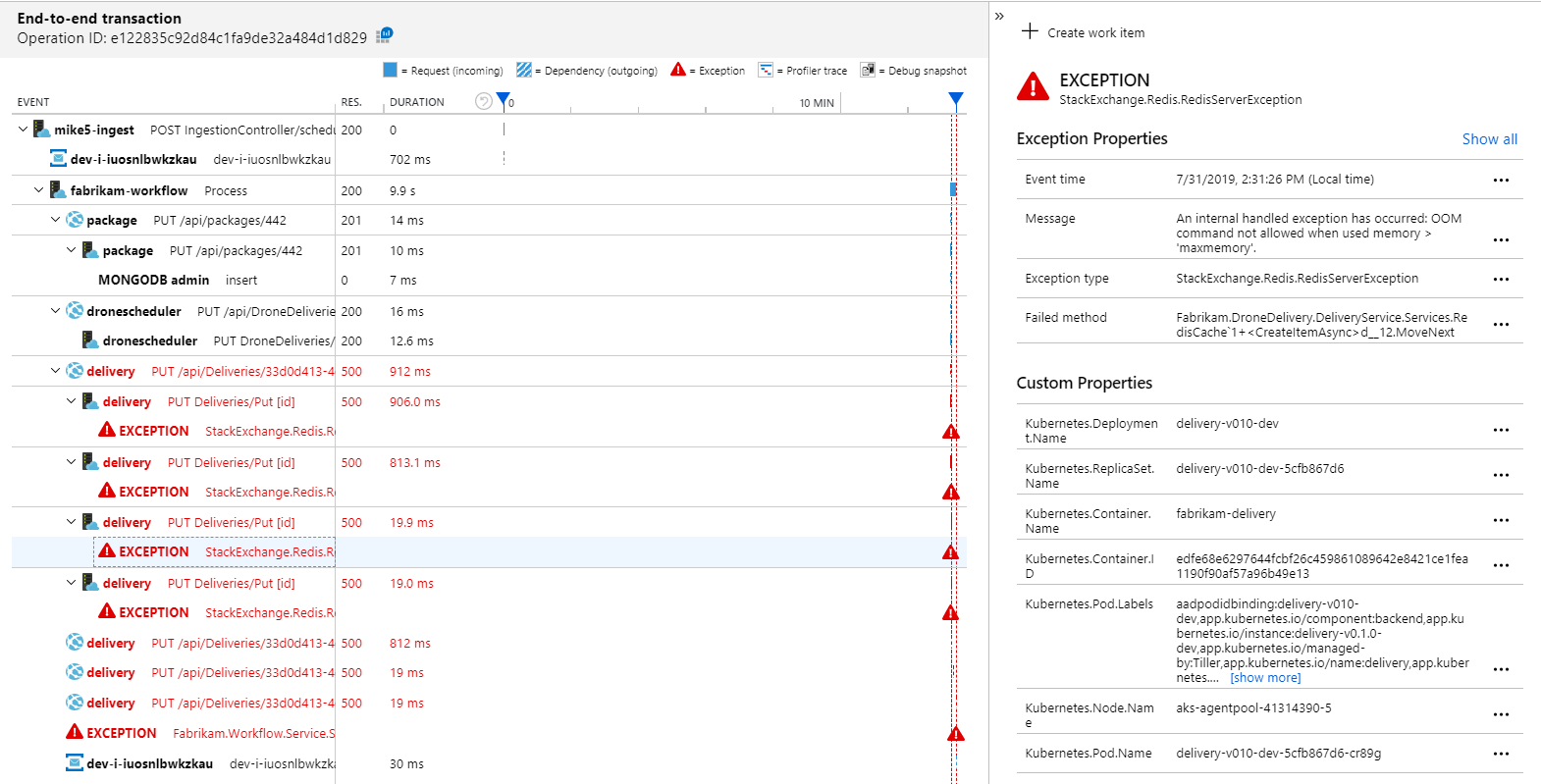
Můžete si všimnout, že se tato volání Redis nezobrazují v mapě aplikace. Je to proto, že knihovna .NET pro Application Insights nemá integrovanou podporu sledování Redis jako závislosti. (Seznam podporovaných položek najdete v tématu Automatické shromažďování závislostí.) Jako záložní řešení můžete ke sledování jakékoli závislosti použít rozhraní API TrackDependency . Zátěžové testování často odhalí tyto druhy mezer v telemetrii, které je možné napravit.
Test 2: Větší velikost mezipaměti
Pro druhý zátěžový test vývojový tým zvětšil velikost mezipaměti v Azure Cache for Redis. (Viz Postup škálování Azure Cache for Redis.) Tato změna vyřešila výjimky kvůli nedostatku paměti a mapa aplikace teď zobrazuje nulové chyby:
Stále však dochází k výrazné prodlevě při zpracování zpráv. Na vrcholu zátěžového testu je rychlost příchozích zpráv vyšší než 5× rychlost odchozích zpráv:
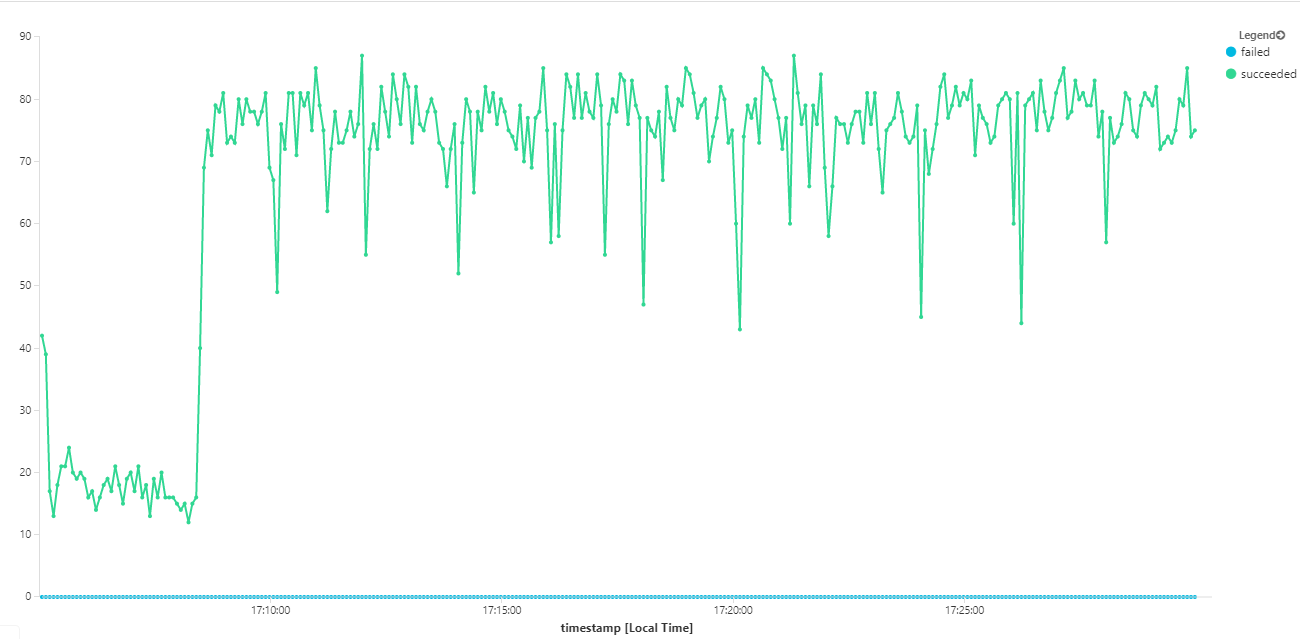
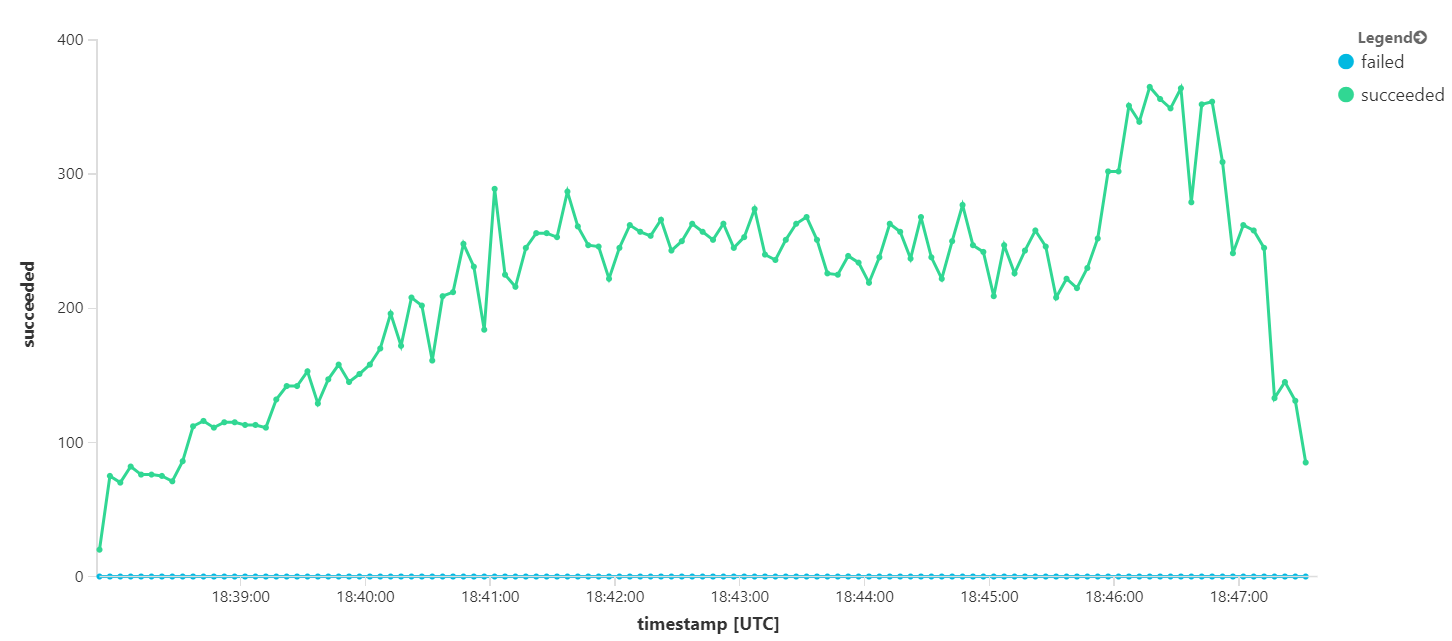
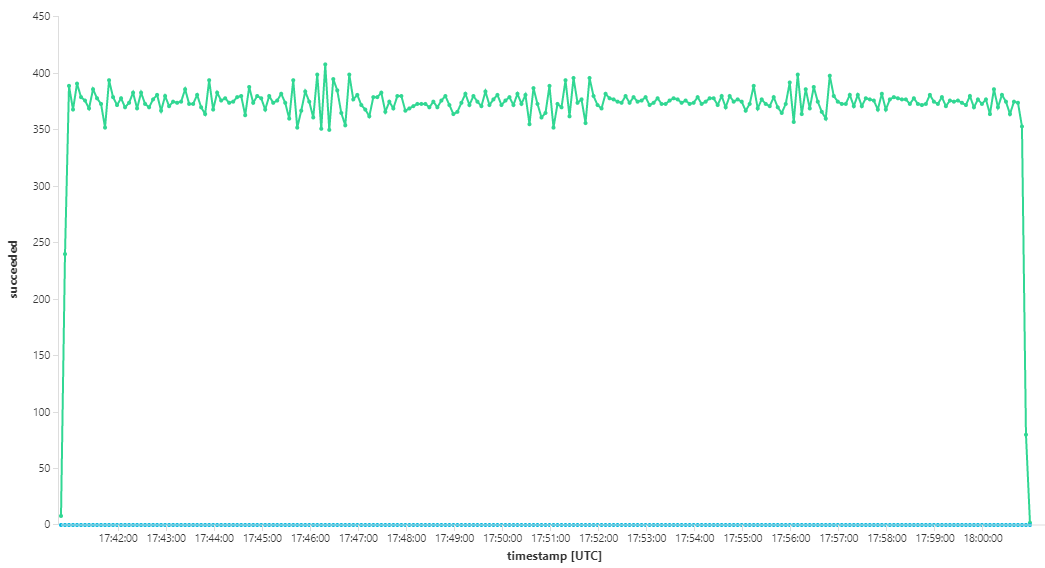
Následující graf měří propustnost z hlediska dokončování zpráv – tedy rychlost, s jakou služba pracovního postupu označí zprávy Service Bus jako dokončené. Každý bod v grafu představuje 5 sekund dat s maximální propustností ~16/s.
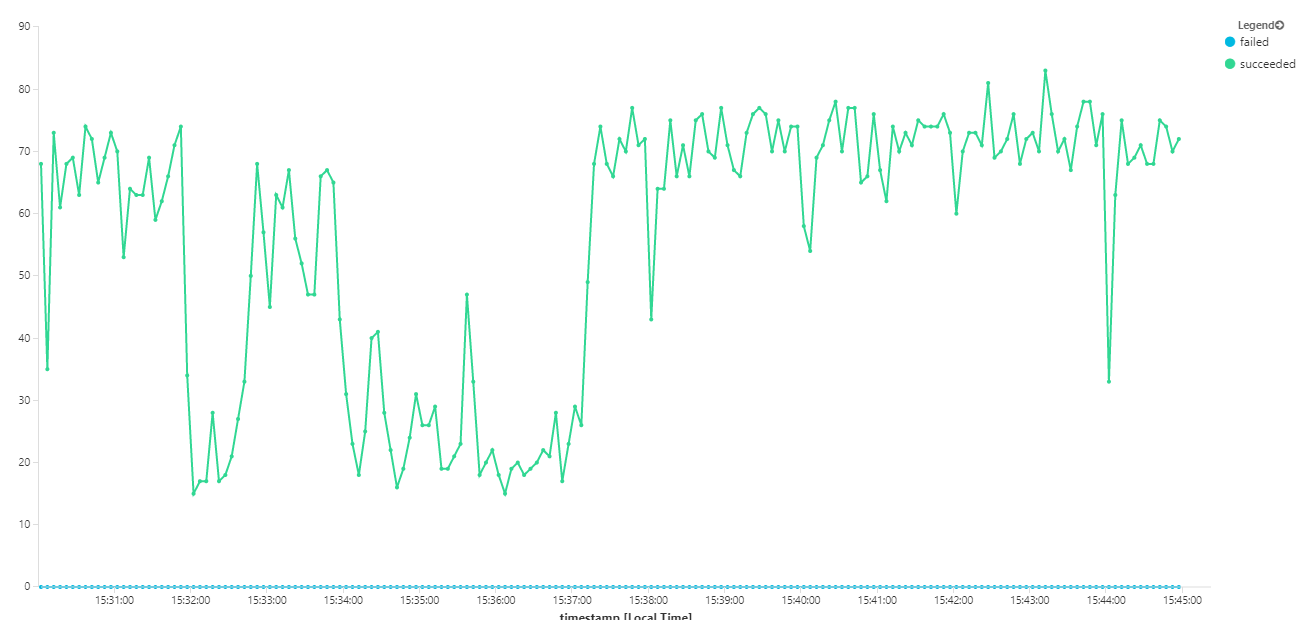
Tento graf se vygeneroval spuštěním dotazu v pracovním prostoru služby Log Analytics pomocí dotazovacího jazyka Kusto:
let start=datetime("2020-07-31T22:30:00.000Z");
let end=datetime("2020-07-31T22:45:00.000Z");
dependencies
| where cloud_RoleName == 'fabrikam-workflow'
| where timestamp > start and timestamp < end
| where type == 'Azure Service Bus'
| where target has 'https://dev-i-iuosnlbwkzkau.servicebus.windows.net'
| where client_Type == "PC"
| where name == "Complete"
| summarize succeeded=sumif(itemCount, success == true), failed=sumif(itemCount, success == false) by bin(timestamp, 5s)
| render timechart
Test 3: Horizontální navýšení kapacity back-endových služeb
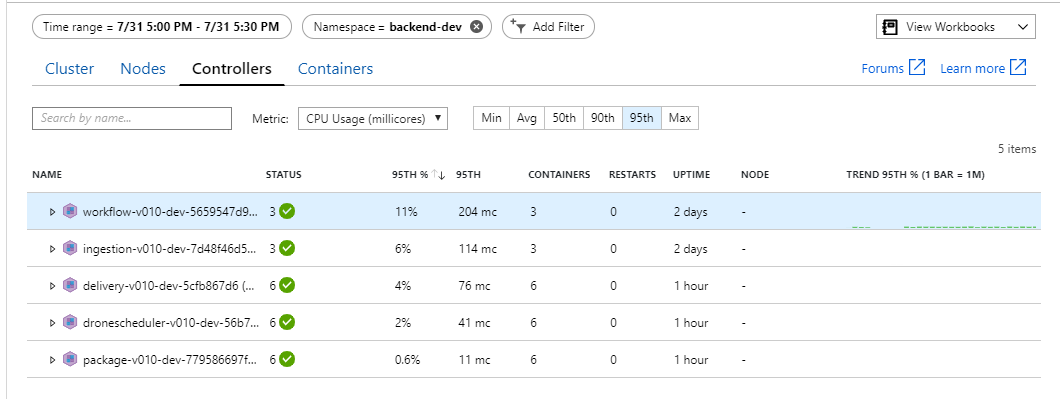
Zdá se, že kritickým bodem je back-end. Dalším snadným krokem je horizontální navýšení kapacity obchodních služeb (Package, Delivery a Drone Scheduler) a zjistit, jestli se propustnost zlepší. Pro další zátěžový test tým škáloval tyto služby ze tří replik na šest replik.
| Nastavení | Hodnota |
|---|---|
| Uzly clusteru | 6 |
| Služba příjmu dat | 3 repliky |
| Služba pracovního postupu | 3 repliky |
| Balíčky, doručení, služby plánovače dronů | Po 6 replikách |
Tento zátěžový test bohužel ukazuje jen mírné zlepšení. Odchozí zprávy stále nedrží krok s příchozími zprávami:
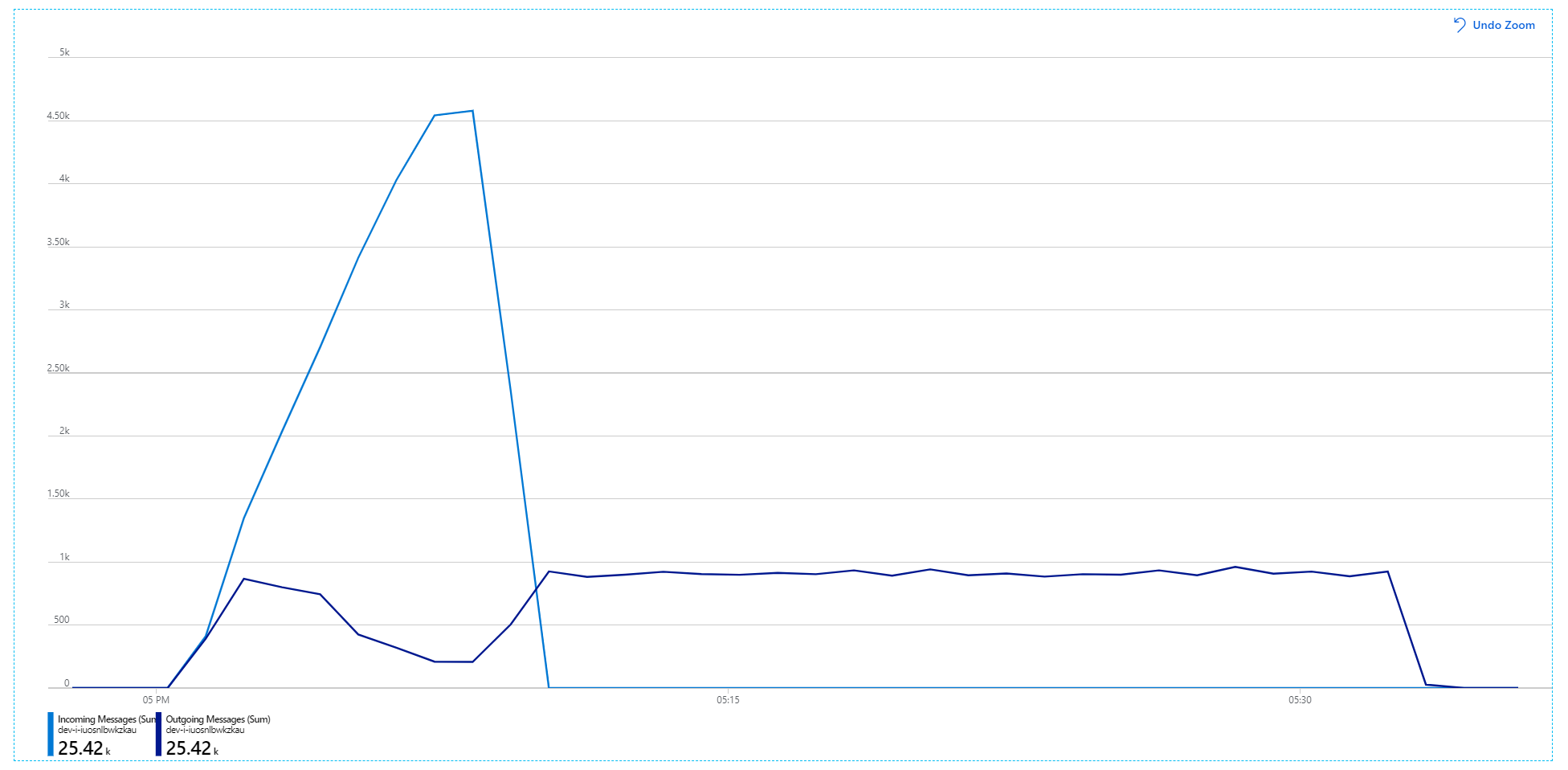
Propustnost je konzistentnější, ale maximální dosažená hodnota je přibližně stejná jako u předchozího testu:
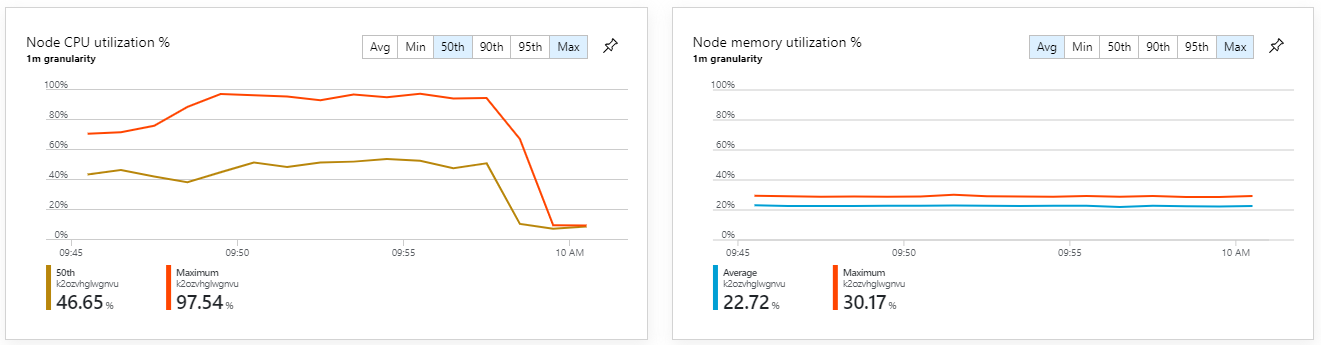
Při pohledu na přehledy kontejnerů služby Azure Monitor se navíc zdá, že příčinou problému není vyčerpání prostředků v rámci clusteru. Za prvé metriky na úrovni uzlů ukazují, že využití procesoru zůstává pod 40 % i na 95. percentilu a využití paměti je přibližně 20 %.
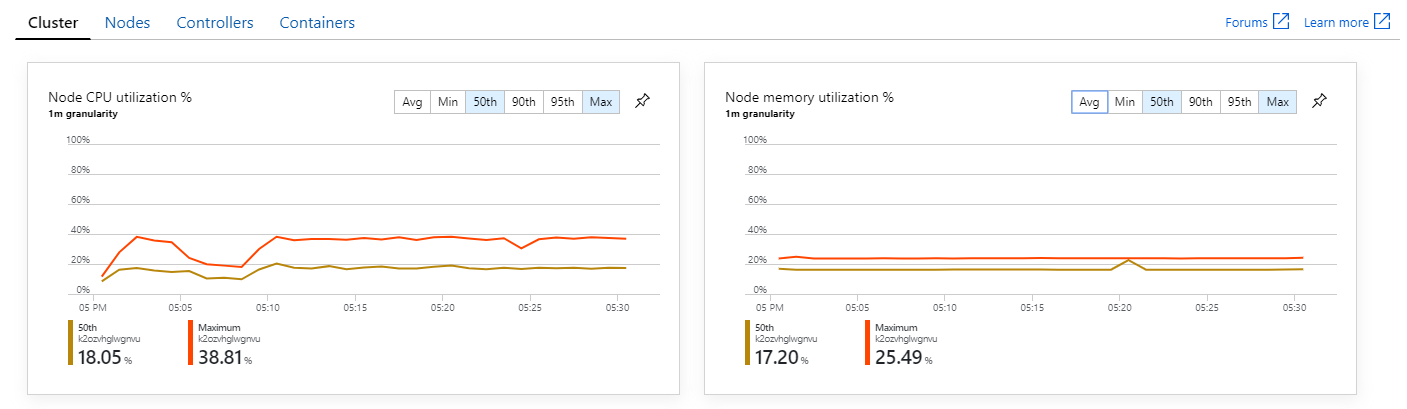
V prostředí Kubernetes je možné, aby jednotlivé pody byly omezené prostředky, i když uzly nejsou. Zobrazení na úrovni podů ale ukazuje, že všechny pody jsou v pořádku.
Z tohoto testu se zdá, že pouhé přidání dalších podů do back-endu nepomůže. V dalším kroku se podrobněji podíváme na službu Pracovního postupu, abyste pochopili, co se děje při zpracování zpráv. Application Insights ukazuje, že průměrná doba trvání operace služby Process pracovního postupu je 246 ms.
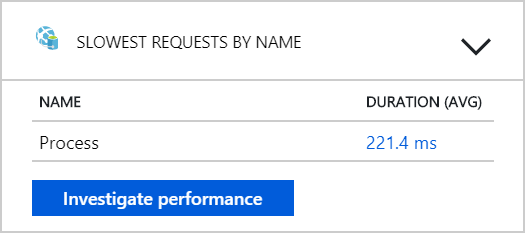
Můžeme také spustit dotaz, abychom získali metriky pro jednotlivé operace v rámci každé transakce:
| Cíl | percentile_duration_50 | percentile_duration_95 |
|---|---|---|
https://dev-i-iuosnlbwkzkau.servicebus.windows.net/ | dev-i-iuosnlbwkzkau |
86.66950203 | 283.4255578 |
| Dodávky | 37 | 57 |
| package | 12 | 17 |
| dronescheduler | 21 | 41 |
První řádek v této tabulce představuje frontu služby Service Bus. Ostatní řádky jsou volání back-endových služeb. Pro referenci najdete dotaz Log Analytics pro tuto tabulku:
let start=datetime("2020-07-31T22:30:00.000Z");
let end=datetime("2020-07-31T22:45:00.000Z");
let dataset=dependencies
| where timestamp > start and timestamp < end
| where (cloud_RoleName == 'fabrikam-workflow')
| where name == 'Complete' or target in ('package', 'delivery', 'dronescheduler');
dataset
| summarize percentiles(duration, 50, 95) by target
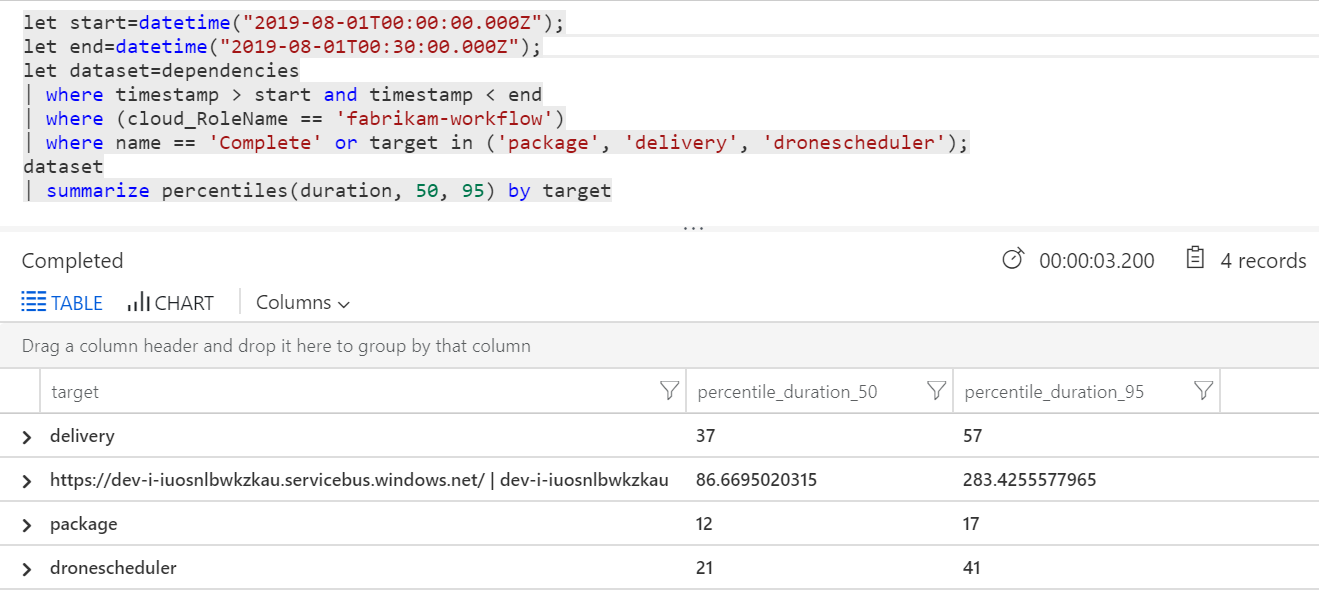
Tyto latence vypadají rozumně. Tady je ale klíčový přehled: Pokud je celková doba operace ~250 ms, znamená to naprostou horní hranici toho, jak rychle se zprávy dají zpracovávat sériově. Klíčem ke zlepšení propustnosti je proto větší paralelismus.
V tomto scénáři by to mělo být možné ze dvou důvodů:
- Jedná se o síťová volání, takže většinu času stráví čekáním na dokončení vstupně-výstupních operací.
- Zprávy jsou nezávislé a nemusí se zpracovávat v pořadí.
Test 4: Zvýšení paralelismu
V tomto testu se tým zaměřil na zvýšení paralelismu. Aby to udělali, upravili dvě nastavení v klientovi Service Bus používaném službou pracovního postupu:
| Nastavení | Popis | Výchozí | Nová hodnota |
|---|---|---|---|
MaxConcurrentCalls |
Maximální počet zpráv, které se mají zpracovávat současně. | 1 | 20 |
PrefetchCount |
Kolik zpráv klient předem načte do místní mezipaměti. | 0 | 3000 |
Další informace o těchto nastaveních najdete v tématu Osvědčené postupy pro zvýšení výkonu pomocí zasílání zpráv služby Service Bus. Spuštěním testu s těmito nastaveními se vytvoří následující graf:
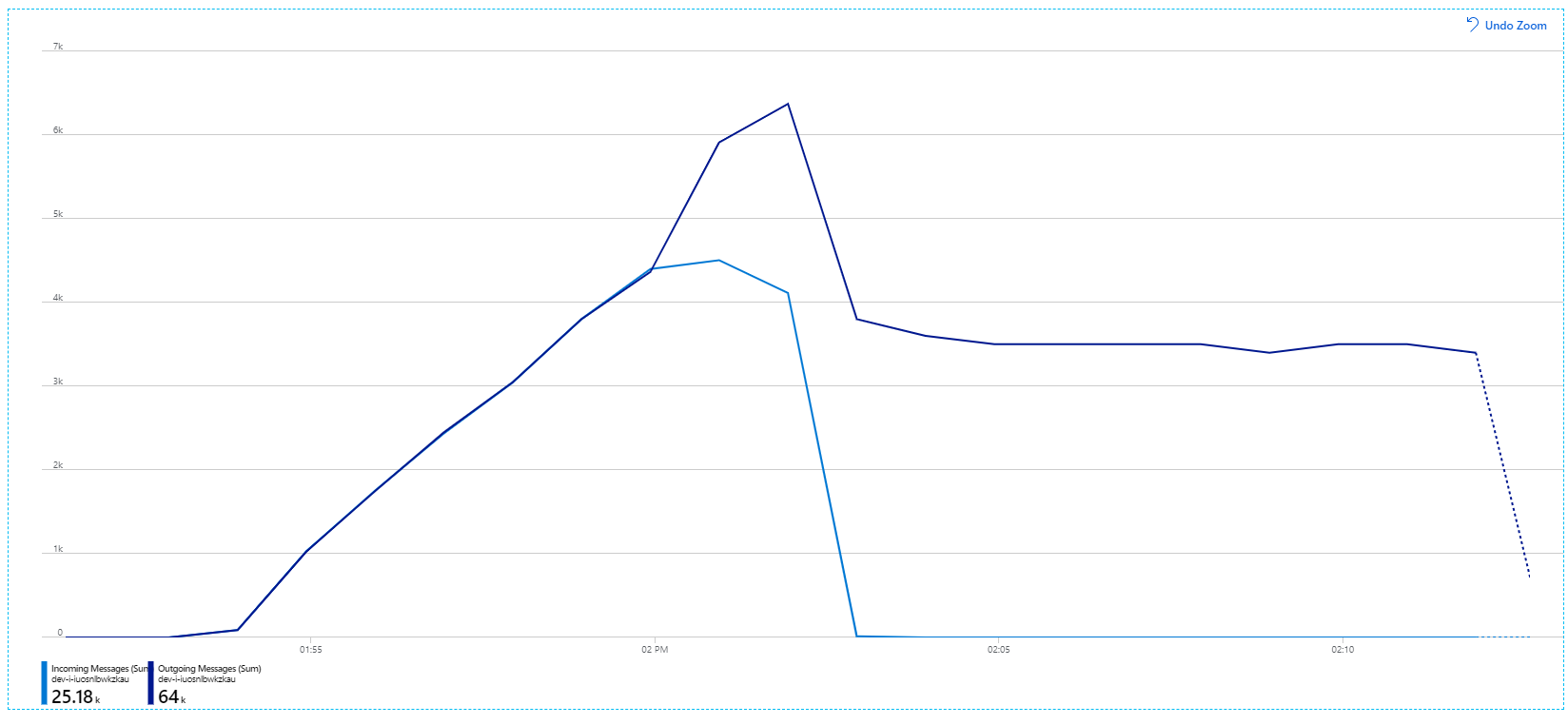
Vzpomeňte si, že příchozí zprávy se zobrazují světle modře a odchozí zprávy tmavě modré.
Na první pohled je to velmi divný graf. Míra odchozích zpráv na chvíli přesně sleduje příchozí rychlost. Ale pak, přibližně ve 2:03, míra příchozích zpráv se vyrovná, zatímco počet odchozích zpráv stále roste, ve skutečnosti překračuje celkový počet příchozích zpráv. To se zdá nemožné.
Vodítko k této záhadě najdete v zobrazení Závislosti v Application Insights. Tento graf shrnuje všechna volání, která služba pracovního postupu provedla ve službě Service Bus:
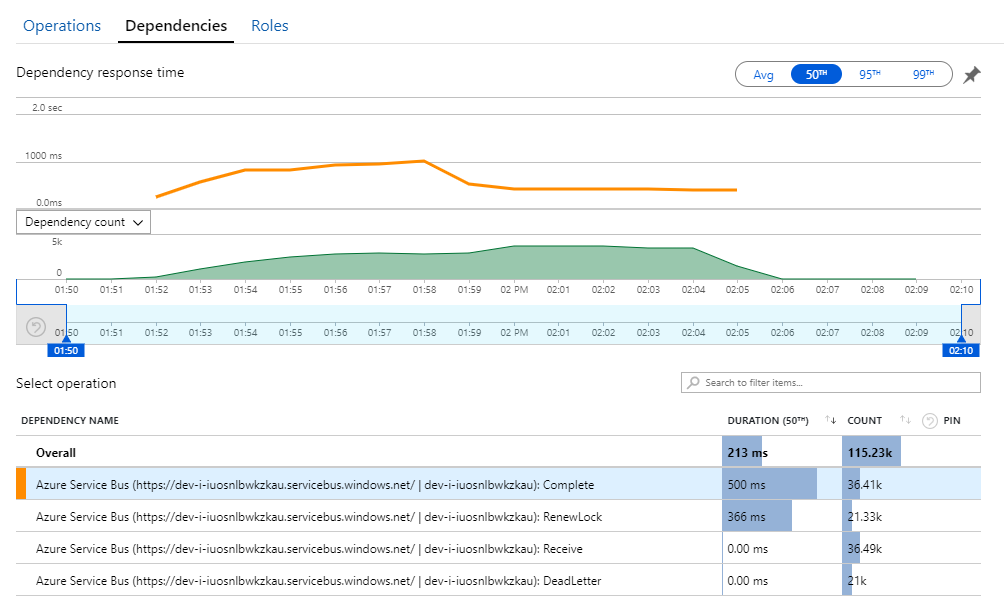
Všimněte si, že položka pro DeadLetter. Tato volání značí, že zprávy přijdou do fronty nedoručených zpráv služby Service Bus.
Abyste pochopili, co se děje, potřebujete porozumět sémantice Peek-Lock ve službě Service Bus. Když klient použije Peek-Lock, Service Bus zprávu načte a uzamkne. Během uzamčení je zaručeno, že zpráva nebude doručena ostatním příjemcům. Pokud zámek vyprší, bude zpráva k dispozici ostatním příjemcům. Po maximálním počtu pokusů o doručení (který je konfigurovatelný) služba Service Bus umístí zprávy do fronty nedoručených zpráv, kde je můžete později prozkoumat.
Mějte na paměti, že služba Pracovního postupu předem načítá velké dávky zpráv – 3 000 zpráv najednou). To znamená, že celková doba zpracování každé zprávy je delší, což vede k vypršení časového limitu zpráv, návratu zpět do fronty a nakonec k přechodu do fronty nedoručených zpráv.
Toto chování můžete vidět také ve výjimkách, kde se zaznamenává mnoho MessageLostLockException výjimek:
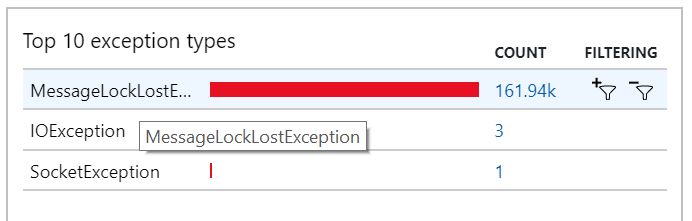
Test 5: Prodloužení doby trvání zámku
Pro tento zátěžový test byla doba trvání uzamčení zpráv nastavena na 5 minut, aby se zabránilo vypršení časových limitů uzamčení. Graf příchozích a odchozích zpráv teď ukazuje, že systém drží krok s rychlostí příchozích zpráv:
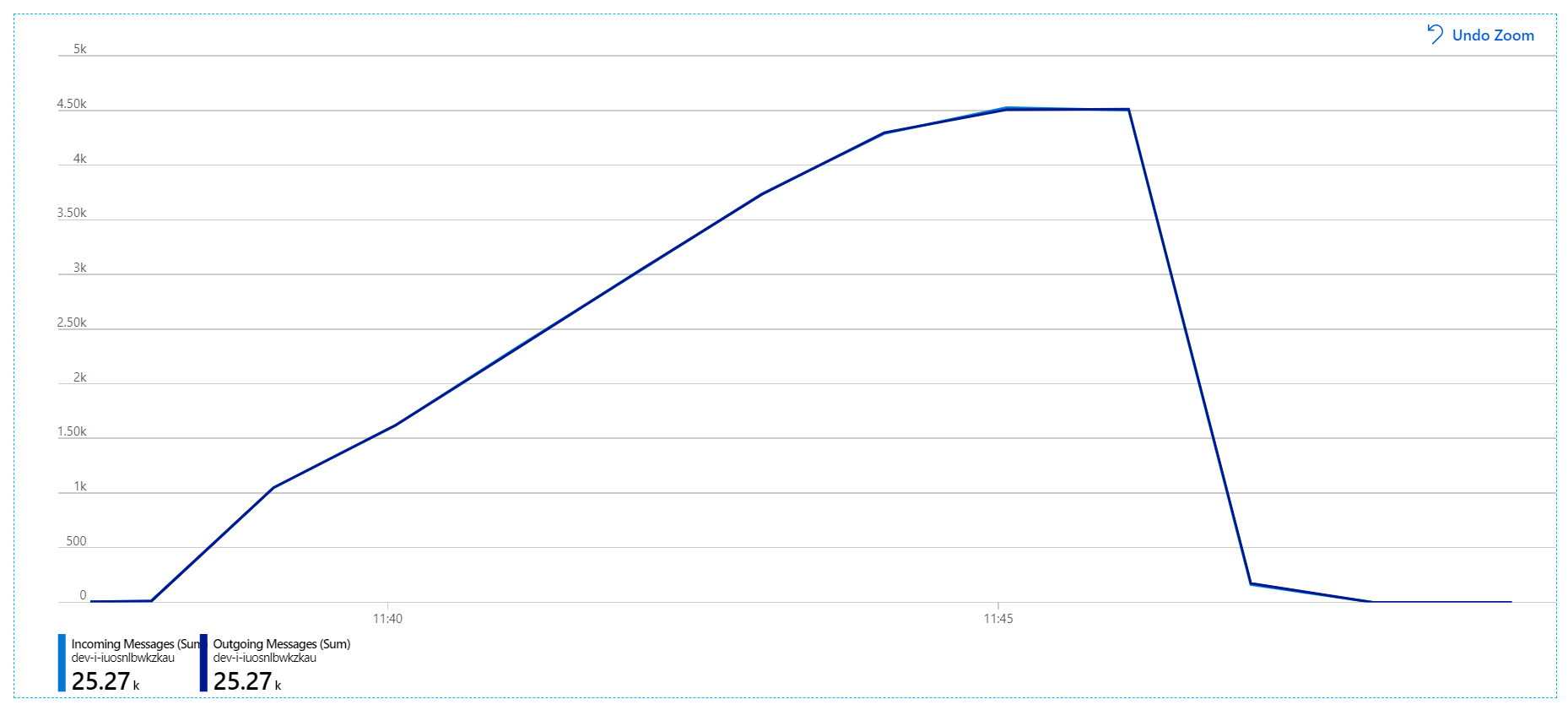
Za celkovou dobu trvání 8minutového zátěžového testu aplikace dokončila 25kilové operace s maximální propustností 72 operací za sekundu, což představuje 400% zvýšení maximální propustnosti.
Spuštění stejného testu s delší dobou trvání však ukázalo, že aplikace tuto rychlost neudrží:
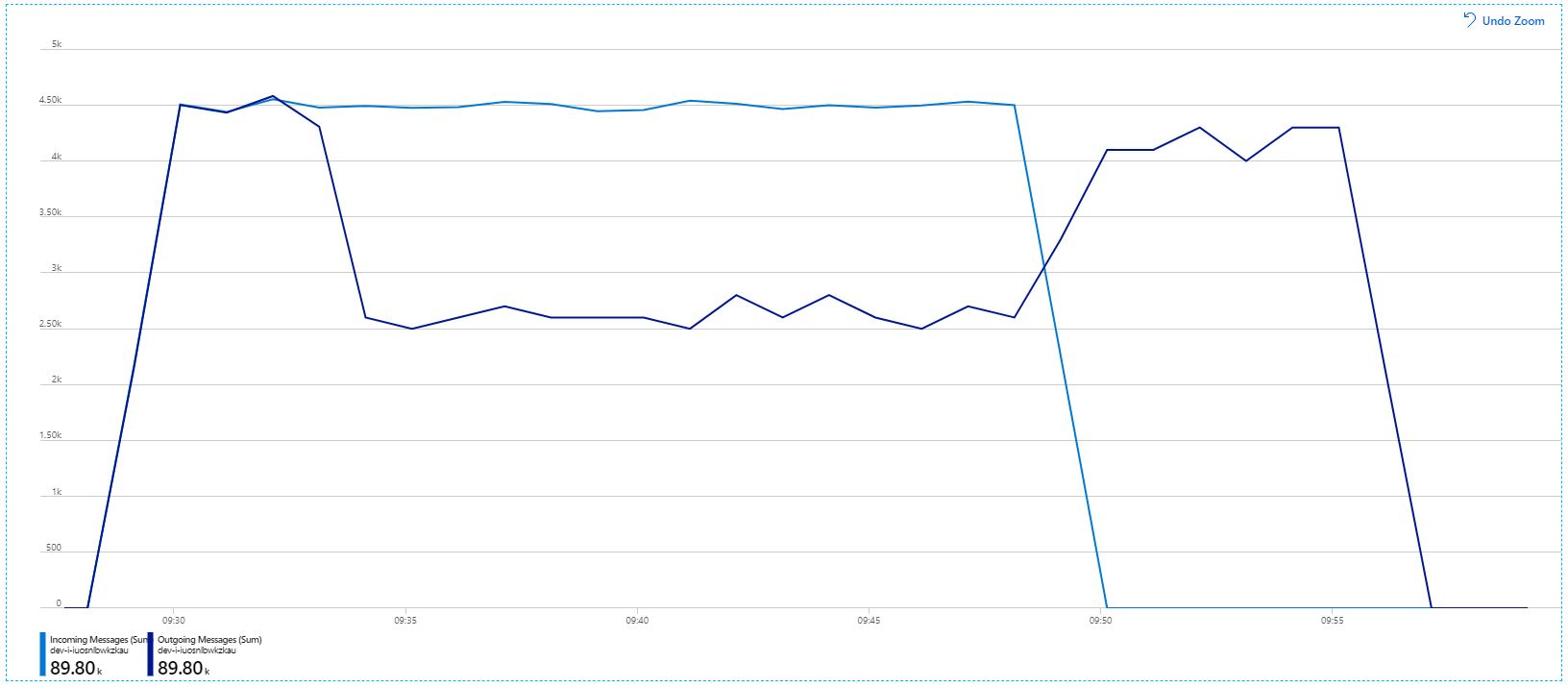
Metriky kontejneru ukazují, že maximální využití procesoru se blížilo 100 %. V tomto okamžiku se zdá, že aplikace je vázána na procesor. Škálování clusteru teď může zvýšit výkon, na rozdíl od předchozího pokusu o horizontální navýšení kapacity.
Test 6: Horizontální navýšení kapacity back-endových služeb (opět)
Pro poslední zátěžový test v sérii tým škáloval cluster Kubernetes a pody následujícím způsobem:
| Nastavení | Hodnota |
|---|---|
| Uzly clusteru | 12 |
| Služba příjmu dat | 3 repliky |
| Služba pracovního postupu | 6 replik |
| Balíčky, doručení, služby plánovače dronů | Každá z 9 replik |
Výsledkem tohoto testu byla vyšší trvalá propustnost bez významných prodlev při zpracování zpráv. Využití procesoru uzlu navíc zůstalo pod 80 %.
Souhrn
Pro tento scénář byly identifikovány následující kritické body:
- Výjimky s nedostatkem paměti v Azure Cache for Redis.
- Nedostatek paralelismu při zpracování zpráv
- Nedostatečná doba trvání uzamčení zpráv, což vede k vypršení časového limitu uzamčení a k umísťování zpráv do fronty nedoručených zpráv.
- Vyčerpání procesoru.
Při diagnostice těchto problémů vývojový tým spoléhal na následující metriky:
- Rychlost příchozích a odchozích zpráv služby Service Bus.
- Mapa aplikace v Application Insights.
- Chyby a výjimky.
- Vlastní dotazy Log Analytics.
- Využití procesoru a paměti v přehledech kontejnerů služby Azure Monitor.
Další kroky
Další informace o návrhu tohoto scénáře najdete v tématu Návrh architektury mikroslužeb.